 最强AI芯片发布,Cerebras推出性能翻倍的WSE-3 AI芯片
最强AI芯片发布,Cerebras推出性能翻倍的WSE-3 AI芯片
前言: 近日,芯片行业的领军企业Cerebras Systems宣布推出其革命性的产品——Wafer Scale Engine 3,该产品成功将现有最快AI芯片的世界纪录提升了一倍。
WSE-3 AI芯片比英伟达H100大56倍
WSE-3芯片采用了台积电先进的5纳米工艺威廉希尔官方网站 ,集成了超过4万亿个晶体管与90万个核心,展现出惊人的125 petaflops计算性能。
此芯片不仅是台积电目前能制造的最大方形芯片,其独特的44GB片上SRAM设计。
摒弃了传统的片外HBM3E或DDR5内存方式,使内存与核心紧密结合,极大缩短了数据处理与计算的距离,提升了整体运算效率。
另一方面,Cerebras的CS-3系统代表了Wafer Scale威廉希尔官方网站 的第三代成就。
其顶部配置有先进的MTP/MPO光纤连接,以及完备的冷却系统包括电源、风扇和冗余泵,确保了系统在高负荷运行时的稳定与可靠。
相较于前代产品,CS-3系统及其新型芯片在保持相同功耗和成本的同时,实现了近两倍的性能提升。
值得注意的是,WSE-3芯片的核心数量高达英伟达H100 Tensor Core的52倍。

