 以太网存储网络的拥塞管理连载案例(五)
以太网存储网络的拥塞管理连载案例(五)
本文节选自《DetectingTroubleshooting, and PreventingCongestion in Storage Networks 存储网络中拥塞处理》
Troubleshooting Congestion in Lossless Ethernet Networks
解决无损以太网网络拥塞问题的方法与光纤通道结构相同。两者都使用逐跳流量控制机制,只是实现方式不同而已。当交换端口显示出口拥塞时,拥塞的根源在于下游流量路径。当交换端口显示入口拥塞时,一定是因为该交换机上的一个或多个端口在出口方向拥塞。
Goals
正如第4 章详细介绍的那样,故障排除的目标有两个:
1. 确定拥塞的来源(元凶)和原因:调查和故障排除的主要目标是确定是否存在拥塞、拥塞源和拥塞原因,拥塞原因可能是慢耗尽(通过高TxWait(如果可用)或快速递增的暂停计数检测到)或过度利用(通过高出口利用率或微爆发事件检测到)。一旦知道了拥塞的来源和原因,就可以对造成拥塞的终端设备进行详细调查。
2. 确定受影响的设备(受害者):次要目标是识别受到罪魁祸首设备不利影响的设备。这些就是受害者。在调查完成之前,您可能不知道设备是罪魁祸首还是受害者。请记住,有时识别不同的受害者类型(直接受害者、间接受害者和同路径受害者)会有所帮助。有关详细信息,请参阅第4 章"识别受影响设备(受害者)"一节。
重要的是要明白,受害设备可能会将性能下降报告为罪魁祸首设备。但问题只能通过调查罪魁祸首而不是受害者来解决。
Congestion Severities and Levels
第4 章定义了光纤通道结构的拥塞严重程度和级别。但它们不能直接用于无损以太网网络,因为与光纤通道不同,无损以太网没有链路(信用)重置的概念,而链路(信用)重置是光纤通道中严重(3 级)拥塞的症状。另一个原因是,如果环境中的设备没有检测这些情况的度量标准,将它们分为不同等级的实际意义就很有限。值得注意的例子是TxWait 和RxWait 指标,在撰写本文时,大多数以太网端口都没有这些指标。因此,与光纤通道不同,使用TxWait 无法检测到1 级拥塞。
总之,对于无损以太网,不同严重程度的拥塞症状可略作如下调整:
1. 轻度拥塞(1 级):延迟增加,但不丢帧。
a. 检测暂停帧数或TxWait/RxWait (如果有)是否过多以及链路利用率是否过高。
2. 中度拥塞(2 级):延迟和丢帧增加。
a. 检测无损级中的丢包情况
3. 严重拥塞(3 级):延迟增加、丢帧和流量持续停顿。
Methodology
我们建议按严重程度递减的方式排除拥塞故障。请注意,这些拥塞严重程度并不是标准化的。它们的唯一目的是帮助用户制定实用的工作流程,从而有助于快速准确地检测和排除拥塞故障。您可以根据自己的环境进行定制。例如,如果没有检测3 级拥塞的简便方法,可先调查2 级拥塞(数据包丢弃),然后再调查1 级拥塞(暂停帧计数或TxWait(如果有))。
有关详细信息,请参阅第4 章"故障排除方法- 降低电平"部分。在将第4 章中的信息应用于无损以太网时,请记住Rx 信用不可用与光纤通道中的入口拥塞相同,后者在以太网网络中由Tx Pause 检测到。同样,Tx 信用不可用等同于光纤通道中的出口拥塞,而以太网网络中的Rx 暂停可检测到出口拥塞。
建议同时学习第4 章的案例研究。虽然这些案例是针对光纤通道描述的,但从中可以了解到无损以太网网络的故障排除方法是如何类似的。
