 【每天学点AI】五个阶段带你了解人工智能大模型发展史!
【每天学点AI】五个阶段带你了解人工智能大模型发展史!

20世纪50年代
NLP的早期研究主要基于规则的方法,依赖于语言学专家手工编写的规则和词典。这些规则通常是关于语法、语义和句法结构的人工规则。

例如一个简单的陈述句通常遵循“主语 + 谓语 + 宾语”的结构,每一个陈述句都以这种规则做标记。
那时候的NLP就像个刚学步的小孩,靠的是一堆人工的规则,就像小时候学说话,需要一个字一个字地学,学完单词学语法。
20世纪70年代
随着时间的推移,20世纪70年代随着计算能力的提升和数据的积累,NLP开始转向基于统计学的方法。这些方法依赖于大量的文本数据,通过统计模型来捕捉语言模式,而非手工制定规则。统计方法开始重视词语的共现关系,并通过概率推断来实现语言处理任务。

NLP开始用大数据来学习语言的规律,就像你长大了,通过听周围人说话来学习新词汇和表达,但是对于你来说每个单词都是独立的,相互没有关系。
2013年
2013年,基于嵌入embedding的NLP方法被发明,通过将词语、短语、句子等语言元素映射到高维的连续向量空间中,这些向量捕捉了词语之间的语义关系,使得模型能够更好地理解和处理语言。
就像用表情符号来表达情感一样,表情是人类语言的抽象,这些向量能捕捉词语的意思和关系。
同年Encoder-decoder的模型结构被发明,为后续的序列到序列(Seq2Seq)模型奠定了基础,至此命运的齿轮开始转动。
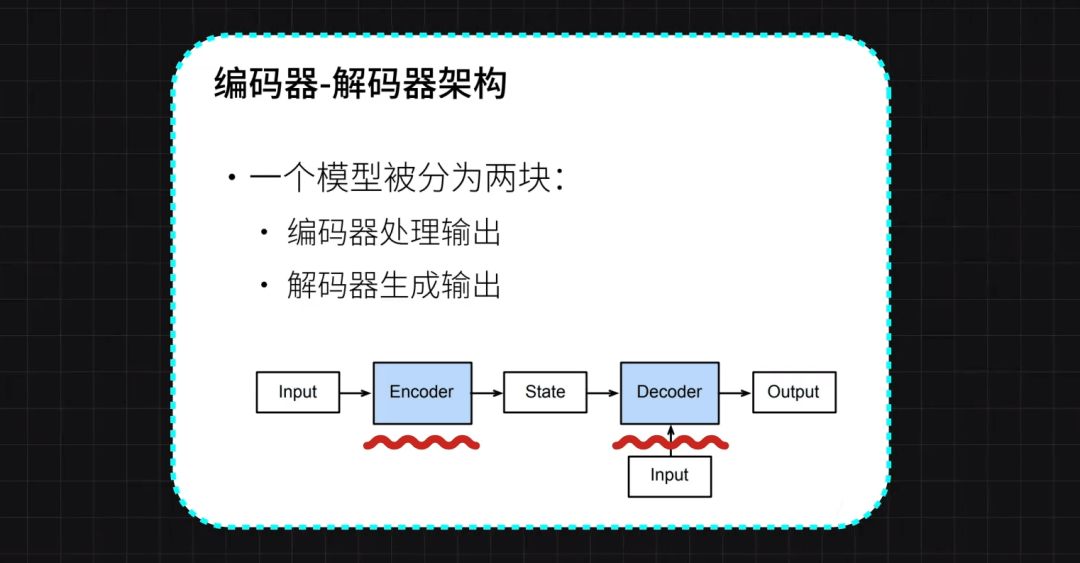
2017年
2017年,"Attention is all you need"论文的发表标志着Transformer模型的诞生,它在上一个阶段词嵌入的基础上,基于自注意力机制的模型,它彻底改变了NLP领域的模型设计和训练方式。

