 优化高性能CPU的ICG延迟设置
优化高性能CPU的ICG延迟设置
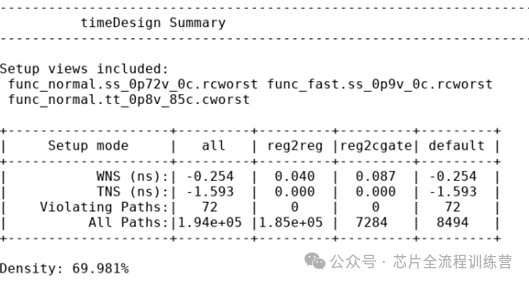
report_timing -path_type full_clock

请问这里SDC为何约束到了ICG的CP端外,还约束了ICG的Q端?假设注释掉Q端的约束,如下图,会有什么问题?

去掉后,timing报告如下,明显setup timing变差了很多。
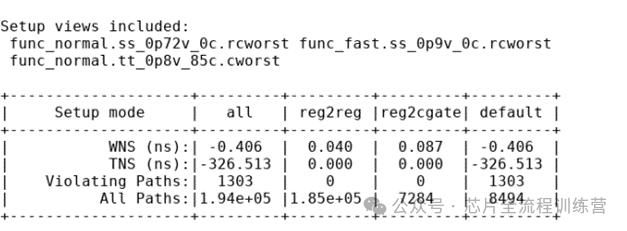
report_timing -path_type full_clock
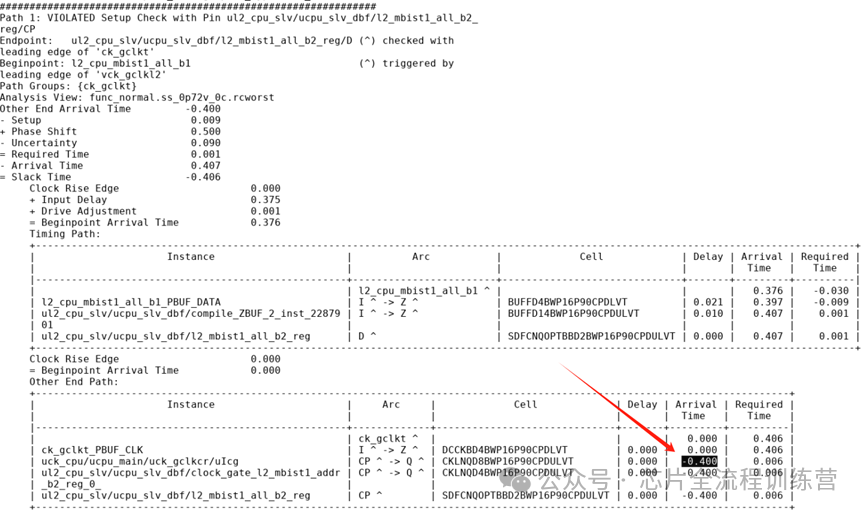
因此,约束ICG的latency为-400ps,目的是把ICG从reg拉开400ps,如果不约束ICG的Q,那么工具为了minimize skew,会默认ICG后面所有的reg的CLK的latency和ICG是一样的-400ps。此时,时钟还是是理想的。因此需要给ICG的Q端也约束上latency,此处约束为-50ps。不经过这个ICG的CLK pin默认latency为0。
注意,ICG本身容易setupviolation,默认icg 和reg 越近越好。
“2.5GHz频率,12nm工艺,DVFS低功耗A72后端培训”
01
12nm Cortex-A72后端实战
本项目是真实项目实战培训,低功耗UPF设计,后端参数如下:
工艺:12nm
频率:2.5GHz
资源:2000_0000instances
低功耗:DVFS
为了满足广大学员的诉求,我们将12nm A72 TOP课程分为两个版本:
1、基础版(价格是知名机构的1/5,全国最低价)
2、进阶版(低功耗、hierarchy UPF、Stampling)!业界最先进威廉希尔官方网站 !
