 FP8在NVIDIA GPU架构和软件系统中的应用
FP8在NVIDIA GPU架构和软件系统中的应用
在深度学习和人工智能的快速发展背景下,尤其是大语言模型(Large Language Model,LLM)的蓬勃发展,模型的大小和计算复杂性不断增加,对硬件的性能和能效提出了极高要求。为了满足这些需求,业界一直在寻求新的威廉希尔官方网站 和方法来优化计算过程。其中,FP8(8 位浮点数)威廉希尔官方网站 凭借其独特的优势,在 AI 计算领域崭露头角。本文作为 FP8 加速推理和训练系列的开篇,将深入探讨 FP8 的威廉希尔官方网站 优势,以及它在 NVIDIA 产品中的应用,并通过客户案例来展示 FP8 在实际部署中的强大潜力。
FP8 的原理与威廉希尔官方网站 优势
FP8 是一种 8 位浮点数表示法,FP8 采取 E4M3 和 E5M2 两种表示方式,其中 E 代表指数位(Exponent),M 代表尾数位(Mantissa)。在表示范围内,E4M3 更精准,而 E5M2 有更宽的动态范围。与传统的 FP16(16 位浮点数)和 FP32(32 位浮点数)相比,它显著减少了存储,提高了计算吞吐。
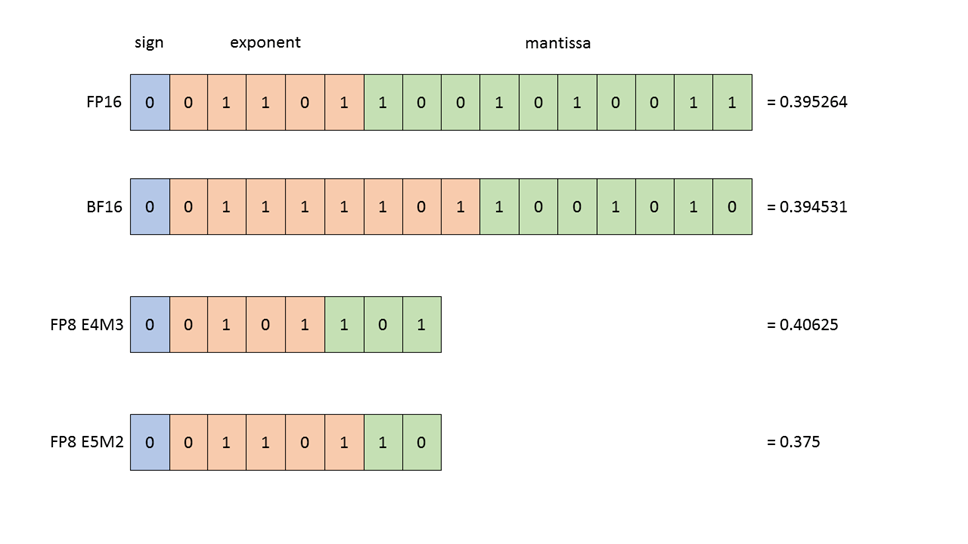
图 1:浮点数据类型的结构。所有显示的值
(在 FP16、BF16、FP8 E4M3 和 FP8 E5M2 中)
都是最接近数值 0.3952 的表示形式。
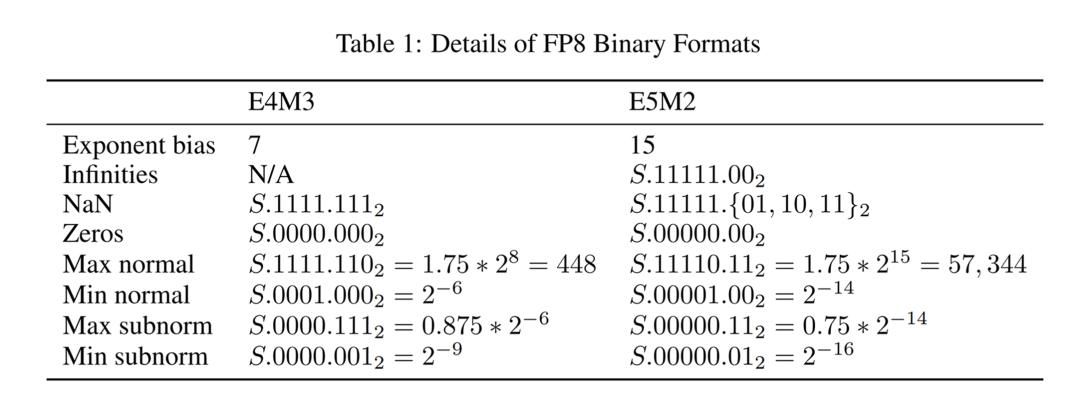
图 2:FP8 二进制格式
数据表示位数的降低带来了更大的吞吐和更高的计算性能,虽然精度有所降低,但是在 LLM 场景下,采用威廉希尔官方网站 和工程手段,FP8 能够提供与更高精度类型相媲美的结果,同时带来显著的性能提升和能效改善。
性能提升:由于 FP8 的数据宽度更小,减少了显存占用,降低了通讯带宽要求,提高了 GPU 内存读写的吞吐效率。并且在相同的硬件条件下,支持 FP8 的 Tensor Core 可以在相同时间内进行更多次的浮点运算,加快训练和推理的速度。
模型优化:FP8 的使用促使模型在训练和推理过程中进行量化,这有助于模型的优化和压缩,进一步降低部署成本。
