 bp神经网络模型拓扑结构包括哪些
bp神经网络模型拓扑结构包括哪些
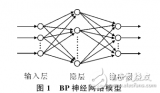
BP神经网络(Backpropagation Neural Network)是一种多层前馈神经网络,其拓扑结构包括输入层、隐藏层和输出层。下面详细介绍BP神经网络的拓扑结构。
- 输入层
输入层是BP神经网络的第一层,用于接收外部输入信号。输入层的神经元数量取决于问题的特征维度。每个输入信号通过一个权重与输入层的神经元相连,权重的初始值通常随机初始化。
- 隐藏层
隐藏层是BP神经网络的核心部分,用于提取特征和进行非线性变换。隐藏层可以有多个,每个隐藏层可以包含不同数量的神经元。隐藏层的神经元数量和层数取决于问题的复杂性和需要的表达能力。
隐藏层的神经元通过权重与输入层的神经元相连,权重的初始值通常随机初始化。隐藏层的神经元使用激活函数进行非线性变换,常用的激活函数有Sigmoid函数、Tanh函数和ReLU函数等。
- 输出层
输出层是BP神经网络的最后一层,用于生成预测结果。输出层的神经元数量取决于问题的输出维度。输出层的神经元通过权重与隐藏层的神经元相连,权重的初始值通常随机初始化。
输出层的神经元使用激活函数进行非线性变换,常用的激活函数有Softmax函数、Sigmoid函数和线性函数等。Softmax函数常用于多分类问题,Sigmoid函数常用于二分类问题,线性函数常用于回归问题。
- 权重和偏置
BP神经网络中的权重和偏置是网络的参数,用于调整神经元之间的连接强度。权重和偏置的初始值通常随机初始化,然后在训练过程中通过反向传播算法进行调整。
权重是神经元之间的连接强度,用于调整输入信号对神经元的影响。偏置是神经元的阈值,用于调整神经元的激活状态。权重和偏置的值通过训练数据进行优化,以最小化预测误差。
- 激活函数
激活函数是BP神经网络中的关键组成部分,用于引入非线性,使网络能够学习和interwetten与威廉的赔率体系 复杂的函数映射。常用的激活函数有:
- Sigmoid函数:Sigmoid函数是一种将输入值压缩到0和1之间的函数,其数学表达式为:f(x) = 1 / (1 + exp(-x))。Sigmoid函数在二分类问题中常用作输出层的激活函数。
- Tanh函数:Tanh函数是一种将输入值压缩到-1和1之间的函数,其数学表达式为:f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))。Tanh函数在隐藏层中常用作激活函数。
- ReLU函数:ReLU函数是一种线性激活函数,其数学表达式为:f(x) = max(0, x)。ReLU函数在隐藏层中常用作激活函数,具有计算速度快和避免梯度消失的优点。
- Softmax函数:Softmax函数是一种将输入值转换为概率分布的函数,其数学表达式为:f(x) = exp(x) / sum(exp(x))。Softmax函数在多分类问题中常用作输出层的激活函数。
- 损失函数
损失函数是衡量BP神经网络预测结果与真实值之间差异的函数,用于指导网络的训练。常用的损失函数有:
- 均方误差(MSE):MSE是回归问题中最常用的损失函数,其数学表达式为:L = (1/n) * sum((y - ŷ)^2),其中y是真实值,ŷ是预测值,n是样本数量。
- 交叉熵损失(Cross-Entropy Loss):交叉熵损失是分类问题中最常用的损失函数,其数学表达式为:L = -sum(y * log(ŷ)),其中y是真实标签的独热编码,ŷ是预测概率。
- Hinge损失:Hinge损失是支持向量机(SVM)中常用的损失函数,用于处理线性可分问题。
- 优化算法
优化算法是BP神经网络训练过程中用于更新权重和偏置的算法。常用的优化算法有:
- 梯度下降(Gradient Descent):梯度下降是最常用的优化算法,通过计算损失函数关于权重和偏置的梯度,然后更新权重和偏置以最小化损失函数。
- 随机梯度下降(Stochastic Gradient Descent, SGD):SGD是梯度下降的一种变体,每次更新只使用一个样本或一个小批量样本,可以加快训练速度。
- 动量(Momentum):动量是一种优化威廉希尔官方网站 ,通过在梯度下降过程中加入动量项,可以加速收敛并避免陷入局部最小值。
-
拓扑结构
+关注
关注
6文章
323浏览量
39197 -
BP神经网络
+关注
关注
2文章
115浏览量
30551 -
非线性
+关注
关注
1文章
213浏览量
23078 -
神经元
+关注
关注
1文章
363浏览量
18450
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论