Troubleshooting Congestion in Spine-Leaf Topology
请参阅图7-14,它是图7-8 脊叶网络网络的一个子集。正如前面"无损脊叶网络中的拥塞"一节所解释的,一个罪魁祸首可能会使许多设备受害,而这些受害设备的用户也可能会报告性能下降。因此,自然要从最先报告问题的地方开始排除故障,即受害设备或其连接的交换端口。无论从哪里开始,重要的是要追踪拥塞的源头,同时寻找严重性较高的事件,然后是严重性较低的事件(3 级2 级1 级)。
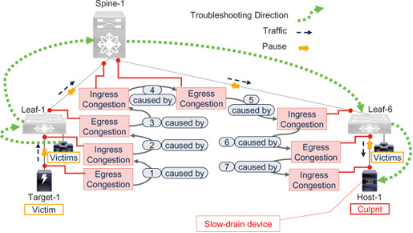
Figure 7-14Congestion troubleshooting direction in a lossless spine-leaf network
假设连接到Leaf-1 的受害主机上的应用程序报告性能下降。这些是间接受害者,因为它们接收来自目标-1 的流量,而目标-1 是罪魁祸首主机-1 的直接受害者。但在故障排除结束之前,这一点还不得而知。故障排除工作流程如下:
1. 转到受害主机直接连接的交换端口。如果发现出口拥塞症状(Rx 暂停或出口丢包),那么这台主机就是罪魁祸首。
2. 如果没有,请在同一交换机的任何其他边缘端口上查找入口拥塞症状(Tx 暂停)。如果发现这样的设备(Target-1),它一定在向罪魁祸首(Host-1)发送流量(如果只有一个拥塞事件或罪魁祸首)。
3. 然后,在Leaf-1 的上游端口上查找出口拥塞症状。
4. 转到其中一个上游设备(例如Spine-1)。Spine-1 发送的Tx 暂停应与Leaf-1 上游端口上的Rx 暂停一致。如果它们的值不一致,请调查位错误或固件错误。
5. 在Spine-1,查找有出口拥塞症状(Rx 暂停)的端口。这些端口通常会传输从显示入口拥塞的端口接收到的流量。
6. 转到流量路径中的下一个设备(Leaf-6)。Leaf-6 发送的Tx 暂停应与Spine-1 上的Rx 暂停一致。如前所述,如果它们的值不同,则应调查位错误或固件错误。
7. 在Leaf-6 上,查找有出口拥塞症状(Rx 暂停或出口丢包)的边缘端口。这应该是连接到罪魁祸首主机(Host-1)的交换端口。如果未发现Rx 暂停或出口丢包,则调查端口是否过度使用。
在任何设备上,如果有更多端口出现出口拥塞症状,应先处理较严重的症状。例如,先处理丢包后处理Rx 暂停。同样,如果TxWait 不可用,应先处理快速增加的暂停计数,再处理缓慢增加的暂停计数。
Reality Check
图7-14 所示的故障排除工作流程需要进行实际检查,原因如下。
1.此故障排除工作流程只能在拥塞状况持续期间使用,因为与Cisco MDS 交换机和Nexus 7000/7700 交换机不同,大多数以太网交换机(包括Cisco Nexus 9000 交换机)不保留带有时间和日期戳的拥塞事件历史记录。
2. 由于大多数以太网交换机不报告TxWait 和RxWait 的百分比,因此即使实时排除故障也很繁琐。在Cisco Nexus 9000 交换机和Cisco UCS 服务器上,命令输出中只有累计暂停计数。用户必须多次执行这些命令并手动计算差值,如例7-7 所示。为数百个端口执行这些步骤既困难又耗时,而且容易出错。试想一下,在图7-8 中可能有数百个端口的脊柱交换机上手动计算这一结果。
3. 正如前面有关暂停帧数的章节所述,暂停帧数的名义增长并不一定表示拥塞。
4. 请注意,造成拥塞的原因可能不止一个。如果造成拥塞的原因在不同的交换机上,那么可能会有不止一条路径。
