 模型与人类的注意力视角下参数规模扩大与指令微调对模型语言理解的作用
模型与人类的注意力视角下参数规模扩大与指令微调对模型语言理解的作用
01
研究动机
近期的大语言模型(LLM)在自然语言理解和生成上展现出了接近人类的强大能力,远远优于先前的BERT等预训练模型(PLM)。然而,尚不清楚这是否意味着模型的计算过程更加接近了人类的语言感知方式。此前的研究表明,与人类行为和神经数据具有更高相关性的模型,在自然语言任务上的表现也越好[1],但在大模型威廉希尔官方网站 井喷的当下,最新、性能最强的大模型是否仍然与人类数据相关,也需要进一步检验。
同时,LLM较PLM等先前模型等能力提升的背后机制尚不清楚。由于现有LLM的基本架构与先前模型一样是Transformer架构,因此这种提升很可能来自与训练过程的差异:可能来自于扩大了的参数和数据规模,也可能来自于预训练后的指令微调。
为了解决上述的两方面问题,本文尝试比较LLM与人类阅读时行为数据的相关性,通过比较扩大规模与指令微调两个因素对于LLM语言理解过程的作用,帮助人们更好地认识LLM的运行机制。由于自注意力(self-attention)机制是Transformer模型的关键机制,并且天然与人类的注意力机制在形式上相似,因此适合用来分析和解释模型的计算过程。本文收集了现有的不同种类(LLaMA,Alpaca,Vicuna)不同大小(7B到65B)的开源LLM在英文文本上的自注意力矩阵进行对比分析,并计算了它们与人类阅读相同文本时的眼动数据的相关性,有效分析了两个因素的作用。
02
贡献
本文的分析主要包括三方面:一,我们逐层计算了不同LLM在所选文本数据上的注意力分布差异;二,我们评估并比较了不同LLM与人类眼动数据的相似度;三,我们分析了模型注意力矩阵对常见平凡特征的依赖性,并展示了这种依赖性与模型语言理解特点的关系。本文的主要发现有:
1)规模扩大可以显著改变模型在普通文本上的注意力分布,而指令微调对此的改变较为有限。然而,指令微调可以提高模型对指令前缀的敏感程度;
2)LLM的人类相似度越高,语言建模的能力也越好。规模扩大对人类相似度的提高基本符合缩放法则[2],而指令微调反而降低了人类相似度。同时,虽然所有模型都以英文为主训练,但它们都与英语为第二语言的人群(L2)有更高的相似度,而不是母语人群(L1);
3)规模扩大可以显著降低模型对平凡特征的依赖性,而指令微调不能。同时,L2的眼动模式也比L1更加依赖于平凡特征。
03
方法
3.1 比较不同模型的注意力差异
我们使用Jensen-Shannon (J-S) 散度来比较不同模型在相同输入句子上的注意力分布差别。比较具有相同层数的模型时,我们逐层计算此J-S散度;比较具有不同层数的模型时,我们分别将两个模型的层平均分为4部分,比较每个部分的平均注意力的J-S散度。
