 探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究
随着信息威廉希尔官方网站
的迅猛发展,存算一体威廉希尔官方网站
逐渐成为计算领域的研究热点。在这一领域,基于SRAM(静态随机存取存储器)和MRAM(磁性随机存取存储器)的存内计算和存算一体架构日益受到重视,为计算性能和能效带来了新的可能性。本文将深入探讨这两种威廉希尔官方网站
的原理、优势及其在不同领域的应用,旨在为读者提供对存算一体威廉希尔官方网站
发展趋势的全面了解。
一.基于 SRAM 的存内计算
在信息威廉希尔官方网站 的不断发展中,SRAM存内逻辑计算威廉希尔官方网站 日益成为研究的焦点。自2016年Jeloka等人提出了基于SRAM的存内逻辑计算以来,这一领域取得了长足的进步。该威廉希尔官方网站 不仅仅局限于逻辑运算,还应用于神经网络的硬件加速,为计算领域带来了全新的可能性。
SRAM的逻辑运算是通过激活同一列的多个存储单元来实现的。这些存储单元的字线被同时激活,通过灵敏放大器感测位线电压,得到存储单元存储比特的逻辑运算结果。在增加额外的逻辑门后,SRAM可以实现逻辑或非和逻辑与非运算。与传统的SRAM阵列相比,新的阵列具有更高的密度和更低的功耗,为存内计算提供了更广阔的发展空间。
在这一领域的持续探索中,研究者们提出了更多创新的SRAM存内计算架构。例如,Aga等人提出了一种新的存内计算架构,通过添加解码器和使用单端灵敏放大器实现了逻辑异或运算。而Dong等人则提出了一种4+2T的SRAM单元,相比传统的6T SRAM单元具有更好的噪声容限。
针对传统6T SRAM单元存在的读写干扰和存储内容翻转等问题,研究者们提出了8T和10T SRAM单元。Agrawal等人则提出了使用8T SRAM单元和8+T SRAM单元的解耦读写路径,成功实现了存内布尔运算,包括逻辑与非、逻辑或非、逻辑异或等逻辑运算。相比于6T SRAM单元,8T SRAM单元提高了数据的吞吐量和处理速度,为计算性能带来了明显的提升。

一些研究者还探索了SRAM单元与算术电路协同的架构,例如Rajput等人提出了一种8T SRAM单元与算术电路协同的架构,具有更高的能量利用率和读取裕量。
基于SRAM的存内逻辑计算威廉希尔官方网站
不断创新,为计算领域带来了更高的性能和更低的功耗。随着这一威廉希尔官方网站
的不断发展,我们有理由期待它在未来的计算应用中发挥更加重要的作用。
二.基于 SRAM 的存内计算在神经网络的应用
近年来,深度学习威廉希尔官方网站
在神经网络领域蓬勃发展,但由于常规训练通常依赖于高功耗的CPU或GPU,因此功耗问题成为制约其应用的重要因素。然而,随着超大规模集成电路制造业的飞速进步,嵌入式系统逐渐成为研究的热点。嵌入式系统以其低功耗和小占用面积的特点,成为解决目标检测等问题的理想选择。
在嵌入式神经形态处理系统的发展中,基于忆阻器的神经形态计算体系架构引起了广泛关注。多种基于忆阻器的神经形态计算体系架构相继被提出。例如,Sun等人提出了一种基于忆阻器的神经形态计算架构,实现了三层全并行卷积神经网络(FP-CNN)。而在此基础上,Sun等人将其作为基本计算单元提出了一种级联神经网络体系架构。Yakopcic等人则提出了一种基于忆阻器的卷积神经网络,利用多个忆阻器交叉阵列实现。