由WSE-3驱动的Cerebras CS-3系统在训练速度上比英伟达的DGX H100系统快了8倍,内存扩大了1900倍。
更令人震惊的是,CS-3系统能够支持高达24万亿个参数的AI模型训练,这一数字是DGX H100的600倍。Cerebras公司高管表示,CS-3系统的能力已全面超越DGX H100。
举例来说,原本在GPU上需要30天才能完成的Llama 700亿参数模型训练,现在通过CS-3集群仅需一天即可完成。
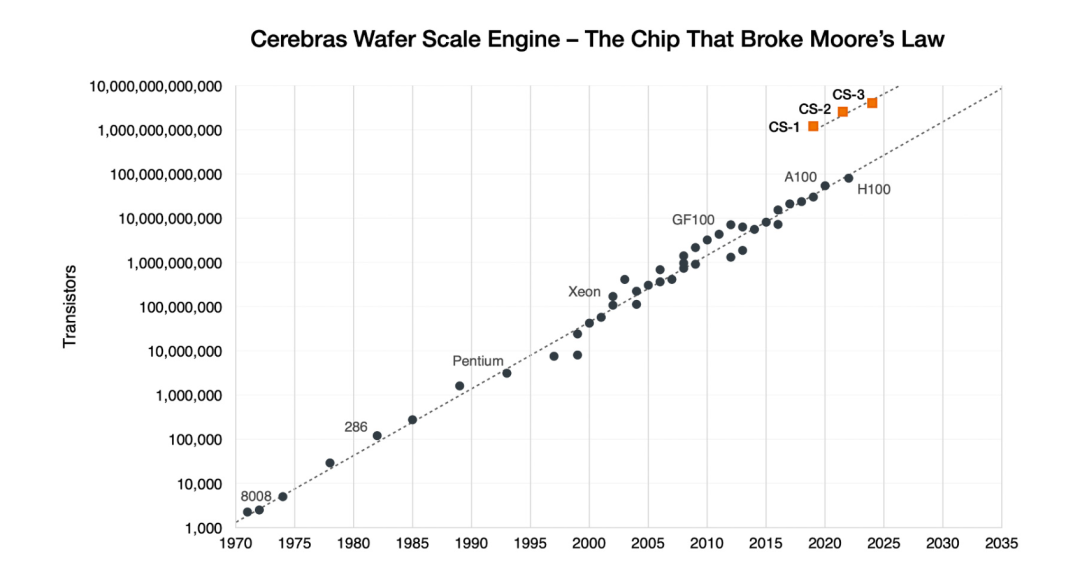
第三代产品成功破圈
WSE-3在保持与前代产品Cerebras WSE-2相同功耗和价格的同时,其性能却实现了翻番,这无疑是对市场的一次重大突破。
WSE-3是Cerebras第三代产品,展现了其在晶圆级芯片设计和制造方面的威廉希尔官方网站 积累。
第一代WSE于2019年推出,采用台积电16nm工艺;第二代WSE-2于2021年发布,采用7nm工艺;WSE-3则使用5nm威廉希尔官方网站 。
相比第一代,WSE-3的晶体管数量增加了两倍以上,达到了4万亿的规模。根据其官方介绍,与晶体管数量的增长相比,芯片上的计算单元、内存和带宽的增长速度有所放缓。
这反映出Cerebras在追求整体性能提升的同时,也在芯片面积、功耗和成本之间进行权衡。
通过多代产品的迭代,Cerebras掌握了晶圆级芯片设计和制造的核心威廉希尔官方网站 ,为未来的创新奠定了基础。
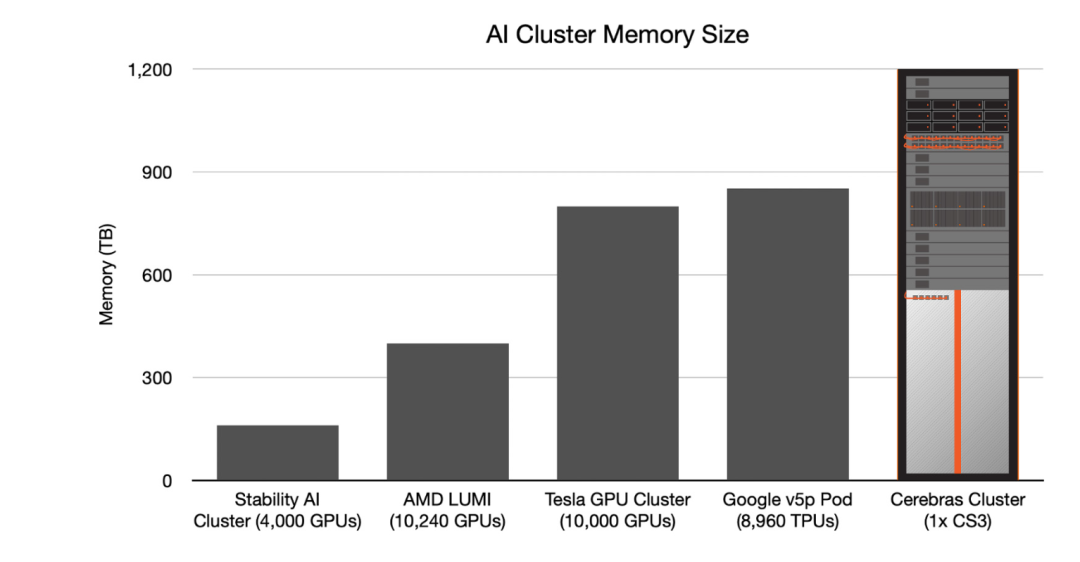
专为AI打造的计算能力
以往,在传统的GPU集群环境下,研究团队在分配模型时不仅需要科学严谨,还需应对一系列复杂的挑战,如处理器单元的内存容量限制、互联带宽的瓶颈以及同步机制的协调等。
此外,团队还需持续调整超参数并开展优化实验,以确保模型的性能达到最佳状态。
然而,这些努力常常因微小的变动而受到影响,导致解决问题所需的总时间进一步延长,增加了研究的复杂性和不确定性。
相比之下,WSE-3的每一个核心均具备独立编程的能力,并且针对神经网络训练和深度学习推理中所需的基于张量的稀疏线性代数运算进行了专门的优化。
这一特点使得研究团队能够在WSE-3的支持下,以前所未有的速度和规模高效地训练和运行AI模型,同时避免了复杂分布式编程技巧的需求。
WSE-3配备的44GB片上SRAM内存均匀分布在芯片表面,使得每个核心都能在单个时钟周期内以极高的带宽(21 PB/s)访问到快速内存,是当今地表最强GPU英伟达H100的7000倍。
而WSE-3的片上互连威廉希尔官方网站 ,更是实现了核心间惊人的214 Pb/s互连带宽,是H100系统的3715倍。
CS-3可以配置为多达2048个系统的集群,可实现高达256 exaFLOPs的AI计算,专为快速训练GPT-5规模的模型而设计。

