 SoC芯片设计系列-ARM CPU子系统组件介绍
SoC芯片设计系列-ARM CPU子系统组件介绍
1、概述
在ARM架构的CPU子系统中,组件设计旨在高效地整合了多种功能模块,以支持处理器核心的运行、内存管理、中断处理、数据交换以及与外部设备的交互等。以下是ARM CPU子系统中的一些关键组件:
1. CPU Cores (处理器核心): 包括多个处理单元,如高性能的Cortex-A系列核心或高效能效核心,负责执行指令。
2. GIC (Generic Interrupt Controller): 管理中断请求,确保系统对事件做出快速响应,支持多级中断处理和虚拟化。
3. DSU (DynamIQ Shared Unit): 在具备DynamIQ威廉希尔官方网站 的SoC中,DSU管理共享资源,如L3缓存,优化多核通信和数据一致性。
4. Cache System: 包括L1 Cache(靠近核心的高速缓存,分指令和数据缓存),L2 Cache(更大,有时是多核共享)。
5. Memory Controller: 控制内存访问,如DDR控制器,管理与主存交互。6. AMBA总线: 如AMBA总线架构,提供系统内部组件间的通信,包括常见的AXI(Advanced eXtensible Interface)协议。
7. System Control Block: 负理系统复位、时钟、电源管理等初始化配置。
8. Security Features: 如TrustZone、加密引擎,确保系统安全。
9. Debugging and Trace: CoreSight、JTAGC等,方便调试和性能分析。
10. Connectivity and Peripherals: 包括USB、Ethernet控制器、显示接口、I2C、SPI等,以支持与外设别交互。
这些组件共同构成了复杂且高度集成的CPU子系统,支持现代计算平台的高效、低功耗、安全性以及可扩展性需求。
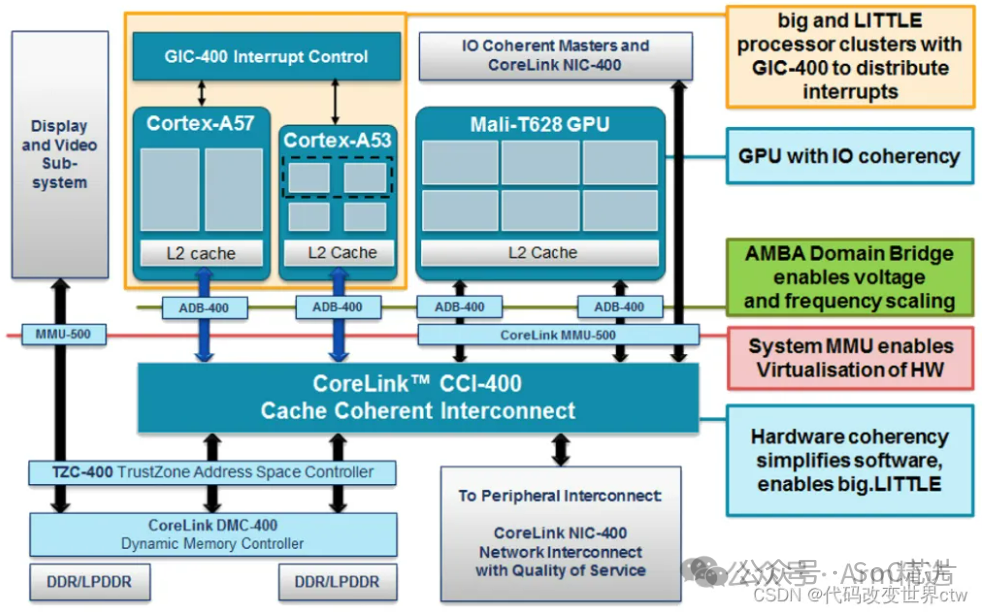
以下是一张比较早期的经典的bit-LITTLE的架构图。
2、CPU Cores
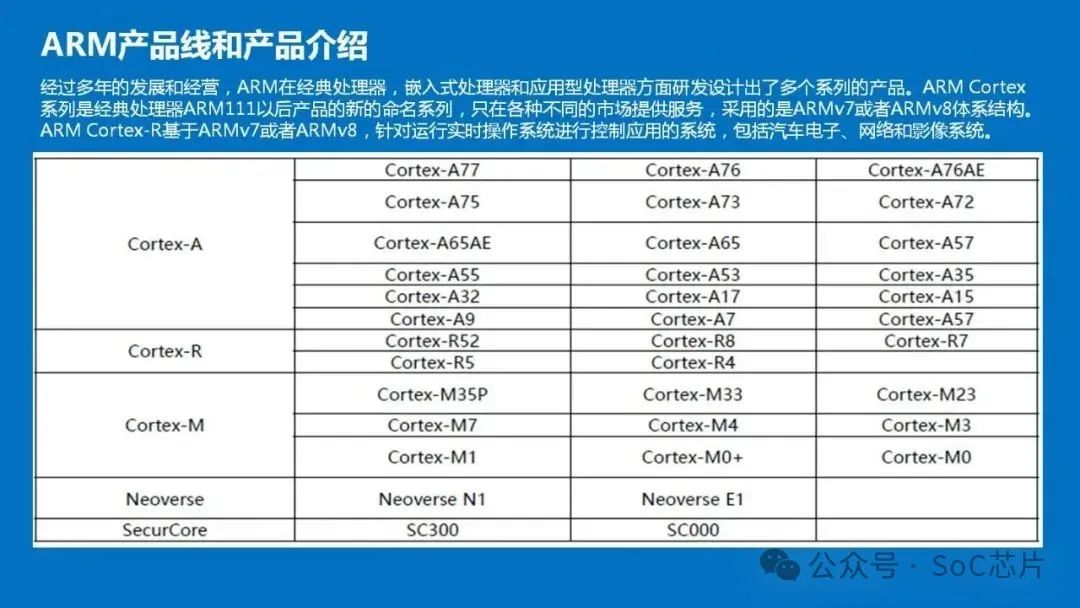
2.1终端芯片处理器
Arm架构是当今世界上最受欢迎的处理器架构之一,经过多年的发展和经营,ARM在经典处理器,嵌入式处理器和应用型处理器方面研发设计出了多个系列的产品。ARM Cortex系列是经典处理器ARM11以后产品的新的命名系列,只在各种不同的市场提供服务,采用的是ARMv7或者ARMv8体系结构,并分为三个系列,分别是Cortex-A,Cortex-R,Cortex-M。

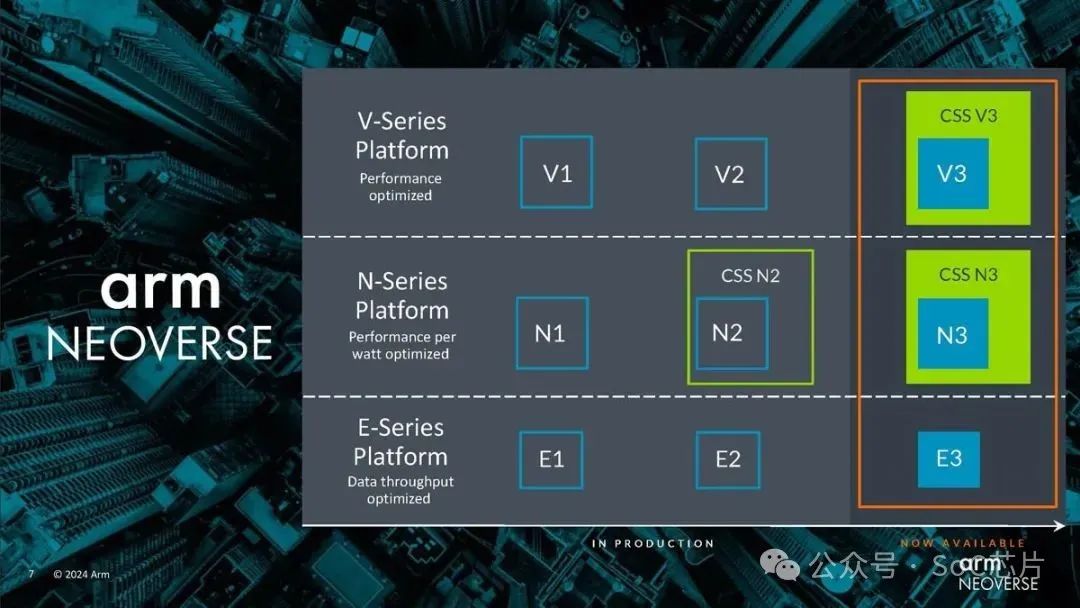
2.2服务器芯片处理器
2024年2月,Arm 推出了新的 Neoverse N3 和 V3 内核以及针对这两个内核的 CSS 产品。正如人们所期望的那样,Neoverse N3 更新了 N2,Neoverse V3 更新了 V2。CSS 是 Arm 的计算子系统,可提供更多预封装 IP,帮助公司更快地开发芯片或小芯片。
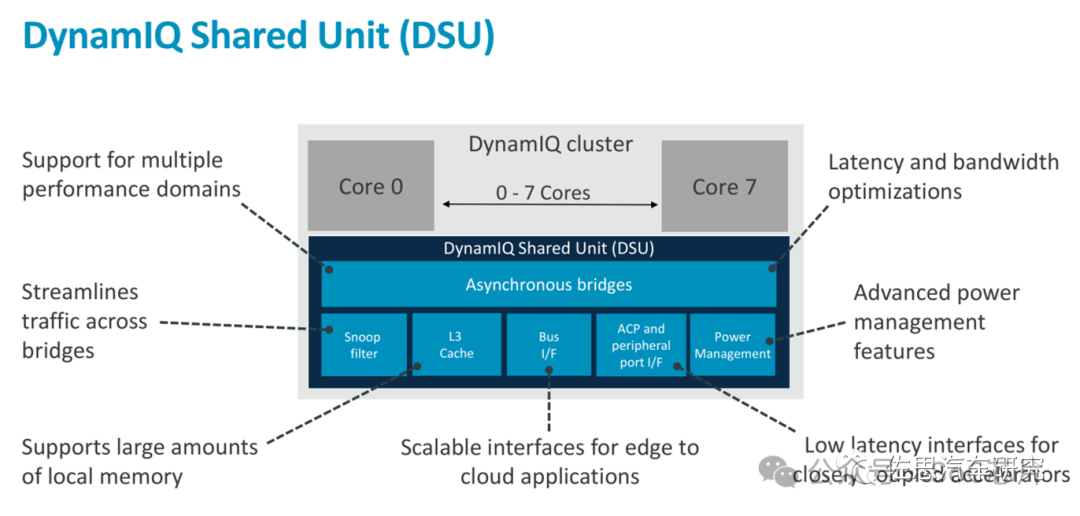
3、DynamIQ Shared Unit (DSU)
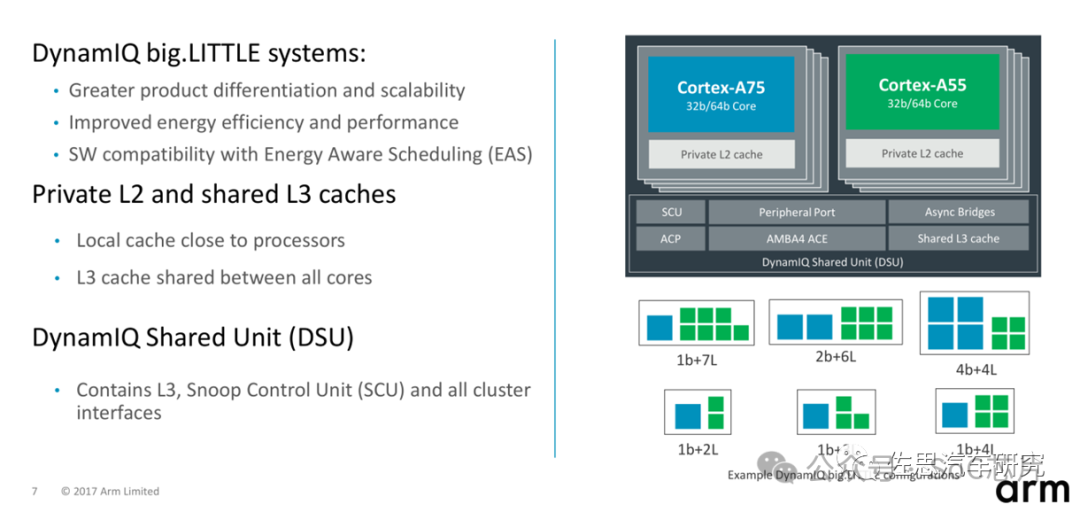
