 顶刊TPAMI最全综述!深入自动驾驶BEV感知的魔力!
顶刊TPAMI最全综述!深入自动驾驶BEV感知的魔力!
1. 写在前面
今天笔者为大家推荐一篇BEV感知的最新综述,分析了BEV感知的核心难点,回顾了关于BEV感知的最新工作,并对不同的解决方案进行了深入分析,还描述了来自工业界的几种BEV方法的系统设计。
下面一起来阅读一下这项工作~
2. 摘要
在鸟瞰图( bird ' s-eye-view,BEV )中学习强大的表征用于感知任务是一种趋势,并引起了工业界和学术界的广泛关注。大多数自动驾驶算法的传统方法在前方或视角视图中执行检测、分割、跟踪等。随着传感器配置越来越复杂,集成来自不同传感器的多源信息并在统一视图中表示特征变得至关重要。BEV感知继承了几个优点,因为在BEV中表示周围的场景是直观的和融合友好的;而在BEV中表示对象是后续模块在规划和/或控制中最需要的。BEV感知的核心问题在于:( a )如何通过视角到BEV的视角转换来重建丢失的三维信息;( b )如何获取BEV网格中的真实标注;( c )如何制定管线以纳入来自不同来源和视图的特征;( d )随着传感器配置在不同场景中的变化,如何适应和推广算法。