 用于自然语言处理的神经网络有哪些
用于自然语言处理的神经网络有哪些
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,旨在让计算机能够理解和处理人类语言。随着深度学习威廉希尔官方网站 的飞速发展,神经网络模型在NLP领域取得了显著进展,成为处理自然语言任务的主要工具。本文将详细介绍几种常用于NLP的神经网络模型,包括递归神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)、变换器(Transformer)以及预训练模型如BERT等。
一、递归神经网络(RNN)
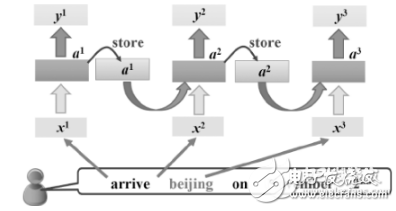
递归神经网络是一种能够处理序列数据的神经网络,其结构类似于链表,特别适合于处理具有时间依赖性的数据。在自然语言处理中,RNN被广泛应用于文本分类、语言建模、情感分析、命名实体识别等任务。
1. 基本原理
RNN的核心思想是通过将前面的信息传递到后面来捕捉序列数据中的依赖关系。具体来说,RNN中的每个节点都有一个隐藏状态,用于存储之前的信息,并将其传递到下一个节点。通过这种方式,RNN能够记忆之前的信息并利用它们来预测下一个单词或字符等。
2. 优缺点
优点 :
- 能够处理任意长度的序列数据。
- 能够记忆并利用序列中的历史信息。
缺点 :
- 存在梯度消失和梯度爆炸的问题,难以捕捉长距离依赖关系。
- 不支持并行处理,计算效率较低。
3. 应用场景
RNN适用于需要处理序列数据的任务,如文本生成、机器翻译等。然而,由于其缺点,RNN在处理长文本时性能受限,因此在实际应用中常被LSTM等变体模型所取代。
二、长短时记忆网络(LSTM)
长短时记忆网络是RNN的一种变体,通过引入门控机制来解决传统RNN存在的梯度消失和梯度爆炸问题。LSTM在自然语言处理领域的应用非常广泛,特别是在机器翻译、文本分类、情感分析等方面。
1. 基本结构
LSTM的模型结构包括三个门控单元:输入门、遗忘门和输出门。这些门分别负责控制新信息的输入、旧信息的遗忘和输出的内容。LSTM的关键在于它的记忆单元,它能够记住历史信息并将其传递到后续的时间步中。
2. 优缺点
优点 :
- 能够处理长序列数据,捕捉长距离依赖关系。
- 解决了RNN的梯度消失和梯度爆炸问题。
缺点 :
- 参数较多,计算复杂度较高。
- 仍然不支持并行处理。
3. 应用场景
LSTM适用于需要处理长序列数据的任务,如机器翻译、问答系统等。在这些任务中,LSTM能够记住历史信息并利用它们来生成更准确的输出。
三、卷积神经网络(CNN)
卷积神经网络是一种能够学习局部特征的神经网络,在计算机视觉领域取得了巨大成功。近年来,CNN也在自然语言处理领域得到了应用,特别是在文本分类、情感分析等任务中。
1. 基本原理
CNN中的核心是卷积层,卷积层通过在输入数据上滑动一个指定大小的窗口来提取不同位置的特征。这些特征被进一步处理并输出一个固定维度的向量表示。为了处理序列数据,通常需要在卷积层上添加池化层或全局平均池化层来提取序列数据的局部或全局特征。
2. 优缺点
优点 :
- 能够并行处理数据,计算效率高。
- 能够捕捉局部特征并减少计算量。
缺点 :
- 相比RNN和LSTM,CNN在处理序列数据时难以捕捉长距离依赖关系。
- 需要固定长度的输入序列。
3. 应用场景
CNN适用于处理定长序列数据的任务,如文本分类、情感分析等。在这些任务中,CNN能够高效地提取文本特征并进行分类或情感判断。
四、变换器(Transformer)
变换器是一种基于注意力机制的模型,能够处理语音、文本等序列数据。在自然语言处理领域,Transformer被广泛应用于机器翻译、文本分类等任务,并取得了显著成效。
1. 基本原理
Transformer模型主要由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责将输入序列转换为一系列隐藏状态表示,而解码器则利用这些隐藏状态表示来生成输出序列。Transformer的核心是注意力机制,它能够通过计算输入数据之间的相关性来动态地调整模型的注意力分配。
2. 优缺点
优点 :
- 能够并行处理数据,计算效率高。
- 能够捕捉长距离依赖关系。
