 简单认识高级处理器
简单认识高级处理器
除了传统的处理器 (CPU、MPU/MCU、DSP 和 GPU),面向当代各种应用的高级处理器(Advanced Processors)层出不穷,例如加速处理单元 (AcceleratedProcessing Unit, APU) 、采用异构系统架构 ( Heterogeneous System Architecture,HSA) 特征设计的集成电路、基于人工神经网络(Artificial Neural Networks,ANN) 深度学习 (Deep Learning)的高级处理器等。
1. 加速处理单元
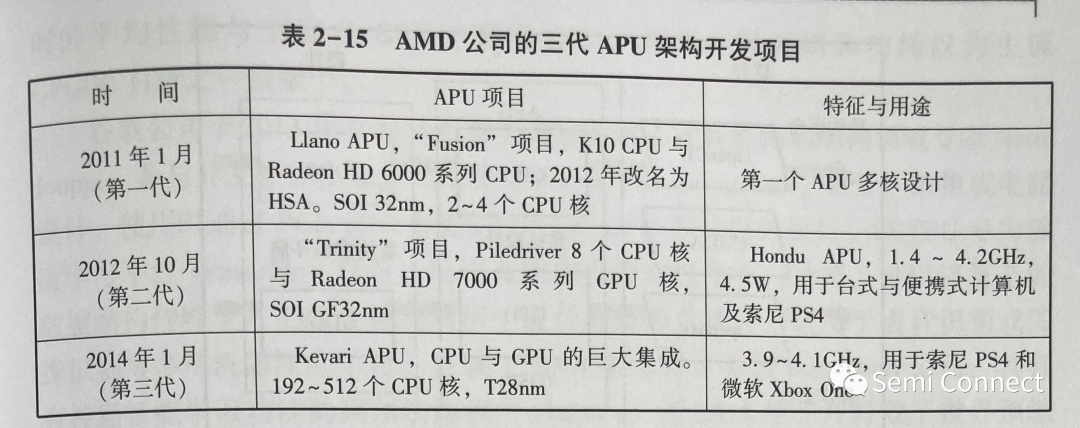
AMD 公司于2006 年收购了 ATI 公司,从设计传统的串行计算处理器 CPU过渡到并行图形处理器 GPU;经过研发升级,再将 CPU 和GPU 合为一体成为APU,集成为单个芯片,使得微处理器的性能得到改进,处理能力得以提高。APU 为随后被扩展为 HSA 走出了一条新路。AMD 公司的三代 APU 架构开发项目见表 2-15。
2.采用异构系统架构特征设计的集成电路
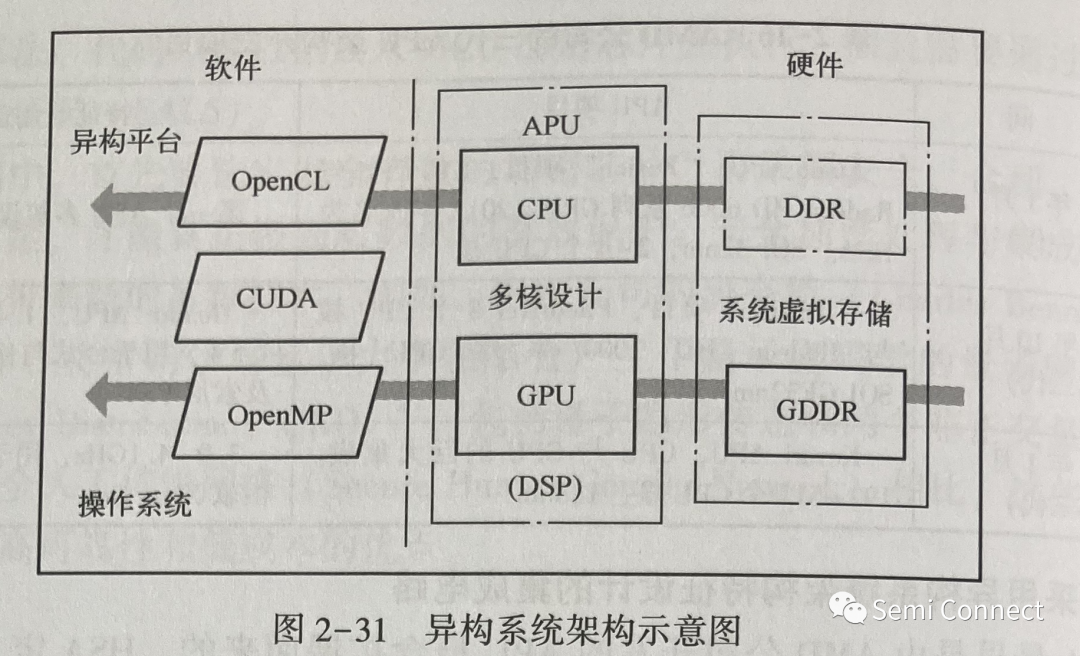
HSA 最早是由 AMD 公司开发的 APU 概念扩展而来的。HSA 定义了一套计算机硬件规范,其核心为 CPU 标量处理和 GPU (或者 DSP)并行处理的结合。与此相应的有开源软件的开发与应用,包括系统级 C/C++高级语言、用于异构系统的开放计算语言 (Open Computing Language, OpenCL)结构、针对三维图形(例如 GPU)的开放图形库 (Open Graphics Library, OpenGL)、开放多进程(Open Multi-Processing, OpenMP)应用程序接口、NVIDIA 公司开发的平行计算与应用接口 ( Compute Unified Device Architecture, CUDA) 的模型、支持多种操作系统的Python 等语言。2012年6月由 AMD、ARM、Imagination、联发科(MediaTek)、高通和三星成立了非营利组织 HSA 协会。HSA 协会着重于开发和定义各种处理器(包括 CPU、GPU、DSP)以及存储器的特点和接口;之后,该协会又添加了 ASIC 设计公司成员,从而建立起新型的并行计算异构系统架构,如图2-31 所示。HSA 包括软件和硬件两大部分。软件包括 OpenCL、OpenMP、CUDA 模型等。图2-31中 CPU 和其专用存储器 DDR,以及 GPU 和其专用存储器 GDDR, 使用指针 (Pointer)功能传递,在HSA 系统中形成了共享的系统虚拟存储器 (System Virtual Memory, SVM)。
