 基于Arm平台的服务器CPU在LLM推理方面的能力
基于Arm平台的服务器CPU在LLM推理方面的能力
作者:Arm 基础设施事业部数据中心解决方案架构师 Ravi Malhotra
在过去一年里,生成式人工智能 (AI) 吸引了科技行业的目光,大家都在想方设法地将大语言模型 (LLM) 部署到其位于云端和边缘侧服务器上的应用中。虽然 GPU 和加速器凭借优异的性能,一直是这些部署任务的默认首选平台。但在推理领域,除了 GPU 和加速器之外,还有其他可行的选择。长期以来,CPU 一直被用于传统的 AI 和机器学习 (ML) 用例,由于 CPU 能够处理广泛多样的任务且部署起来更加灵活,因此当企业和开发者寻求将 LLM 集成到产品和服务中时,CPU 成了热门选择。
本文将介绍基于 Arm Neoverse 的 AWS Graviton3 CPU 在规模化灵活运行 Llama 3[1] 和 Phi-3[2] 等业内标准 LLM 方面的能力,并展示与其他基于 CPU 的服务器平台相比的主要优势。
AWS Graviton3 上的 LLM 性能
为了展示基于 Arm 平台的服务器 CPU 在 LLM 推理方面的能力,Arm 软件团队和我们的合作伙伴对 llama.cpp 中实现的 int4 和 int8 内核进行了优化,以利用这些较新的指令[3]。我们在 AWS Graviton3 平台上进行了多次实验,以测量不同场景下对性能的影响,并将影响因素隔离开。
所有实验均在 AWS r7g.16xlarge 实例上进行,该实例带有 64 个虚拟 CPU (vCPU) 和 512 GB 的内存。所用的模型是经过 int4 量化的 Llama3-8B。