大幅简化并行编程复杂度
传统的集群建设方式,通常需要数以万计的GPU或AI加速器来协同解决某一问题。
在英伟达所构建的GPU集群中,这些集群通过Infiniband、以太网、PCIe和NVLink交换机等设备进行连接,其中大部分功率和成本均投入到芯片间的重新连接上。
此外,为了管理这些芯片间的互连、通信和同步,还需编写大量的代码,这无疑增加了并行编程的复杂性。
然而,Cerebras采用了一种与英伟达截然不同的方法。他们选择保留整个晶圆,因此所需的芯片数量减少了50倍以上,从而显著降低了互连和网络的复杂性和成本。
在软件层面,Cerebras提供了一套优化的软件栈,其中包括内置的通信机制和自动化的内存管理。
这使得开发人员能够使用更少的代码实现复杂的模型,从而大幅降低了编程负担。
这种软硬件协同优化的策略,不仅简化了开发过程,也加速了AI应用的开发和部署。
业务模式与传统厂商存在显著差异
传统上,英伟达、AMD、英特尔等公司倾向于采用大型台积电晶圆,并将其切割成更小的部分以生产芯片。
然而,Cerebras却选择了一种截然不同的路径,它保留了晶圆的完整性。
在当前高度互联的计算集群中,数以万计的GPU或AI加速器协同工作以处理复杂问题。
Cerebras的策略将芯片数量减少50倍以上,从而显著降低了互连和网络成本,同时减少了功耗。
在英伟达GPU集群中,这些集群配备了Infiniband、以太网、PCIe和NVLink交换机,大量的电力和成本消耗在重新链接芯片上。
通过维持整个芯片的完整性,Cerebras有效地解决了这一问题。
凭借WSE-3,Cerebras继续巩固其作为全球最大单芯片生产者的地位。
这款芯片呈正方形,边长达到21.5厘米,几乎占据了整个300毫米硅片的面积。
将Cerebras的设计理念与拼图游戏进行类比,可以清晰地揭示其创新之处。
传统的芯片制造过程类似于将拼图切成小块并逐一拼接,而Cerebras的方法则更像是保持拼图的完整性,使得各部件之间的连接更加紧密,从而提升了整体效率和性能。
这种前瞻性的设计理念为WSE-3芯片的成功提供了坚实的基石。
结尾:
综合评估,WSE-3标志着人工智能芯片设计领域的新趋势,它以单片规模之巨实现了性能与效率的显著提升。
对于其他公司而言,若要复制此类产品,必须在晶圆制造、封装互连、系统集成及软件栈等多个领域投入长期的研发努力,并克服众多威廉希尔官方网站 难关。
Cerebras之所以能够在市场中脱颖而出,其关键在于这些领域中所展现的持续创新能力及突破。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19265浏览量
229671 -
晶圆
+关注
关注
52文章
4895浏览量
127936 -
晶体管
+关注
关注
77文章
9684浏览量
138091 -
AI芯片
+关注
关注
17文章
1882浏览量
34995 -
DDR5
+关注
关注
1文章
422浏览量
24143
原文标题:热点丨最强AI芯片发布,Cerebras推出性能翻倍的WSE-3 AI芯片
文章出处:【微信号:World_2078,微信公众号:AI芯天下】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
天玑9400生成式AI威廉希尔官方网站 太牛了!打造最强AI体验

NEO推出3D X-AI芯片,AI性能飙升百倍
后摩智能引领AI芯片革命,推出边端大模型AI芯片M30
AI初创公司Cerebras秘密申请IPO
AI初出企业Cerebras已申请IPO!称发布的AI芯片比GPU更适合大模型训练

risc-v多核芯片在AI方面的应用
世界第一AI芯片发布!世界纪录直接翻倍 晶体管达4万亿个
Cerebras推出性能翻倍的WSE-3 AI芯片
Cerebras Systems推出迄今最快AI芯片,搭载4万亿晶体管
Cerebras发布WSE-3 AI芯片,性能翻倍达4万亿晶体,能耗不变
Cerebras推出WSE-3 AI芯片,比NVIDIA H100大56倍

Cerebras推WSE-3芯片,性能翻倍,助力超大规模AI模型训练






 工商网监
工商网监
评论