 大语言模型事实性幻象的实验性分析
大语言模型事实性幻象的实验性分析
作者|李军毅 陈杰 机构|中国人民大学
研究方向|自然语言处理
来自| RUC AI Box
尽管大语言模型能力不断提升,但一个持续存在的挑战是它们具有产生幻象的倾向。本文构建了幻象评测基准HaluEval 2.0,并基于该评测框架从预训练/有监督微调/提示设计/推理四个方面探索幻象来源。另外,还通过一系列威廉希尔官方网站 深入研究了减轻LLM幻象的方法。
引言
大语言模型(LLM)在自然语言处理(NLP)的广泛领域中展现出巨大的潜力。然而,尽管模型能力有所提升,但一个持续存在的挑战在于它们具有产生幻象的倾向,即生成看似合理但事实上不准确的内容。这一问题严重限制了LLM在现实世界应用(如临床诊断)中的部署,在这些应用中,生成值得信赖的可靠文本至关重要。
在 LLM 时代,幻象相关的研究显著增加,这些研究主要围绕三个问题展开,即 LLM 为何产生幻象(source),如何检测幻象(detection)以及如何减轻幻象(mitigation)。现有的工作大多集中于分析或解决个别挑战,仍然缺乏系统而深入的对 LLM 幻象的实验分析。为此,我们针对事实性幻象,从幻象的检测、来源和缓解三个方面进行了全面系统的实验性分析。我们的贡献包括:
构建了幻象评测基准 HaluEval 2.0,提出了一个简单有效的幻象自动评估框架。
基于上述评测框架,我们从预训练(pre-training)、有监督微调(supervised fine-tuning)、提示设计(prompt design)和推理(inference)四个方面探索幻象的来源。
我们还通过一系列广泛使用的威廉希尔官方网站 ,包括基于人类反馈的强化学习(RLHF)、检索增强(retrieval augmentation)、反思(self-reflexion)、提示改进(prompt improvement)等,深入研究了减轻 LLM 幻象的方法。
总的来说,我们的工作带来了一系列关于 LLM 幻象的来源和缓解的重要实证发现,构建的幻象评测基准可用于进一步的研究。
幻象评测基准HaluEval 2.0
HaluEval 2.0包括五个领域的 8770 个问题,其中生物医学、金融、科学、教育和开放域的问题数量分别为1535、1125、1409、1701 和 3000。基于 HaluEval 2.0,我们在一些具有代表性的开源和闭源 LLM 上进行了实验:
开源模型:Alpaca (7B), Vicuna (7B and 13B), YuLan-Chat (13B), Llama 2-Chat (7B and 13B)
闭源模型:text-davinci-002/003, ChatGPT, Claude, Claude 2
幻象的检测
我们提出了一个简单而有效的评测框架,用于检测 LLM 回答中的事实性错误。我们将具有挑战性的幻象检测任务分解为两个较简单的子任务:1)从回答中提取多个事实性陈述;2)确定每个陈述是否包含幻象。基于该检测方法,我们可以在 HaluEval 2.0 上对各种 LLM 进行评估。我们设计了两个不同级别的指标来衡量 LLM 回答中包含幻象的程度。