在这项调查中,我们回顾了关于BEV感知的最新工作,并对不同的解决方案进行了深入分析。此外,还描述了来自工业界的几种BEV方法的系统设计。此外,我们还介绍了一套完整的实用指南,以提高BEV感知任务的性能,包括相机、激光雷达和融合输入。最后,指出了该领域未来的研究方向。我们希望本报告能给社区带来一些启示,并鼓励更多关于BEV感知的研究工作。
3. 文章结构
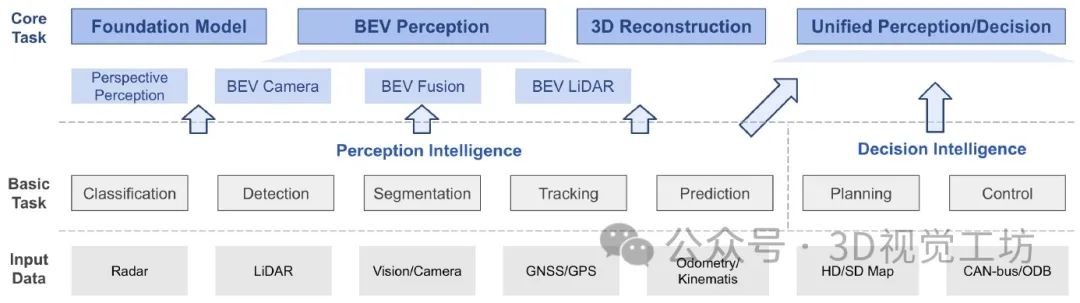
BEV感知的任务总结,包括输入数据总结、底层任务总结,还有核心任务总结。
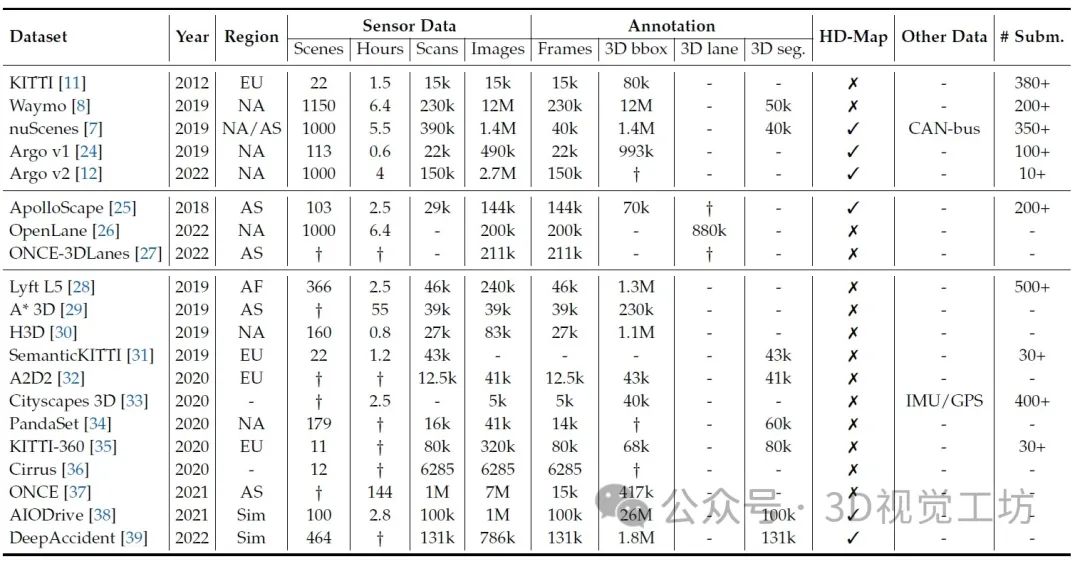
BEV感知数据集总结。
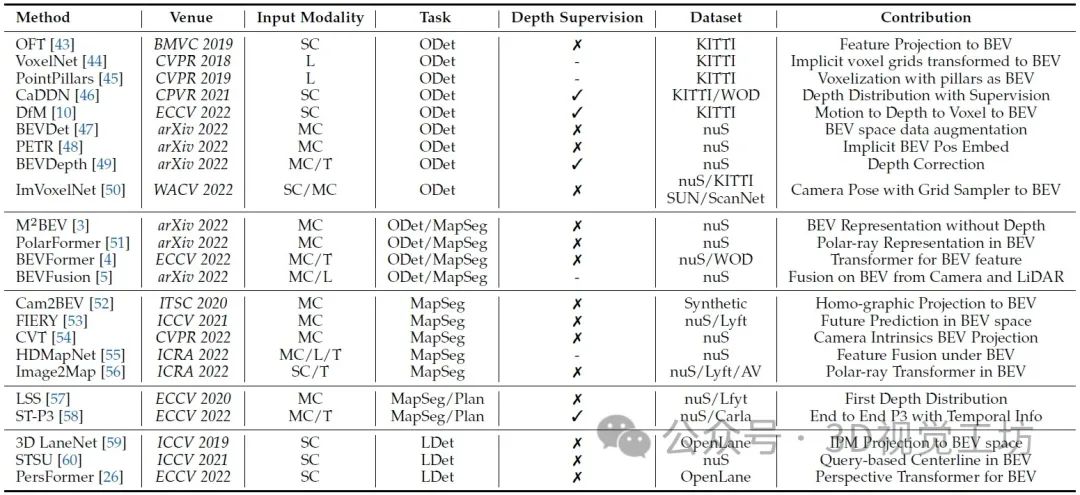