DynamIQ Shared Unit (DSU) 是ARM Cortex-A 系列列处理器中引入的一个关键组件,尤其是那些采用DynamIQ威廉希尔官方网站 的高端多核设计中,如Cortex-A57、Cortex-A53、Cortex-A72、Cortex-A73等。DSU在SoC(System-on-Chip)架构中扮演着至关重要的角色,其主要功能和特点包括:
1. L3缓存控制器:DSU集成L3缓存控制器,为整个CPU集群提供共享的、大容量的高速缓存,以减少对更慢速主存的依赖,提高数据交换效率。
2. 一致性管理:在多核处理器系统中,DSU负责维护缓存一致性,确保所有核心看到的数据是一致的,通过实施缓存一致性协议(如MESI、MOESI)来协调数据更新。
3. 数据共享与分配:DSU优化多核间的数据分配和共享,通过有效的缓存分配策略和传输机制,减少数据复制,提高数据访问效率。
4. 能效管理:作为SoC的一部分,DSU还可能集成能效管理机制,支持动态调整频率和电源状态,以平衡性能与能耗。
5. 系统互联:DSU通过高带宽、低延迟的内部总线与CPU核心、外设别、内存控制器等SoC组件相连,确保数据快速流动。
简言之,DynamIQ Shared Unit是DynamIQ架构中的一个核心组件,它通过提供共享缓存、缓存一致性管理、数据高效共享和能效优化,支持高性能、多核处理器系统中复杂数据处理和高效协作。
4、Snoop Control Unit(SCU)
Snoop Control Unit(SCU)是多处理器系统中的一个关键组件,特别是在包含缓存一致性设计中,如对称多处理机群集(SMP)或片上系统(SoC)中。其主要作用是维护缓存一致性,确保所有处理器核心对共享缓存的内容有统一的视图景,从而保证数据的一致性和正确性。SCU的工作机制通常包括以下方面:
1. 监听(Snooping): SCU监听所有处理器核心对共享缓存的访问请求,包括读取和写入操作。当一个核心试图修改缓存中的数据时,SCU介入以确保其他核心对该数据的缓存副本不会变得陈旧。
2. 缓存更新: 如果一个核心请求的数据在另一个核心的缓存中是脏(已修改但未回写回主存),SCU会促使持有该脏数据的核心将其写回到共享缓存或主存,然后更新请求核心的缓存,保证数据最新。
3. 一致性协议: SCU遵循一定的缓存一致性协议,如MESI(Modified, Exclusive, Shared, Invalid)、MOESI(Modified, Owner, Exclusive, Shared, Invalid)或其他协议,来决定如何响应缓存访问并维护一致性。
4. 广播与仲裁: 在多核系统中,SCU可能需要广播某些缓存操作,比如写操作,给所有核心,或仲裁缓存访问冲突,决定哪个核心优先级次序。
5. 目录管理: 在大型系统中,SCU可能配合缓存目录使用,目录存储哪个缓存行位于哪些地方,其状态,减少广播范围和提高效率。
综上所述,Snoop Control Unit是多处理器缓存一致性机制中的重要一环,通过监听和协调处理器间的缓存操作,确保数据的一致性,从而支持高效、可靠并行计算。
5、Coresight system
CoreSight架构是ARM公司为复杂系统级芯片(SoC)设计的调试和追踪解决方案,它提供了一个高度集成且可扩展的框架,用于系统级的调试、性能分析和优化。CoreSight架构旨在支持多核和多处理器环境,尤其是在面对现代嵌入式系统和高性能计算领域,其功能强大且灵活的特性能够显著提升开发效率和系统性能。以下是CoreSight架构的一些关键组成部分和功能:
