 使用自监督学习重建动态驾驶场景
使用自监督学习重建动态驾驶场景

无论是单调的高速行车,还是平日的短途出行,驾驶过程往往平淡无奇。因此,在现实世界中采集的用于开发自动驾驶汽车(AV)的大部分训练数据都明显偏向于简单场景。
这给部署鲁棒的感知模型带来了挑战。自动驾驶汽车必须接受全面的训练、测试和验证,以便能够应对复杂的场景,而这需要大量涵盖此类场景的数据。
在现实世界中,收集此类场景数据要耗费大量时间和成本。而现在,仿真提供了另一个可选方案。但要大规模生成复杂动态场景仍然困难重重。
在近期发布的一篇论文中,NVIDIA Research 展示了一种基于神经辐射场(NeRF)的新方法——EmerNeRF 及其如何使用自监督学习准确生成动态场景。通过自监督方法训练,EmerNeRF 在动静态场景重建上的表现超越了之前其他 NeRF 方法。详细情况请参见 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision。



图 1. EmerNeRF 重建动态驾驶场景的示例
相比其他 NeRF 重建方法,EmerNeRF 的动态场景重建准确率高出 15%,静态场景高出 11%。新视角合成的准确率也高出 12%。
打破 NeRF 方法的局限性
NeRF 将一组静态图像重建成逼真的 3D 场景。这使得依据驾驶日志重建用于 DNN 训练、测试验证的高保真仿真环境成为可能。
然而,目前基于 NeRF 的重建方法在处理动态物体时十分困难,而且实践证明难以扩展。例如有些方法可以生成静态和动态场景,但它们依赖真值(GT)标签。这就意味着必须使用自动标注或人工标注员先来准确标注出驾驶日志中的每个物体。
其他 NeRF 方法则依赖于额外的模型来获得完整的场景信息,例如光流。
为了打破这些局限性,EmerNeRF 使用自监督学习将场景分解为静态、动态和流场(flow fields)。该模型从原始数据中学习前景、背景之间的关联和结构,而不依赖人工标注的 GT 标签。然后,对场景做时空渲染,并不依赖外部模型来弥补时空中的不完整区域,而且准确性更高。