尽管这些方法在网络架构方面取得了显著成效,但当忆阻器阵列存在低良率问题时,其性能却会受到明显影响。为此,本文提出了一种基于忆阻器的神经形态计算方法,结合了提高忆阻器阵列乘累加计算准确率的校准方法和可减少训练误差的原位训练方法,从而能够提高网络在低良率阵列中的识别率。
这一方法的提出将为嵌入式神经计算带来全新的可能性,不仅能够提高计算准确率,还能在较低的功耗下实现更为稳健的性能表现。随着该方法的进一步研究和应用,我们有信心在嵌入式神经计算领域迈出更加坚实的步伐,为智能计算的未来铺平道路。
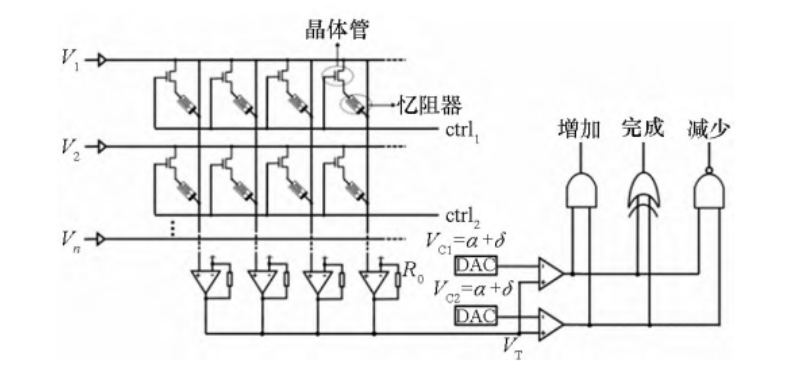
一种编程忆阻器交叉阵列的电路如下图:
2.1 神经网络算法(BNN)
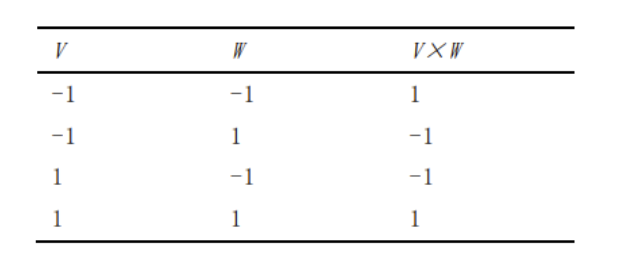
神经网络算法中,乘加计算是最为频繁的操作之一。为了应对计算需求与功耗之间的平衡,研究者们提出了二值化神经网络(BNN),将输入和权重进行二值化,限定为1或-1。这种二值化使得基于SRAM的乘法运算可以被视为逻辑同或运算。然而,使用一位二值权重可能会导致较大的精度损失,因此研究者们将注意力转向了并行计算,以实现多位权重运算。
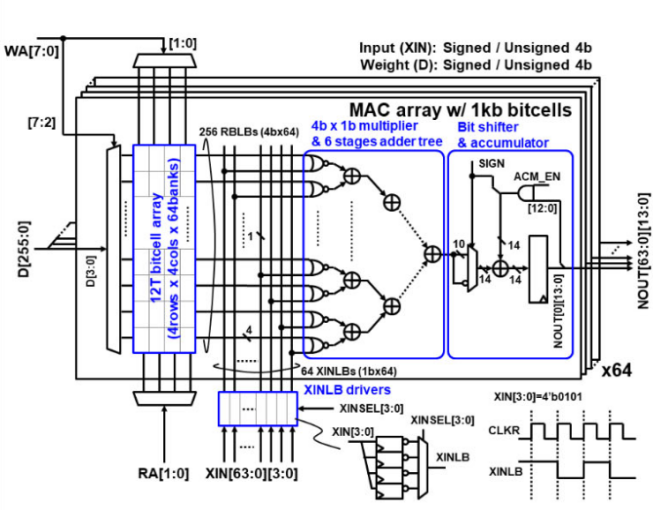
一种被提出的并行计算结构包括WL开关矩阵用于激活多行字线,闪存ADC的多电平检测器(MLSA)以及生成基准电压的参考生成器。另一种基于6T SRAM的双拆分结构实现了完全并行的乘积和累加计算,取得了显著的效果。该架构不仅可以实现全连接层的计算时间达到2.3 ns,而且能效最高可达55.8 TOPS/W。然而,这种架构使用了大量的晶体管,导致了较大的面积。
乘法真值表如下。
Nguyen等人提出了用于DNN存内计算的10T SRAM,并设计了整体架构,成功映射了LeNet-5手写数字识别网络。该架构支持完全并行的乘加计算,并且实现了4位权重、4位输入、8位输出的乘加操作。另外,Su等人提出了可用于2到8位运算的双向转置6T SRAM,支持神经网络推理和训练的过程。
此外,为了进一步降低功耗,研究者们还研究了稀疏性处理。Han等人提出了一种基于8T SRAM的DNN加速器,不仅具有前向传播和后向传播功能,还具有稀疏性处理功能。通过只存储非零值及其地址的方式来过滤零值,使得不必要的计算被跳过,最终实现了功耗上的降低。
在国内外,许多优秀团队也为SRAM的存内计算做出了贡献。他们提出了各种创新的方法和结构,如无乘法函数逼近器、更高线性度和吞吐量的SRAM单元、无ADC的动态SRAM架构等,以加速神经网络的计算过程并降低功耗。这些研究成果为神经网络计算的进一步优化提供了重要的参考和启示。
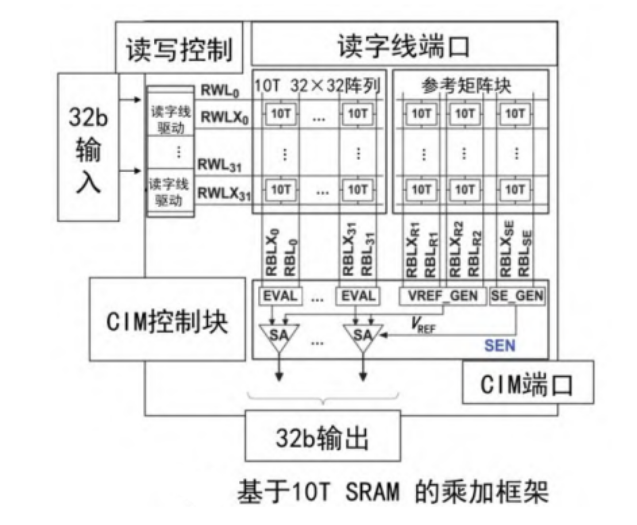
如下图所示,这种架构通过在一个32×32的10T SRAM阵列中输入32个输入向量,将输入向量与权重矩阵做乘法运算。在同一列上的所有SRAM单元的位线上的电流被求和并转换成interwetten与威廉的赔率体系 电压,在敏感放大器模块中将此模拟电压与参考电压进行对比,生成数字信号的输出。参考电压由3列10T SRAM组成的参考阵列块生成,同时此参考阵列块还产生检测放大器SA的检测使能信号。通过这样的方式,完成了矩阵和向量之间的乘加运算。
这种架构是通过28纳米CMOS工艺实现的,具有高能效和高吞吐量的优势。这意味着它在进行神经网络计算时能够以更低的功耗和更高的效率完成任务,从而提高了整个系统的性能表现。