Transformer模型通过多头注意力机制和位置编码,有效地处理了序列数据,提高了模型的并行处理能力和性能。它用自注意力机制让模型能同时关注句子中的所有词,就像你在聊天时,能同时关注群里每个人的发言。
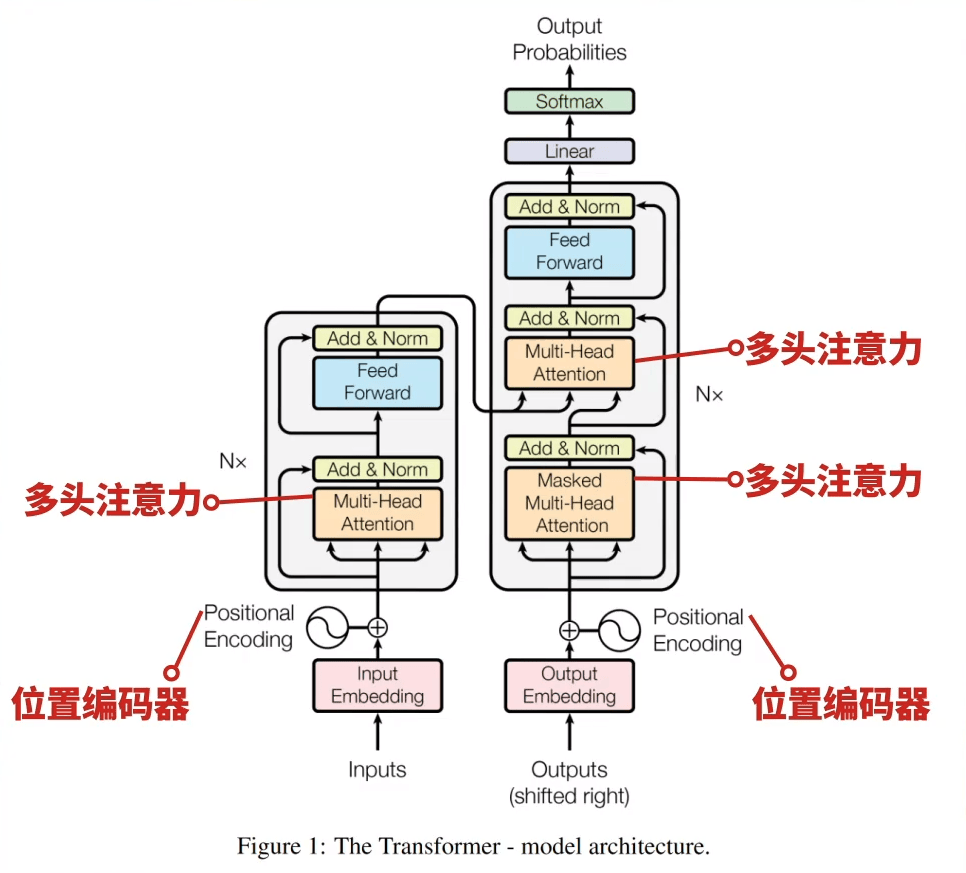
随后,基于Transformer架构的BERT和GPT等模型相继出现,它们通过预训练和微调的方式,在多种NLP任务上取得了突破性的性能。
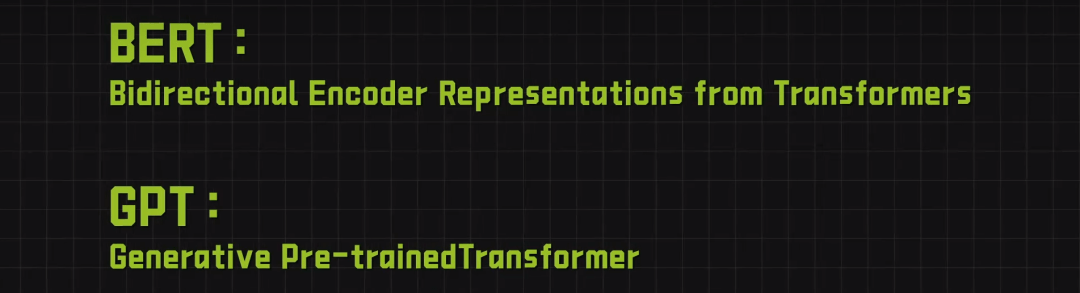
2022年
之后的故事大家都很熟悉了,2022年chatgpt横空出世,大模型的涌现一发不可收拾。你知道他们为什么叫大模型吗?是因为这些模型的参数量已经达到了百亿甚至千亿级别!
AI体系化学习路线
学习资料免费领
【后台私信】AI全体系学习路线超详版+100余讲AI视频课程 +AI实验平台体验权限
全体系课程详情介绍

-
AI
+关注
关注
87文章
30830浏览量
268991 -
人工智能
+关注
关注
1791文章
47244浏览量
238369 -
大模型
+关注
关注
2文章
2439浏览量
2676
发布评论请先 登录
相关推荐
【每天学点AI】人工智能大模型评估标准有哪些?

《AI for Science:人工智能驱动科学创新》第6章人AI与能源科学读后感
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的威廉希尔官方网站 支撑学习心得
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新
三菱电机功率器件发展史






 工商网监
工商网监
评论