5. 最后,在手动解释暂停帧数时,如果拥塞条件停止,由于事件没有时间和日期标记,因此无法知道其计数何时增加。
由于这些原因,使用命令行界面很难排除无损以太网网络拥塞的故障。
Troubleshooting Congestion using a Remote Monitoring Platform
通过使用远程监控平台,可以改变在无损以太网网络中排除拥塞故障时令人不快的现实,该平台可持续轮询暂停帧的数量,以保存带有时间和日期戳的历史记录。
UCS 流量监控(UTM) 应用程序就是此类应用程序的一个示例。有关详细信息,请参阅第9 章。UTM 应用程序可以使用比较分析、踩点和季节性等方法近乎实时地检测拥堵情况并排除故障。
Comparative Analysis
比较网络端口(主机端口和交换机端口)的暂停帧速率,检测是否有几个端口的暂停帧数比其他端口高得多。
在图7-8 中,有数千台主机、
1. 每60 秒从边缘交换端口或主机轮询一次Tx 和Rx 暂停。
2. 计算累计暂停帧数的delta 值,了解60 秒内的变化情况。
3. 按"Tx 暂停"降序排列主机,或按"Rx 暂停"降序排列边缘交换端口。
4. 调查该列表中排名前10 位的主机。通常情况下,这些主机的慢排空严重程度较高。
应在所有类似实体中使用相同的比较分析。例如,将所有骨干端口相互比较,检测是否有几个端口报告了过多的暂停帧。
Trends and Seasonality
暂停帧对无损以太网网络的运行非常重要,因此其正常活动是没有问题的。但要仔细分析任何峰值和谷值。此外,还要查找暂停帧计数在过去几天或几周内是否一直在上升,尽管可能不会出现任何突然的峰值。此外,还要查找是否存在季节性,即暂停帧数的峰值是否出现在一天中的特定时段或一周中的特定日子,甚至一年中的特定月份。
从图表上看,低计数的直线就可以了。注意峰值,尤其是持续时间较长的大峰值。
Monitoring a Slow-drain Suspect
可疑设备是发送暂停帧的终端设备。但它不一定是罪魁祸首。可以肯定的是,我们需要更多的信息,因为如前所述,仅仅计算暂停帧的数量并不能说明传输到底停止了多长时间。
根据我们的经验,以下几种方法有助于判断嫌疑人是否也是罪魁祸首。
1. 不发送暂停帧的终端设备不是慢排空的来源。可以将这些设备排除在可疑设备列表之外,从而只关注那些发送暂停帧的设备。
2. 终端设备每秒最多只有几百个暂停帧(如少于300 个)并不会使其成为可疑设备。但是,当暂停帧速率增加到每秒数百或数千的大倍数时,终端设备就会成为可疑设备。每秒数百万个暂停帧无疑会使终端设备非常接近于罪魁祸首,因此应积极监控。
3. 检查上游端口的拥塞扩散症状。例如,在脊叶拓扑结构中,主机暂停帧速率的峰值是否与位于主机流量路径上的骨干交换机端口的暂停帧速率峰值一致?如果是,则表明拥塞正在蔓延,因此主机是罪魁祸首。如果不是,则表明主机只是瞬间暂停了流量,因此不会成为罪魁祸首。
4. 比较终端设备在两个(或多个)端口上发送暂停帧的速率。通常情况下,它们的速率应该是一致的。但如果一个端口每秒发送数百个暂停帧,而另一个端口每秒发送数百万个暂停帧,或出现类似的非均匀暂停帧速率,则需要进行调查。
5. 高暂停帧速率或暂停帧速率的增加必须与终端设备上层的事件相关联。例如,终端设备上的I/O 错误、应用性能下降、I/O 完成时间增加和IOPS 减少。这种关联必须在网络中的可疑终端设备(发送暂停帧)和其他终端设备(不发送暂停帧)上进行。这是因为,如果可疑设备真的是罪魁祸首,那么由其造成的拥塞就会扩散,使许多其他终端设备受害。