与 INT8 的数值表示相比较,FP8 在 LLM 的训练和推理更有优势。因为 INT8 在数值空间是均匀分布的,而 FP8 有更宽的动态范围, 更能精准捕获 LLM 中参数的数值分布,配合 NVIDIA Transformer Engine、NeMo 以及 Megatron Core 的训练平台和 TensorRT-LLM 推理优化方案,大幅提升了 LLM 的训练和推理的性能,降低了首 token 和整个生成响应的时延。
FP8 在 NVIDIA GPU 架构和软件系统中的应用
作为 AI 计算领域的领导者,NVIDIA 一直在推动新威廉希尔官方网站 的发展和应用。FP8 威廉希尔官方网站 在其产品中得到了广泛的支持和应用。
GPU 架构与 Transformer Engine
NVIDIA GPU 无论是 Hopper 架构、还是 Ada Lovelace 架构都支持 Transformer Engine 进行 FP8 的训练和推理。Transformer Engine 是一项专门为加速 Transformer 模型训练和推理而打造的软件库,应用混合的 FP8 和 FP16/BF16 精度格式,大幅加速 Transformer 训练,同时保持准确性。FP8 也可大幅提升大语言模型推理的速度,性能提升高达 Ampere 架构的 30 倍。
推理方面
TensorRT-LLM
TensorRT-LLM是 NVIDIA 针对 LLM 推出的高性能推理解决方案。它融合了 FasterTransformer 的高性能与 TensorRT 的可扩展性,提供了大量针对 LLM 的新功能,而且能与 NVIDIA Triton 推理服务器紧密配合,使先进的 LLM 发挥出更优异的端到端性能。
TensorRT-LLM 可运行经 FP8 量化的模型,支持 FP8 的权重和激活值。经 FP8 量化的模型能极好地保持原 FP16/BF16 模型的精度,并且在 TensorRT-LLM 上加速明显,无论在精度上还是性能上,都明显好于 INT8 SmoothQuant。
TensorRT-LLM 还为 KV 缓存(key-value cache)提供了 FP8 量化。KV 缓存默认是 FP16 数据类型,在输入文本或输出文本较长时,占据显著的数据量;在使用 FP8 量化之后,其数据量缩小一半,明显地节省显存,从而可以运行更大的批量。此外,切换到 FP8 KV 缓存可减轻全局显存读写压力,进一步提高性能。