1. 调试和追踪IP模块:•包括嵌入式追踪宏单元(ETM, Embedded Trace Macrocell, ETM)、系统追踪宏单元(STM, System Trace Macrocell, STM)、数据观看点单元(Data Watchpoint Unit, DWT)等,这些模块负责捕获程序执行时的指令流、数据访问、系统事件、性能计数等信息。
2. 跨触发接口 - CTI(Cross Trigger Interface, CTI):允许不同调试和追踪组件之间同步事件,支持复杂的系统级调试和性能分析。
3. 调试访问点 - DAP(Debug Access Port, DAP)和DP(Debug Port):提供调试接口,允许调试器通过串行线调试协议(如JTAG, SWD)访问系统。
4. 电源管理:支持系统级的动态电压和频率调整(DVFS),优化能效。
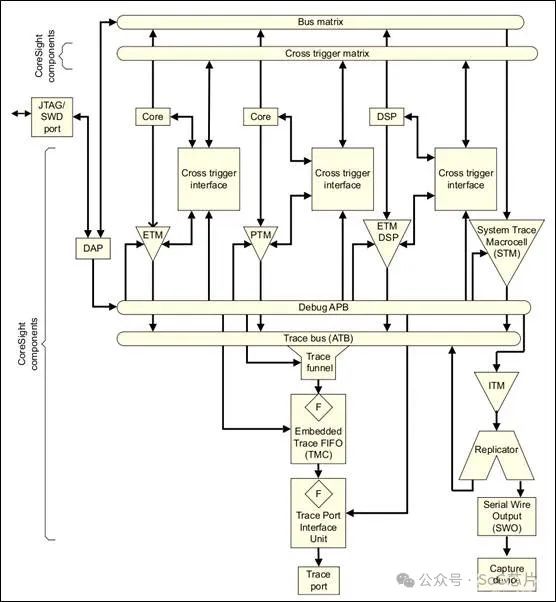
CoreSight架构的组件可按需组合,根据SoC的具体需求定制化集成,以达到最佳的调试、性能监控和系统优化效果,支持从简单的单核微控制器到复杂的多核服务器芯片的广泛应用。
6、System Memory Management Unit(SMMU)
ARM SMMU指的是ARM架构中的System Memory Management Unit,它是一种系统级的内存管理单元,主要负责地址转换和内存访问权限控制。在ARM架构中,SMMU主要用于处理非CPU核心的内存管理,尤其是外设别和硬件加速器的内存访问。与CPU核心中的MMU(管理虚拟地址到物理地址转换)类似,SMMU提供了对系统其他组件的内存访问控制,确保安全和高效的数据交互。特别地,ARM SMMU在不同场景下的应用和功能包括:
1. 外设别DMA访问隔离:SMMU通过配置映射表管理外设别DMA请求,确保其只能访问被授权的内存区域,防止非法或越界访问,增强了系统安全性。
2. 硬件加速器访问控制:对于硬件加速器(如GPU、网络加速器、加密加速器等),SMMU确保它们仅访问指定的内存区域,避免对系统关键数据的干扰,同时优化访问效率。
3. 虚拟化支持:在虚拟化环境中,SMMU为每个虚拟机提供独立的地址空间映射表,实现内存的隔离,保障虚拟机间不能互相干扰,提升了虚拟化平台的安全性和稳定性。
4. 中断处理:SMMU在某些实现中,如GICv3,可能间接参与中断路由和管理,特别是与中断的虚拟化处理,确保中断能被正确、高效地路由至目标处理器。
5. 内存属性管理:SMMU还可以控制内存访问属性,如是否缓存、共享与否、访问权限等,进一步细化内存管理,提升系统整体性能和安全性。组件与实现:•Stream Table:根表基地址寄存于寄存器中,是SMMU查找中断或DMA请求映射的起点。•Context Descriptor:描述符定义了第一阶段映射表的基地址,与第二阶段配置相关联。•Translation Tables:用于实际的地址转换,依据不同阶段的映射表结构,完成从虚拟到物理地址的映射。
综上,ARM SMMU是系统中一个关键的组件,它对内存访问的高效、安全控制和虚拟化支持至关重要,特别是在高性能、多核和异构计算系统中。
6.1. 什么是SMMU?
SMMU(system mmu),是I/O device与总线之间的地址转换桥。
它在系统的位置如下图:
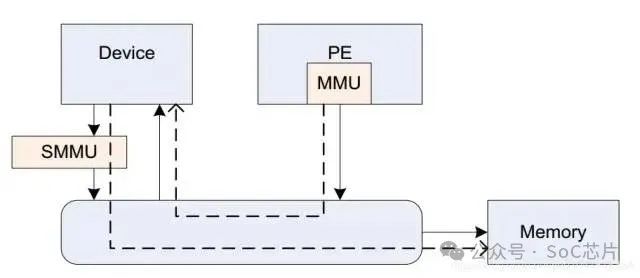
它与mmu的功能类似,可以实现地址转换,内存属性转换,权限检查等功能。
6.2. 为什么需要SMMU?
