 超大规模数据中心与HPC的网络融合
超大规模数据中心与HPC的网络融合
01.摘要
随着大规模分布式数据处理和复杂数据中心服务的兴起,数据中心内部流量急剧增加,其特征与高性能超级计算机中的流量相似。然而,用于超级计算机和数据中心的网络威廉希尔官方网站 存在显著差异,因此将它们整合起来是一个自然的问题。
本文探讨了这两种工作负载类型和威廉希尔官方网站 之间的差异和共性,概述了在多个层面实现整合的途径。并预测新兴的智能网络解决方案将加速这种整合的过程。
02.引言
近年来,数据中心计算经历了前所未有的增长,由最初的内部服务器机房发展为巨型、超级和仓储规模的数据中心。这些系统中的网络端点数量已经超过了世界上最大超级计算机的规模,这些超级计算机刚刚达到了Exascale标准。第一代数据中心的网络主要为外部客户提供数据,并支持在数据中心运行的简单分布式应用。然而,随着大规模数据处理和机器学习的出现,数据中心网络的需求迅速纳入了传统高性能计算的范畴。这些新的流量需求引发了关于高性能和传统数据中心网络是否应该融合的讨论。尽管由此产生的规模经济具有吸引力,但也有一些阻碍融合的因素。在本文中,我们指出了高性能计算和数据中心计算之间的差异和共性,以及它们对大规模网络威廉希尔官方网站 发展的影响。我们得出结论,能够同时支持高性能计算(HPC,High Performance Computing)和超大数据中心(MDC,Mega Data Center)工作负载的智能高性能数据中心网络将很快在工业界得以应用。
高性能计算一直在推动计算的极限。顶级系统,称为超级计算机,在地球上具有最高的集中计算能力。虽然大多数超级计算机同时运行多个应用程序,但它们被设计为在整个机器上运行单个“顶级运行”(Hero Run)应用程序,以解决世界上最具挑战性的问题,如在大流行传染病中寻找疫苗,或训练最大的深度学习模型。在当今的威廉希尔官方网站 限制下,超级计算机不再是单一服务器,而是由数万个通过高速通信网络连接的独立服务器组成。网络(即互连)是最关键的组成部分,超级计算机的设计围绕特定的网络架构。这使得网络成为一个主要的区分因素,因为“单一应用”场景通常具有严格的延迟和带宽要求。可以说,正是互连网络将一组服务器转变为超级计算机。
超级计算机系统运行并行应用程序,最常在使用消息传递接口(MPI,Message Passing Interface,[1])的分布式内存超级计算机上实现。MPI程序在每台服务器上以进程形式运行相似的代码,并且算法通常使用大规模同步并行(BSP,Bulk Synchronous Parallel)计算模型设计,作为一系列计算-通信-同步阶段。在此场景中,应用程序只能在所有进程完成同步后进入下一个阶段。这一问题在后来在超大规模数据中心(MDC)中被重新发现,成为长尾问题[2]。许多编程威廉希尔官方网站 可以减少同步和通信开销(例如,[3],[4]),然而,在极端扩展的情况下,BSP应用程序受到延迟的限制。实际上,通信延迟(尾部)分布确定了系统的可扩展性极限,并确定了单个应用程序可以有效使用的最大进程数[5]。
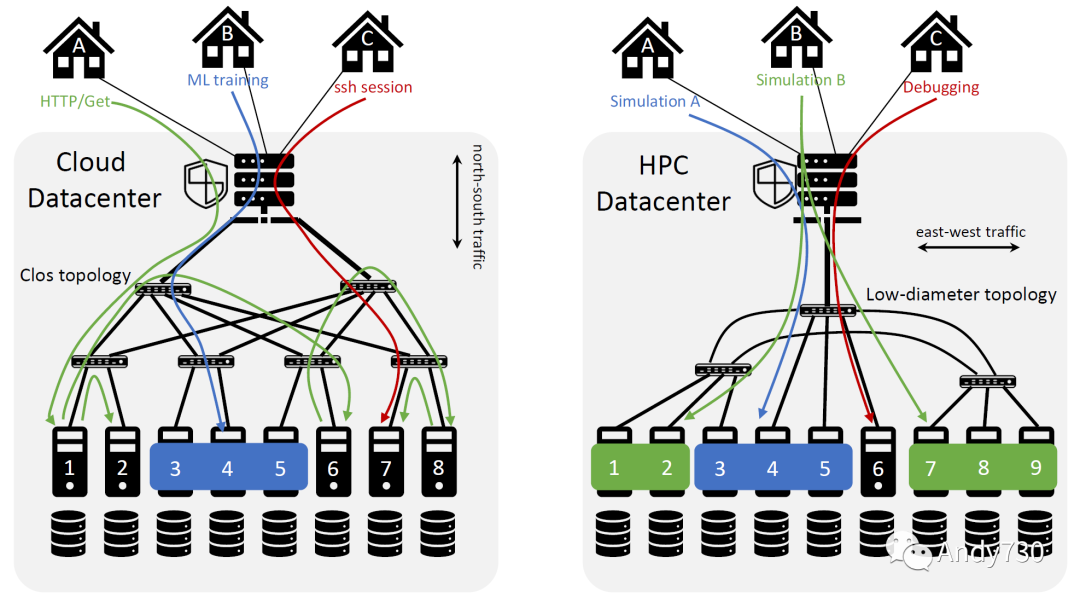
