 新一代GPU之王B200面世,带动产业链狂欢!
新一代GPU之王B200面世,带动产业链狂欢!
电子发烧友网报道(文/周凯扬)作为AI时代不容置疑的无冕之王,英伟达每年举办的GTC大会不仅是针对英伟达软硬件生态开发者的一场盛会,也是英伟达展示肌肉的舞台。在近日举办的GTC大会上,英伟达CEO黄仁勋在发布新品的同时,也宣告了一个新的计算时代的到来。
黄仁勋表示,我们需要更大的模型,然后用更多的多模数据去训练它,而不再局限于互联网上的文本数据,还有图片、图表。正如我们通过电视来获取支持知识一样,这些大模型也将快速接入视频数据,比如最近爆火的Sora等。
192GB HBM3e内存,Blackwell架构的前锋
为了应对更大的模型,自然也就需要更大的GPU,这才有了英伟达此次发布的Blackwell GPU平台。Blackwell架构以数学家David Harold Blackwell命名,作为两年前发布的Hopper架构继任者,Blackwell可以说实现了设计到性能上的全方位升级,而首个享受这些升级的,就是B200 GPU。
全新的B200 GPU基于台积电4NP工艺,采用了两个GPU die集成在同一芯片上的设计,并配备了192GGB的HBM3e超大内存。也正因如此,B200单芯片的晶体管数量达到了惊人的2080亿个,TDP也高达1000W。但这样疯狂的堆料带来的自然是性能的翻倍提升,在FP8精度的训练性能上,B200 GPU的算力是上一代的2.5倍。
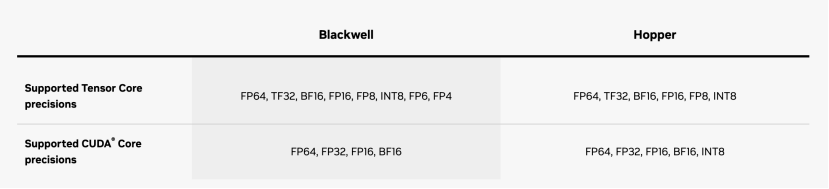
两代GPU架构支持精度 / 英伟达
有趣的一点在于,在英伟达第二代Transformer引擎的支持下,此次B200加入了对FP4精度的支持,从而支持到规模更大,性能要求更高的模型。在FP4精度下的推理性能,B200的算力更是达到了上一代的5倍。如果以1750亿参数的GPT-3大模型作为实例进行测试的话,B200 GPU的总体性能是H100的7倍,训练速度则是H100的4倍。
为了更好地提升B200的扩展性,英伟达基于最新的第五代NVLink威廉希尔官方网站
,开发了一块全新的NVLink Switch芯片,双向带宽高达1800GB/s,是上一代的两倍。与此同时,NVLink支持的最大扩展规模也得到了提升,如今最多支持576块B200 GPU互联互通。

GB200超级芯片 / 英伟达
除了新架构的GPU外,英伟达基于NVLink C2C互联威廉希尔官方网站
,也为超级芯片GH200打造了下一代继任者GB200。GB200超级芯片由一个Grace CPU与两块B200 GPU组成,并以超低功耗却能实现900GB/s超大带宽的互联。不过此次英伟达并没有对CPU的架构进行升级,仍然采用的是72核Arm Neoverse N2的设计,所以此次GH200的主要性能提升还是在GPU上,英伟达GB200在LLM推理性能上有了30倍的提升,但能效比也提升了25倍。
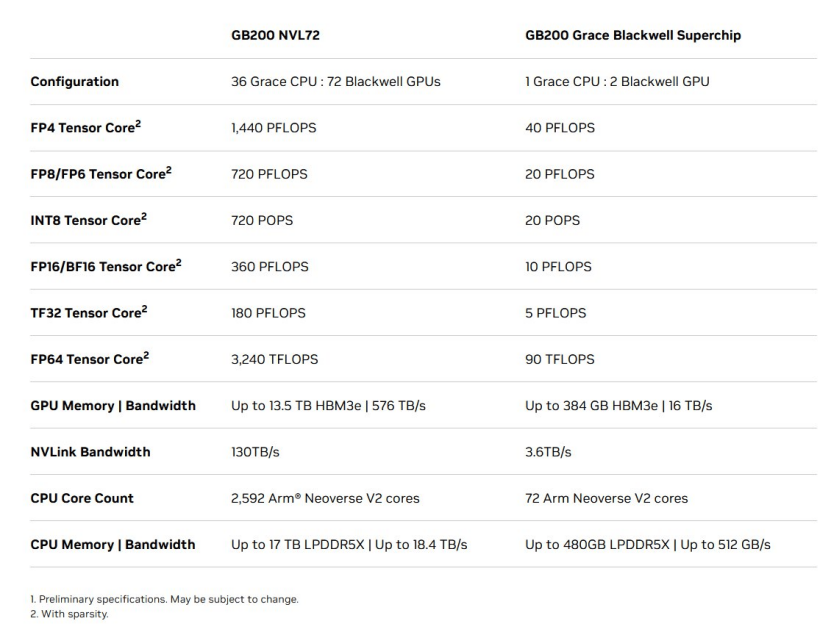
GB200 NVL72与GB200配置与性能 / 英伟达