训练方面
NVIDIA NeMo
NVIDIA NeMo 是一款端到端云原生框架,用户可以在公有云、私有云或本地,灵活地构建、定制和部署生成式 AI 模型。它包含训练和推理框架、护栏工具包、数据管护工具和预训练模型,为企业快速采用生成式 AI 提供了一种既简单、又经济的方法。NeMo 适用于构建企业就绪型 LLM 的全面解决方案。
在 NeMo 中,NVIDIA 集成了对 FP8 的全面支持,使得开发者能够轻松地在训练和推理过程中使用 FP8 格式。通过 NeMo 的自动混合精度训练功能,开发者可以在保持模型准确性的同时,显著提高训练速度。此外,NeMo 还将陆续提供了一系列配套的工具、库和微服务,帮助开发者优化 FP8 推理的性能等。这些功能使得 NeMo 成为了一个强大而灵活的框架,能够满足各种 AI 应用场景的需求。
Megatron Core
Megatron Core 是 NVIDIA 推出的一个支持 LLM 训练框架的底层加速库。它包含了训练 LLM 所需的所有关键威廉希尔官方网站 ,例如:各类模型并行的支持、算子优化、通信优化、显存优化以及 FP8 低精度训练等。Megatron Core 不仅吸收了 Megatron-LM 的优秀特性,还在代码质量、稳定性、功能丰富性和测试覆盖率上进行了全面提升。更重要的是,Megatron Core 在设计上更加解耦和模块化,不仅提高了 LLM 训练的效率和稳定性,也为二次开发和探索新的 LLM 架构提供了更大的灵活性。
Megatron Core 支持 FP8 的训练,很快也将支持 MoE 的 FP8 训练。
FP8 在 LLM 训练和推理的成功应用
以下将详细介绍几个成功案例,并深入剖析其中的威廉希尔官方网站 细节,以展现 FP8 在推动 AI 模型高效训练和快速推理方面的巨大潜力。
FP8 在 LLM 的推理方面的成功应用
Google 的 Gemma 模型与 TensorRT-LLM 完美结合
Google 一直在寻求提高其 LLM 的推理效率。为此,Google 与 NVIDIA 团队合作,将 TensorRT-LLM 应用于 Gemma 模型,并结合 FP8 威廉希尔官方网站 进行了推理加速。