图1:数据中心和HPC机器的使用场景。云数据中心为多个客户提供各种交互式服务,其中包括一些分布式服务,例如机器3-5上的机器学习训练任务。右侧的HPC数据中心主要专注于为三个分布式仿真工作负载提供服务,客户在这里不需要即时答复。
超级计算机的规模已经被仓储规模的超大数据中心超越。现代网络化世界需要存储和处理由连接的客户端设备消耗的数据。每个人现在都拥有多个移动设备,并产生和消耗越来越多以云为中心的计算和存储。此外,并非所有客户端端点必须在设备后面由人类消耗数据或服务。随着物联网(IoT)的普及,数亿台设备向全球数据中心传送图像、视频和网页等数据。AWS、Google、Facebook或Microsoft等超大数据中心的规模大于最大的单一超级计算机,并且它们在相同的计算、存储和网络基础设施上同时运行更多多样化的应用程序,以支持更多互动式终端用户。MDC运营商的范围是其全球用户群,随着应用的增长,而HPC运营商的范围是在规划时定义的应用程序容量。图1显示了HPC和MDC工作负载的概貌。
MDC系统运行分布式应用程序,其中异步进程使用诸如远程过程调用(RPC)等编程接口进行成对通信。这些应用程序很少需要使用多服务器或全局同步,因此减少了延迟对总体应用性能的影响。单个端点对之间的通信产生的增加的延迟仅影响个别请求,而不影响整个应用程序。每当在MDC应用程序中出现多对一的通信模式,例如在Map-Reduce或分布式文件系统中的组播模式,开发人员通常依赖于软截止期限,以减轻响应延迟的长尾影响。由此产生的应用程序不会在无限的尾延迟下停滞,而是在结果质量或效率上做出妥协。这是通过简单地忽略迟到的RPC响应或在不同服务器上冗余地启动它们来实现的。因此,网络缺陷不会减缓应用程序,而是导致了资源的浪费(可以通过添加更多服务器来恢复)。
数据中心的传统角色是存储、处理和将数据传递给驱动从其服务器到互联网的终端客户的数据,形成所谓的南北流量。当面向互联网的路径成为瓶颈时,数据中心网络容量可以相对较小。然而,在当今分布式数据分析和机器学习的时代,互连网络的吞吐量和延迟要求稳步增长,与服务器之间的通信相关的东西西流量以数量级的方式占主导地位。从这个意义上说,MDC流量类似于传统的HPC应用程序,尽管应用了更容忍延迟的模型。对于一些新兴应用程序来说,明显地表明HPC和现代大数据分析(例如深度学习、文档搜索或推荐系统)具有相似的计算和通信模式。例如,许多机器学习可以被表达为张量代数,协同过滤类似于双分图上的传统图分析。这些大数据工作负载与传统HPC工作负载之间的主要区别在于前者强调程序员的生产力,而后者强调性能。由于各种原因,编程环境可能会继续沿着不同的路径演变,但我们认为底层工作负载及其计算特性非常相似,并且正在迅速趋于融合。
然而,这些工作负载是使用非常不同的互连网络模式:HPC网络被优化为最高性能,而MDC网络遵循传统的数据中心部署和运营理念。当深入了解细节时,就会发现最底层已经趋于融合,随着向上移动,共性逐渐显现。此外,高性能加速器的引入(例如通用图形处理单元,GPU)对当今的MDC产生了更高带宽需求,需要在MDC中引入专业网络,导致HPC样式的网络连接岛屿。这些系统通常通过专用的HPC样式后端网络来补充前端数据中心网络。