三.基于 MRAM 的存算一体
基于MRAM(磁性随机存取存储器)的存算一体(MRAM-in-Memory Computing)是一种新型的计算模式,它结合了内存和计算的功能,利用MRAM的非易失性和快速读写特性,在存储器内部进行计算操作,从而提高计算效率和能源利用率。
MRAM作为一种新型的存储威廉希尔官方网站 ,具有快速的读/写速度、低功耗和非易失性等优点。这些特性使得MRAM非常适合用于存算一体的应用。在存算一体中,计算任务可以直接在MRAM中进行,而无需将数据从存储器传输到CPU进行处理,从而减少了数据传输的延迟和能耗。
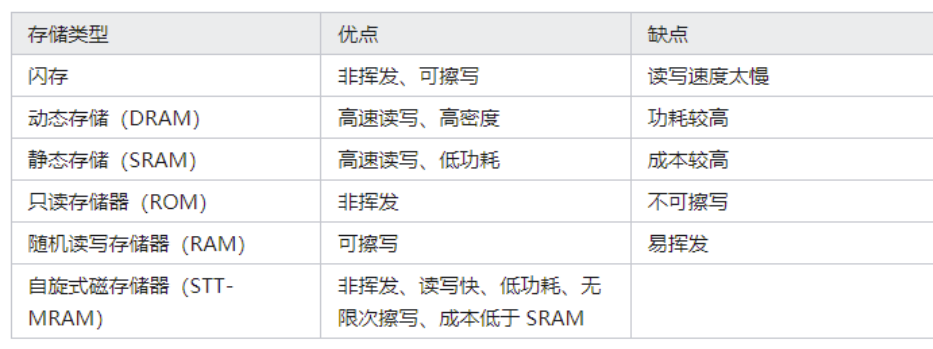
MRAM 与其他类型存储器相比具有明显优势。下表列出几种不同类型的存储器优缺点比较:
通过将计算操作与存储操作结合在一起,存算一体架构可以实现更高效的数据处理。例如,对于机器学习应用,可以在MRAM中进行矩阵乘法等计算密集型操作,而无需将数据移动到CPU或GPU。这样可以大大减少数据传输的时间和能耗,提高系统的整体性能。
此外,存算一体还可以降低硬件系统的复杂性,减少了CPU和存储器之间的通信带宽需求,简化了系统架构,降低了成本。
自旋芯片被认为具有SRAM的高速度、DRAM的高密度以及Flash的非易失性等优点,这一观点得到了中国科学院院士、南京大学物理系教授和博士生导师的认同。此外,自旋芯片的抗辐射性也备受军方青睐,使其原则上可以取代当前各类存储器,成为未来的通用存储器。
鲁汶仪器的一位员工介绍称,目前,MRAM主要在军工、大数据高性能存储等领域有一些应用。然而,随着工艺的成熟和成本的降低,MRAM有望取代DRAM。
然而历史上在DRAM和Flash的发展过程中,一直有人认为还有其他存储芯片威廉希尔官方网站
可以取代它们,但都没有成功。赵巍胜认为,DRAM和Flash将随着新威廉希尔官方网站
的引入不断发展。例如,DRAM威廉希尔官方网站
因为EUV光刻机的使用而得以进步。目前,MRAM在特定应用场景下已经有了一定的市场份额,如ToT、车载、航空航天等领域。然而,未来MRAM很有可能向新的消费级市场发起冲击。
四.SRAM 的存内计算和于 MRAM 的存算一体探讨
SRAM的存内计算和基于MRAM的存算一体是两种不同的计算模式,它们各自有着独特的特点和优势。
SRAM的存内计算:
工作原理:SRAM的存内计算利用存储单元的逻辑运算功能,通过激活同一列的多个存储单元来实现逻辑运算。
优势:
高密度和低功耗:相比传统的SRAM阵列,新的SRAM存内计算架构具有更高的密度和更低的功耗,提供了更广阔的发展空间。
逻辑运算功能:SRAM存储单元具有逻辑运算功能,可以实现逻辑与非、逻辑或非、逻辑异或等逻辑运算。
创新:研究者们提出了各种创新的SRAM存内计算架构,如8T和10T SRAM单元,以及解耦读写路径等,进一步提高了计算性能和能效。
基于MRAM的存算一体:
工作原理:基于MRAM的存算一体将计算和存储功能结合在一起,利用MRAM的快速读/写速度和非易失性,在存储器内部进行计算操作。
优势:
减少数据传输:由于计算任务可以直接在MRAM中进行,无需将数据传输到CPU或GPU,因此可以减少数据传输的延迟和能耗。
降低系统复杂性:存算一体可以降低硬件系统的复杂性,简化系统架构,降低成本。