了解SMMU出现的背景,需要知道系统中的两个概念:DMA和虚拟化。
DMA:((Direct Memory Access),直接内存存取, 是一种外部设备不通过CPU而直接与系统内存交换数据的接口威廉希尔官方网站 。外设可以通过DMA,将数据批量传输到内存,然后再发送一个中断通知CPU取,其传输过程并不经过CPU, 减轻了CPU的负担。但由于DMA不能像CPU一样通过MMU操作虚拟地址,所以DMA需要连续的物理地址。
虚拟化:在虚拟化场景, 所有的VM都运行在中间层hypervisor上,每一个VM独立运行自己的OS(guest OS),Hypervisor完成硬件资源的共享, 隔离和切换。
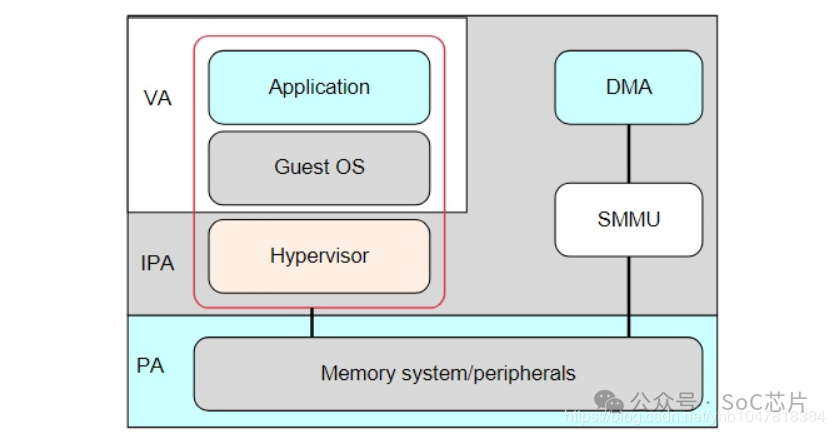
但对于Hypervisor + GuestOS的虚拟化系统来说, guest VM使用的物理地址是GPA, 看到的内存并非实际的物理地址(也就是HPA),因此Guest OS无法正常的将连续的物理地址分给硬件。
因此,为了支持I/O透传机制中的DMA设备传输,而引入了IOMMU威廉希尔官方网站 (ARM称作SMMU)。
总而言之,SMMU可以为ARM架构下实现虚拟化扩展提供支持。它可以和MMU一样,提供stage1转换(VA->PA), 或者stage2转换(IPA->PA),或者stage1 + stage2转换(VA->IPA->PA)的灵活配置。
*[VA:虚拟地址;IPA: 中间物理地址;PA:物理地址]
6.3. SMMU常用概念
术语 概念
StreamID 一个平台上可以有多个SMMU设备,每个SMMU设备下面可能连接着多个Endpoint, 多个设备互相之间可能不会复用同一个页表,需要加以区分,SMMU用StreamID来做这个区分( SubstreamID的概念和PCIe PASID是等效的)
STE Stream Table Entry, STE里面包含一个指向stage2地址翻译表的指针,并且同时还包含一个指向CD(Context Descriptor)的指针.
CD Context Descriptor, 是一个特定格式的数据结构,包含了指向stage1地址翻译表的基地址指针
4. SMMU数据结构查找
SMMU翻译过程需要使用多种数据结构,如STE, CD,PTW等。
4.1 SID查找STE
Stream Table是存放在内存中的一张表,在SMMU驱动初始化时由驱动程序创建好。
Stream table有两种格式,一种是Linear Stream Table, 一种是2-level Stream Table.
1. Linear Stream Table
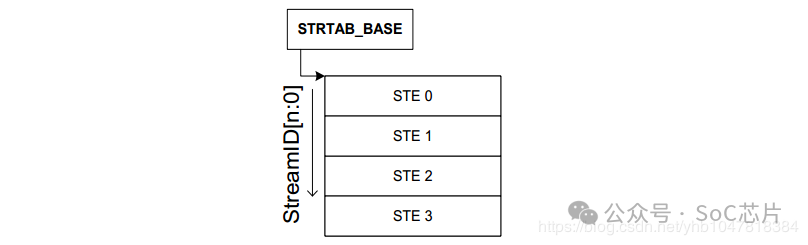
Linear Stream Table是将整个stream table在内存中线性展开成一个数组, 用Stream Id作为索引进行查找.
Linear Stream Table 实现简单,只需要一次索引,速度快;但是平台上外设较少时,浪费连续的内存空间。
2. 2-level Stream Table
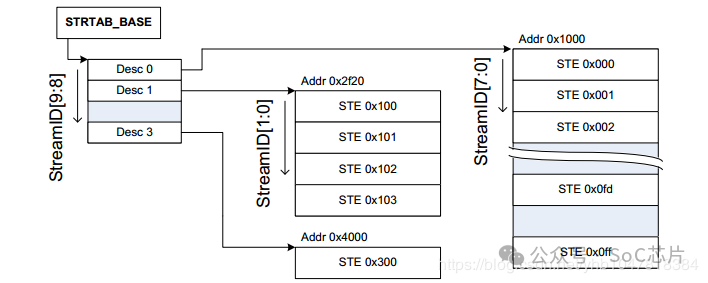
2-level Stream Table, 顾名思义,就是包含2级table, 第一级table, 即STD,包含了指向二级STE的基地址STD。第二级STE是Linear stream Table. 2-level Stream Table的优点是更加节省内存。
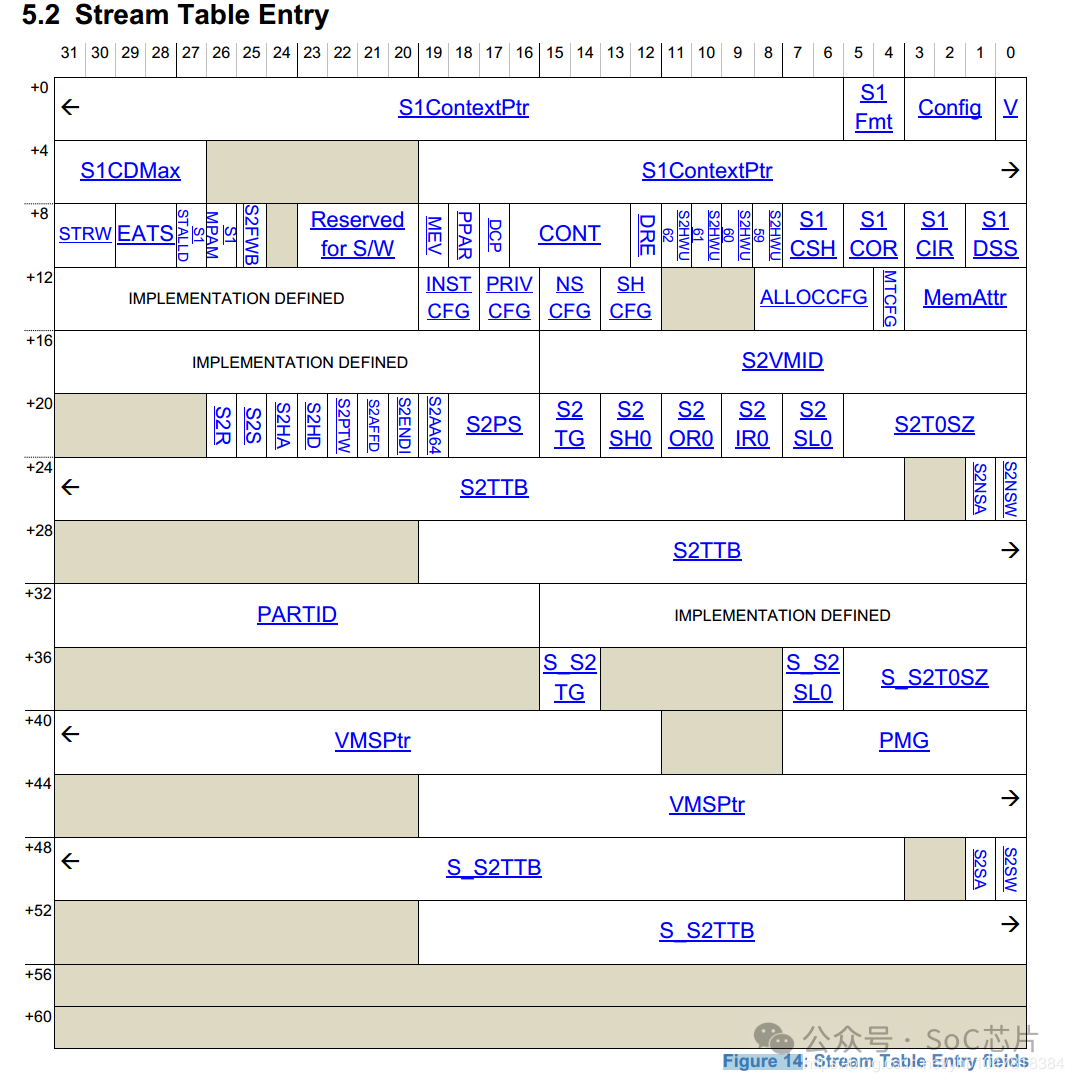
SMMU根据寄存器配置的STRTAB_BASE地址找到STE, STRTAB_BASE定义了STE的基地值, Stream id定义了STE的偏移。如果使用linear 查找, 通过STRTAB_BASE + sid * 64(一个STE的大小为64B)找到STE;若使用2-level查找, 则先通过sid的高位找到L1_STD(STRTAB_BASE + sid[9:8] * 8, 一个L1_STD的大小为8B), L1_STD定义了下一级查找的基地址,然后通过sid 找到具体的STE(l2ptr + sid[7:0] * 64).