针对万亿参数级别的超级大模型,英伟达基于GB200和NVLink威廉希尔官方网站
推出了集成36/72个GPU的GB200 NVL36/72方案。基于GB200 NVL72打造的MGX系统更是可以实现30TB的统一内存,130TB/s的总带宽,甚至是单机柜exaFLOP级(FP4精度)的AI算力。英伟达表示,即便面对1.8万亿参数的GPT-MoE-1.8T超大模型,也可以实现比同数量H100 GPU高出4倍的训练性能,以及实时的AI推理。
B200发布后,哪些产业同步受益
过去英伟达先进AI GPU的热度,已经带动了一批上下游产业的发展,而随着B200的发布,相关市场或再度迎来一轮爆发。从制造上游来看,无疑晶圆代工厂受益最大,无论是提供逻辑代工、先进封装方案的台积电,还是为新GPU提供大容量HBM内存的三大存储厂商(SK海力士、三星和美光)。
四年之前,英伟达在GA100采取了将芯片分成两半,通过高速互联威廉希尔官方网站
来完成通信的设计,然而这一大胆的设计却很少被人注意。而如今在CUDA、GPU团队,以及台积电的先进逻辑与封装工艺下,B200终于采用了Chiplet的设计,将两个GPU die集成在单个封装内,并做到了逼近台积电4NP工艺节点的极限die面积,以及高达10TB/s的C2C互联速度。
再考虑到未来即将出货的H200和B100 GPU,这一系列芯片将进一步推动台积电4nm工艺走向满载的产能利用率,而这还是在过去只被视为淡季的Q1。更不用说这一系列芯片带来的CoWoS产能压力,据报道,台积电已经计划投资160亿美元在台湾建设6座新的CoWoS封装设施,甚至有爆料称台积电开始考虑出海扩张CoWoS封装产能,第一站很可能会在日本,足以看出GPU的订单数量之夸张。
这也进一步推动了存储厂商在HBM上的营收占比,三大参与厂商在HBM产能供应上的竞争已经进入了白热化阶段。本次GTC线下活动中,SK海力士、三星和美光均展示了自己的HBM3e解决方案。据TrendForce预估,2024年全年HBM产能将同比提升260%,于整个DRAM行业产值占比从去年的8.4%扩大至20.1%。不过,对于存储厂商而言,今年的订单基本已经排满了,依照英伟达和AMD的发布计划来看,即便在疯狂扩产下,2025年的产能恐怕也抵不住即将疯狂袭来的订单。
另一个即将从数据中心进一步攫取更多市场机会的产业为液冷,而且服务器厂商们早已准备好了对应的解决方案。目前随着服务器AI算力的不断增强,液冷解决方案的普及率在整个服务器市场依然算不上高,甚至不到5%。
B200、GB200以及GB200 NVL72尽管一再强调提高了能效比,但对于单个系统的散热要求依然提高了。毕竟单个GB200 NVL72机柜的计算单元规模就比过去的DGX系统高出不少,液冷是英伟达目前给出的唯一设计,毕竟单个GB200超级芯片的最高TDP可达2700W。
为此服务器OEM几乎同时宣布了对应的液冷服务器配置方案,比如戴尔推出了首个采用液冷配置的PowerEdge XE9680服务器,Supermicro也发布了液冷ORV3 MGX系统。鸿海集团也发布了针对GB200 NVL72的先进液冷解决方案,具备高达1300kW的强大散热能力。