威廉希尔官方网站 细节方面,双方团队首先使用 NVIDIA AMMO 库对 Gemma 模型进行了精细的量化处理,将模型的权重和激活值从高精度浮点数(FP16/BF16)转换为低精度浮点数(FP8)。通过仔细调整量化参数,威廉希尔官方网站 团队确保了 Gemma 模型在使用低精度进行推理的时候不损失准确性。这一步骤至关重要,因为它直接影响到模型推理的性能和准确性。
接下来,威廉希尔官方网站 团队利用 TensorRT-LLM 对量化后的 Gemma 模型进行了优化。TensorRT-LLM 通过一系列优化威廉希尔官方网站 (如层融合、flash-attention)来提高模型的推理速度。在这个过程中,FP8 威廉希尔官方网站 发挥了重要作用。由于 FP8 的数据宽度较小,它显著减少了模型推理过程中所需的显存带宽和计算资源,从而提高了推理速度。同时,FP8 能够降低存放激活值、KV 缓存所需要的显存,增大我们推理时能够使用的 batch size,进一步的提升我们的吞吐量。
最终,通过 TensorRT-LLM 和 FP8 威廉希尔官方网站 的结合,Google 成功在模型发布的同时实现了 Gemma 模型的高效推理。这不仅为用户提供了更快的响应时间和更流畅的语言处理体验,还展示了 FP8 在推动 AI 模型推理加速方面的巨大潜力。
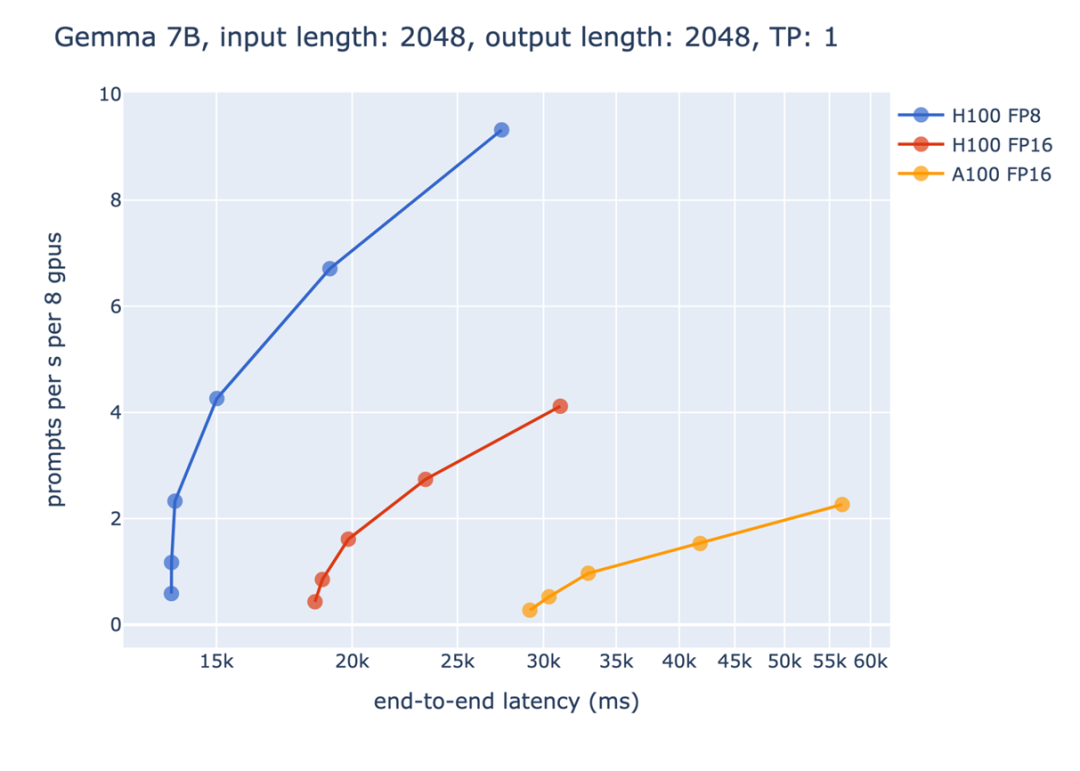
图 3:静态批处理,延迟 vs 吞吐量
从上图我们可以看到 FP8 相较于 FP16 带来的收益。横轴代表的是某个端到端的时间限制,纵轴代表的是吞吐量。对于生成式模型的性能评测,不能够单纯的只考虑吞吐量或是延迟。如果只追求吞吐量,导致延迟太长,会让使用者有不好的体验;相反的,如果只考虑延迟,则会导致没办法充分利用硬件资源,造成浪费。
因此,常见的评测条件是,在一定的延迟限制下,达到最大的吞吐量。以上图为例,如果将端到端的时间限制设为 15 秒,则只有 FP8 能够满足要求,这展示了在一些对延迟限制比较严格的场景下,FP8 加速带来的重要性。而在 20 秒这个时间限制下,都使用 Hopper GPU 进行推理时,FP8 对比 FP16 在吞吐量上能够带来 3 倍以上的收益。这是由于上面提到的,FP8 能够在相同的时间限制下使用更大的 batch size,从而有更好的 GPU 利用率,达到更高的吞吐量。