提示词处理
提示词词元 (Token) 通常是并行处理的,即使对于单次操作 (batch=1),也会使用所有可用核心。在这方面,经过 Arm 优化,每秒处理的词元数提升了 2.5 倍;在处理更大的批次大小时,性能小幅提升。
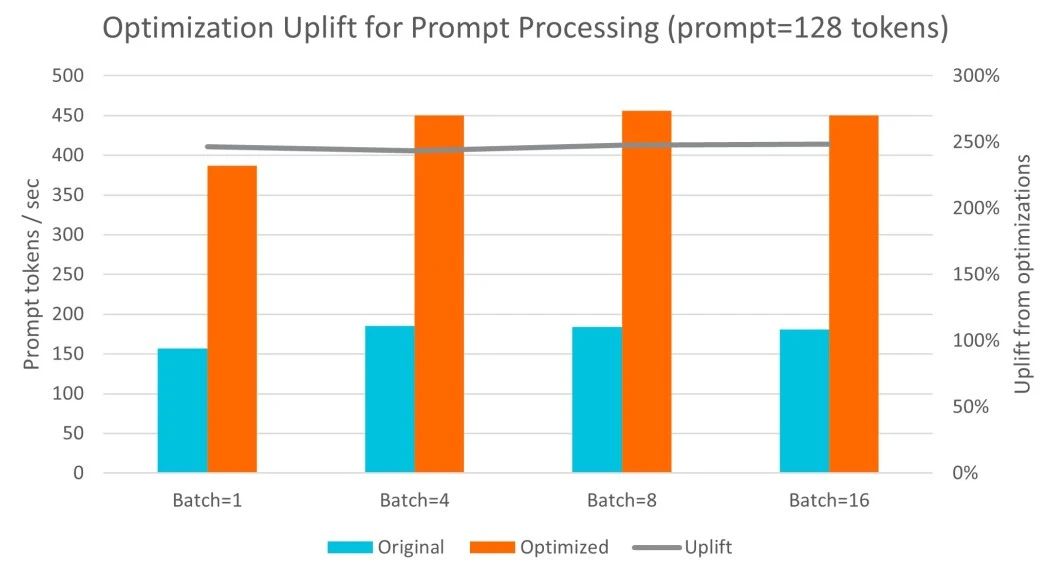
图:提示词处理经优化得到提升
词元生成
词元生成以自回归的方式进行,对于所需生成的输出长度高度敏感。在这方面,经过 Arm 优化,吞吐量最多可提高两倍,有助于处理更大的批次大小。
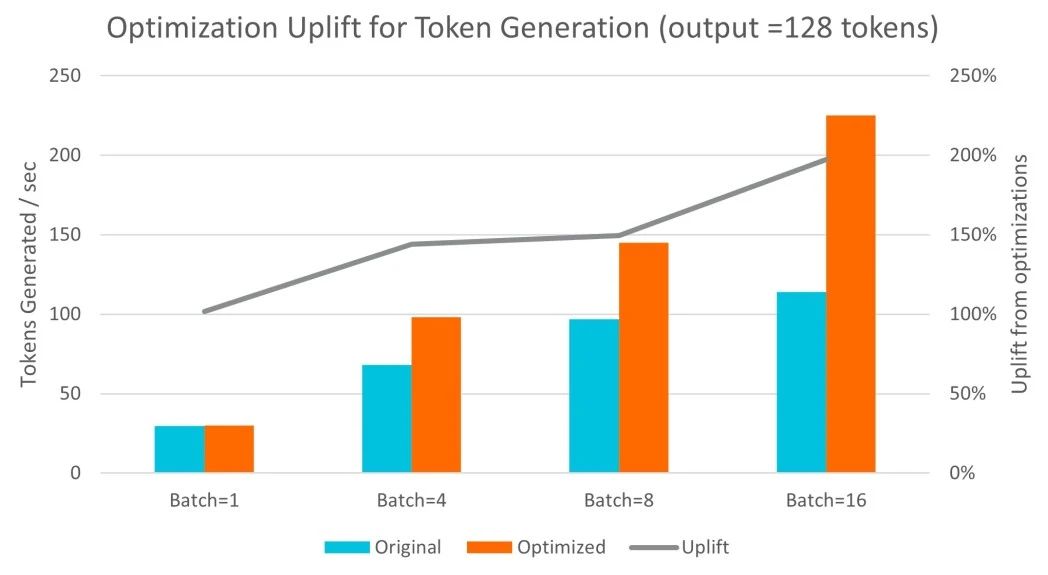
图:词元生成经优化得到提升
延迟
词元生成的延迟对 LLM 的交互式部署非常重要。对于下个词元响应时间 (time-to-next-token),100ms 的延迟是关键的目标指标,这是基于人们每秒 5-10 个单词的典型阅读速度计算得出的。在下方图表中,我们看到在单次操作和批量处理的场景下,AWS Graviton3 都能满足 100ms 的延迟要求,因此适合于作为 LLM 的部署目标。
我们使用了两组不同的模型 Llama3-8B 和 Phi-3-mini (3.8B),以展示不同规模的 LLM 的延迟情况。
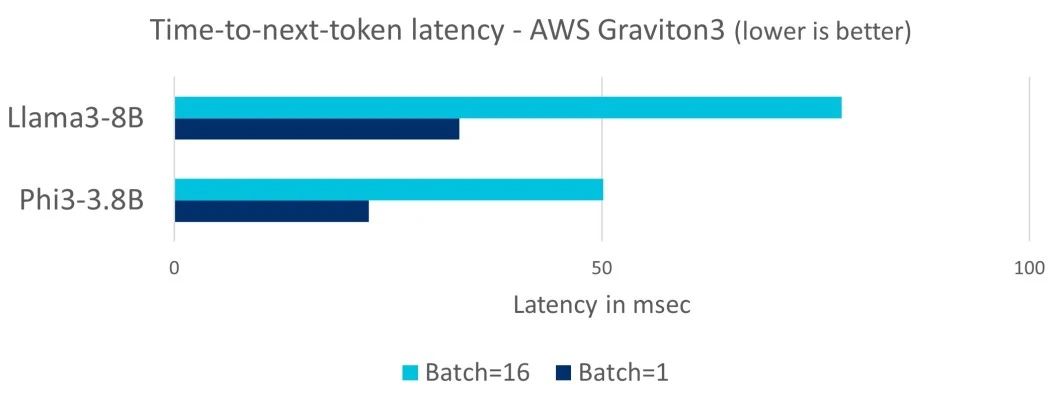
图:AWS Graviton3 的下个词元响应时间延迟情况
即使是在 2019 年推出的 AWS Graviton2 这样的上一代 Arm 服务器平台上,也能运行多达 80 亿参数的新 LLM,并且在单次操作和批量处理的场景下,均能满足 100ms 的延迟要求。