6.网络端口的过多Tx 暂停帧应导致该链路的Rx 流量降低。如果结果与此不同,则可能表明暂停帧没有到达流量发送方,或者没有被正确处理,或者是在没有TxWait/RxWait 的情况下,仅使用暂停帧数量检测拥塞的局限性,这在前面有关PFC 风暴的章节中已有解释。需要记住的要点是比较暂停帧和相反方向的流量。
Monitoring an Over-utilization Suspect
正如第1 章"定义完全使用率vs 高使用率vs 过度使用率"和"监控完全使用率vs 高使用率vs 过度使用率"两节所述,我们建议将任何高使用率(如超过80%)情况与过度使用率同等对待。这是因为,根据我们的经验,大多数高使用率情况也有一定的过度使用时间。要确定高使用率是否导致拥塞,可监控上游端口的暂停帧。但在开始调查时,除非另有证明,否则应将高使用率情况与过度使用情况同等对待。这种方法节省了检测拥塞和寻找解决方案的时间。
FC and FCoE in the Same Network
有些交换机,如Cisco Nexus 9000 交换机、Nexus 5000/6000 交换机和Cisco UCS Fabric Interconnect 可以有FC、FCoE(无损)和以太网(有损)端口。这些交换机以类似于前面解释的方式将拥塞从流量控制出口端口扩散到流量控制入口端口。唯一不同的是流量控制机制,因此检测拥塞的指标也不同。
请注意,FC 端口使用Rx B2B 信用不可用检测入口拥塞,使用Tx B2B 信用不可用检测出口拥塞。有关光纤通道指标的详细解释,请参阅第3 章。
FCoE 端口(无损以太网)使用"Tx 暂停"检测入口拥塞,使用"Rx 暂停"检测出口拥塞。前面关于拥塞检测指标的章节解释了这些指标。
ConsiderFigure 7-15with the following components.
有损以太网:没有逐跳流量控制(如PFC 或LLFC)的骨干网络。这部分网络的流量依靠其他机制(如OSI 模型第4 层的TCP)进行拥塞控制。
无损光纤通道:具有B2B 流量控制功能的边缘核心光纤通道Fabric。MDS-1 连接存储阵列(Target-1 和Target-2)。
融合(有损+无损)以太网:有损以太网网络和光纤通道结构共享叶子交换机(L-4 和L-6)。它们有专用的以太网上行链路(无流量控制)连接到骨干交换机,光纤通道上行链路连接到MDS-1。下行链路连接到一个或多个FEX(FEX-4 和FEX-6),最终连接到主机。叶子到FEX 链路和FEX 到主机链路使用PFC。无损FC/FCoE 流量保持在无丢包类别中,而有损以太网流量保持在不受流控制的其他类别中。
FEX 代表思科Fabric Extender。从外形上看,它像一个交换机,但实际上像一个远程模块。它需要一个父交换机来实现控制功能(如路由协议)和管理功能(如配置端口)。父交换机和FEX 之间的链接使用SFP 和电缆,并运行逐跳流量控制(如PFC)。这与ISL 类似。因此,在处理拥塞时,可将FEX 视为交换机,尽管从一般意义上讲,FEX 本身可能并不符合交换机的条件。
图7-15 是思科UCS 架构的近似表示。叶子交换机代表Fabric Interconnects,FEX 代表I/O 模块(IOM),主机代表服务器。有关Cisco UCS 服务器的详细信息,请参阅第9 章。
让我们分析Host-1 和Host-2 造成的拥塞事件,并遵循故障排除方法。
Congestion Spreading due to Slow-Drain