例如,Google TPU的专用环形互连和Azure HPC的InfiniBand部署连接GPU服务器。这种复制导致了显著的低效率——考虑到底层已经相同,只是通信协议不同!事实上,像AWS Nitro和Microsoft的Catapult [6]这样的端点解决方案尝试优化现有的以太网络。从另一方面来看,Cray的Slingshot威廉希尔官方网站 [7]来自以HPC为中心的视角,并增加了以太网兼容性。这些例子显示了需求和解决方案如何隐含了一个共同的高性能网络解决方案。
虽然在高层次上,HPC和MDC的网络需求相似,但细节中藏着复杂之处。我们将讨论一系列要求,涵盖了从设计和部署哲学到应用程序编程接口的HPC和数据中心网络之间的差异。我们评论每个差异的根本性,并揭示未来基于智能网卡(NIC)和交换机的网络计算解决方案将弥合其中许多差异。每个部分都以简要的威廉希尔官方网站 预测结束。
03.设计和部署哲学
两种网络观点之间最显著的差异在于机器部署的方式。一个MDC自然是来自多个供应商的松散连接的服务器集合,可以逐步扩展和升级。布线基础设施会经历多代机器和威廉希尔官方网站 。MDC会将光纤安装为楼宇基础设施,从而将基础设施和大部分网络拓扑与服务器解耦。机架交换机代表了数据中心网络和计算服务器之间的架构边界。多供应商支持是基本的,并且基于以太网用于物理层和互联网协议(IP)用于更高层次。速度异构性对于MDC网络也是基本的,不同的服务器可能以不同的链路速度连接,并且内部网络链路可能与端点速度不同。MDC运营商无法承受因重新配置而导致的大量停机时间,必须同时运行多种威廉希尔官方网站 。在MDC中进行的这种增量升级使现代化变得具有挑战性,并禁止在威廉希尔官方网站 上取得大的跃进。
传统上,超级计算机被视为一次性的安装,并且通常是按照这种方式设计和布线的:所有端点和内部链路的链路速度都相同;它们的网络使用单一供应商的组件;通常在初始安装之前就会制定升级计划。由于高带宽互连的重要性和成本,许多超级计算机超越了Clos网络或胖树作为互连拓扑的方案。设计范围从超立方体或高维扭曲网络 [8] 到更具成本效益的低直径拓扑 [9],[10]。它们的部署模型允许超级计算机在系统的每个新一代中应用对网络威廉希尔官方网站 的彻底变革。HPC站点会并行运行旧系统和新系统,在停用系统之前迁移工作负载。这种操作模式在占地面积、功耗和成本方面昂贵,HPC运营商正在推动更加渐进的方法。
威廉希尔官方网站 预测:增量部署和向后兼容性要求阻碍了许多创新威廉希尔官方网站 在MDC中的应用。HPC系统将继续引领威廉希尔官方网站 领域朝着完全新的、革命性的方向发展。
04.运营理念
在历史上,数据中心和HPC中心对其运营采取了非常不同的方式。这是由他们的客户所要求的:云数据中心为从手机用户到银行和医院等各种终端客户提供服务。它们运行I/O密集的工作负载作为实时服务,其中中断在几秒钟内就可见,并可能导致巨大的经济损失。例如,收集的数据,比如信用卡交易,无法重建,任何损失都是有害的。因此,提供的服务必须非常可靠并始终可用。超级计算机沿着一条不同的道路发展,这条道路以性能和成本为代价,其中可以容忍小规模的中断(每年几个小时)。个别作业可能会失败,只要它们可以在服务等级协议(SLA)允许的时间内重新运行,并且计算资源进行了过度配置以允许这样做。这使得HPC运营商能够在软件和硬件方面采用更冒险的部署,并且总体上比MDC运营商在网络和硬件威廉希尔官方网站 方面更为激进。