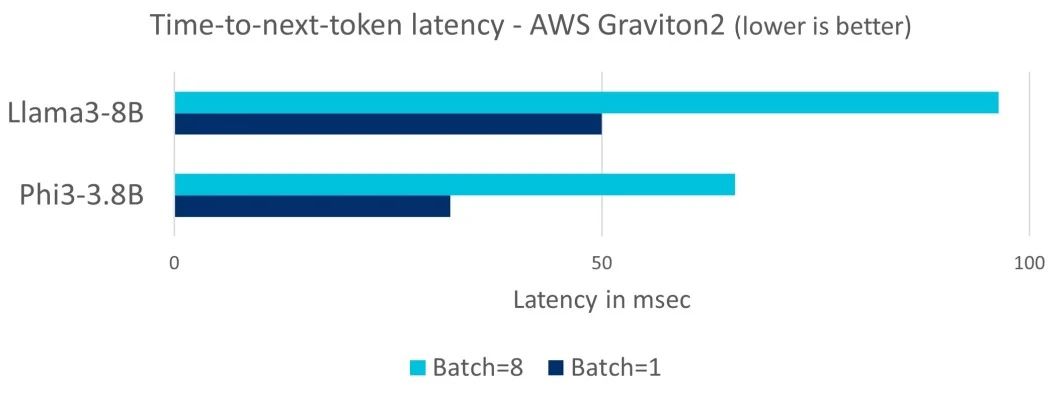
图:AWS Graviton2 的下个词元响应时间延迟情况
性能比较
此外,我们使用经过 int4 量化的 Llama3-8B 模型,比较了它在 AWS Graviton3 与在 AWS 上其他新一代服务器 CPU 的性能。
AWS Graviton3:r7g.16xlarge,64 个 vCPU,512 GB 内存,3.43 美元/小时
第四代 Intel Xeon:r7i.16xlarge,64 个 vCPU,512 GB 内存,4.23 美元/小时
第四代 AMD EPYC:r7a.16xlarge,64 个 vCPU(SMT 关闭),512 GB 内存,4.87 美元/小时
我们发现,相较于其他两款 CPU,在提示词处理和词元生成方面,AWS Graviton3 的性能高出三倍。
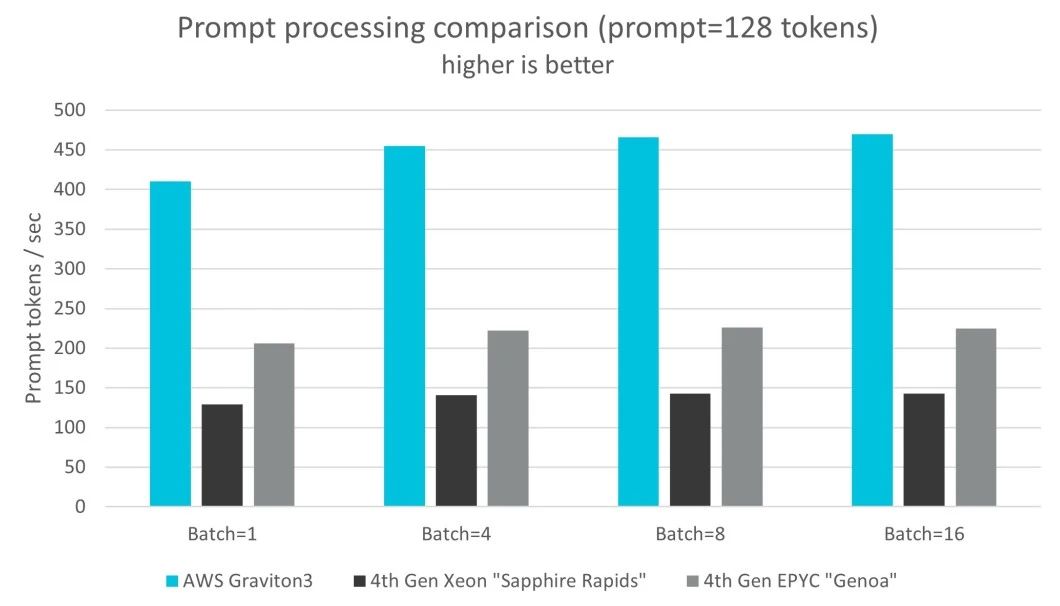
图:提示词处理比较
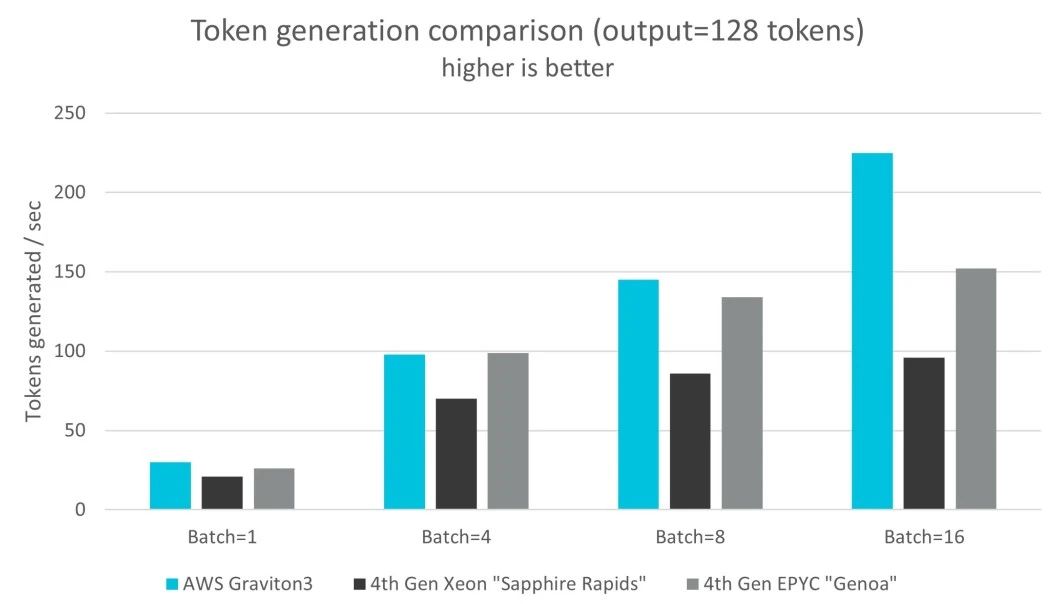
图:词元生成比较
同样值得注意的是,AWS Graviton3 CPU 比第四代 x86 CPU 更具成本效益,这在 Graviton3 实例相对较低的定价中就有所体现。鉴于 LLM 对算力的要求已经非常高,以单位价格词元数量来计算总体拥有成本 (TCO),是推动 LLM 在数据中心内广泛采用的关键。
在这一点上,AWS Graviton3 拥有显著优势,每美元词元数量最高多了三倍,不仅在 CPU 中处于领先,也为希望在采用 LLM 的过程中逐步扩大规模的用户提供了令人信服的优势。
