 对于谷歌应用传统的自动语音识别(ASR)系统的解析
对于谷歌应用传统的自动语音识别(ASR)系统的解析
目前,谷歌的各种语音搜索应用还在使用传统的自动语音识别(ASR)系统,它包括一个包括声学模型(AM )、一个发音模型(PM)和一个语言模型(LM),它们都是彼此独立训练的,而且需要研究人员在不同数据集上进行手动调试。例如,当声学模型采集到一些声波特征,它会参考上下文中的音素,有时甚至是一些无关的音素来生成一系列subword单元预测。之后,发音模型会在手工设计的词典中为预测音素映射序列,最后再由语言模型根据序列概率分配单词。
和联合训练所有组件相比,这种对各模型进行独立训练其实是一种次优的选择,它会使整个过程更复杂。在过去几年中,端对端系统开发越来越受欢迎,它们的思路是把这些独立的组件组合成一个单一系统共同学习,但一个不可忽视的事实是,虽然端对端模型在论文中表现出了一定的希望,但没人真正确定它们比传统的做法效果更优。
为了验证这一点,近日,谷歌推荐了一篇由Google Brain Team发表的新论文:State-of-the-art Speech Recognition With Sequence-to-Sequence Models,介绍了一种新的、在性能上超越传统做法的端对端语音识别模型。论文显示,相较于现在最先进的语音识别工具,谷歌新模型的字错误率(WER)只有5.6%,比前者的6.7%提升了16%。此外,在没有任何预测评分的前提下,用于输出初始字假设的端对端模型在体量上是传统工具的十八分之一,因为它不包含独立的语言模型和发音模型。
这个新模型的系统建立在Listen-Attend-Spell(LAS)端到端体系结构上,该结构由3部分组成,其中Listen组件的编码器和标准声学模型类似,把时频语音信号x作为输入,并用一组神经网络层将输入映射为一个高水平的表征henc。Attend接收前者编码器的输出,并用henc来学习输入x和预测subword单元{yn, … y0}之间的对齐。其中每个subword单元通常是字形或词形。组合,Attend组件将输出传输给Spell组件(解码器),它类似语言模型,能产生一组预测字词的概率分布。
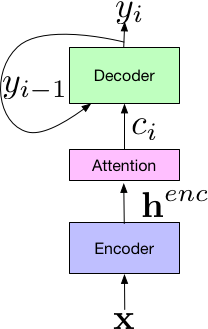
不同于传统的独立训练,LAS的所有组件都在一个单一的端到端神经网络中联合训练,这意味着它更简单方便。此外,由于LAS是一个彻底的神经网络,所以它不需要外部增设手工组件,例如有穷状态转移机、lexicon或TN模型。最后,LAS不需要像传统模型一样用单独系统生成的决策树或time alignment来做Bootstrap,它可以在给定文本转录和相对应音频资料的情况下直接训练。
在论文中,谷歌大脑团队还介绍他们在LAS中引入各类新颖的结构对神经网络做了调整,包括改进传递给解码器的attention vector,以及用更长的subword单元对网络进行训练(如wordpiece)。他们也用了大量优化训练方法,其中就有使用最低错词率进行训练。这些创新都是端到端模型较传统性能提升16%的原因。
这项研究另一个值得兴奋的点是多方言和多语言系统,这可能开启一些潜在应用,由于它是一个经优化的单个神经网络,模型的简单性使它独具吸引力。在LAS中,研究人员可以将所有方言、语言数据整合在一起进行训练,而无需针对各个类别单独设置AM、PM和LM。据论文介绍,经测试,谷歌的这个模型在7种英语方言、9种印度语言上表现良好,并超越了对照组的单独训练模型。
虽然这个数据结果令人兴奋,但这暂时还不是一个真正成熟的工作,因为它还不能实时处理语音,而这是它被用于语音搜索的一个重大前提。此外,这些模型生成的数据和实际数据仍存在不小的差距,它们只学习了22000个音频文本对话,在语料库数据积累上远比不上传统方法。当面对一些罕见的词汇时,比如一些人工设计的专业名词、专有名词,端到端模型还不能正确编写。因此,为了让它们能更实用、适用,谷歌大脑的科学家们未来仍将面临诸多问题。
-
谷歌
+关注
关注
27文章
6164浏览量
105310 -
语音识别
+关注
关注
38文章
1739浏览量
112635 -
语音搜索
+关注
关注
0文章
6浏览量
7818
原文标题:谷歌大脑发力语音搜索:一个用于语音识别的端到端模型
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
手机语音识别应用中DSP该怎么选择?
TWEN-ASR ONE 语音识别系列教程(1)——运行第一个语音程序
HarmonyOS开发-语音识别
语音识别威廉希尔官方网站 ,语音识别威廉希尔官方网站 是什么意思
ASR语音识别威廉希尔官方网站 的介绍应用和优势及实际案例分析
ASR语音威廉希尔官方网站 的原理以及未来发展趋势分析
探索自动语音识别威廉希尔官方网站 的独特应用
什么是自动语音识别(ASR)?如何使用深度学习和GPU加速ASR






 工商网监
工商网监
评论