图 2. EmerNeRF 将图 1 第一段视频中的场景分解为动态场、静态场和流场
因此,其他模型往往会产生过于平滑的背景和精度较低的动态物体(前景),而 EmerNeRF 则能重建高保真的背景及动态物体(前景),同时保留场景的细节。
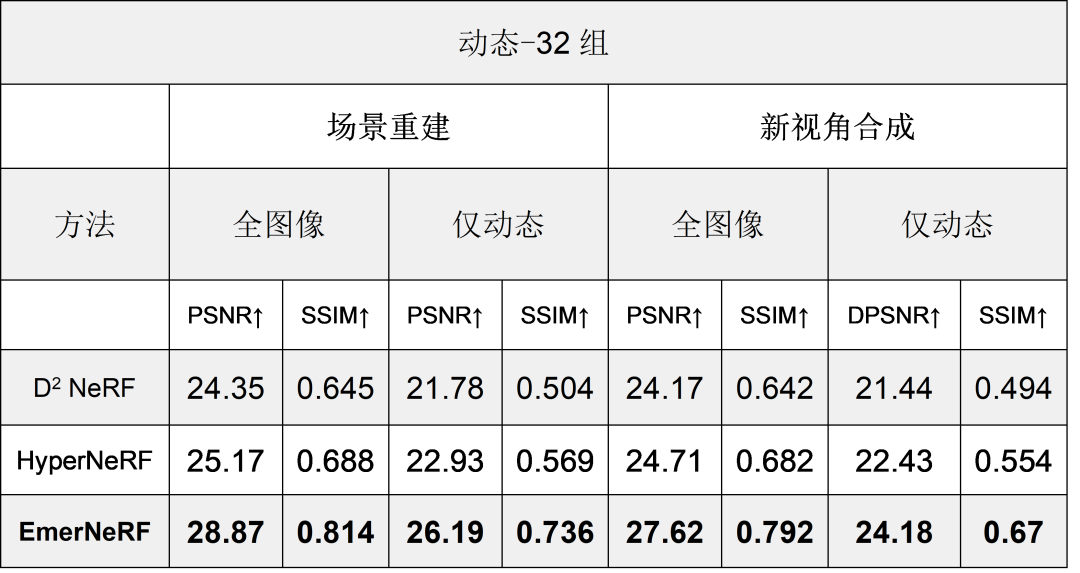
表 1. 将 EmerNeRF 与其他基于 NeRF 的动态场景重建方法进行比较后的评估结果,分为场景重建性能和新视角合成性能两个类别
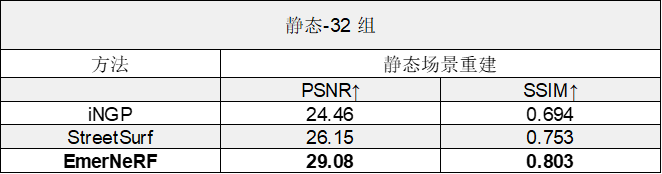
表 2. 将 EmerNeRF 与其他基于 NeRF 的静态场景重建方法进行比较后的评估结果
EmerNeRF 方法
EmerNeRF 使用的是自监督学习,而非人工注释或外部模型,这使得它能够避开之前方法所遇到的难题。
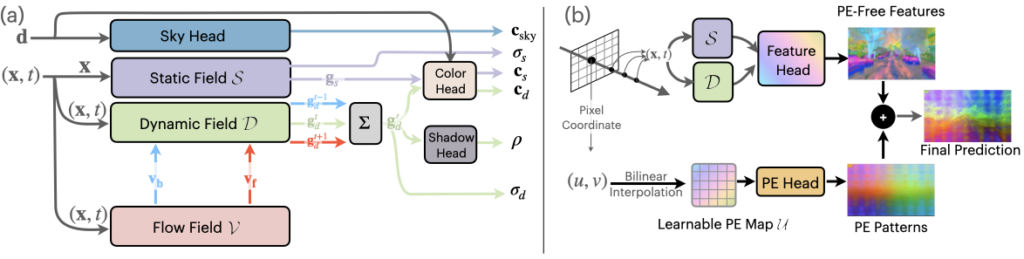
图 3.EmerNeRF 分解和重建管线
EmerNeRF 将场景分解成动态和静态元素。在场景分解的同时,EmerNeRF 还能估算出动态物体(如汽车和行人)的流场,并通过聚合流场在不同时间的特征以进一步提高重建质量。其他方法会使用外部模型提供此类光流数据,但通常会引入偏差。
通过将静态场、动态场和流场结合在一起,EmerNeRF 能够充分表达高密度动态场景,这不仅提高了重建精度,也方便扩展到其他数据源。
使用基础模型加强语义理解
EmerNeRF 对场景的语义理解,可通过(视觉)基础大模型监督进一步增强。基础大模型具有更通用的知识(例如特定类型的车辆或动物)。EmerNeRF 使用视觉 Transformer(ViT)模型,例如 DINO, DINOv2,将语义特征整合到场景重建中。
这使 EmerNeRF 能够更好地预测场景中的物体,并执行自动标注等下游任务。

图 4. EmerNeRF 使用 DINO 和 DINOv2 等基础模型加强对场景的语义理解
不过,基于 Transformer 的基础模型也带来了新的挑战:语义特征可能会表现出与位置相关的噪声,从而大大限制下游任务的性能。

图 5. EmerNeRF 使用位置嵌入消除基于 Transformer 的基础模型所产生的噪声
为了解决噪声问题,EmerNeRF 通过位置编码分解来恢复无噪声的特征图。如图 5 所示,这样就解锁了基础大模型在语义特征上全面、准确的表征能力。
评估 EmerNeRF
正如 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision 中所述,研究人员整理出了一个包含 120 个独特场景的数据集来评估 EmerNeRF 的性能,这些场景分为 32 个静态场景、32 个动态场景和 56 个多样化场景,覆盖了高速、低光照等具有挑战性的场景。
然后根据数据集的不同子集,评估每个 NeRF 模型重建场景和合成新视角的能力。
如表 1 所示,据此,EmerNeRF 在场景重建和新视角合成方面的表现始终明显优于其他方法。
EmerNeRF 的表现还优于专门用于静态场景的方法,这表明将场景分解为静态和动态元素的自监督分解既能够改善静态重建,还能够改善动态重建。
总结
自动驾驶仿真只有在能够准确重建现实世界的情况下才会有效。随着场景的日益动态化和复杂化,对保真度的要求也越来越高,而且更难实现。
与以前的方法相比,EmerNeRF 能够更准确地表现和重建动态场景,而且无需人工监督或外部模型。这样就能大规模地重建和编辑复杂的驾驶数据,解决目前自动驾驶汽车训练数据集的不平衡问题。
NVIDIA 正迫切希望研究 EmerNeRF 带来的新功能,如端到端驾驶、自动标注和仿真等。
如要了解更多信息,请访问 EmerNeRF 项目页面并阅读 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision。
了解更多
-
适用于自动驾驶汽车的解决方案
https://www.nvidia.cn/self-driving-cars/
-
EmerNeRF 项目页面
https://emernerf.github.io/
-
阅读 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision.
https://arxiv.org/abs/2311.02077
GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击“阅读原文”或扫描下方海报二维码,立即注册 GTC 大会。
原文标题:使用自监督学习重建动态驾驶场景
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3775浏览量
91039
原文标题:使用自监督学习重建动态驾驶场景
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
时空引导下的时间序列自监督学习框架