为了帮助判断J-S散度的大小,我们提出用Vicuna v0 与 v1.1的注意力J-S散度作为其他比较的参考值。两个模型拥有一致的架构、大小与训练数据,只是数据格式有较小的差别。当其他两个模型的J-S散度大于此参考值时,我们认为这是注意力模式上的较大差别,反之则是较小的差别。
此J-S散度也被用来比较模型在普通文本与指令文本上的注意力分布差别。我们在普通文本的每个句子前加上指令前缀,如“Please translate this sentence into German:”,并在计算J-S散度时将前缀部分的注意力分数忽略,计算添加指令前后,模型注意力的J-S散度。同时,我们还使用了一个噪声前缀进行同样的实验,作为控制组,更好地评价指令前缀的影响。
3.2 模型与人类眼动的相似度
人类眼动数据的形式如图1所示。我们将模型的每个注意力头作为一个自变量,将人类注意力作为目标,建立线性回归模型,计算此模型的拟合分数,并与人类被试之间的拟合分数作商,作为人类相似度分数。
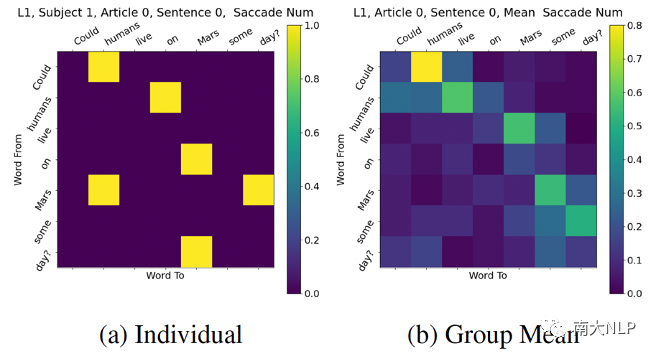
图1 单人与群体平均的眼动矩阵示例
3.3 平凡特征依赖性
已有研究表明,Transformer模型的注意力模式可能包含一些简单、固定的特征,包括每个词都关注句子中第一个词、每个词都关注自身、每个词都关注前一个词等[3,4]。我们将这三种平凡特征作为自变量,人类注意力与模型注意力分别作为目标,建立线性回归模型,同样计算拟合分数,作为对这三种平凡特征的依赖性的度量。
04
实验
我们使用了Reading Brain数据集[5]中的文本和人类行为数据。文本数据包括5篇英语说明文,人类行为数据包括52名英语母语者与56名非母语者的数据。对于眼动数据,我们使用眼跳动次数,而不是注视时间,以减少其他因素(如单词长度)对眼动数据的影响。对于LLM,我们选用了774M(GPT-2 Large),7B(LLaMA, Alpaca, Vicuna),13B(LLaMA, Alpaca, Vicuna),65B(LLaMA)的多个模型。
4.1 模型注意力分布差异
随着参数规模扩大,模型注意力分布发生显著变化,而指令微调的作用有限。图2展示了不同大小模型的J-S散度结果。结果显示,LLaMA,Alpaca和Vicuna模型均在7B与13B大小之间显示出较大的注意力分布差异,说明参数规模扩大对整体注意力分布有较大改变。图3展示了经过指令微调(Alpaca,Vicuna)与未经过(LLaMA)的模型注意力的J-S散度结果。结果表明,只有Vicuna 13B模型较微调前产生了高于参考值的注意力散度,说明指令微调对整体注意力分布的影响有限。