最终找到的STE如下所示,表中的信息包含属性相关信息, 翻译模式信息(是否 stream bypass, 若否,选择stage1, stage2或者stage1 + stage2翻译模式)。
.2 SSID查找CD
CD包含了指向stage1地址翻译表的基地址指针.
如下图所示, STE指明了CD数据结构在DDR中的基地址S1ContextPTR, SSID(substream id)指明了CD数据结构的偏移,如果SMMU选择进行linear, 则使用S1ContextPTR + 64 * ssid 找到CD。如果SMMU选择2-level, 则使用ssid进行二级查找获得CD(与上节STE的方式一致)。
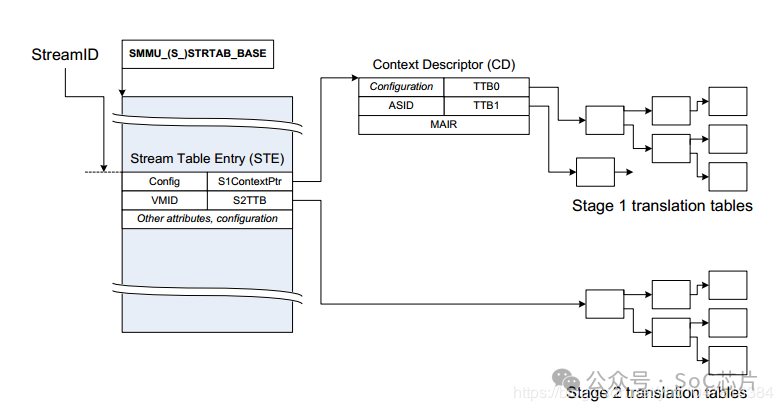
最终找到的CD如下所示:

表中信息包含memory属性,翻译控制信息,异常控制信息以及Page table walk(PTW)的起始地址TTB0, TTB1, 找到TTBx后,就可以PTW了。
5. SMMU地址转换
5.1 单stage的地址转换:
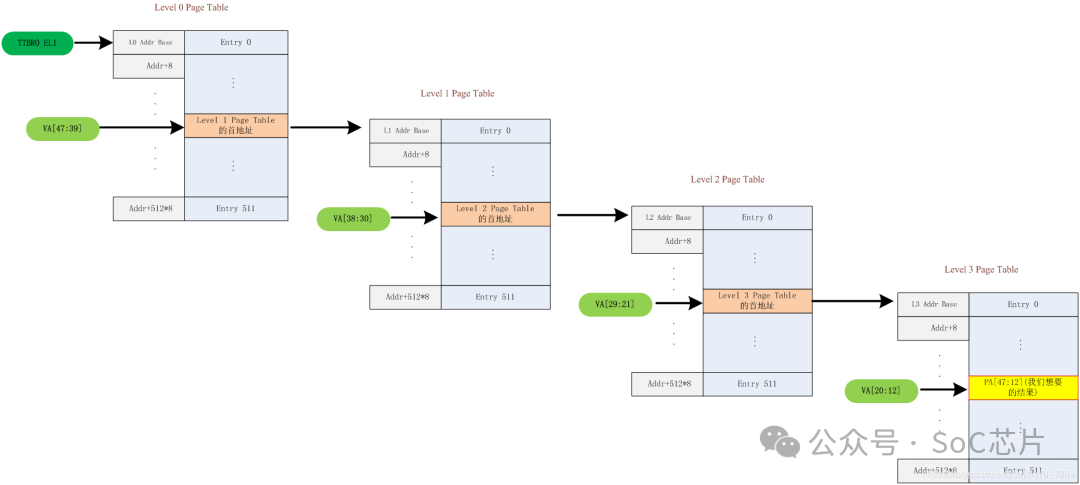
TTB 和 VA[47:39]组成获取Level0页表的地址PA;
Level0页表中的next-level table address 和 VA[38:30]组成获取Level1的页表地址PA;
Level1页表中的next-level table address 和 VA[29:21]组成获取Level2的页表地址PA;
Level2页表中的next-level table address 和 VA[20:12]组成获取Leve3的页表地址PA;
level3页表中的output address和va[12:0]组成获取组后的钻换地址
在stage1地址翻译阶段:硬件先通过StreamID索引到STE,然后用SubstreamID索引到CD, CD里面包含了stage1地址翻译(把进程的GVA/IOVA翻译成IPA)过程中需要的页表基地址信息、per-stream的配置信息以及ASID。在stage1翻译的过程中,多个CD对应着多个stage1的地址翻译,通过Substream去确定对应的stage1地址翻译页表。所以,Stage1地址翻译其实是一个(RequestID, PASID) => GPA的映射查找过程。
5.2 stage1+stage2的地址转换:
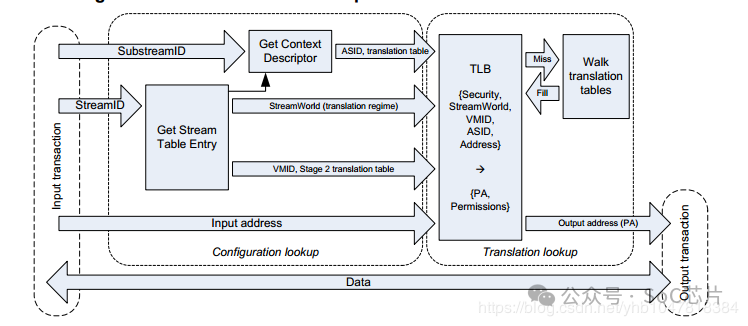
在使能SMMU两阶段地址翻译的情况下,stage1负责将设备DMA请求发出的VA翻译为IPA并作为stage2的输入, stage2则利用stage1输出的IPA再次进行翻译得到PA,从而DMA请求正确地访问到Guest的要操作的地址空间上。
在stage2地址翻译阶段:STE里面包含了stage2地址翻译的页表基地址(IPA->HPA)和VMID信息。如果多个设备被直通给同一个虚拟机,那么意味着他们共享同一个stage2地址翻译页表。
在两阶段地址翻译场景下, 地址转换流程步骤:
1.Guest驱动发起DMA请求,这个DMA请求包含VA + SID前缀
2.DMA请求到达SMMU,SMMU提取DMA请求中的SID就知道这个请求是哪个设备发来的,然后去StreamTable索引对应的STE
3.从对应的STE表中查找到对应的CD,然后用ssid到CD中进行索引找到对应的S1 Page Table
4.IOMMU进行S1 Page Table Walk,将VA翻译成IPA并作为S2的输入
5.IOMMU执行S2 Page Table Walk,将IPA翻译成PA,地址转化结束。
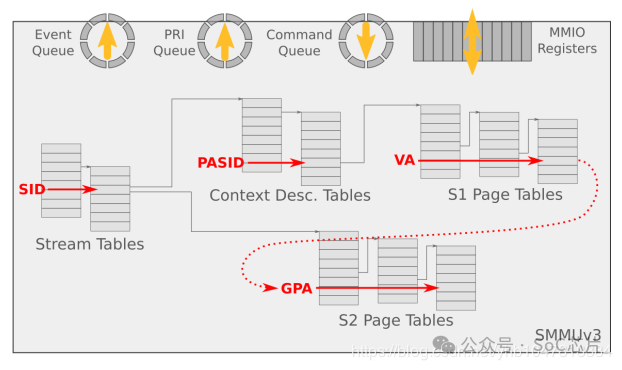
6. SMMU command queue 与 event queue
系统软件通过Command Queue和Event Queue来和SMMU打交道,这2个Queue都是循环队列。
Command queue用于软件与SMMU的硬件交互,软件写命令到command queue, SMMU从command queue中 地区命令处理。
Event Queue用于SMMU发生软件配置错误的状态信息记录,SMMU将配置错误信息写到Event queue中,软件通过读取Event queue获得配置错误信息并进行配置错误处理。
7、 GIC Controller
6.1 gic的版本号
§gic400,支持gicv2架构版本。
§gic500,支持gicv3架构版本。