HarmonyOS NEXT应用元服务开发内容动态变化场景
自连数字化健康管理方案应用全场景
神经重建在自动驾驶模拟中的应用

【《大语言模型应用指南》阅读体验】+ 基础知识学习
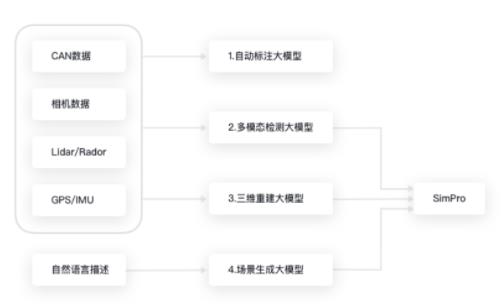
基于大模型的仿真系统研究一——三维重建大模型
神经网络如何用无监督算法训练
深度学习中的无监督学习方法综述
标贝数据采集标注在自动驾驶场景中落地应用实例
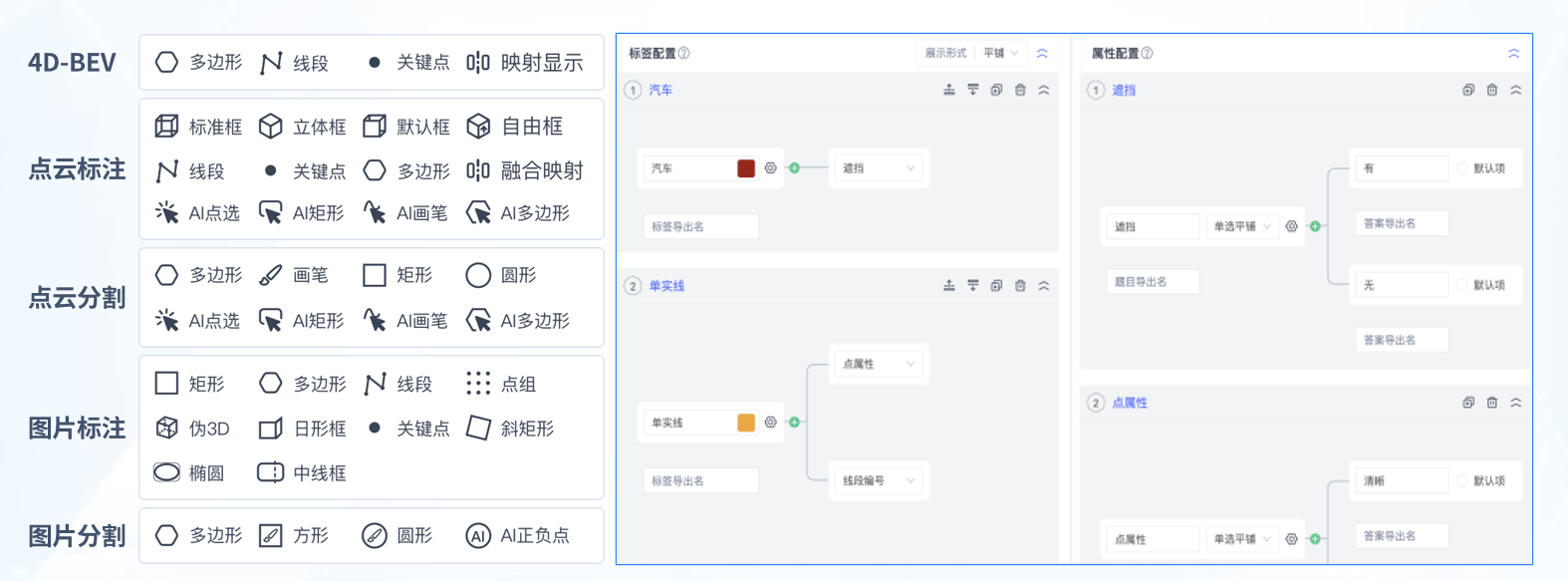
康谋分享 | aiSim5仿真场景重建感知置信度评估(三)

机器学习基础知识全攻略
OpenAI推出Sora:AI领域的革命性突破






 工商网监
工商网监
评论