进阶版本的低功耗设计如下:7个power domain
Stampling打起来真是高级手工艺术,全网唯一:
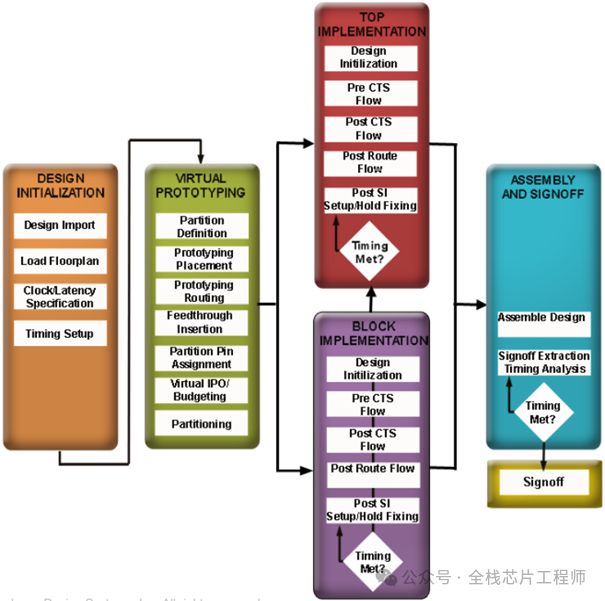
Flow:PartitionFlow
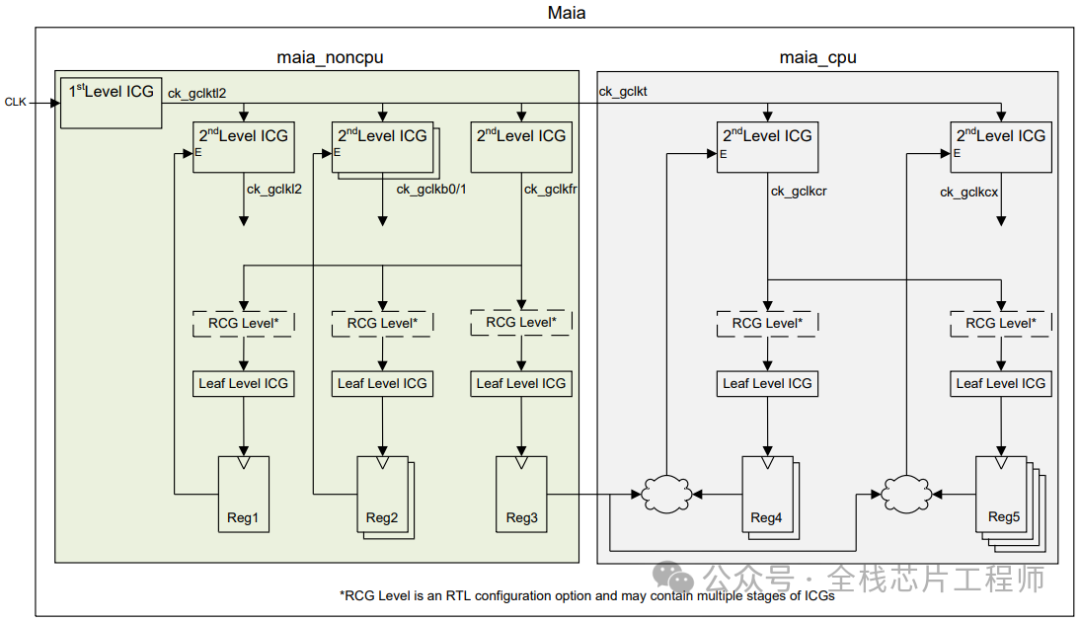
时钟结构分析:
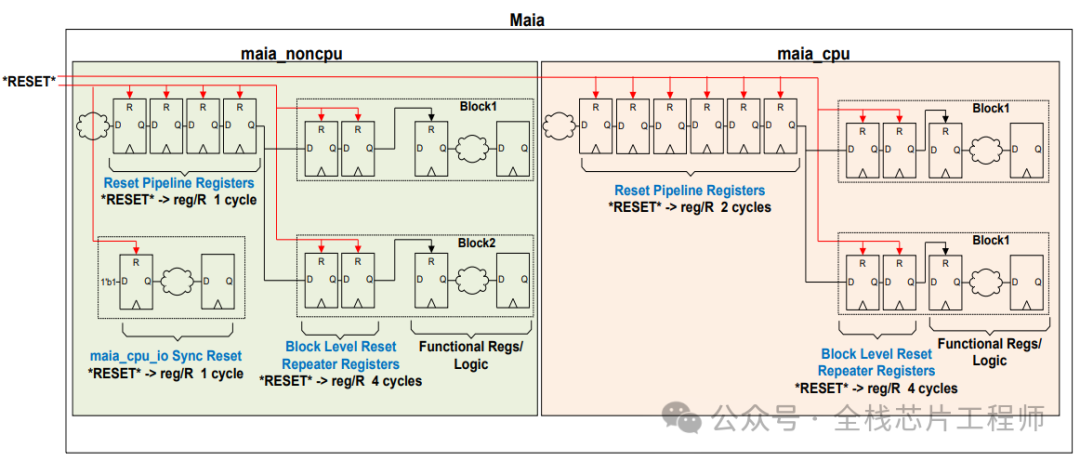
复位结构分析:
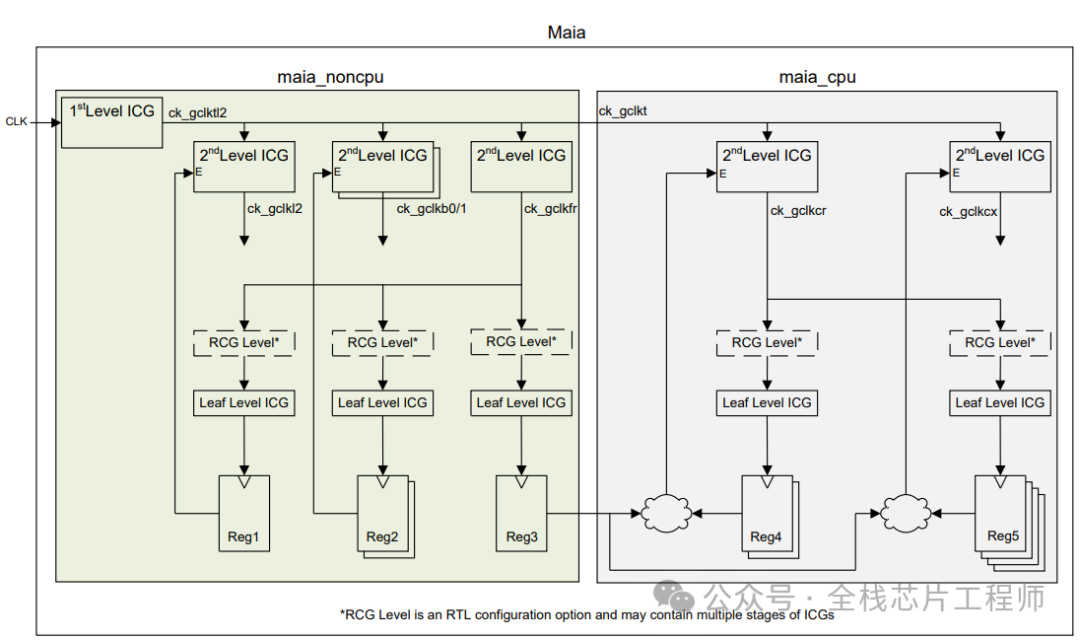
12nm 2.5GHz的A72实战训练营需要特别设置Latency,TOP结构如下,参加过景芯SoC全流程训练营的同学都知道CRG部分我们会手动例化ICG来控制时钟,具体实现参见40nm景芯SoC全流程训练项目,本文介绍下12nm 2.5GHz的A72实战训练营的Latency背景,欢迎加入实战。
时钟传播延迟Latency,通常也被称为插入延迟(insertion delay)。它可以分为两个部分,时钟源插入延迟(source latency)和时钟网络延迟(Network latency)。
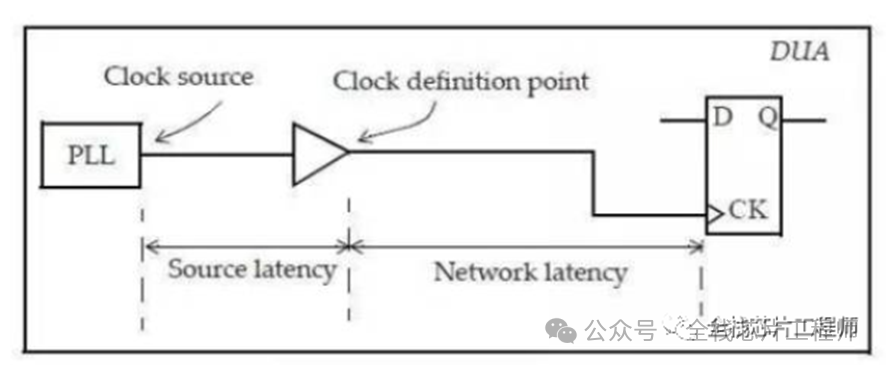
大部分训练营同学表示平时都直接将Latency设置为0了,那latency值有什么用呢?其实这相当于一个target值,CTS的engine会根据你设置的latency值来插入buffer来实现你的latency target值。
下图分为1st Level ICG和2nd Level ICG,请问这些ICG为什么要分为两层?