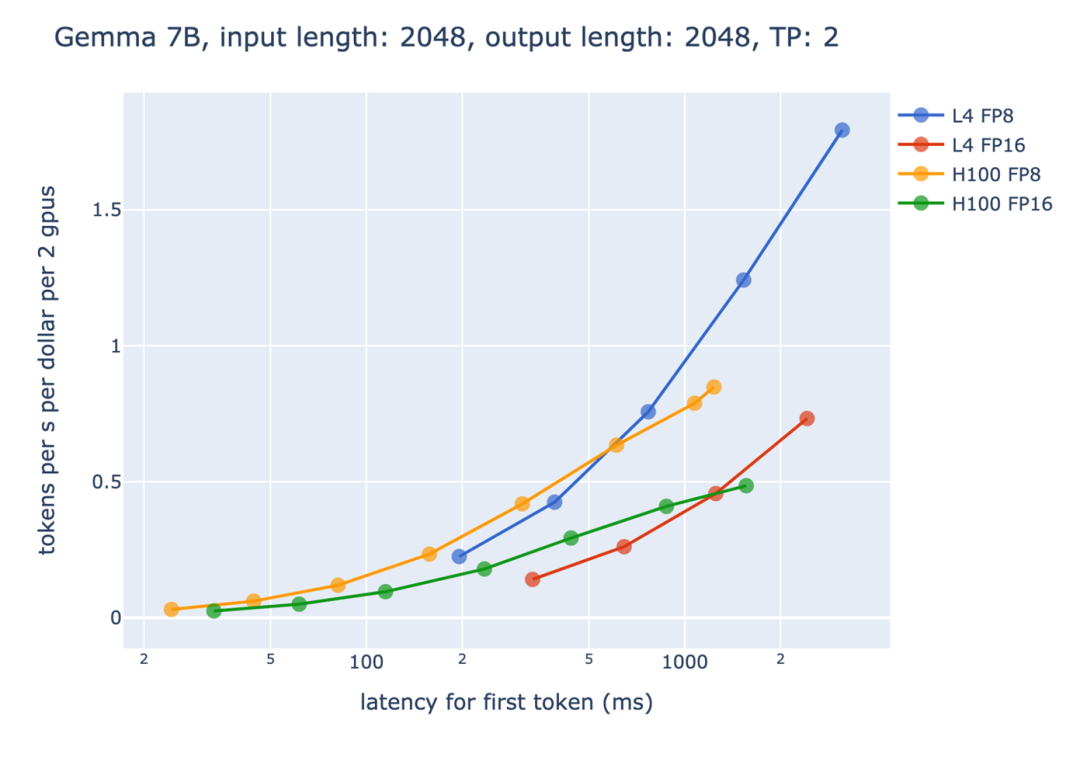
图 4:首 token 延迟 vs 基于每 dollar 的吞吐量
另外一方面,从性价比的角度来看,FP8 也带来了很大的收益。上图中,横轴是产生第一个 token 的时间限制,而纵轴则是每单位的资源能产生的 token 数量。请注意由于要处理长输入,产生第一个 token 的时间通常会比较长,而后面的阶段可以透过流处理(streaming)的方式,每产生一个 token 就立即返回给使用者,让使用者不会觉得等待时间过长。我们可以观察到,随着时间限制的增加,FP8 带来的收益也越来越大。尤其是在 L4 Tensor Core GPU 上面,由于 GPU 本身的显存较小,因此 FP8 节省显存使用带来的效益更加的明显。
FP8 在 LLM 训练方面的成功应用
Inflection AI 的 FP8 训练
Inflection AI 是一家专注于 AI 威廉希尔官方网站 创新的公司,他们的使命是创造人人可用的 AI,所以他们深知大模型的训练对于 AI 生成内容的精准性和可控性至关重要。因此,在他们近期推出的 Inflection2 模型中,采用了 FP8 威廉希尔官方网站 对其模型进行训练优化。
Inflection-2 采用了 FP8 混合精度在 5000 个 NVIDIA Hopper 架构 GPU 上进行了训练,累计浮点运算次数高达约 10^25 FLOPs。与同属训练计算类别的 Google 旗舰模型 PaLM 2 相比,在包括知名的 MMLU、TriviaQA、HellaSwag 以及 GSM8k 等多项标准人工智能性能基准测试中,Inflection-2 展现出了卓越的性能,成功超越了 PaLM 2,彰显了其在模型训练方面的领先性,同时也印证了 FP8 混合精度训练策略能够保证模型正常收敛并取得良好的性能。
从 LLM 训练到推理, FP8 端到端的成功应用
零一万物的双语 LLM 模型:FP8 端到端训练与推理的卓越表现