MDC网络通过结合确保部分操作的机制(例如,用于故障隔离的独立网络平面)和用于控制平面冗余的分布式协议,以优先考虑网络可用性。HPC互连使用单独的管理网络以确保可靠性,但依赖于集中式控制平面来实现高性能网络,以在有效管理的情况下接受短时间的不可用性。在MDC上运行的应用程序使用软件级别的复杂冗余(例如,在单独的服务器上使用备用服务或复制存储)来实现可靠性。在故障端点上运行的应用程序将迅速重新启动到新资源上,并重新连接到服务。这使得运营商可以以更低可靠性的、更便宜的硬件为代价,但需要额外的软件开销。另一方面,HPC应用程序依赖于在故障后从检查点重新启动应用程序。为了在大规模时降低重新启动成本,HPC供应商使用比MDC更可靠的硬件,例如,HPC网络使用链路级和端到端的重试来保护通信。因此,HPC软件的可靠性开销较低,而MDC必须采用昂贵的复制和共识方案。MDC网络运营商可以从HPC中学到更先进的硬件容错威廉希尔官方网站 ,例如使用链路级重试。
安全性对于任何计算系统都是一个重要的考虑因素。HPC系统在软件[11]和硬件安全性方面传统上要求不那么严格,通常依赖于物理安全性(例如,空气隔离系统和建筑保护),并避免在节点上使用多租户。系统管理员是一个受信任的实体,用户被谨慎地允许进入系统。MDC系统为敏感的第三方工作负载提供服务,其租户不信任运营商或其他租户,后者可能是任何持有信用卡的人。这需要在MDC中具备更高水平的安全性,并促使解决方案的出现,例如可信执行或一般的机密计算,以及安全的高性能网络[12]。最近,越来越多的HPC系统在共享文件系统中托管敏感数据(例如医疗记录),因此需要采用类似MDC的安全性概念。
MDC由极少数人员操作;其规模如此之大,以至于使用基于人的操作模型是不切实际的,自动化是必须的。这要求具备复杂的监控、日志记录和控制基础设施,在HPC系统中是不存在的。监控对于故障排除和容量管理至关重要。虽然我们尚未深入讨论容量问题,但“工作负载焦虑”是MDC网络设计中的一个重要因素。这源于计算和存储容量必须被配置来吸收端用户流量和应用工作负载配置中的不可预测的变化。网络必须容忍这种计算、存储和工作负载的变化,而不需要进行重大的重新设计。
MDC在部署或配置应用程序时不愿考虑物理亲和性,因为容量是按照时间顺序部署的,而亲和性会使虚拟机(VM)分配策略变得更加复杂。此外,可用性服务级别协议要求在区域或可用性区域内跨数据中心分布应用程序。在HPC应用程序部署中通常考虑地理位置。虽然在递归结构网络(例如胖树或Clos网络)上相对简单实现本地放置,但在其他拓扑上实现本地放置较为困难。然而,全球带宽网络承诺使得放置决策变得不那么关键。
威廉希尔官方网站 预测:根本的差异在于对(网络)可用性和安全性的处理方式。如果HPC运营商实施MDC运营提出的更严格的要求,HPC和MDC网络的运营方面将缩小差距。其他方面更为相似,可能会趋于融合。
05.服务多样性