- 相比RNN和LSTM,Transformer在训练过程中更容易优化。
缺点 :
- 需要大量的训练数据和计算资源。
- 对于短文本或单个单词级别的任务可能不如RNN或LSTM有效。
3. 应用场景
Transformer适用于需要处理长序列数据且对计算效率有较高要求的### 场景的任务,如机器翻译、文本摘要、语音识别等。
在机器翻译中,Transformer凭借其出色的长距离依赖捕捉能力和高效的并行计算能力,显著提升了翻译的质量和速度。相比传统的基于RNN或LSTM的模型,Transformer能够更准确地理解源语言的语义信息,并生成更流畅、更自然的目标语言文本。
在文本摘要领域,Transformer同样表现出色。它能够从长文本中快速提取关键信息,并生成简洁明了的摘要。这一能力得益于Transformer的注意力机制,使得模型能够专注于文本中的重要部分,而忽略掉冗余或无关的信息。
此外,Transformer还被广泛应用于语音识别任务中。通过结合语音信号的时序特性和Transformer的注意力机制,模型能够更准确地识别语音中的单词和句子,提高语音识别的准确率和鲁棒性。
五、预训练模型:BERT及其变体
近年来,预训练模型在自然语言处理领域引起了广泛关注。BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer结构的预训练模型,它通过在大规模文本数据上进行无监督学习,获得了丰富的语言表示能力。
1. 基本原理
BERT的核心思想是利用大规模语料库进行预训练,学习文本中单词和句子的上下文表示。在预训练阶段,BERT采用了两种任务:遮蔽语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。MLM任务通过随机遮蔽输入文本中的一部分单词,要求模型预测这些被遮蔽的单词;NSP任务则要求模型判断两个句子是否是连续的文本片段。这两个任务共同帮助BERT学习文本中的语言知识和语义关系。
2. 优缺点
优点 :
- 强大的语言表示能力,能够捕捉丰富的上下文信息。
- 灵活的迁移学习能力,可以方便地应用于各种NLP任务。
- 提高了模型的泛化能力和性能。
缺点 :
- 需要大量的计算资源和训练数据。
- 模型参数较多,计算复杂度较高。
3. 应用场景
BERT及其变体模型被广泛应用于各种NLP任务中,包括文本分类、命名实体识别、问答系统、文本生成等。通过微调(Fine-tuning)预训练模型,可以将其快速适应到特定的NLP任务中,并取得优异的性能表现。例如,在文本分类任务中,可以通过微调BERT模型来学习不同类别的文本特征;在问答系统中,可以利用BERT模型来理解和回答用户的问题;在文本生成任务中,可以借助BERT模型来生成连贯、自然的文本内容。
六、未来展望
随着深度学习威廉希尔官方网站 的不断发展和计算资源的日益丰富,神经网络在自然语言处理领域的应用将会更加广泛和深入。未来,我们可以期待以下几个方面的进展:
- 更高效的模型架构 :研究人员将继续探索更加高效、更加适合NLP任务的神经网络架构,以提高模型的计算效率和性能。
- 更丰富的预训练任务 :除了现有的MLM和NSP任务外,未来可能会引入更多种类的预训练任务来进一步丰富模型的语言表示能力。
- 跨语言理解和生成 :随着全球化的加速和互联网的发展,跨语言理解和生成将成为NLP领域的一个重要研究方向。未来的模型将能够更好地理解和生成多种语言的文本内容。
- 多模态融合 :未来的NLP系统可能会融合文本、图像、语音等多种模态的信息,以实现更加全面、准确的理解和生成能力。
总之,神经网络在自然语言处理领域的应用前景广阔,我们有理由相信,在未来的发展中,神经网络将继续推动NLP威廉希尔官方网站 的进步和应用拓展。
-
神经网络
+关注
关注
42文章
4767浏览量
100662 -
自然语言处理
+关注
关注
1文章
618浏览量
13541 -
nlp
+关注
关注
1文章
487浏览量
22030
发布评论请先 登录
相关推荐
神经网络模型用于解决什么样的问题 神经网络模型有哪些
RNN在自然语言处理中的应用
自然语言处理中的卷积神经网络的详细资料介绍和应用
浅谈图神经网络在自然语言处理中的应用简述






 工商网监
工商网监
评论