应用前景:MRAM作为一种新型存储威廉希尔官方网站
,在军工、大数据高性能存储等领域已经有了一些应用,并有望取代DRAM。
对比:
工作原理差异:SRAM的存内计算主要利用存储单元的逻辑运算功能,而基于MRAM的存算一体则是将计算和存储功能集成在MRAM中。
优势重点不同:SRAM存内计算注重于提高计算性能和能效,而基于MRAM的存算一体则注重于减少数据传输延迟和降低系统复杂性。
应用领域不同:SRAM存内计算主要应用于逻辑计算和神经网络硬件加速,而基于MRAM的存算一体则更多应用于军工、大数据高性能存储等领域。
两者各有特点,适用于不同的场景和应用需求。SRAM的存内计算更适用于需要高性能逻辑计算和神经网络加速的场景,而基于MRAM的存算一体则更适用于减少数据传输延迟和简化系统架构的场景。
五.总结
本文深入探讨了基于SRAM和MRAM的存算一体威廉希尔官方网站
在计算领域的应用和发展。首先,介绍了基于SRAM的存内逻辑计算威廉希尔官方网站
,包括其原理、优势以及在神经网络领域的应用。其次,详细讨论了基于MRAM的存算一体威廉希尔官方网站
,包括其工作原理、优势以及在军工和大数据存储领域的应用。最后,对比了SRAM的存内计算和基于MRAM的存算一体威廉希尔官方网站
的差异,包括工作原理、优势重点和应用领域等方面。
在全文中,强调了这两种威廉希尔官方网站 在提高计算性能、降低能耗、简化系统架构等方面的重要作用,展望了它们在未来的计算应用中的潜力和前景。同时,对于不同场景下的适用性和优势进行了详细的分析和比较,为读者提供了深入了解存内计算威廉希尔官方网站 的参考。
参考文献
DRAM时代即将到来,泛林集团这样构想3D DRAM的未来架构
3D DRAM Is Coming. Here’s a Possible Way to Build It.Benjamin Vincent
3D堆叠DRAM Cache的建模以及功耗优化关键威廉希尔官方网站
研究
存内计算概述
中国科学威廉希尔官方网站
大学
应用于忆阻器阵列存内计算的低延时低能耗新型感知放大器
基于存算一体集成芯片的大模型专用硬件架构
高能效高安全新兴计算芯片:现状、挑战与展望 54.01(2024):34-47.
校准方法和存内训练相结合的忆阻器神经形态计算方法
Survey of In-Memory Computing Technology Based on SRAM and Non-Volatile Memory
审核编辑 黄宇
-
存储器
+关注
关注
38文章
7484浏览量
163767 -
神经网络
+关注
关注
42文章
4771浏览量
100719 -
sram
+关注
关注
6文章
767浏览量
114675 -
MRAM
+关注
关注
1文章
236浏览量
31717 -
存内计算
+关注
关注
0文章
30浏览量
1378
发布评论请先 登录
相关推荐
存内计算威廉希尔官方网站 工具链——量化篇
知存科技再推存算一体芯片,用AI威廉希尔官方网站 推动助听器智能化

知存科技助力AI应用落地:WTMDK2101-ZT1评估板实地评测与性能揭秘
什么是存内计算
2023年存算一体是芯片设计的威廉希尔官方网站 趋势

直播预约 |开源芯片系列讲座第24期:SRAM存算一体:赋能高能效RISC-V计算

开源芯片系列讲座第24期:基于SRAM存算的高效计算架构





 工商网监
工商网监
评论