在图7-15 中,Host-1 是一个慢速排空设备,因为它的无损流量处理速率低于向其传送帧的速率。因此,它会向FEX-4 发送PFC 暂停帧,以降低无损类别的流量速率。无损类之外的流量不受流量控制,因此在队列满时可能会被丢弃。
当超过FEX-4 的暂停阈值时,它会向L-4 发送PFC 暂停帧,以降低不丢弃类的流量速率。但L-4 的上行链路(入口端口)运行光纤通道。当其缓冲区耗尽时,它会降低向上游邻居(MDS-1)发送R_RDY 的速率。最后,MDS-1 降低向目标发送R_RDY 的速率,以减少来自目标的流量。
Congestion Spreading due to Over-Utilization
请看图7-15 中的主机-2。它没有造成慢排空,但在其交换端口的出口方向上造成了100% 的使用率,这可能会因过度使用而导致拥塞。用前面解释过的类似方法从MDS-1 追逐拥塞源时,在到达FEX-6 后,可能找不到任何有Rx 暂停增量的出口端口。在这种情况下,请查找正在以高出口利用率运行的端口,这是过度利用导致拥塞的迹象。这样就能找到罪魁祸首Host-2。
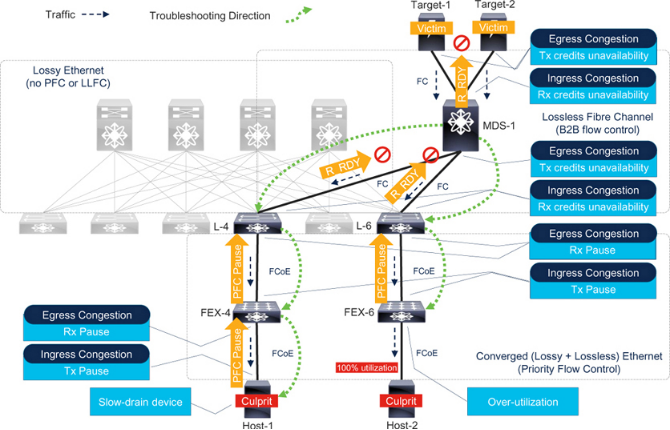
Figure 7-15Congestion troubleshooting workflow with FC and FCoE in the same network
请注意以下几点:
1. FC 和FCoE 混合网络中拥塞的蔓延情况与仅有FC 或仅有FCoE 的网络类似。
2. 在FEX-4 和FEX-6 的上行链路上,排空缓慢和过度使用也会导致类似的症状。即使在L-4、L-6 和MDS-1 上也无法找到拥塞原因。只有FEX-4 和FEX-6 上的边缘链路能明确区分拥塞原因,因为它们直接连接到拥塞源(罪魁祸首终端设备)。
3.无损以太网链路(L-4 和L-6 下行链路)和光纤通道链路(L-4 和L-6 上行链路)的拥塞故障排除方法与前面解释的相同。不同之处在于,L-4 和L-6 交换机本身需要追寻拥塞源。在这些交换机上,入口(FC)端口使用光纤通道指标,出口(以太网)端口使用PFC 指标。它们的命令不同。执行这两种命令,检查交换机上FC 和FCoE 流量的出口拥塞情况。
4. 在图7-15 中,如果L-4 不在上行FC 端口(例如Cisco UCS Fabric Interconnects)上提供入口拥塞检测指标,则可以使用MDS-1 上的出口拥塞检测指标。同样,如果Host-1 不监控Tx 暂停帧(或监控起来不够方便),则可选择监控FEX-4 上的Rx 暂停。
Bit Rate Differences between FC and FCoE
交换机在FC 和FCoE 端口之间传输流量时,必须仔细考虑比特率的差异。如第2 章"光纤通道比特率"、"光纤通道速度与比特率之间的差异"和表2-4 所述,某些光纤通道比特率与宣传的速度有很大差异。例如,8GFC 端口的比特率为8.5 Gbps,但考虑到8b/10b 编码,只能以6.8 Gbps 的速度传输数据。这使得10 GbE 的"速度"几乎比8GFC 快50%。因此,当FCoE 流量从10 Gbps 以太网端口切换到8GFC 端口时,可能会出现速度不匹配导致的拥塞。当流量从16GFC 端口(比特率为14.025 Gbps)切换到工作速率为10 Gbps 的FCoE 端口时,会出现另一种常见的拥塞情况。正如本章所述,速度或容量不匹配程度越高,拥塞就越容易发生和蔓延。