§gic600,支持gicv3架构版本
§gic700, 支持gicv4.1架构版本
6.2 gic中断类型
GIC 分为不同类型的中断源:
§Shared Peripheral Interrupt (SPI) : 共享中断
§Private Peripheral Interrupt (PPI) : 私有中断
§Software Generated Interrupt (SGI) : 软件产生中断
§Locality-specific Peripheral Interrupt (LPI)
每个中断源都由一个 ID 号标识,称为 INTID。 前面列表中介绍的中断类型就是根据 INTID 的范围定义的:
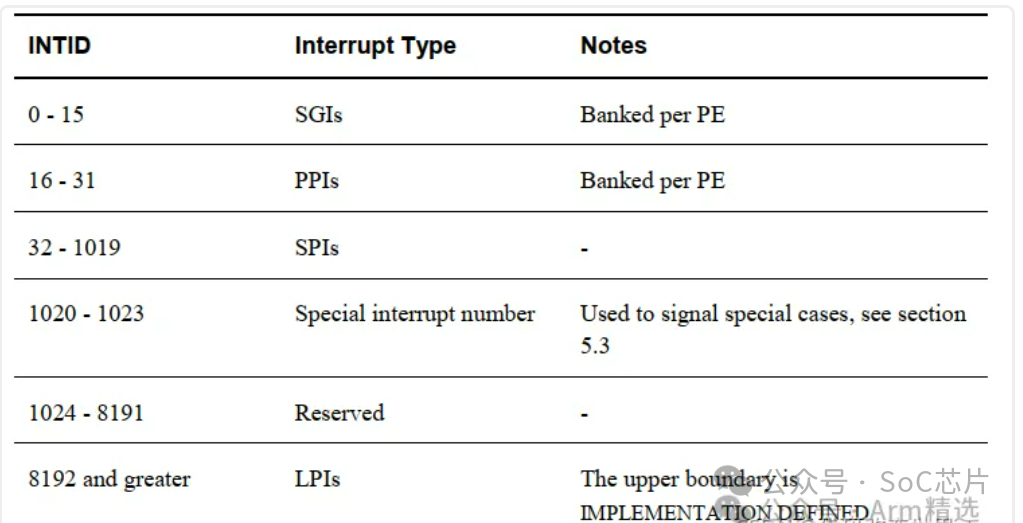
6.3 LPI介绍
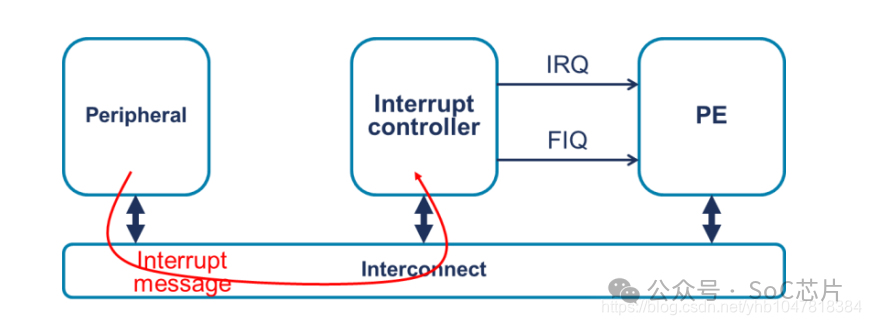
Locality Specific Interrupts(LPI),这是一个与GICv3及之后版本相关的概念。LPI中断是GIC架构中用来优化中断管理的一部分,特别是针对PCI Express (PCIe) 设备的中断处理,它与传统的共享中断线方法不同,提供了更高效的中断处理机制。以下是LPI的主要特点和工作原理:
1. 基于消息的中断:LPI中断不同于传统的硬件中断线机制,它基于消息传递,即中断信号通过写入内存中的特定地址(中断向量寄存器)来触发,而非通过物理线路。
2. 中断优化:LPI机制设计用于优化了中断处理,减少中断延迟和提高吞吐量,特别是在多核和虚拟化环境中。它避免了物理中断线的限制,简化了系统设计和扩展性。
3. 中断状态表:LPI中断的状态信息存储在内存中,GIC通过配置的中断状态表(Pending状态表)来跟踪这些中断,这允许快速查询和处理状态,减少了硬件开销耗。
4. GICv3及以后支持:GICv3开始引入了对LPI中断的直接注入支持,包括了中断状态表和中断配置寄存取址等,而GICv4在此基础上进一步优化,如支持虚拟中断直接注入到虚拟机。
5. 中断路由与优先级:LPI中断也涉及到中断的路由和优先级管理,GIC的Distributor组件会根据中断的属性和系统策略,决定如何路由到适当的CPU核心,以及处理的优先级。
综上所述,LPI在GIC框架下是针对高性能和高效中断处理的一个设计,特别是在现代的多核处理器和虚拟化系统中,它利用内存消息机制替代传统的硬件中断线,优化中断管理,提升了系统响应速度和效率。
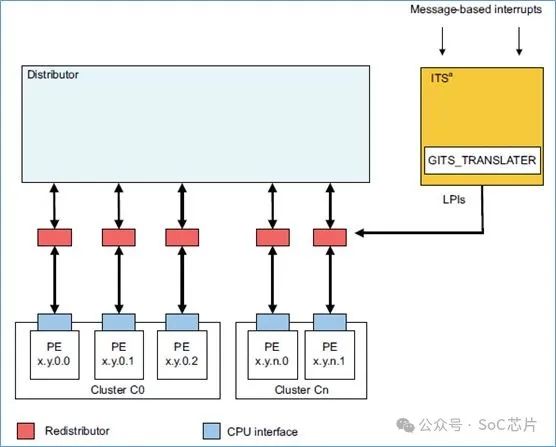
LPI,和SPI,PPI,SGI有些差别,LPI的中断的配置,以及中断的状态,是保存在memory的表中,而不是保存在gic的寄存器中的。
·GICR_PROPBASER:保存LPI中断配置表的基地址
·GICR_PENDBASER: 保存LPI中断状态表的基地址
这里,就涉及到两个表:
6.3.1 LPI中断配置表
该表,保存在memory中。基地址,由GICR_PROPBASER寄存器决定。

该寄存器描述如下:

其中的Physical_Address字段,指定了LPI中断配置表的基地址。
对于LPI配置表,每个LPI中断,占用1个字节,指定了该中断的使能和中断优先级。

当外部发送LPI中断给redistributor,redistributor首先要查该表,也就是要访问memory来获取LPI中断的配置。为了加速这过程,redistributor中可以配置cache,用来缓存LPI中断的配置信息。
因为有了cache,所以LPI中断的配置信息,就有了2份拷贝,一份在memory中,一份在redistributor的cache中。如果软件修改了memory中的LPI中断的配置信息,需要将redistributor中的cache信息给无效掉。
6.3.2 LPI中断状态表
该表,处于memory中,保存了LPI中断的状态,是否pending状态。
LPI中断的状态,不是保存在寄存器中,而是保存在memory中的pending表中。该状态表,由redistributor来进行更改。而该table的基地址,是由软件来设置的。
软件通过设置 GICR_PENDBASER 寄存器来设置。

该寄存器,设置LPI状态表的基地址,该状态表的memory的属性,如shareability,cache属性等。
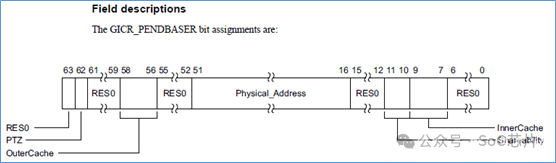
每个LPI中断,占用一个bit空间
·0: 该LPI中断,没有处于pending状态
