 从AI手机到AI PC,Arm拿什么打造AI盛宴?
从AI手机到AI PC,Arm拿什么打造AI盛宴?
电子发烧友网报道(文/黄晶晶)去年,Arm基于Armv9.2架构推出了Cortex-X4内核,更早前还有Cortex-X3/2/1内核。今年,Arm推出了第二代Armv9.2 CPU 集群,其中包括Cortex- X925,这一次并没有延用单个数字,如Cortex-X5这样的命名方式。在最近包括电子发烧友在内参与的Arm威廉希尔官方网站
媒体分享日期间,Arm威廉希尔官方网站
专家表示,Cortex-X925是Cortex-X推出以来取得最高IPC同比增幅的CPU,Arm想以此来清楚呈现其与前代产品的不同。与此同时,Cortex-X925 CPU与Immortalis-G925 GPU进行命名上的统一,以表明这些是真正的旗舰高端 IP,也是Arm终端CSS的基石。
Arm 终端计算子系统 (CSS) 作为最新的Arm计算平台,首次在终端领域为Arm CPU和GPU交付物理实现。此举也将使构建基于 Arm 架构的解决方案变得更加简单,确保万无一失。
联发科将基于Arm Cortex- X925 CPU和 Arm Immortalis-G925 GPU推出新一代天玑9400手机SoC。同时, Arm 也在与生态系统合作伙伴紧密合作,计划推出面向AI PC的处理器。前不久,Arm CEO公开表示希望Arm在5年内拿下50%的Windows PC 市场。这一切都将基于Arm最新的CPU和GPU以及着眼于未来数年发展的CSS来实现。
一个平台助力3nm芯片量产、端侧AI:Arm终端计算子系统
AI时代,生产力应用需要高性能平台来为高分辨率屏幕提供高刷新率;高端游戏应用已经采用了计算复杂型威廉希尔官方网站
,为用户带来视觉震撼的游戏体验;创意工作者正在不断开辟将手机用于专业摄影用例的无尽可能。这些用例需要强大的计算能力作为支撑,并且正在通过 AI 得到进一步增强。在终端设备上打造新一波具有突破性的端侧生成式 AI 体验,全新的计算平台能力必不可少。Arm最新推出的终端计算子系统(CSS) 聚焦于实现平台能力的重大飞跃,优先考虑了四个关键领域:突破性能边界以处理要求苛刻的安卓实际工作负载;针对生成式 AI 以及更广泛的 AI/ML 和计算机视觉工作负载提高性能;持续专注于实现两位数的系统能效提升;扩展平台以获得更高的性能点,满足新一代 AI PC 设备的需求(包括笔记本电脑和平板电脑)。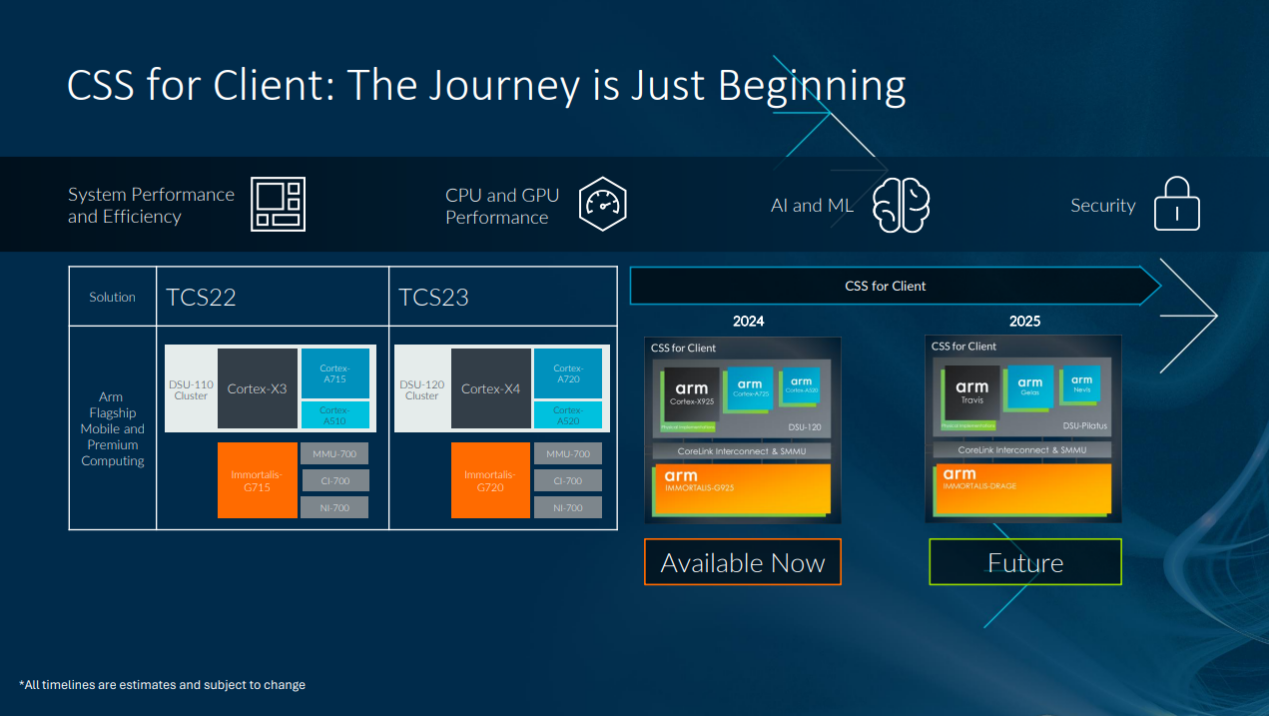