微观幻象率(MiHR)衡量每个回答中幻象陈述的比例:
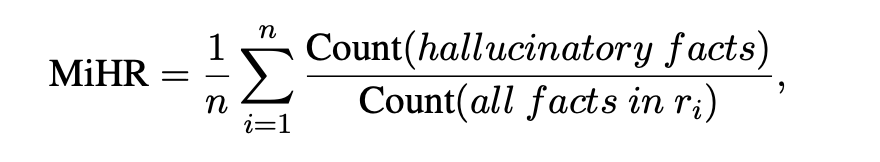
宏观幻象率(MaHR)计算含有幻象陈述的回答比例:
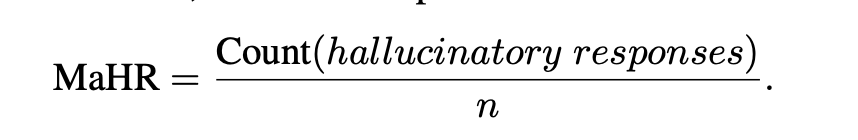
我们在 HaluEval 2.0 上衡量了各种 LLM 产生幻象的倾向,实验结果如下表所示:
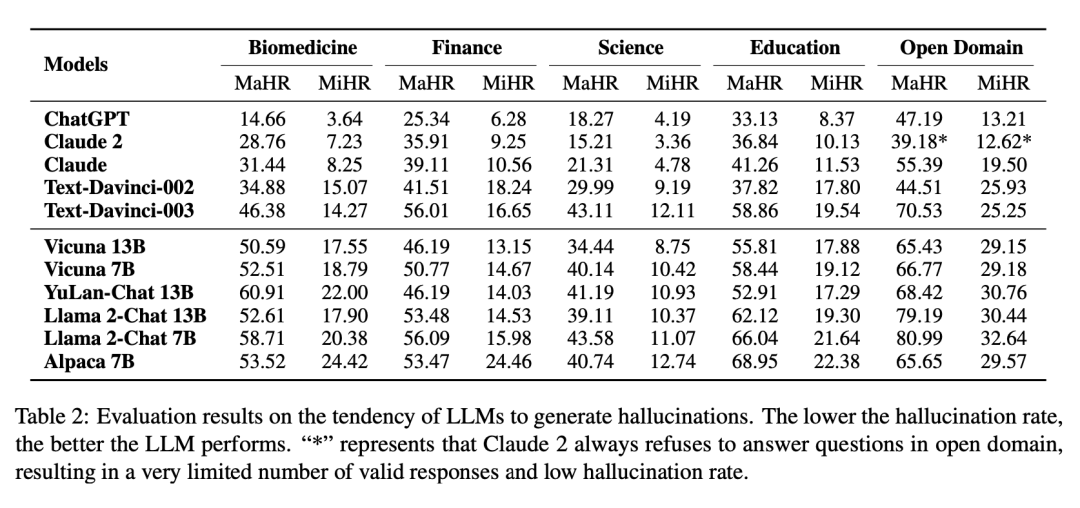
我们可以看到,开源模型和闭源模型之间存在着明显的性能差距。在开源模型中,我们可以发现扩大模型规模可以有效降低产生幻象的倾向。另外我们发现,MaHR 和 MiHR 的正相关性并不强,这是因为有些模型倾向于用较少的事实生成较短的回答,从而减少幻象的发生,但同时也减少了回答中信息的丰富性。更多的实验结论与分析详见论文。
幻象的来源和缓解
我们进行了广泛的实验,从预训练(pre-training)、有监督微调(supervised fine-tuning)、提示设计(prompt design)和推理(inference)四个方面探索可能诱发 LLM 幻象的因素:

我们研究了基于人类反馈的强化学习(RLHF)、检索增强(retrieval augmentation)、反思(self-reflexion)、提示改进(prompt improvement)等广泛使用的方法减轻 LLM 幻象的有效性:

下面是各部分的实验结论,更多的实验细节、结果和分析详见论文。
预训练:在更多 tokens 上进行预训练对减少 LLM 幻象的影响较小,而将专业数据(如科学文本)纳入预训练则可以极大地减轻特定领域的幻象。预训练知识的频率对幻象的来源有很大影响,即频率越低,幻象越多。
微调:通过改进指令对 LLM 进行有监督微调有助于减轻幻象。平衡指令的复杂性有利于减少幻象,而使用过于复杂的指令则会导致更高水平的幻象。RLHF 是减轻 LLM 幻象的有效方法,但其效果依赖于所在领域。
推理:在专业领域如医学,以多样性为导向的解码方法会诱发更多幻象,而在开放领域,贪心搜索会加剧幻象。逐个 token 生成的方式可能会让 LLM 在先前生成错误的基础上继续出现错误,从而导致幻象。量化虽然加快了推理速度,但在很大程度上也会导致 LLM 幻象的产生。
提示设计:在任务描述中加入更多细节并利用上下文学习可以减少幻象的产生。改写问题或将任务描述放在问题之后会诱发更多幻象。对于更易读和表达更正式、更具体的问题,LLM 产生幻象的倾向较低。
审核编辑:汤梓红
-
开源
+关注
关注
3文章
3333浏览量
42481 -
语言模型
+关注
关注
0文章
523浏览量
10273 -
自然语言处理
+关注
关注
1文章
618浏览量
13554 -
LLM
+关注
关注
0文章
286浏览量
327
原文标题:HaluEval 2.0:大语言模型事实性幻象的实验性分析
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论