BEV感知的主要工作。在输入模态下," L "为LiDAR," SC "为单相机," MC "为多相机," T "为时间信息。在Task下,' ODet '用于3D目标检测,' LDet '用于3D车道线检测,' MapSeg '用于地图分割,' Plan '用于运动规划,' MOT '用于多目标跟踪。
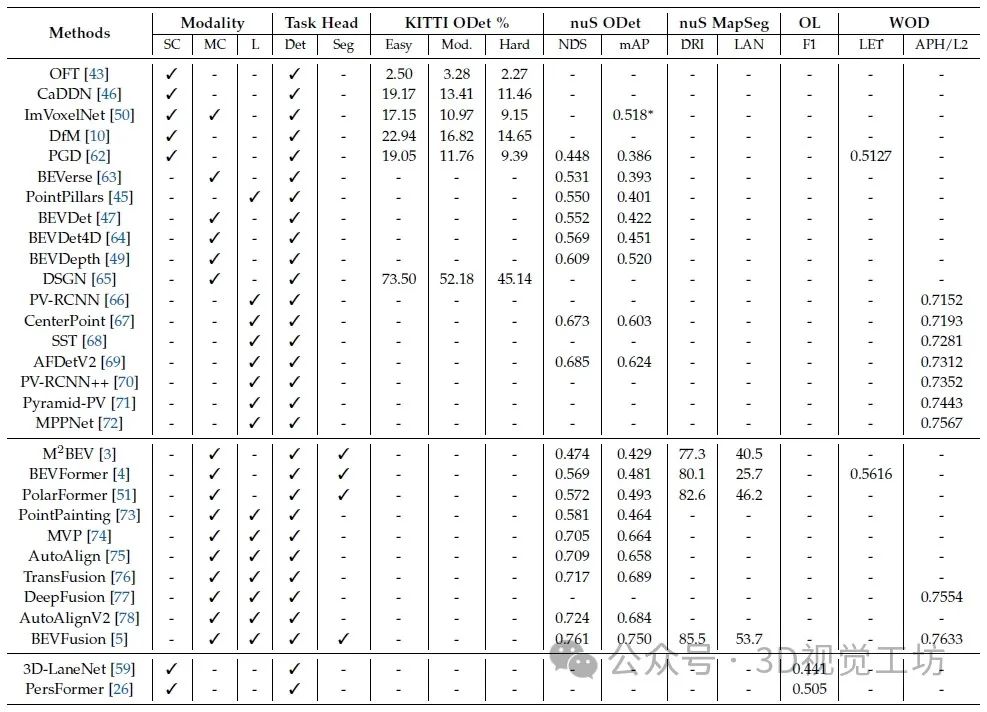
BEV感知算法在主流基准上的性能比较。
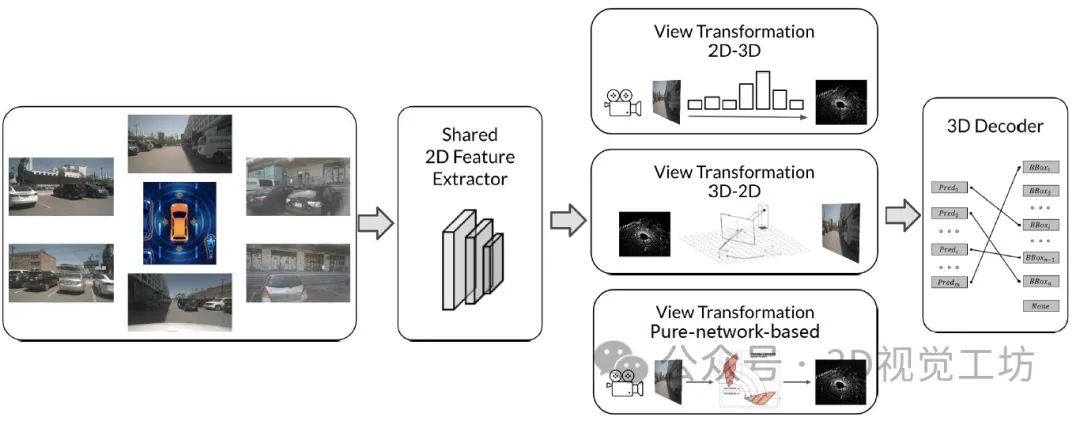
视觉BEV感知的通用框架。包括2D特征提取器、视图转换和3D解码器3个部分。在视图转换中,有两种方式对3D信息进行编码- -一种是从2D特征中预测深度信息;另一种是从3D空间采样2D特征。
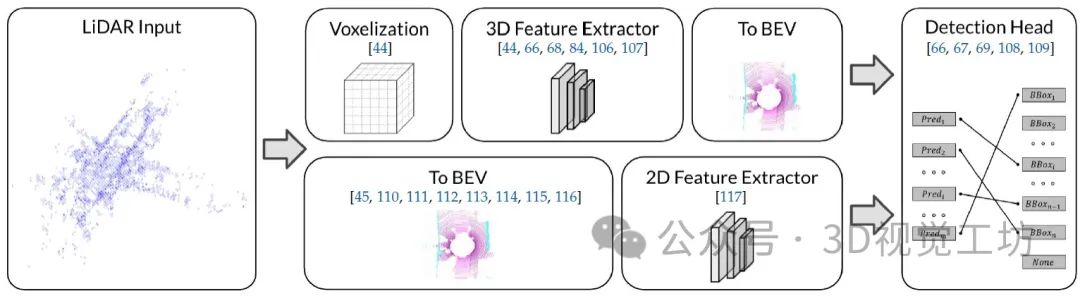
LiDAR BEV感知的通用框架。将点云数据转换为BEV表示主要有两个分支。上层分支提取三维空间中的点云特征,提供更准确的检测结果。下层分支在2D空间中提取BEV特征,提供更高效的网络。
视觉BEV感知检测任务。