Arm终端CSS包括第二代 Armv9.2 CPU 集群,内含性能最强的 Arm Cortex-X — Cortex-X925 CPU 以及效率最高的 Cortex-A 核心——Cortex-A725 和更新后的 Cortex-A520 CPU,让三纳米工艺上的性能和效率达到全新水平。基于第五代 Arm GPU架构的全新GPU系列包括专为旗舰移动设备设计的 Arm Immortalis-G925,以及面向大众行业市场移动设备的 Arm Mali-G725和Mali-G625。
新的Arm终端CSS 物理实现面向超过3.6GHz的运行频率,并在先进的三纳米工艺上实现了一流的平台功耗、性能和面积 (PPA)。这些实现在多家代工厂可用,为合作伙伴提供更大的灵活性。适用于安卓系统的 CSS 参考软件栈搭配固定虚拟平台 (Fixed Virtual Platform, FVP),助力合作伙伴加速流片前的软件开发。
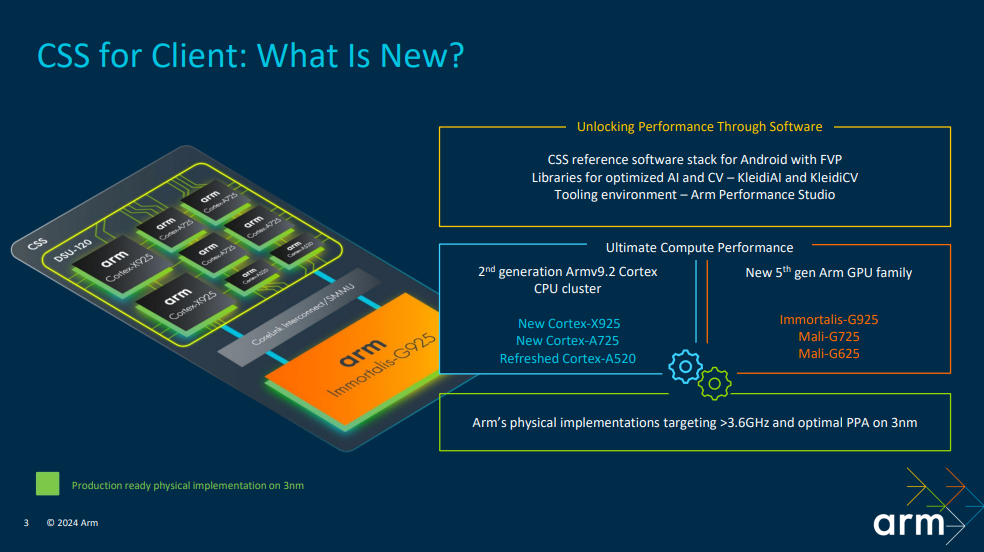
此外,全新 Arm Performance Studio 提供了全方位工具环境,帮助开发者简化开发流程,充分发挥 Arm 终端 CSS 的潜力。
Arm 终端事业部产品管理总监Steve Hopper详细解析了基于FPGA为终端CSS构建的内部参考平台上运行安卓软件栈的性能表现。他表示,作为Arm最快的安卓平台,终端CSS在基于 2+4+2(2个Cortex-X925 + 4个Cortex-A725 + 2个Cortex-A520)的CPU集群配置的表现来看,配置上包含第二个Cortex-X925是为了提高CSS 平台上重要用例的性能,如应用启动和 AI 性能。并且通过将 L3 缓存大小从 8MB 增加到 16MB,并在集群中所有核心之间共享,计算量大的工作负载实现进一步加速。

相比去年基于FPGA的安卓旗舰配置实现,2+4+2 CPU 集群将应用启动提速约 33%。通过集群的升级,包括额外的 Cortex-X 核心,并将 L3 缓存增加到 16MB,性能提升了约10%。对于 AI 大语言模型 (LLM),测量到终端 CSS 平台上词元 (Token) 首次响应时间,结果显著提升46%和42%。

Arm 终端 CSS同时致力于进一步推动移动端 LLM 性能的提升,使其成为端侧生成式 AI 体验的最佳平台。词元首次响应时间 (TTFT) 指标用以衡量生成首个响应词元的速度。通过终端 CSS、Cortex-X925 和 KleidiAI 威廉希尔官方网站
,对于具有 3.8B 参数模型的 Phi-3 的 TTFT,实现46%的显著提升;而对于具有 8B 参数的更大模型 Llama 3,TTFT 性能提高了惊人的42%。