·1: 该LPI中断,处于pending状态
该状态表,由redistributor来设置。软件如果修改该表,会引发unpredictable行为。
6.4 LPI的实现方式
为了实现LPI,gicv3定义了以下两种方法来实现:
·使用ITS,将外设发送到eventID,转换成LPI 中断号
·forwarding方式,直接访问redistributor的寄存器GICR_SERLPIR,直接发送LPI中断
6.4.1、forwarding方式
这种方式,比较简单,主要由下面几个寄存器来实现:
·GICR_SERLPIR
·GICR_CLRLPIR
·GICR_INVLPIR
·GICR_INVALLR
·GICR_SYNCR
其gic框图如下所示:
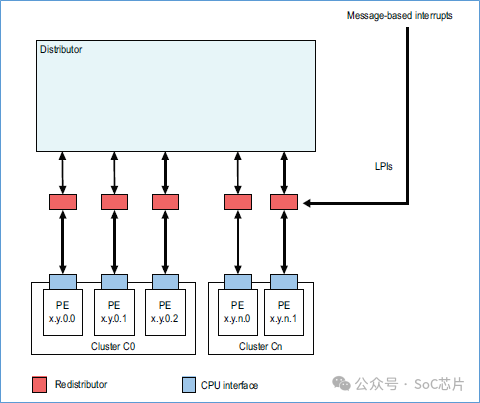
GICR_SERLPIR,将指定的LPI中断,设置为pending状态。

GICR_INVLPIR,将指定的LPI中断,清除pending状态。寄存器内容和GICR_SERLPIR一致。
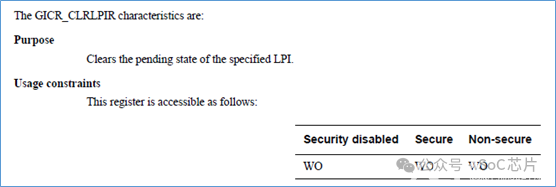
GICR_INVLPIR,将缓存中,指定LPI的缓存给无效掉,使GIC重新从memory中载入LPI的配置。
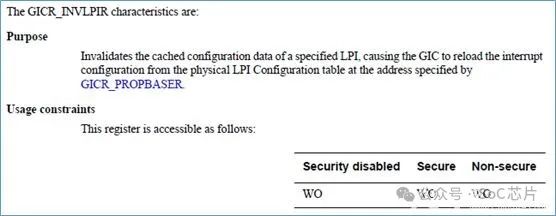
GICR_INVALLR,将缓存中,所有LPI的缓存给无效掉,使GIC重新从memory中,载入LPI中断的配置。
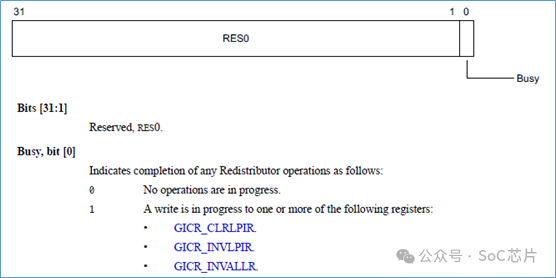
GICR_SYNCR,对redistributor的操作是否完成。

寄存器,只有第0bit是有效的。如果为0,表示当前对redistributor的操作是完成的,如果为1,那么是没有完成的。
6.4.2、使用ITS方式
理解了forwarding方式,那么理解ITS方式,就要容易了。forwarding方式,是直接得到了LPI的中断号。
但是对于ITS方式,是不知道LPI的中断号的。需要将外设发送的DeviceID,eventID,通过一系列查表,得到LPI的中断号以及该中断对应的target redistributor,然后将LPI中断,发送给对应的redistributor。
下图是带有ITS的gic框图:
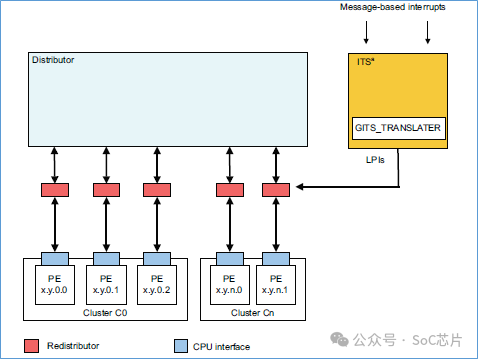
外设,通过写GITS_TRANSLATER寄存器,发起LPI中断。写操作,给ITS提供2个信息:
·EventID:值保存在GITS_TRANSLATER寄存器中,表示外设发送中断的事件类型
·DeviceID:表示哪一个外设发起LPI中断。该值的传递,是实现自定义,例如,可以使用AXI的user信号来传递。
ITS将DeviceID和eventID,通过一系列查表,得到LPI中断号,再使用LPI中断号查表,得到该中断的目标cpu。
ITS将LPI中断号,LPI中断对应的目标cpu,发送给对应的redistributor。redistributor再将该中断信息,发送给CPU。
6.5 ITS组件
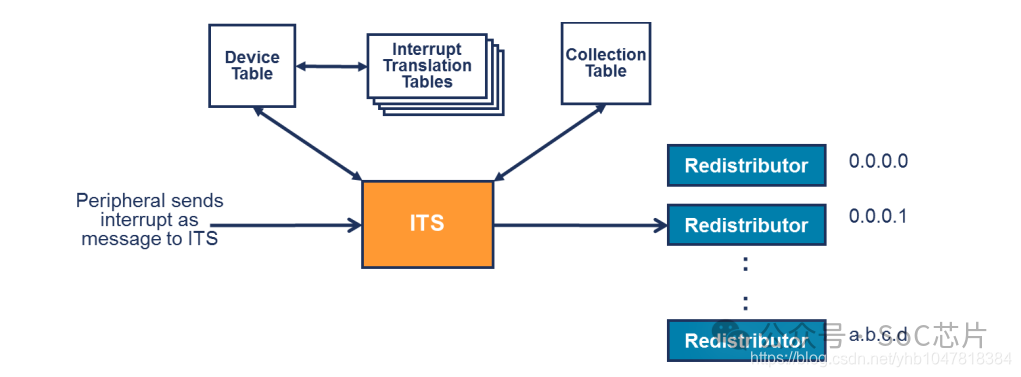
ITS(Interrupt Translation Service)是GICv3及之后版本中引入的一项高级特性,特别针对PCI Express (PCIe) 系统的中断处理进行了优化。以下是GIC的ITS的主要工作原理和功能:
1. 中断转换与路由优化:ITS的主要职责是将PCIe的Message Signaled Interrupts (MSI) 转换为系统内部中断ID,进而路由到适当的CPU核心。这一转换过程优化了中断的分配,尤其是对于多核处理器和虚拟化环境中的中断路由。
2. 高效中断处理:通过硬件加速中断的翻译和路由,ITS降低了中断处理延迟,提高了系统响应速度,特别是在处理大量中断的场景下,如数据中心、高性能计算和网络设备。
3. 中断虚拟化支持:在虚拟化环境中,ITS可以更高效地重定向中断到正确的虚拟机,支持中断隔离和虚拟中断的灵活管理,增强虚拟化平台的性能和可扩展性。
4. 中断表管理:ITS维护一个中断转换表,存储了中断源到中断ID的映射关系,以及相关的优先级和路由信息。这个表支持动态更新,允许系统根据需要调整中断配置。
5. 硬件辅助的中断分配:GIC的Distributor组件与ITS协同工作,确保中断被高效地分配给CPU Interface,而CPU Interface负责中断的发送EOI(End of Interrupt)信号,告知中断已处理完毕,完成循环。