3.基于人工神经网络深度学习的高级处理量
约翰•麦卡锡(John McCarthy)在1956年最早使用了人工智能 (ArtificialIntelligence, AI)这个词,他也因此被称为 “人工智能之父”。AI通过使用机器学习 (Machine Learning)而设计的产品应用广泛,发展迅速。1986 年 GeffreyHinton 等人发表了神经网络中反向传播算法(Back-Propagation Algorithm)的文章。2006 年Hinton 的这一研究有了新的突破,并提出了深度学习(DeepLearning)的概念。近年来,深度神经网络 (Deep Neural Network, DNN)、卷积神经网络 ( Convolutional Neural Network, CNN)、循环神经网络 (RecurrentNeural Network,RNN,例如时间递归神经网络,即 Long Short - Term Memory,LSTM)等深度学习方法大大推动了各种芯片的设计进程。
Intel 公司 2017 年推出了 Nervana 平台,利用其 APU 产品 LakeCrest, 采用CPU 与FPGA 重组架构设计,用在深度学习的分析算法领域中。另外,Intel于2016-2017 年发布的高级CPU 都可以用在深度学习的相关领域。例如,2016年第一季度发布了 14nm 工艺制造的 Atom x5-Z8330 处理器,含有4 核4线程,L2缓存(Cache)为 2MB, 最高工作频率为 1.92GHz。 Intel 于 2016 年第四季度发布了至强(Xeon Phi)系列处理器 7290,含72核,采用14nm 工艺,集成16GB 缓存,工作频率为 1.5GHz。Intel 于 2017 年发布了第七代4核处理器 IntelCore-i7 系列,工作频率为 3.5~4.5GHz。
IBM 公司承担美国 DARPA 的 SyNAPSE 项目,基于 CNN 设计了认知计算机(Cognitive Computer),从而于 2014 年设计出备受关注的具有 4096 个 CPU 众核的真北(TrueNorth) 神经网络芯片,它有54 亿个晶体管,功耗只有70mW。它interwetten与威廉的赔率体系 2.68 亿个神经轴突(Synapse),每个 CPU 核可以模仿 256 个可编程的神经元 (Neuron),总共等效于 100 万个神经元。