请问,为什么不全部把Latency设置为0?2nd Level ICG的latency应该设置为多少呢?
latency大小直接影响clock skew的计算。时钟树是以平衡为目的,假设对一个root和sink设置了400ps的latency值,那么对另外的sink而言,就算没有给定latency值,CTS为了得到较小的skew,也会将另外的sink做成400ps的latency。请问,为何要做短时钟树?因为过大的latency值会受到OCV和PVT等因素的影响较大,并有time derate的存在。
审核编辑:黄飞
-
cpu
+关注
关注
68文章
10873浏览量
212093
原文标题:高性能CPU的ICG Latency设置
文章出处:【微信号:全栈芯片工程师,微信公众号:全栈芯片工程师】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
CPU和GPU频率的查看及设置
AutoKernel高性能算子自动优化工具
怎样去设置电脑电源的高性能模式呢
怎么把电源计划设置为高性能呢
《现代CPU性能分析与优化》---精简的优化书
《现代CPU性能分析与优化》--读书心得笔记
高性能CPU时钟网络设计
Linux CPU的性能应该如何优化
CPU与内存延迟的关系分析 影响CPU性能差距的因素
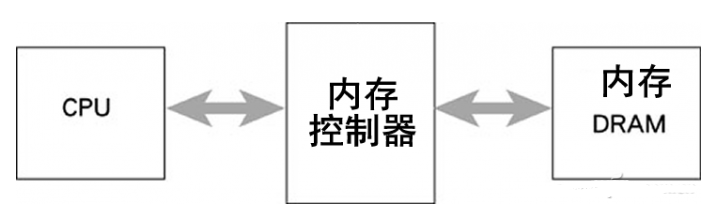
突破性能瓶颈,实现CPU与内存高性能互连
CPU程序几个优化程序性能的手段详解






 工商网监
工商网监
评论