对于 Immortalis-G925,在17 个主流 AI 网络(使用 fp16 数据类型)上观察到 AI 推理速度平均提高了 36%。Cortex-X925 CPU的推理速度与上一代 Cortex-X4 相比提升59%。通过利用一颗额外的 Cortex-X925 CPU,在 17 个主流 AI 网络中 int8 和 fp16 数据类型的 AI 推理时间大幅提升了170%。

可以说,作为一个可扩展平台,Arm 终端 CSS 为CPU 和 GPU 上的 AI 推理工作负载带来了显著的性能飞跃。这是硬件进步与 Arm Compute Library 优化相结合所产生的强大效果。
70%的第三方ML/AI应用运行在CPU上
Arm Cortex-X系列自2020年推出以来主要聚焦于优化提高单线程性能。Cortex-X1到X4的迭代都是如此。今年推出的Cortex-X925 CPU设计更具创新性。
“要实现优异性能,并非只涉及单个因素,要综合考虑每时钟周期指令数 (IPC)、频率、编译器、操作系统 (OS)、封装等多个方面。因此,我们革新设计理念,通过协同设计IP与物理解决方案,不仅实现量产就绪,而且具备领先的性能、功耗和面积 (PPA) 表现。”Arm终端事业部高级产品经理Manish Pandey说道。
基于以上设计理念,Arm正在改变Cortex-X CPU性能的发展轨迹。具体来看Arm Cortex-X925,它是Arm推出的迄今为止速度最快、性能最强的CPU。
通过结合前沿的微架构功能、可配置性和先进的物理解决方案,Cortex-X性能表现得到大幅提升。Cortex-X925的单线程性能提升36%(这有赖于对缓存大小、先进的功耗与热管理威廉希尔官方网站
,以及更新运行时Runtime选择上的进一步投入),AI 性能提高46%。

在先进的3nm工艺节点上Cortex-X925实现3.8GHz运行频率,使得下一代设备的 Geekbench得分提高30%以上。
Cortex-X925核心对端侧AI能力的提升显著,该核心优化AI的响应速度、网页浏览、图像和视频,以及更出色的高帧率游戏体验等。
在大语言模型 (LLM) 上,词元 (Token) 首次响应时间缩短约40%,同时在热门的 AI 网络中,推理速度提升高达 35%。这还只是ISO配置提升,再计入额外的缓存投入和工艺节点迁移提供的更高频率,能让设备实现更加出色的性能。
在功耗改进方面,在DVFS曲线的操作点上端,Cortex-X925在关键时刻达到峰值性能,这表现在设备响应速度显著提升。在操作点的中段范围内,Cortex-X925在给定的功耗范围内提升了性能,也就是在功耗和热设计受限的设备中能够实现更多功能。此外,在固定的计算需求下,Cortex-X925 降低了功耗,有助于延长电池续航时间。