MDC折射了其运营商的业务模式。一个专注于向企业客户销售虚拟机容量的运营商(例如Microsoft),与一个聚焦于人际互动的“终端用户中心”运营商(例如Facebook),拥有不同的网络配置文件、控制策略和服务级别协议(SLA)。然而,所有MDC运营商都广泛应用虚拟化和多租户威廉希尔官方网站 ,以提高管理效率和资源利用率。虚拟化对网络产生深远影响,因为它促使采用覆盖网络,将流量引导到虚拟端点而非物理端点。而当前的HPC互连则未涉及这种虚拟化或多租户的要求,通过采用裸金属寻址以降低开销。
MDC承载着大量具有截然不同流量需求的服务。例如,吞吐量型工作负载,如备份流量、复制和存储,与对延迟极为敏感的流量(如分布式计算和客户互动)共享相同的物理链路。这对MDC网络提出了极高的服务质量(QoS)要求。HPC网络主要用于并行计算和文件I/O,QoS曾不是首要任务,尽管随着工作负载多样性的增加,它变得越来越重要。例如,许多HPC和AI应用程序中使用的AllReduce操作在相对静默的网络上表现良好,但其他租户的流量可能显著影响可扩展性[13]。值得注意的是,用于美国Exascale系统的HPC互连提供了QoS和先进的拥塞管理。
MDC网络的规模受可靠供电而非应用可扩展性的限制。当今的MDC网络跨足多个位置和地区,以确保在面对大规模故障时仍能保持可用性。这引入了高度的数据中心间流量,与传统的数据中心内部东西流量和面向客户的南北流量不同。另一方面,HPC流量主要由保持在单个数据中心内的本地通信所主导。
威廉希尔官方网站 预测:在MDC网络上运行的服务将继续需要广泛的QoS类别。HPC系统将看到服务多样性的增加,这将使MDC风格的机制变得相关。
06.协议栈和层次结构
开放系统互连(OSI)层次结构规定了从物理层(L1)到应用层(L7)的通信协议栈的设计模式。层次之间的区分有争议,但大多数互联网服务可以映射到它们。数据中心业界继承了许多传统的互联网协议栈,并且只是最近开始转向更专业化的协议,例如数据中心TCP(DCTCP)或数据中心量化拥塞通知(DCQCN)。然而,HPC网络始终调整为最高性能,并且不提供用于完整OSI栈所需的许多头部(每个协议级别一个)。例如,在HPC互连网络中,传输层L3很少存在,因为网络不打算可路由。图2比较了MDC和HPC系统的OSI层次。
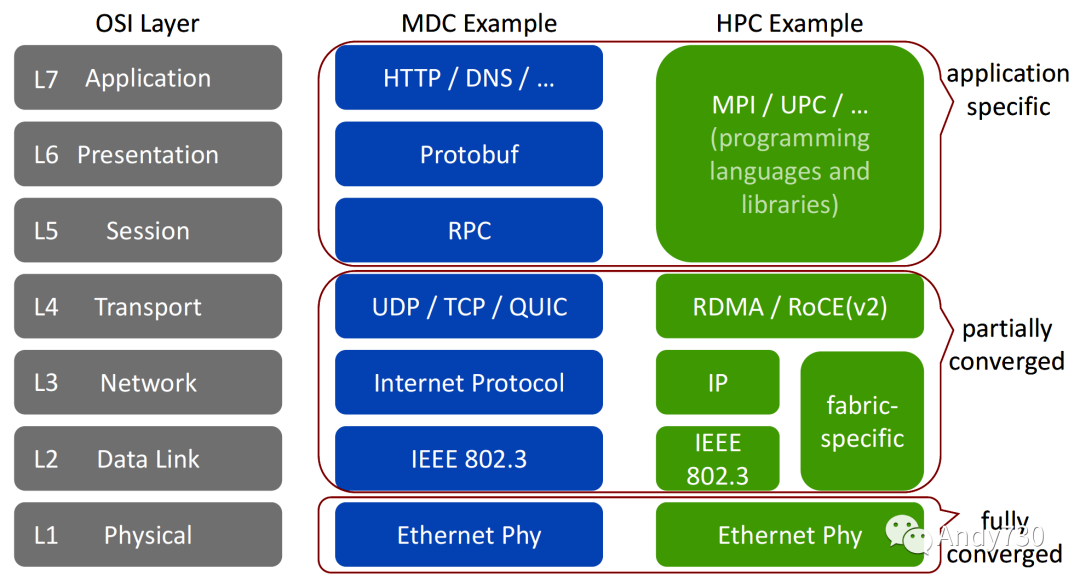
图2:开放系统互联层
在电气或光信号级别(L1),MDC和HPC网络是相同的。在布线和设备基础设施的规模经济和众多的威廉希尔官方网站 约束方面,确保谁先到达谁就是赢家。以25G、56G,以及最近的112G通道为代表,以太网多年来一直在这场竞赛中胜出。一些HPC和MDC网络威廉希尔官方网站 共享L2-L4,但其他HPC威廉希尔官方网站 采用专有协议,具有更专业和更精简的头部,以实现最低的开销。
一个有趣的融合点是远程直接内存访问(RDMA),长期以来一直在HPC和存储网络中使用,以在L4或L5上实现源进程和目标进程之间的高性能通信。该协议通常完全卸载到硬件实现中,操作系统绕过减少了延迟和延迟的变化。许多MDC运营商在生产中使用或计划使用它(Azure、Google 1RMA、AWS Nitro)。然而,在MDC规模上,RDMA和TCP/IP流之间的缓冲区和带宽共享可能会对某些流量造成不利影响。