虽然无法完全消除以太网和光纤通道在比特率上的差异,但必须尽可能地缩小它们之间的差距,例如32GFC 和25 GbE。除了端口速度外,还应考虑共享FCoE 链路的最低带宽保证,因为FC/FCoE 流量可能不允许占用链路的全部容量。
对于带有FC 和FCoE 端口的交换机,如Cisco UCS Fabric Interconnect(参见第9 章),这应该是一个设计层面的决策。初步设计完成后,应持续监控流量模式,并根据需要增加额外容量。
Multiple no-drop Classes on the Same Link
当无损以太网网络中启用了多个无损类时,请按照每次一个类(CoS)的拥塞故障排除方法进行操作。
图7-15 中的融合拓扑只为FCoE 流量设置了一个无损类。在同一拓扑中,可为RoCEv2 流量启用另一个无损类。
请参阅图7-16。存储阵列连接到叶子交换机(L-1),并为RoCEv2 进行了配置。主机-1 和主机-2 通过FEX-4 连接到叶子L-4。这些主机以分配给CoS 5 流量的无损类访问RoCEv2 存储。脊叶拓扑现在可为CoS 5 流量提供PFC。RoCEv2 流量使用IP 标头中的DSCP 字段进行分类,从而实现前面所述的第3 层PFC。不过,为简单起见,本节假定RoCEv2 是表7-1 中CoS 到DSCP 映射的CoS 5 流量。
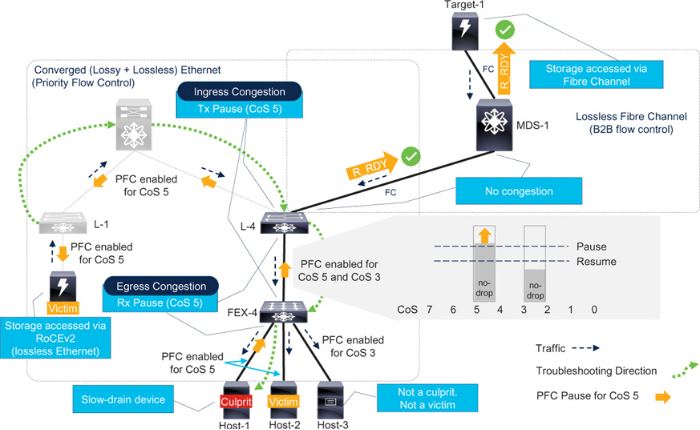
Figure 7-16Congestion troubleshooting with multiple no-drop classes
FCoE 主机(Host-3)连接到FEX-4,并将FCoE 流量分配到CoS 3。FEX-4 和L-4 将CoS 3 流量分配到专用的无损类。在L-4 上,CoS 3 流量通过光纤通道上行链路发送。
总之,在此拓扑中,L-4 和FEX-4 之间的链路为两个无损类配置了PFC,分别分配给CoS 5 和CoS 3。因此,交换端口创建了两个独立的无损队列,分别有自己的暂停阈值和恢复阈值。
当Host-1(RoCEv2 主机)成为慢排空设备时,它会发送CoS 5 的PFC 暂停帧。当FEX-4 的暂停阈值超过CoS 5 队列时,它只向L-4 发送CoS 5 的PFC 暂停帧。结果,Host-2(另一台使用CoS 5 的RoCEv2 主机)因L-4 和FEX-4 之间的共享链路拥塞而受害。
L-4 不会接收CoS 3 的PFC 暂停帧,因此不会减慢CoS 3 流量。因此,FCoE 主机(Host-3)不会受到影响。
在L-4 上,拥塞只扩散到CoS 5 上行链路(骨干交换机),而不扩散到光纤通道上行链路。
总之,启用多个不丢包类别时,应分别注意每个类别的拥塞症状。分析L-4 上每个端口的暂停计数器可能会导致错误的方向。只在CoS 5 中排除故障可以找到拥塞源(Host-1)。
Bandwidth Allocation Between Lossless and Lossy Traffic
回想一下,增强传输选择(ETS,除PFC 外)是使融合(有损+无损)以太网取得成功的重要功能,因为它为无损类提供带宽保证,同时与其他类别的流量共享链路。
请注意以下有关使用ETS 分配带宽的要点:
1. 每个无损类别都预留了最少数量的缓冲区。
2. 无损类别会被分配一个最小带宽,例如链路容量的50%。但这并不是"无损"类所能达到的最大带宽。当其他类没有流量时,流量类最多可占用100% 的链路容量。
3. 但是,当其他类别有流量时,无损类别的带宽分配就会受到限制(假设为50%)。这可能会因过度使用而造成拥塞。