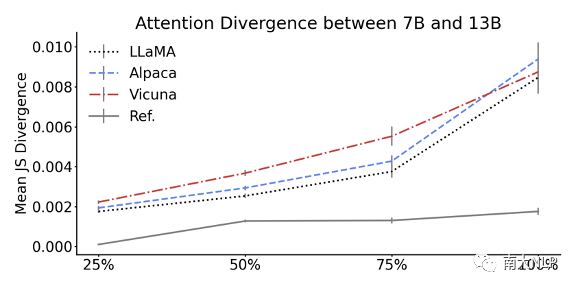
图2 7B与13B模型注意力的平均J-S散度
然而,指令微调提高了模型对指令前缀的敏感程度。图4显示了不同模型在普通文本与指令文本上的注意力J-S散度,可以发现,所有模型均在两种文本上显示出了高于参考值的注意力差异,但这种差异在LLaMA(未经过指令微调)的深层逐渐衰减,在Alpaca和Vicuna的深层却保持在较高水平。这种现象在噪声前缀的场景下没有出现。这说明在指令微调前,模型已经具备了一定的识别指令前缀的能力,但这种能力主要集中在模型浅层;在指令微调后,模型识别指令前缀的能力向深层移动,因此能对模型的生成过程产生更直接的改变。
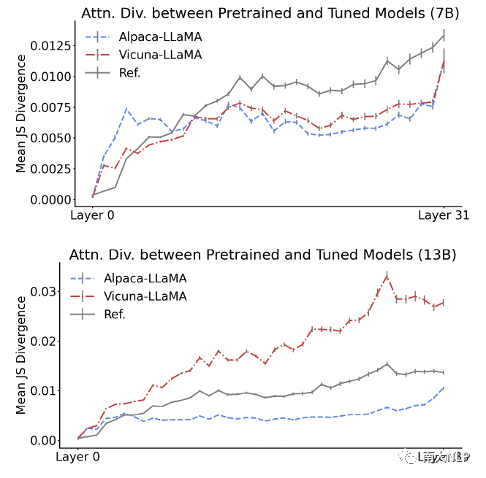
图3 经过与未经过指令微调的模型注意力的J-S散度
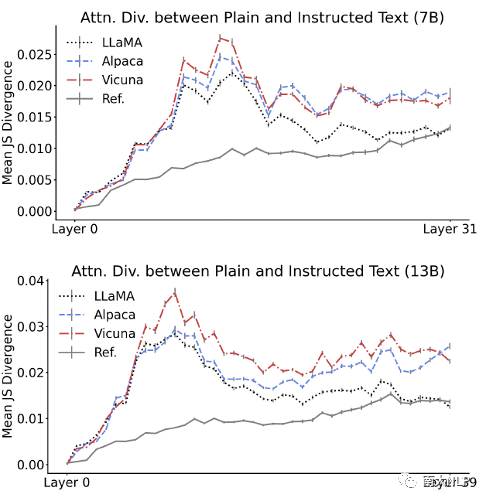
图4 普通文本与指令文本上的模型注意力的J-S散度
4.2 人类相似度
人类相似度与语言建模能力正相关。图5展示了各个模型在Reading Brain数据集的文本上的下一个单词预测(Next Token Prediction, NTP)损失与它们所有层中最大的人类相似度分数,以及两者的线性关系。可以发现,人类相似度越高,NTP损失越低,即语言建模能力越强。这说明人类相似度分数的确与语言感知能力有关。
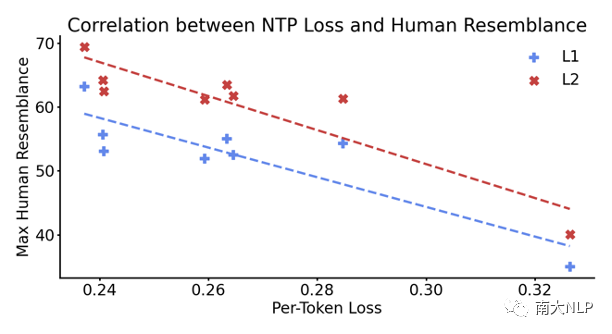
图5 各模型的NTP损失与人类相似度及其相关性
参数规模扩大能够提升人类相似度,而指令微调会降低人类相似度。图6展示了未经过指令微调的不同大小模型(GPT-2 774M到LLaMA 65B)的所有层中,最大的人类相似度分数。可以发现,随着参数规模的指数增加,模型的人类相似度分数约呈现线性提升,符合缩放法则。表1则展示了7B与13B的LLaMA模型在指令微调前后的人类相似度。可以发现,指令微调不仅不能提升人类相似度,反而会造成轻微的降低。相对t检验结果显示,指令微调显著降低人类相似度的层数,远高于显著提升人类相似度的层数。
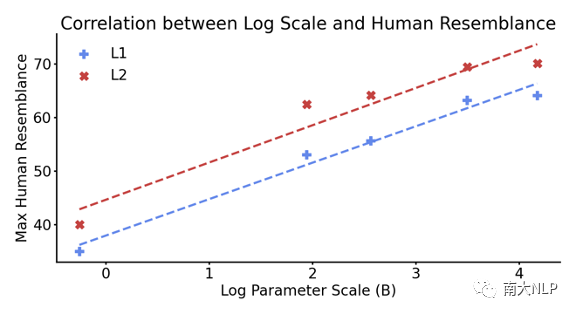
图6 不同大小模型的所有层中最大的人类相似度分数
表1 指令微调前后模型的人类相似度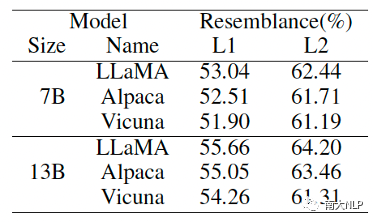
4.3 平凡特征依赖性