Cortex-A700所对应的产品系列已经发展了14代,整个团队过去曾开发Cortex-A9(大约20年前的首个乱序执行 CPU)和 Cortex-A73(迄今出货量最高的乱序执行CPU)。现在,这个团队全面专注于 Cortex-A700 系列的性能效率。
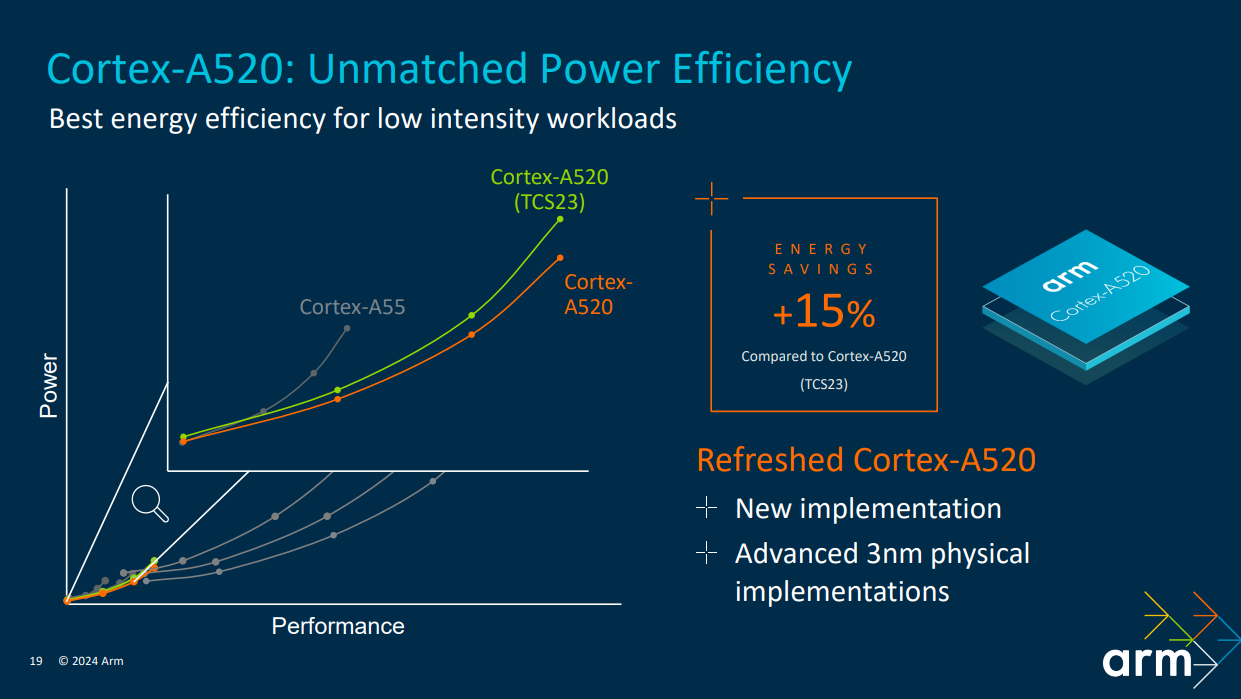
今年推出的Arm Cortex-A725,在性能效率设计上主要是满足持续的AI和游戏体验,以及为这条产品线在三纳米工艺上实现最佳的物理解决方案。Cortex-A725与去年的产品相比,能效提高25%。AI是高度线程化的,可以非常有效地在多核上运行更多的计算。通过提升25%的能效,可为整个核心提供余量。

Cortex-A520也做了更新。针对三纳米工艺的实现,对于Cortex-A520 来说同样比较复杂。通过更新实现流程,并与专用集成电路 (ASIC)/芯片团队紧密合作,以确保在保持微架构不变的情况下,Arm为合作伙伴提供最佳的三纳米工艺解决方案。
依据不同的终端应用,Cortex-X925、Cortex-A725、Cortex-A520这几个核在设计时可进行组合。DSU就起到将CPU IP高效协同的集群作用,同时DSU具有可扩展性。DSU作为一款特别的IP,它的性能指标包括缓存大小、带宽、延迟、漏电和动态功耗。今年,DSU-120 针对多个新用例进行了重点更新,聚焦在 PPA 和功耗方面的改善。
例如,机器学习 (ML)/AAA 游戏等用例对于缓存大小和缓存吞吐量较为敏感。而 AI 智能摄像头等用例则对缓存大小敏感度低,但对内存延迟更为敏感。而低强度线程的工作负载则对漏电比较敏感。DSU可以通过单个实现,达到动态应对不同用例的效果。
今年Arm在DSU中推出半切片断电模式 (Half Slice Powerdown),还为面向 RAM 新增了Quick Nap (QNap) 模式,QNap 模式是介于RAM运作 (Functional) 模式和保留 (Retention) 模式之间,可在不影响性能的前提下有效降低漏电。
Arm 终端事业部产品管理总监 Steve Hopper表示,由于CPU的易访问性,其通常是运行AI工作负载的首选目标,以安卓平台来看,目前70%的第三方 ML/AI 应用运行在CPU上。未来,在高端设备中 CPU、GPU和NPU三者相辅相成。但对于一些较低级别的设备来说,厂商可能很难承担NPU的费用,因此,CPU 往往是一个很好的运行此类工作负载的选择。
