 神经网络前向传播和反向传播区别
神经网络前向传播和反向传播区别
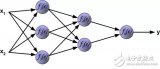
神经网络是一种强大的机器学习模型,广泛应用于各种领域,如图像识别、语音识别、自然语言处理等。神经网络的核心是前向传播和反向传播算法。本文将详细介绍神经网络的前向传播和反向传播的区别,以及它们在神经网络训练中的作用。
- 前向传播(Forward Propagation)
前向传播是神经网络中最基本的过程,它将输入数据通过网络层进行逐层计算,最终得到输出结果。前向传播的过程可以分为以下几个步骤:
1.1 初始化输入数据
在神经网络的输入层,我们将输入数据初始化为网络的输入。输入数据可以是图像、音频、文本等多种形式,它们需要被转换为数值型数据,以便神经网络进行处理。
1.2 激活函数
激活函数是神经网络中的关键组成部分,它为网络引入非线性,使得网络能够学习复杂的函数映射。常见的激活函数有Sigmoid、Tanh、ReLU等。激活函数的作用是对输入数据进行非线性变换,增加网络的表达能力。
1.3 权重和偏置
权重和偏置是神经网络中的参数,它们在训练过程中不断更新,以优化网络的性能。权重决定了输入数据在网络中的权重,而偏置则为网络提供了一个偏移量,使得网络能够更好地拟合数据。
1.4 矩阵运算
在神经网络中,每一层的输出都是通过矩阵运算得到的。矩阵运算包括加权求和和激活函数的计算。加权求和是将输入数据与权重相乘,然后加上偏置,得到当前层的输出。激活函数则对加权求和的结果进行非线性变换,得到最终的输出。
1.5 逐层传递
神经网络通常由多个隐藏层组成,每个隐藏层都会对输入数据进行处理。前向传播的过程就是将输入数据逐层传递,直到最后一层得到输出结果。
- 反向传播(Backpropagation)
反向传播是神经网络训练中的关键算法,它通过计算损失函数的梯度,更新网络的权重和偏置,以优化网络的性能。反向传播的过程可以分为以下几个步骤:
2.1 损失函数
损失函数是衡量神经网络性能的指标,它衡量了网络输出与真实标签之间的差异。常见的损失函数有均方误差(MSE)、交叉熵(Cross-Entropy)等。损失函数的选择取决于具体的任务和数据类型。
2.2 计算梯度
在反向传播中,我们需要计算损失函数关于权重和偏置的梯度。梯度是一个向量,它指示了损失函数在当前点的增长方向。通过计算梯度,我们可以知道如何调整权重和偏置,以减小损失函数的值。
2.3 链式法则
在神经网络中,由于存在多个层和激活函数,我们需要使用链式法则来计算梯度。链式法则是一种数学方法,它允许我们通过计算复合函数的导数,来得到每个单独函数的导数。在神经网络中,链式法则用于计算损失函数关于每个权重和偏置的梯度。
2.4 更新权重和偏置
根据计算得到的梯度,我们可以使用梯度下降算法来更新网络的权重和偏置。梯度下降算法的核心思想是沿着梯度的反方向更新参数,以减小损失函数的值。更新的幅度由学习率决定,学习率是一个超参数,需要根据具体任务进行调整。
2.5 迭代优化
神经网络的训练是一个迭代优化的过程。在每次迭代中,我们都会进行前向传播和反向传播,计算损失函数的梯度,并更新权重和偏置。通过多次迭代,网络的性能会逐渐提高,直到达到满意的效果。
- 前向传播与反向传播的区别
前向传播和反向传播是神经网络中两个不同的过程,它们在网络训练中扮演着不同的角色。以下是它们之间的主要区别:
3.1 目的不同
前向传播的目的是将输入数据通过网络层进行计算,得到输出结果。而反向传播的目的是计算损失函数的梯度,更新网络的权重和偏置,以优化网络的性能。
3.2 过程不同
前向传播是一个自上而下的过程,从输入层开始,逐层传递到输出层。而反向传播是一个自下而上的过程,从输出层开始,逐层传递到输入层。
3.3 参数更新
在前向传播中,网络的权重和偏置是固定的,不会发生变化。而在反向传播中,我们会根据计算得到的梯度更新网络的权重和偏置。
3.4 依赖关系
前向传播是反向传播的基础,反向传播需要前向传播的结果作为输入。在每次迭代中,我们都会先进行前向传播,然后进行反向传播。
-
神经网络
+关注
关注
42文章
4771浏览量
100720 -
数据
+关注
关注
8文章
7006浏览量
88947 -
图像识别
+关注
关注
9文章
520浏览量
38268 -
机器学习模型
+关注
关注
0文章
9浏览量
2569
发布评论请先 登录
相关推荐
解读多层神经网络反向传播原理
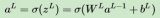






 工商网监
工商网监
评论