 Cortex R52内核Cache的相关概念(2)
Cortex R52内核Cache的相关概念(2)
Cache相关概念
3Outer&Inner R/W allocate
表示分配方式为外部和内部都是读写分配。
读/写分配是一种内存访问策略,用于确定处理器在访问内存时是否需要将数据加载到高速缓存中。具体来说:
读分配:当处理器需要从内存中读取数据时,如果该数据不在高速缓存中,则会将相应的数据块加载到高速缓存中,以便处理器能够更快地访问和处理数据。
写分配:当处理器需要向内存写入数据时,如果写入的数据不在高速缓存中,则会先将相应的数据块加载到高速缓存中,并在高速缓存中进行写操作,然后再将更新后的数据写入到内存中。读/写分配可以影响系统的性能表现,合理选择读/写分配策略可以提高数据访问的效率和速度。
如果外部和内部都是读/写分配,表示处理器在与外部存储器和内部缓存之间的数据交互时,都采用读/写分配的方式来管理数据的加载和写入操作。这样的设置可以根据具体场景提高数据访问的效率和性能。
4Write-Back,Write-Through
Write-back写回,和Write-Through写透是两种不同的缓存策略,它们在处理器访问数据时的行为有所不同:在写回策略下,当处理器要写入数据时,数据首先被写入到缓存中,而不是直接写入到内存中。只有在缓存行被替换出去时,才会将被修改的数据写回到内存中。这样可以减少对内存的频繁写入操作,提高缓存的利用率和性能。
在写透策略下,当处理器要写入数据时,数据会同时被写入到缓存和内存中。每次写操作都会导致数据被同步写入到内存,确保内存和缓存中的数据一致性。虽然可以保证数据的一致性,但可能会增加写操作的延迟。
效率上来说,写回策略通常比写透策略效率更高。这是因为写回策略减少了对内存的频繁写入,利用了缓存的特性来减少内存访问次数,提高了系统整体的性能。然而,写回策略需要额外的控制逻辑来管理缓存中数据与内存之间的一致性,因此需要更多的硬件支持。选择哪种策略取决于系统的设计需求和性能优化目标。
5Outer&Inner non-allocate
外部和内部都是非分配的意味着在存储器属性中指定了不进行分配(non-allocate)的方式。这意味着处理器在访问这种类型的内存时,不会将数据加载到高速缓存中进行缓存,而是直接在内存中读取或写入数据。
当外部和内部都是非分配时,处理器在访问这段内存时不会将其内容缓存起来,而是每次都直接从内存读取或写入数据。这种方式可能会增加内存访问的延迟,但可以确保处理器访问的数据是最新的,适用于对数据实时性要求较高的场景。
6Outer&Inner non-cacheable
表示外部和内部都不开缓存
7Non-transient可以理解为非瞬态
"transient" 通常用来描述一种短暂存在或暂时性的状态或属性。而 "non-transient" 则表示相反的情况,即不是短暂的或不是暂时的。
在代码中提到的 "non-transient" 和 "transient" 可能用来描述内存访问属性的持久性或持续性。例如,如果一个内存区域被标记为 "non-transient",可能意味着该区域的属性在一段时间内保持不变,而不是临时性的或随机变化的。

点击可查看大图
这里要注意的一点是:如上图红框所示CortexR52的内核的write-back被当成是write-through来对待。
System ram的MPU配置说明

点击可查看大图
这里的ATTRINDEX1对应的就是Attr1的配置,其它的序号也是一一对应的。
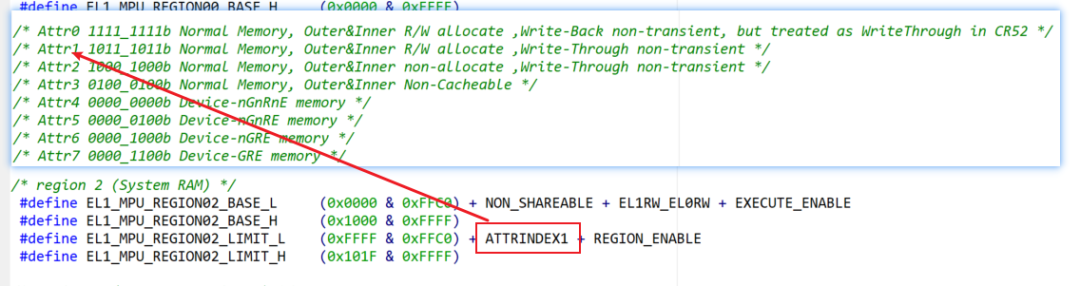
点击可查看大图
Attr1可以看出他的配置是正常存储设备,内外部读写分配,并且是写透的cache策略,这面要注意的是,打开cache一定要是non_shareable。
我们再看一下下图中System RAM mirror:的MPU配置策略与system ram正好相反,ATTRINDEX3对应的Attr3是没有使能cache,却是“outer_shareable”的状态。这个也好理解,因为开cache,又开共享的话会影响数据一致性的。

点击可查看大图
下个章节将介绍Cortex R52具体的缓存操作的实践和性能测试。
-
处理器
+关注
关注
68文章
19286浏览量
229824 -
内核
+关注
关注
3文章
1372浏览量
40289 -
Cortex
+关注
关注
2文章
202浏览量
46497
原文标题:解密Cortex R52内核Cache:操作实践、性能测试与深度解析(2)
文章出处:【微信号:瑞萨MCU小百科,微信公众号:瑞萨MCU小百科】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
解析Arm Neoverse N2 PMU事件L2D_CACHE_WR

Arm Cortex-R82AE赋能高性能区域控制器设计
RM57L843基于ARM® Cortex®-R内核的Hercules™微控制器数据表

TMS570LC4357基于ARM Cortex®-R内核的Hercules™微控制器数据表
Cortex R52内核Cache的具体操作(2)

Cortex R52内核Cache的相关概念(1)
CortexR52内核Cache的具体操作

摩芯半导体与安谋科技达成合作
RZ/T2M直流伺服电机解决方案

兆易创新推出GD32F5系列Cortex-M33内核MCU
Cortex-M85内核单片机如何快速上手

强大的Arm® Cortex®-M3内核(下)
CV3域控芯片家族又添两员!各档规格完整覆盖,软件功能全面兼容
Arm Cortex-M52的主要特性和规格






 工商网监
工商网监
评论