4. 端口在无损等级中的传输容量为50%,在其他等级中的传输容量为50%。
5.当端口已按各流量等级的带宽分配满负荷传输时,例如无损等级的流量为50%,其他等级的流量为50%、
a. 如果交换机上的其他端口接收到的有损类流量超过了该端口的发送量,多余的流量就会像有损网络一样被丢弃。
b. 如果交换机上的其他端口接收到更多要从该端口发送出去的无损类流量,则接收到多余流量的端口会在暂停阈值处发送一个暂停帧。每个入口端口都维护有自己的暂停阈值、恢复阈值和净空的无损队列。这种情况就像过度使用造成的拥塞,并导致拥塞扩散。
Effect of Lossy Traffic on no-drop Class
一个常见的误解是,有损类中的流量不会影响无损类。这取决于处理问题的方式。
无损类的流量可以消耗100% 的容量。但是,当其他类有流量时,它就会被限制在保证带宽内。换句话说,以前不会造成拥塞的链路,在其他(有损耗)类别的流量增加后,可能会开始造成拥塞(由于过度使用)。例如,考虑一条10 GbE 链路,其中5 Gbps 分配给无损类,5 Gbps 分配给其他类。如果不存在其他流量,无损类中的无损流量可以消耗掉链路的全部容量。但是,如果其他流量需要2 Gbps,无损流量将被限制在8 Gbps。这台交换机现在必须将其他端口的入口速率均衡为8 Gbps,而之前的速率为10 Gbps。为实现速率均衡,交换机会调用PFC,导致拥塞扩散。
如果只监控I/O 吞吐量,这种情况就不容易理解了。早期,10 Gbps 的I/O 吞吐量不会造成拥塞。后来,仅8 Gbps 就会造成拥塞。
由于这些原因,在融合存储网络甚至共享存储网络中确定过度使用情况要比专用存储网络困难得多。再也不能通过出口百分比利用率来确定过度利用。在链路级别上分别监控每类流量和每类拥塞情况,以及将两者结合起来,有助于更好地理解和检测此类问题。
Case Study 1 — An Online Gaming Company
一家在线游戏公司将融合以太网网络用于无损存储I/O 流量和有损TCP/IP 流量。他们的服务器以10 GbE 连接网络,50% 的带宽分配给无损类。他们的链路利用率很少超过90%。
他们报告了以下观察结果:
许多应用程序都报告了性能下降。
问题只在工作时间出现。
在同一时间段内,他们发现了一台CPU 高的服务器,但这台服务器的链接利用率从未超过70%。在这台服务器上运行的应用程序的所有者怀疑存在存储访问问题。
CPU 高并不是有力的证据,但应用程序所有者怀疑是存储问题。他们没有在主机上看到任何I/O 错误。为了验证网络拥塞情况,他们检查了该服务器链接上的暂停帧计数。他们发现,在问题持续期间,服务器发送了很多暂停帧。此外,连接该服务器的交换机也在其上行链路上进一步发送暂停帧。这是拥塞的扩散,可能会使许多其他服务器受害。
接下来,他们想找到在链路利用率保持在70% 以下的情况下,该服务器出现高Tx Pause 的原因。他们开始监控每个类的流量利用率,并在问题持续期间发现了以下情况:
1. 服务器入口链路利用率从5 Gbps 提高到7 Gbps。
2.每级流量监测显示
a. 无损类的流量从2 Gbps 降至1.5 Gbps。
b. 其他(有损)类别的流量从3 Gbps 增加到5.5 Gbps。
根据这些观察结果,我们怀疑其他(有损)流量的增加可能会导致CPU 使用率过高,从而没有足够的资源来处理存储I/O。因此,服务器试图减慢入口I/O 流量,这一点从暂停帧的数量和整个I/O 的减少可以看出。