GPU:游戏与AI/ML兼得
Arm Immortalis-G925是Arm目前性能最强、效率最高的GPU,也是Arm终端计算子系统 (CSS) 的组成部分。
与Immortalis-G720相比,Arm终端CSS参考平台中的 Immortalis-G925在各种图形应用中的性能提高了37%;在运行AI/ML网络方面,性能显著提高了 36%。在提供与2023年参考平台相当的游戏性能时,Arm终端CSS中的 Immortalis-G925 能节省高达 30% 的功耗;而在对复杂对象进行光线追踪,其性能提升高达 52%。
安谋科技 (Arm China) 市场总监王刚分析,Immortalis-G925主要关注三个方面:实际环境中的游戏性能、AI/ML 性能,以及与生态合作伙伴的紧密协作。
在游戏性能方面,主流手游运行在采用 Immortalis-G925的Arm 终端 CSS 参考平台时,与去年的解决方案相比,性能平均提升了46%。以米哈游的《原神》为例,Arm 终端 CSS 使其性能提高49%。由腾讯光子工作室群和 KRAFTON 公司联合开发的《绝地求生手游》运行速度提升36%,《Roblox》更是大幅提升46%。此外,其他热门手游的性能也提升29% 到72%。这种代际的性能飞跃令人惊叹,对开发者和最终玩家来说具有重大意义。
前面提到许多AI运行在CPU上,但对于某些工作负载,如图像分割或物体检测,ML很适合在GPU上运行。Arm 持续提升GPU对 AI/ML 性能和效率的支持。
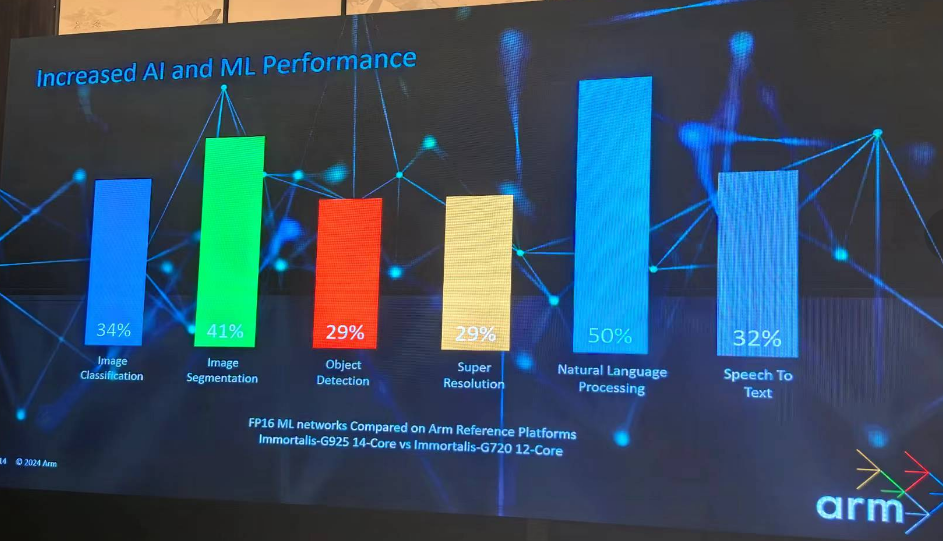
在图像处理(如分割或分类)方面,与去年的全面计算解决方案 (TCS) 相比,采用 Immortalis-G925的Arm 终端 CSS性能显著提升41%。在超级采样任务中,使用神经网络放大图像时,性能提升将近30%;在自然语言处理和语音转文本方面,获得50%性能提升。
现代手游愈发复杂,不仅在于着色器的复杂度,场景中的几何图形数量也呈爆炸式增长。过度绘制是场景中模糊不清的重叠像素数量,即在最终图像中实际不会看见的部分。Arm GPU具备多种威廉希尔官方网站
以减少过度绘制,进而减少到达片段着色阶段的原语数量。
此前为了有助于从 GPU 上获得更好的性能,一些应用可能会从前向后对不透明对象进行排序,这会增加CPU负载。Immortalis-G925引入了片段预处理 (Fragment Prepass) 的新机制,使得应用无需进行任何对象或原语排序。由于无需对象排序,渲染线程周期缩短了高达 43%。此外,片段预处理还可以更高效地减少过度绘制,进而提高性能和能效,同时减少应用的 CPU负载。