中国科学院计算所2016年报道了结合 GPU 和 CPU 的深度学习专用处理器寒武纪(Cambrian)芯片,计算速度大为提高,为其虛拟现实研究建立了基础。寒武纪1号(DianNao)芯片采用 65nm 工艺.芯片面积为 3.02mm²,主频为0.98GHz,功耗为 0.485W,峰值性能达每秘 4520 亿次神经网络基本运算。寒武纪2 号(DaDianNao)芯片包含 16个处理器核,采用28nm 工艺,面积为67.7mm²,主频为 606MHz,功耗约为 16W。据称与主流 GPU 相比,寒武纪2号单芯片性能超过若干倍,能耗极低,高效能计算系统性能提升数百倍。寒武纪3号(PuDianNao)芯片采用 65nm 工艺,面积为 3.51mm²,主频为 1GHz,功耗为0.596W,峰值性能达每秒10 560 亿次基本操作。PuDianNao 运行机器学习算法时的平均性能与主流 GPGPU (通用GPU)相当,但面积和功耗仅为主流GPGPU 百分之一量级。
谷歌公司于2013 年9月从惠普实验室聘请了计算机体系结构领域专家 NormJouppi,参与开发被称作张量处理器 (Tensor Processing Unit, TPU)的集成电路设计,使用时通过 PCle插口去优化 CPU 和 GPU 芯片组的运行。该TPU 专为深度学习平台TensorFlow 打造,运用高层次机器深度学习与计算,可以将复杂的数据结构传输至人工智能神经网络中进行分析和处理,可以用于语音识别或图像识别等多项机器深度学习。谷歌于 2014 年合并了英国 DeepMind 公司,其具有神经智能学习功能的阿尔法围棋(AlphaGo)于2016 年5月打败了世界顶级围棋棋手李世石。AlphaGo 2.0于2017 年6月打败个人围棋大赛四冠王柯洁。阿尔法围棋是在 TPU 之上运行的,在人机比赛时最多使用了 1920 个 CPU 和 280个GPU。谷歌公司于2017 年4月5 日公开发表官方博客,介绍TPU 的架构,其处理 AI 事务速度比其他 GPU 与 CPU 结合模式快 15~30倍,计算能效高 50~80倍。这些进展为未来各种新型的高级处理器产品设计带来新的激励。
-
处理器
+关注
关注
68文章
19217浏览量
229494 -
dsp
+关注
关注
553文章
7968浏览量
348575 -
amd
+关注
关注
25文章
5456浏览量
134026 -
gpu
+关注
关注
28文章
4717浏览量
128813 -
深度学习
+关注
关注
73文章
5497浏览量
121066
原文标题:高级处理器,高級處理器,Advanced Processors
文章出处:【微信号:Semi Connect,微信公众号:Semi Connect】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
別让处理器编号混淆您的认识

视频处理器让投影变得更简单

简单认识IA-64架构处理器
简单认识POWER系列架构处理器

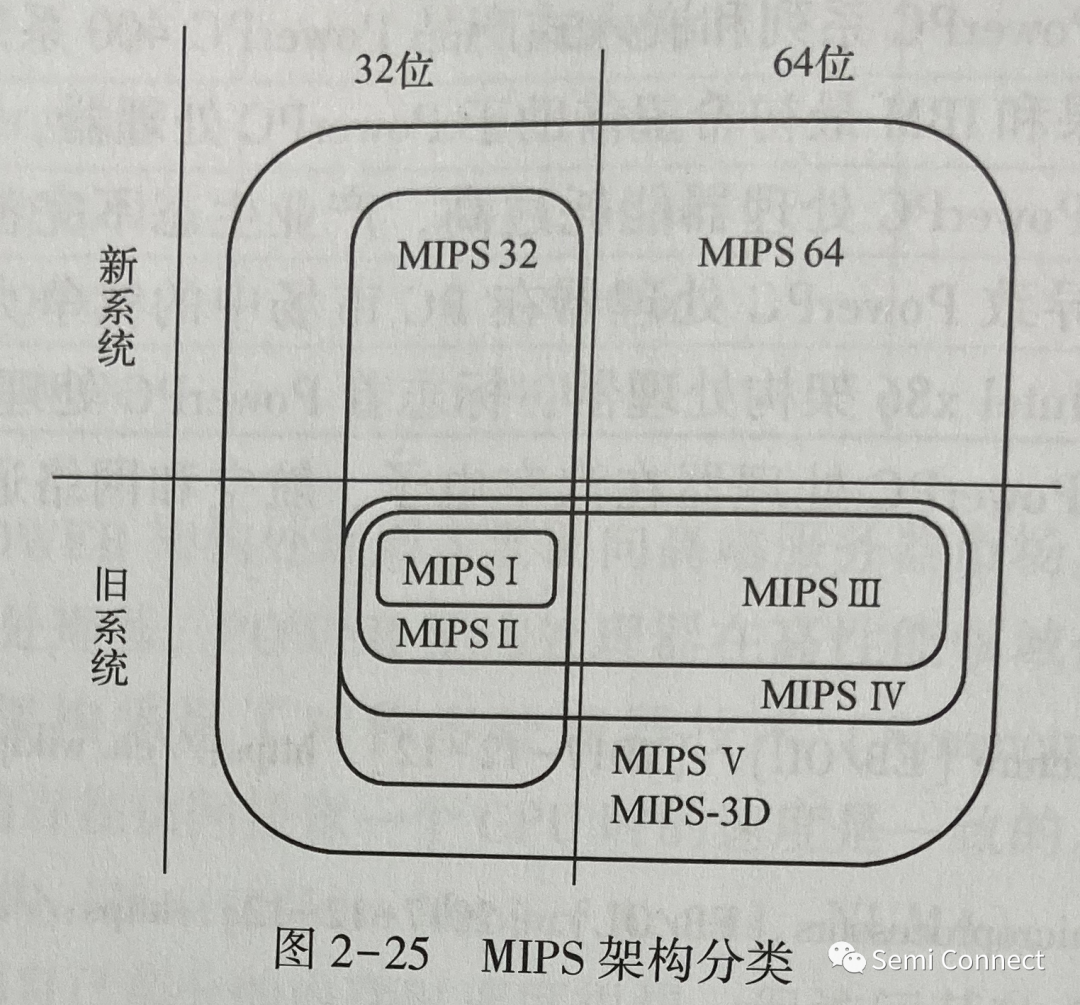
简单认识MIPS架构处理器
简单认识数字信号处理器







 工商网监
工商网监
评论