为了验证这一理论,他们将该应用程序移到了一台CPU 数量更多的强大服务器上。这一改变之后,应用程序不再遇到性能问题。有损类流量保持在3 Gbps 至5.5 Gbps 之间。无损类的平均流量为2 Gbps。暂停帧数保持在最低水平,没有出现任何峰值或骤降。服务器的CPU 使用率也不高。
除了说明监控每个端口和每个类流量利用率的重要性外,本案例研究还展示了全栈可观测性如何帮助更快、更准确地检测拥塞问题。但全栈可观察性并不是本案例研究的目的。真正的教训是,当有损类的流量增加时,可能也会导致无损类的拥塞。在本案例中,真正的问题出在网络之外,也就是服务器的CPU 容量,但其影响却体现在网络上,使许多其他服务器也深受其害。
不能一概而论地认为CPU 高会导致I/O 性能问题。只有在本案例研究中,CPU 高才会导致问题。影响I/O 性能的原因还有很多。本案例研究的关键是了解有损耗类流量对无丢包类的影响。
Case Study 2 — Converged Versus Dedicated Storage Network
本案例研究与案例研究1 相似。不同之处在于服务器的CPU 利用率不再很高。此外,无损类的平均流量为6 Gbps(60%),有损类的平均流量为2 Gbps(20%)。当报告应用性能下降时,持续时间也与会聚链路的100% 利用率相吻合。对每类流量利用率进行调查后发现,有损类的流量从2 Gbps 激增到5 Gbps。同时,无损类的流量从6 Gbps 下降到5 Gbps。这是因为在这条10 GbE 链路上,无损类被分配了5 Gbps(50%)的带宽保证。但该交换机其他端口上无损流量的总入口速率仍为6 Gbps。为了将这些流量均衡到5 Gbps,该交换机调用了PFC,从而导致拥塞扩散。交换机上接收边缘端口发送流量的其他端口上的Tx 暂停帧峰值证实了这一点。
在本案例研究中,明显的问题是融合链路的容量不足,以及无损和有损类之间的流量争用。通过增加另一条10 GbE 链路,这一问题得以解决。
在本案例研究中,两种类型的流量(有损和无损)都使用两条链路,这是共享存储网络的方法。另一种有效的方法是将一条链路专用于有损(普通级)流量,另一条链路专用于无损(无丢包级)流量,这就是专用存储网络的方法。
正确答案在于链路的容量和这些链路的预期吞吐量。专用存储网络是一种不同的架构,需要以不同的方式进行操作。其优点在于结构的独立性、可扩展性、故障隔离和更易于故障排除。相反,专用存储网络的部署成本更高,需要更多资源来管理和运行。
-
以太网
+关注
关注
40文章
5419浏览量
171618 -
交换机
+关注
关注
21文章
2638浏览量
99545 -
PFC
+关注
关注
47文章
971浏览量
106045 -
UTM
+关注
关注
0文章
29浏览量
13068 -
存储网络
+关注
关注
0文章
31浏览量
8100
原文标题:以太网存储网络的拥塞管理连载(五)
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
以太网存储网络的拥塞管理连载方案(一)
以太网存储网络的拥塞管理连载方案(二)
以太网存储网络的拥塞管理连载方案(三)
以太网存储网络的拥塞管理连载案例(六)



以太网供电新标准促热网络化电源管理应用市场
以太网光纤通道(FCoE)威廉希尔官方网站 问答
以太网的分类及静态以太网交换和动态以太网交换、介绍
以太网光模你了解多少
优化网络管理与监控——工业以太网交换机的智能化之路






 工商网监
工商网监
评论