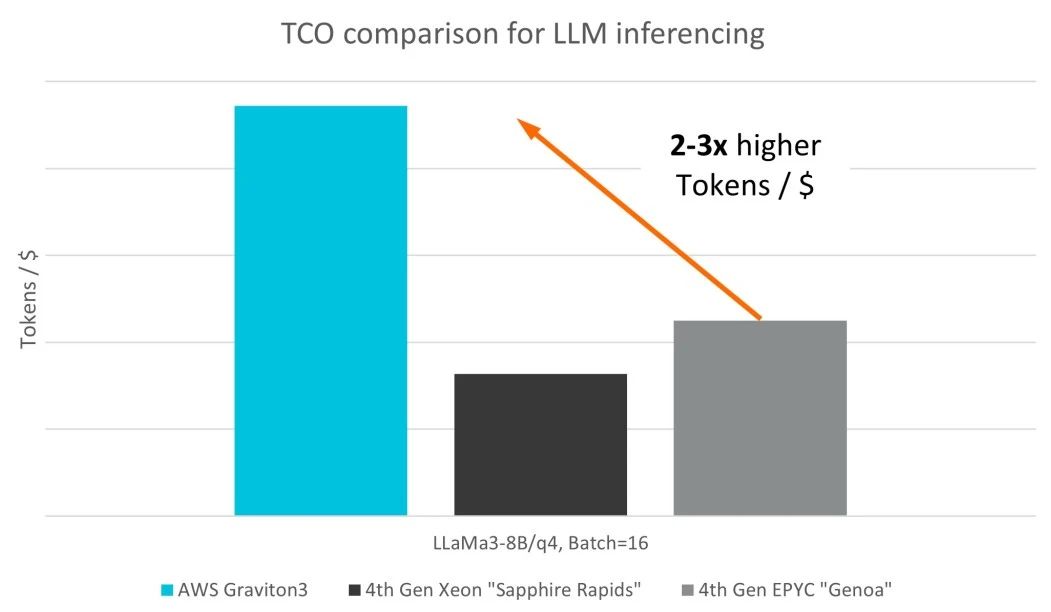
图:LLM 推理的 TCO 比较
结论
当开发者想要在其应用中部署专用 LLM 时,服务器 CPU 为开发者提供了灵活、经济和简化的起点。Arm 新增了几项关键特性,有助于显著提升 LLM 的性能。得益于此,基于 Arm Neoverse 的服务器处理器(如 AWS Graviton3)不仅能提供优于其他服务器 CPU 的 LLM 性能,还能为更多应用开发者降低采用 LLM 的门槛。
-
ARM
+关注
关注
134文章
9087浏览量
367398 -
cpu
+关注
关注
68文章
10855浏览量
211594 -
服务器
+关注
关注
12文章
9124浏览量
85332 -
人工智能
+关注
关注
1791文章
47201浏览量
238271
原文标题:在基于 Arm Neoverse 的 AWS Graviton3 CPU 上实现出色性能
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
安谋科技与鸿钧微电子携手,加速服务器CPU产业和生态落地

AI推理CPU当道,Arm驱动高效引擎

Arm芯片引领国产服务器逆袭?
AMD推出首款基于ARM的CPU与开发平台 加快ARM服务器生态系统发展
ARM服务器CPU终于正式量产
华为首款Arm架构服务器CPU鲲鹏920,业界最高性能Arm架构服务器CPU
关于Arm服务器芯片的现状和发展分析
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求
EDA软件在ARM服务器的应用解析





 工商网监
工商网监
评论