GIC的ITS特性是现代中断处理威廉希尔官方网站 的一个重要进展,它提高了中断处理的效率、灵活性和可扩展性,特别是在复杂的多核处理器和虚拟化系统中,确保了中断处理的高效和及时响应。
6.5.1、ITS处理流程
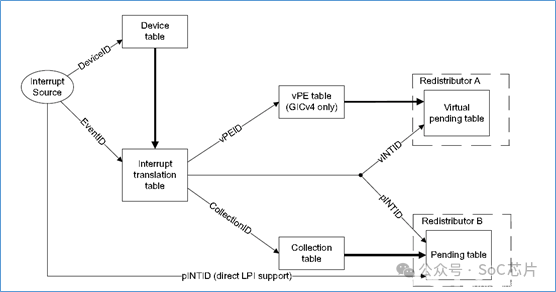
ITS使用三类表格,实现LPI的转换和映射:
·device table: 映射deviceID到中断转换表
·interrupt translation table:映射EventID到INTID。以及INTID属于的collection组
·collection table:映射collection到redistributor
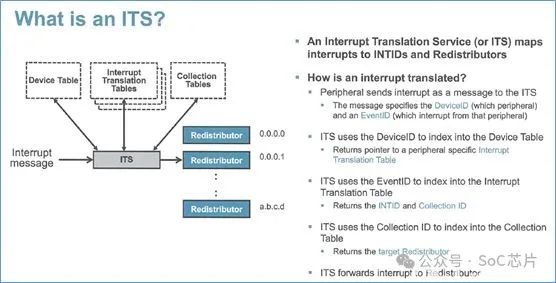
当外设往GITS_TRANSLATER寄存器中写数据后,ITS做如下操作:
·使用DeviceID,从设备表(device table)中选择索引为DeviceID的表项。从该表项中,得到中断映射表的位置
·使用EventID,从中断映射表中选择索引为EventID的表项。得到中断号,以及中断所属的collection号
·使用collection号,从collection表格中,选择索引为collection号的表项。得到redistributor的映射信息
·根据collection表项的映射信息,将中断信息,发送给对应的redistributor
以上是物理LPI中断的ITS流程。虚拟LPI中断的ITS流程与之类似。以下是处理流程图:
6.5.2、ITS命令
ITS操作,会涉及到很多表,而这些表的创建,维护是通过ITS命令,来实现的。虽然这些表,是在内存中的,但是GICv3和GICv4,不支持直接访问这些表,而是要通过ITS命令,来配置这些表。
ITS的操作,是通过命令,来控制的。外部通过发送命令给ITS,ITS然后去执行命令,每个命令,占32字节。
ITS有command队列,命令写在这个队列里面。ITS会自动的按照队列顺序,一一执行。
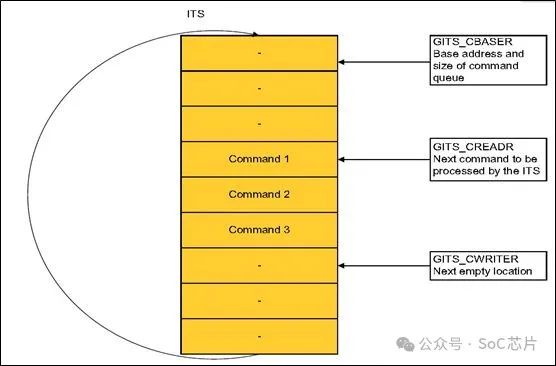
每个命令占32个字节。
命令,存放在内存中,GITS_CBASE,保存命令的首地址。GITS_CREADR,是由ITS控制,表示下一个命令的地址。GITS_CWRITER,是下一个待写命令的地址。软件往GITS_CWRITER地址处,写入命令,之后ITS就会执行这个命令。
ITS提供的命令,有很多,可以查阅GIC手册获取更多。
以下是CLEAR命令。

6.5.3、ITS table
ITS包括很多个表,这些表均处于 non-secure区域。
GITS_BASER,指定ITS表的基地址和大小。软件,在使用ITS之前,必须要配置。
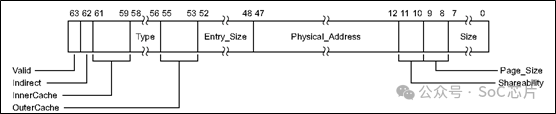
其中的Physical_Address字段,就指定了表的基地址所在位置。
以下是各个表的基地址,对应的寄存器。

审核编辑:刘清
-
控制器
+关注
关注
112文章
16334浏览量
177815 -
DDR
+关注
关注
11文章
712浏览量
65318 -
ARM处理器
+关注
关注
6文章
360浏览量
41723 -
SoC芯片
+关注
关注
1文章
610浏览量
34905 -
Cortex-A
+关注
关注
0文章
20浏览量
34266
原文标题:SoC芯片设计系列---ARM CPU子系统组件介绍
文章出处:【微信号:gh_9d9a609c9302,微信公众号:SoC芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ARM系列之PCSA资料介绍
ARM GIC(一)之ARM soc中断的处理介绍
基于ARM处理器的SOC系统讲解
Arm Corstone SSE-700子系统威廉希尔官方网站 参考手册
Arm Corstone SSE-123子系统威廉希尔官方网站 参考手册
Arm Corstone™ SSE‑123子系统威廉希尔官方网站 概述
Arm Corstone SSE-710子系统威廉希尔官方网站 参考手册
Arm CoreLink™ SSE-200嵌入式子系统威廉希尔官方网站 概述
基于ARM7TDMI的SoC中MP3子系统的设计
ARM是什么意思,arm与cpu是什么关系
ARM Architecture, Core, CPU,SOC概念简明介绍资料下载






 工商网监
工商网监
评论