零一万物是一家专注于 LLM 的独角兽公司,他们一直致力于在 LLM 模型及其基础设施和应用的创新。其最新的支持 200K 文本长度的开源双语模型,在 HuggingFace 预训练榜单上,与同等规模的模型中对比表现出色。在零一万物近期即将发布的千亿模型 AI Infra 威廉希尔官方网站 上,他们成功地在 NVIDIA GPU 上进行了端到端 FP8 训练和推理,并完成了全链路的威廉希尔官方网站 验证,取得了令人瞩目的成果。
零一万物的训练框架是基于 NVIDIA Megatron-LM 开发的 Y 训练框架, 其 FP8 训练基于 NVIDIA Transformer Engine。在此基础上,零一万物团队进一步的设计了训练容错方案:由于没有 BF16 的 baseline 来检查千亿模型 FP8 训练的 loss 下降是否正常,于是,每间隔一定的步数,同时使用 FP8 和 BF16 进行训练,并根据 BF16 和 FP8 训练的 loss diff 和评测指标地差异,决定是否用 BF16 训练修正 FP8 训练。
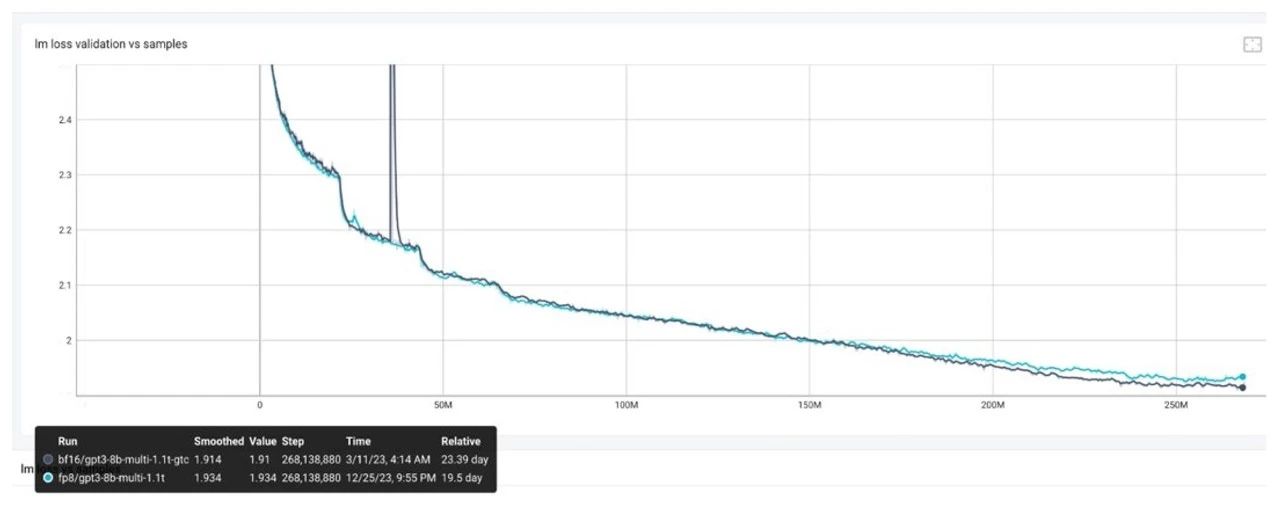
由于 FP8 训练的过程中需要统计一定历史窗口的量化信息,用于 BF16 到 FP8 的数据裁切转换,因此在 BF16 训练过程中,也需要在 Transformer Engine 框架内支持相同的统计量化信息的逻辑,保证 BF16 训练可以无缝切换到 FP8 训练,且不引入训练的效果波动。在这个过程中,零一万物基于 NVIDIA 软硬结合的威廉希尔官方网站 栈,在功能开发、调试和性能层面,与 NVIDIA 团队合作优化,完成了在大模型的 FP8 训练和验证。其大模型的训练吞吐相对 BF16 得到了 1.3 倍的性能提升。
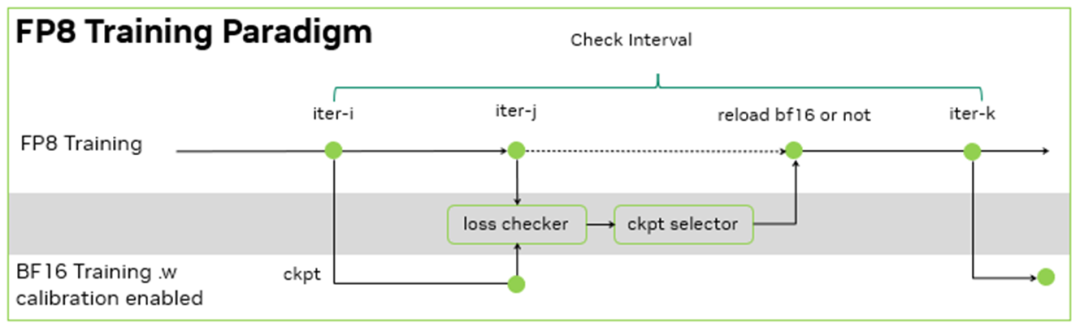
图 5:FP8 训练范式
在推理方面,零一万物基于 NVIDIA TensorRT-LLM 开发了 T 推理框架。这个框架提供了从 Megatron 到 HuggingFace 模型的转化,并且集成了 Transformer Engine 等功能,能够支持 FP8 推理,大大减小了模型运行时需要的显存空间,提高了推理速度,从而方便社区的开发者来体验和开发。具体过程为:
将 Transformer Engine 层集成到 Hugging Face 模型定义中。
开发一个模型转换器,将 Megatron 模型权重转换为 HuggingFace 模型。
加载带有校准额外数据的 Huggingface 模型,并使用 FP8 精度进行基准测试。取代 BF16 张量以节省显存占用,并在大批量推理中获得 2~5 倍的吞吐提升。

图 6:FP8 模型转换与评测流程
总结与展望
基于上述 LLM 使用 FP8 训练和推理的成功实践,我们可以看到 FP8 在推动 AI 模型的高效训练和快速推理方面的巨大潜力。随着 FP8 训练和推理方法的不断完善和广泛应用,我们确信 FP8 将在 LLM 应用中扮演越来越重要的角色,敬请期待更多成功案例和威廉希尔官方网站 解密。
审核编辑:刘清
-
NVIDIA
+关注
关注
14文章
4985浏览量
103033 -
人工智能
+关注
关注
1791文章
47258浏览量
238418 -
深度学习
+关注
关注
73文章
5503浏览量
121152 -
GPU芯片
+关注
关注
1文章
303浏览量
5811 -
大模型
+关注
关注
2文章
2442浏览量
2686
原文标题:FP8:前沿精度与性能的新篇章
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
解锁NVIDIA TensorRT-LLM的卓越性能
《CST Studio Suite 2024 GPU加速计算指南》
如何使用FP8新威廉希尔官方网站 加速大模型训练
FP8数据格式在大型模型训练中的应用

TensorRT-LLM低精度推理优化


【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片GPU
AMD与NVIDIA GPU优缺点
FP8模型训练中Debug优化思路
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
NVIDIA推出两款基于NVIDIA Ampere架构的全新台式机GPU

FPGA在深度学习应用中或将取代GPU
NVIDIA的Maxwell GPU架构功耗不可思议

NVIDIA GPU因出口管制措施推迟发布





 工商网监
工商网监
评论