当今RDMA网络实现中的简单基于硬件的重传机制依赖于无丢包传输层。然而,大多数数据中心网络传统上使用有丢包的路由器,即在队列满时丢弃数据包。尽管有关有丢包(端点控制的流速)与无丢包(网络控制的流速)的辩论尚未结束,但RDMA对无丢包网络的要求在保守的数据中心环境中提高了应用的障碍。出于这个原因,为了确保无丢包的语义,MDC将RDMA流量分配到专用的QoS队列或在后端网络中进行物理隔离。
威廉希尔官方网站 预测:随着链路速度的增加,额外数据包头部的相对带宽开销逐渐消失,HPC网络可能选择支持更复杂的可路由协议。我们预计将看到对UDP/IP上基于消息的协议的转变;远程直接内存访问(RDMA)通过融合以太网(RoCE)是这一趋势的第一个迹象。在MDC和HPC规模上的实验和优化将受到离散事件网络interwetten与威廉的赔率体系 的推动,例如分布式的ns-3、SST或LogGOPSim。
07.网络利用率
网络利用率即成本效益,是MDC和HPC系统中的重要驱动因素之一。由于许多MDC应用程序可以容忍较高的延迟,因此它们的网络理论上可以以更高的稳定利用率运行,并且在平均负载超过30-40%的情况下,不会产生过多的延迟影响。然而,丢包的影响可能如此严重,以至于运营商努力保持网络链路的利用率远低于数据包开始丢弃的点。
在网络规划阶段,网络利用率是关于估算所有叠加工作负载的端到端性能的。我们发现,在这个阶段,应用网络模拟可以分析个别链路的运行状态、交换机缓冲区的压力,当然还有数据包的丢弃和重传。在运营阶段,网络利用率是关于监视相同的链路和交换机缓冲区,当然还要将丢包和重传与链路和缓冲区进行关联。模拟和操作都可以以服务级别协议(SLA)为导向,其中整个网络利用率通过延迟分布来感知,几乎不需要将带宽作为指标处理。
大规模的BSP式HPC应用程序在通信和计算阶段运行,产生突发的开关式流量模式,对延迟分布有严格的要求。HPC网络被设计为满足突发流量的峰值带宽要求。当系统运行多个作业时,可以增加效益,但作业之间的争用,也被称为“近邻干扰”(Noisy Neighbor)问题,会导致关键的延迟变化。在MDC和HPC网络中,性能隔离可以缓解此问题,因此这是一个关注点。MDC运营商在流量源(通常是虚拟机)处实施速率限制器以解决网络性能隔离问题。在HPC中,确保最小化性能变化要求限制应用程序及其流量类型之间的交互,因为系统噪声[5],[14]和网络噪声[13],[15]对应用程序性能产生有害影响。在HPC网络中使用的单一供应商模型允许部署在更细粒度上运行的新型硬件拥塞管理机制(例如[7])。
静态等代价多路径(ECMP,Static Equal Cost Multipathing)可能导致拥塞热点,尤其是在通信密集型流较少的情况下。自适应路由或数据包喷射(packet spraying)可提高网络利用率,同时控制瞬时数据包丢失的风险。然而,直到最近,大多数商用以太网交换机没有提供自适应路由或数据包喷射,因为MDC网络端点不太支持乱序数据包的接收。最近引入了自适应流簇(flowlet)路由,在不改变数据包顺序的同时提供某种有限形式的自适应路径选择,这在MDC交换机中得到了应用。自适应路由是在低直径拓扑(在HPC中常见)中高效利用的先决条件,基本上允许同时使用最小路径和非最小路径。HPC网络端点使用RDMA传输支持乱序交付,其中数据包携带目标地址并可以独立写入内存。