最后自然就是服务器上的高速通信了,与B200同步公布的还有Quantum-X800 InfiniBand和Spectrum™-X800 Ethernet这两大高速网络解决方案。在与英伟达LinkX线缆和光模块的组合下,可以做到最高2公里内的800GB/s网络传输速度。尽管这是英伟达收购Mellanox后发布的专用方案,但无疑加快了800G网络普及的进程。
计算光刻,反哺芯片制造
去年,英伟达推出了cuLitho这一软件库,借助GPU的强大算力有望将光罩的开发速度提升40倍。在今天的GTC大会上,英伟达也宣布和台积电、新思达成合作,正式将其计算光刻威廉希尔官方网站
投入生态当中去,并充分利用英伟达此次发布的Blackwell GPU。
计算光刻主要用于芯片的开发和制造环节,通过建立大量的数学和物理模型来帮助客户设计光罩。相比传统基于CPU的计算光刻威廉希尔官方网站
,基于GPU加速和生成式AI算法的计算光刻威廉希尔官方网站
要高效得多,英伟达声称集成了350个H100的系统就可以替代掉一个由40000个CPU组成的计算光刻系统,加速生产时间的同时,降低了成本、部署空间和功耗。
写在最后
尽管每次在英伟达展示其新品后,这些产品都会成为其他AI硬件公司拿来作为各种性能对比的参考,比如这次Groq就在GTC会后很快正面回应了英伟达,并发布了“Groq仍然更快”的声明。然而,明眼人都能看出来,在当今的市场环境下,英伟达在AI行业的地位依旧不可撼动。
其中不仅有架构创新、CUDA的功劳,也少不了英伟达在半导体上下游多年来的经营。台积电优先给英伟达CoWoS封装产能,AI服务器厂商们在发布会后一呼百应,都佐证了英伟达已经为这个新计算时代打造好了一条完整且已经得到证实的AI生态。
-
gpu
+关注
关注
28文章
4729浏览量
128897 -
英伟达
+关注
关注
22文章
3771浏览量
90991
发布评论请先 登录
相关推荐
头部电池企业扩产热,锁单锂盐带动产业链高景气
NVIDIA DGX B200首次面向零售市场:配备8块B200 GPU
英伟达或取消B100转用B200A代替
星曜半导体完成10亿元B轮融资,中国移动产业链发展基金领投
英伟达GPU新品规划与HBM市场展望
特斯拉加码AI布局:xAI将采购30万块英伟达B200芯片
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
会员风采!华秋电子——致力于“为电子产业增效降本”的数字化智造平台
英伟达H200性能显著提升,年内将推出B200新一代AI半导体
英伟达发布新一代AI芯片B200
英伟达发布性能大幅提升的新款B200 AI GPU
英伟达计划拉大GB200与B100/B200规格差异,以刺激用户购买GB200
戴尔发布英伟达B200 AI GPU:高功耗达1000W,创新性冷却工程设计必要
NVIDIA将在今年第二季度发布Blackwell架构的新一代GPU加速器“B100”

陶瓷基板产业链分布及工艺制作流程





 工商网监
工商网监
评论