Immortatis-G925还改进了光线追踪威廉希尔官方网站
。在保持视觉准确性的同时,性能提高27%。开发者也可选择稍微降低场景处理中的透明度准确性,由此可带来 52% 的性能提升,并且降低 57% 的内存访问,进而能够大幅降低功耗。
Immortalis-G925 所支持的着色器核心数量增加50%,达到24个核心的最大配置,而上一代最多只有16个。为了实现这一性能目标,并确保能够支持所有着色器核心,Tiler 和命令流前端 (Command Stream Front-end, CSF) 等顶级单元都经过了调整和优化,以充分发挥 GPU 的性能。
Immortalis-G925具备硬件光线追踪,可配置10个以上的核心,适用于旗舰智能手机等设备。面向高端手机市场推出Mali-G725,可在6至9个核心之间扩展。此外,它还能提供与旗舰产品相同的API支持,同时为其他级别设备提供引人入胜的游戏体验。而适用于智能手表和入门级移动设备的Mali-G625可在1至5个核心之间扩展,提供广泛的性能支持。
小结:
Arm CPU内核性能的提升从Cortex-X925这个产品开始进行了设计理念的改变,这将影响未来数年的内核设计。同样,Arm Immortalis-G925 GPU也实现了大幅提升。更重要的是当处理器进入3nm工艺制程时,Arm终端CSS的发布为客户的芯片从设计到量产提供全方位的支持。这背后的一个巨大动力自然是AI,更确切地说是Arm要引领端侧AI,这一次不仅是手机,还将有PC以及其他未来可能的智能终端。
-
ARM
+关注
关注
134文章
9097浏览量
367653 -
AI
+关注
关注
87文章
30919浏览量
269172 -
AI PC
+关注
关注
0文章
123浏览量
251
发布评论请先 登录
相关推荐
AI PC芯片X86与Arm六四分?乾坤未定,竞争焦灼

Arm推出GitHub平台AI工具,简化开发者AI应用开发部署流程
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的威廉希尔官方网站 支撑学习心得
AI PC:真正的AI PC,敢于下场
risc-v多核芯片在AI方面的应用
开发者手机 AI - 目标识别 demo
联想4月18日发布AI PC新品,引领AI PC时代
AI PC产品密集发布,预计2025年AI PC占全球PC出货量40%

NanoEdge AI的威廉希尔官方网站 原理、应用场景及优势
新火种AI|全网热炒的“AI PC”,可能是个伪概念






 工商网监
工商网监
评论