参数规模扩大可以降低平凡特征依赖性,而指令微调会提高平凡特征依赖性。图7展示了7B模型到13B模型到平凡特征依赖性分数变化,可以发现尤其在深层,模型的依赖性分数发生了较大下降。反之,图8展示了指令微调前后模型平凡特征依赖性分数的变化,可以发现依赖性分数在深层上升了。这说明参数规模扩大可以让模型的语言理解过程更加灵活,而指令微调则会让其更加固定。
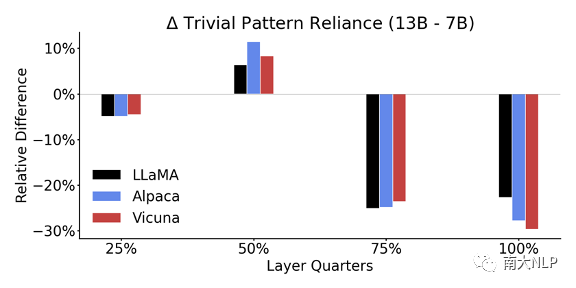
图7 7B到13B大小的平凡特征依赖性分数变化
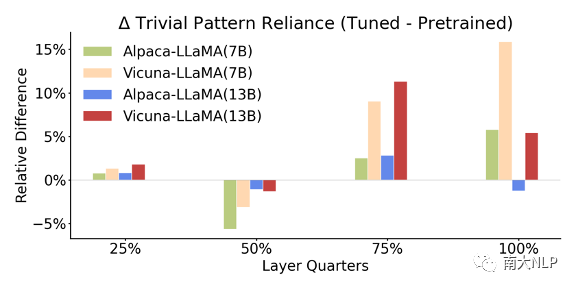
图8 指令微调后的平凡特征依赖性分数变化
L2对平凡特征的依赖程度更高。表2展示了L1与L2人群的眼动模式对平凡特征的依赖性分数。可以发现,L2在最小值、最大值与平均值上均高于L1,独立t检验结果也支持L2分数显著高于L1。这说明非母语人群在阅读英语文本时的眼动模式比母语人群显示出更多的固定、简单模式。
表2 L1与L2的平凡特征依赖性分数,SE为标准差
05
总结
本文评估了参数规模扩大与指令微调对模型在自然语言理解过程中的注意力的影响。我们发现,参数规模扩大可以有效改变模型的整体注意力分布,提高模型的人类相似度,并降低模型对平凡特征的依赖程度;而指令微调基本上起到相反的效果,但也会提高模型对指令内容的敏感性。同时,我们的结果也展示出,目前的以英语为主的开源LLM的注意力模式更接近非英语母语者的眼动模式,提示了当前模型与人类在语言感知上的差异。
审核编辑:刘清
-
PLM
+关注
关注
2文章
121浏览量
20868 -
语言模型
+关注
关注
0文章
523浏览量
10273 -
LLM
+关注
关注
0文章
287浏览量
327
原文标题:EMNLP2023 | 模型与人类的注意力视角下参数规模扩大与指令微调对模型语言理解的作用
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】揭开大语言模型的面纱
【大语言模型:原理与工程实践】核心威廉希尔官方网站 综述
【大语言模型:原理与工程实践】大语言模型的基础威廉希尔官方网站
【大语言模型:原理与工程实践】大语言模型的评测
【大规模语言模型:从理论到实践】- 阅读体验
【《大语言模型应用指南》阅读体验】+ 基础知识学习
基于注意力机制的深度学习模型AT-DPCNN

一种注意力增强的自然语言推理模型aESIM

基于语音、字形和语义的层次注意力神经网络模型

基于多层CNN和注意力机制的文本摘要模型

基于循环卷积注意力模型的文本情感分类方法
PyTorch教程-16.5。自然语言推理:使用注意力






 工商网监
工商网监
评论