LiDAR BEV感知分割任务。
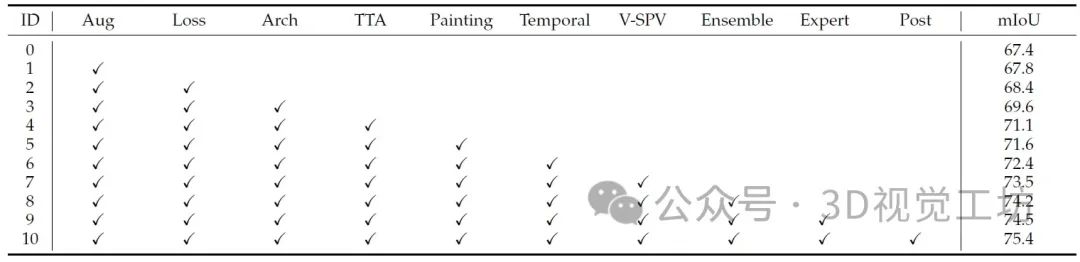
4. 总结
这篇综述对近年来的BEV感知进行了全面的回顾,作者认为未来的发展趋势是:( a )如何设计一个更精确的深度估计器;( b )如何在一种新的融合机制中更好地对齐来自多个传感器的特征表示;( c )如何设计一个无参数的网络,使得算法的性能不受姿态变化或传感器位置的影响,从而在各种场景中获得更好的泛化能力;以及( d )如何从基础模型中整合成功的知识,以促进BEV的感知。
-
传感器
+关注
关注
2550文章
51056浏览量
753259 -
算法
+关注
关注
23文章
4608浏览量
92853 -
自动驾驶
+关注
关注
784文章
13794浏览量
166415
原文标题:顶刊TPAMI最全综述!深入自动驾驶BEV感知的魔力!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
浅析基于自动驾驶的4D-bev标注威廉希尔官方网站

标贝科技:自动驾驶中的数据标注类别分享

标贝科技:自动驾驶中的数据标注类别分享

自动驾驶中一直说的BEV+Transformer到底是个啥?

聊聊自动驾驶离不开的感知硬件
FPGA在自动驾驶领域有哪些优势?
FPGA在自动驾驶领域有哪些应用?
自动驾驶识别威廉希尔官方网站 有哪些
深度学习在自动驾驶中的关键威廉希尔官方网站
未来已来,多传感器融合感知是自动驾驶破局的关键
黑芝麻智能开发多重亮点的BEV算法威廉希尔官方网站 助力车企高阶自动驾驶落地

BEV感知算法:下一代自动驾驶的核心威廉希尔官方网站
BEV和Occupancy自动驾驶的作用

自动驾驶领域中,什么是BEV?什么是Occupancy?

自动驾驶感知算法提升处理策略





 工商网监
工商网监
评论