威廉希尔官方网站 预测:基于UDP/IP的基于消息的协议的兴起放宽了端点的排序要求,使得超越静态多路径的路由方法成为可能。我们还预测这些传输的拥塞避免方面,以及TCP本身,将产生快速的演进。
08.应用程序和编程模型需求
应用程序需求在两方面都发生了变化,并且似乎在中间趋于一致。HPC曾经是非常底层的,应用在裸机上运行,并通过紧凑的消息传递(MPI)[1],[16]或远程内存访问(RMA)[17]接口访问网络。这些接口可以提供低于100纳秒的开销,以达到亚微秒级的端到端延迟。MDC应用程序通常依赖于开销巨大的拷贝语义的套接字。快速的RPC框架[18]可以潜在地弥合差距,并在MDC环境中实现透明的零拷贝。
基于任务的HPC编程模型使用和扩展这些已建立的接口,以放宽BSP对延迟的要求。传统的MDC应用程序对延迟相对不敏感,但新兴的工作负载,例如新的数据分析和深度学习工作负载类似于BSP风格的HPC应用程序,并具有同样严格的延迟要求。然而,在MDC中,程序员的生产力、快速原型设计和快速部署比性能更为重要。只有成熟的应用程序和堆栈明确针对性能进行调优。许多应用程序是使用Java或Python等托管语言编写的,并在虚拟化环境中运行,仅用了多达10微秒才能到达网络。HPC和MDC在不同的级别进行优化:HPC专注于最佳利用CPU和网络资源,而MDC专注于整个系统的生产力和利用率。
不同的应用需求导致了不同的网络API。对于高性能计算来说,向RDMA网络的转变发生在将近二十年前。从那时起,RDMA一直以个位数微秒的延迟运行,允许将大部分通信工作卸载到网络接口。虚拟内存机制允许数据路径绕过主机操作系统,直接在端点内存之间移动数据。高性能计算编程框架直接向应用程序公开远程内存访问语义,以最小化开销[17]。而MDC则逐渐认识到这些威廉希尔官方网站 的潜力[19]。由于RDMA不适用于传统的TCP/IP套接字模型和分层路由,MDC应用速度较慢。然而,RoCEv2和Priority Flow Control(PFC)等规范使得L3路由成为可能,并将RDMA引入MDC。
现代HPC网络远不止于RDMA,网卡执行消息匹配和集体操作,将这些任务从CPU或GPU卸载出来,以提高计算和通信的重叠。MDC中的智能网卡应用通常是为了提供者的利益,确保隔离,而不是改善租户应用。在MDC中,多租户使得卸载用户级逻辑比在HPC中更加复杂,因为网卡通常由单个应用程序拥有。通用的智能网卡编程接口,如网络中的流处理(sPIN [20]),承诺一种通用的加速策略,可以描述为网络的CUDA。
威廉希尔官方网站 预测:RDMA在当今的HPC系统中无处不在,而MDC运营商正在为其更大比例的流量采用RDMA。此外,我们预计在MDC和HPC网络中会看到可编程网络加速器的显著发展,超越RDMA的简单内存存储语义。
09.结论与预测
尽管数据中心提供商正忙于调整到RDMA和数据包级别的路由方法,但研究界正在迅速转向具有智能网卡和交换机的通用的流处理。新的网络加速设备以及营销术语,如DPU、IPU或NPU,正被各种供应商推向市场。
目前,它们主要部署在微软的Catapult和AWS的Nitro网卡上,用作基础设施支持。它们的主要用途是提高安全性(租户隔离),效率(封装和加密卸载)和成本(专业化和内部开发),以支持多租户主机。HPC系统尚未大规模部署智能网卡。我们预测,它们的角色将很快包括更通用的网络处理和将应用特定协议卸载到专用硬件。
由于HPC和MDC之间的主要区别在协议栈的上层,智能网卡和网络计算可以通过使用应用特定协议将两者统一起来。我们将在同一网络上看到基于套接字的(TCP/IP或QUIC)应用程序和MPI应用程序,并且智能加速的网卡(参见[21])将实现协议的差异。此外,应用特定协议是端点和交换机中网络加速的重要机遇。我们将看到基于交换机的网络计算,例如用于深度学习工作负载的减少[22],从而在所有层面实现工作负载的专业化。
与网络组件(如网卡或交换机)相关的术语“智能”需要超出当前营销术语的严格定义。我们建议将网络接口称为“智能”,如果它允许对消息或流进行有状态计算。有了这样清晰的定义,我们可以推理出这些智能网络的行为。
我们得出结论,虽然HPC和MDC在应用层面上趋于融合,但它们的特性需求足够不同,以支持两条发展线。当前的生态系统形成了一个有趣的反馈循环,突破性的新威廉希尔官方网站 可以在风险可接受的HPC环境中推动并测试。然而,大众市场仍将是以太网,它会慢慢吸收在HPC中开发的成功威廉希尔官方网站 。最近的一个例子是RoCE的出现。如果可以通过使用智能网卡和交换机进行配置,HPC和MDC都可以通过使用相同的硬件基础设施显著降低成本。以太网品牌的核心是互操作性的承诺,这可以为HPC和MDC网络奠定坚实的基础,然而,支持RDMA的供应商仍需履行这一承诺。
总之,虽然我们不知道哪种威廉希尔官方网站 将在10-15年内主导大众市场,但它肯定会被称为以太网。
-
数据中心
+关注
关注
16文章
4775浏览量
72120 -
应用程序
+关注
关注
37文章
3268浏览量
57699 -
HPC
+关注
关注
0文章
316浏览量
23767
原文标题:超大规模数据中心与HPC的网络融合
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
安森美SiC MOSFET在超大规模数据中心的应用
伟创力收购数据中心液冷公司JetCool Technologies
Zettabyte与纬创携手打造台湾首个超大规模AI数据中心
谷歌正在考虑在越南建设超大规模数据中心
新思科技1.6T以太网IP解决方案推动数据中心发展
有哪些威廉希尔官方网站 影响超大规模数据中心建设
燧原科技与锐捷网络携手共筑AI数据中心高性能网络新纪元
SAS 24G+规范发布,为超大规模数据中心HDD和SSD
燧原科技与清程极智携手共创AI未来:共筑超大规模智算集群新篇章
华为云华东(芜湖)数据中心正式开服
数据中心选择光纤时的考虑因素
大规模数据中心网络演进的七大主流趋势
超大规模数据中心采用三星FDP SSD降低存储成本





 工商网监
工商网监
评论