 降低Transformer复杂度O(N^2)的方法汇总
降低Transformer复杂度O(N^2)的方法汇总
导读
文章总结了降低Transformer模型复杂度的方法,包括Softmax Attention的计算复杂度、稀疏Attention方法等。
Transformer最重要的特性是Global Interaction,也就是说对于任意两个位置的token(不论它们离的有多远),它们之间都能直接进行信息交互。这个特性解决了传统序列建模中长依赖的问题。
但Transformer也有一个典型问题:它的计算复杂度和空间复杂度均为 , 其中 为序列长度。
因此实际应用中很难将Transformer应用到长序列任务上,如包数万个token的论文阅读、书籍阅读等任务。
解决Transformer计算复杂度的方法多种多样。本文介绍其中最主流、最常见的一些方法。
Note:
为简化,本文不单独讨论multi-head的情况。大多数方法都可以平移到到multi-head中。
本文主要讨论Transformer的Decoder。通常Encoder和Decoder的唯一区别是Encoder中当前token可以attend到左边和右边的其它token,而Decoder中当前token只能attend到左边token。所以本文介绍的这些方法都可以轻易地扩展到Encoder中。
1. Transformer的计算复杂度
首先来详细说明为什么Transformer的计算复杂度是 。将Transformer中标准的Attention称为Softmax Attention。令 为长度为 的序列, 其维度为 , 。 可看作Softmax Attention的输入。
Softmax Attention首先使用线性变换将输入 变换为Query、Key和Value:
(1)
(2)
(3)
其中 和 都是待训练的参数矩阵; 是 和 的维度; 是 的维度。由此可得 的shape分别为:
(4)
(5)
(6)
在常见的Transformer中, 通常 。因此为了简化符号, 我们假设后文中 , 并且只用符号 (Dimension)。
有了Q、K、V, Softmax Attention(SA)的计算如下:
(7)
容易看到,Softmax Attention的计算主要包含两次矩阵乘法操作。
首先回忆一下矩阵乘法的计算复杂度。对于矩阵 和 , 它们的矩阵乘法共需要 次乘法运算。可以拿国内线性代数教材使用最多的计算方法来理解:为了计算这两个矩阵的乘积, 需要拿矩阵 的每一行去与矩阵 的每一列做点积。因此总共需要 次点积。每次点积包含 次乘法和 次加法。考虑到加法复杂度远小于乘法, 所以总的计算复杂度就是 。
这个 可以使用两种方法理解:
第一种理解方法, 因为加法复杂度远小于乘法, 所以忽略加法, 那么 计算复杂度中的base operator指的是乘法操作。
第二种理解方法, 因为 与 的量级一致, 所以 计算复杂度中的base operator 指的是乘加操作 (乘法和加法) 。
回到Transformer的复杂度问题上,前面提到Softmax Attention的计算主要包含两次矩阵乘法操作。
第一次矩阵乘法是 , 结合上文关于矩阵乘法复杂度的结论和这两个矩阵的大小(公式 (4)和公式(5)),可知 的复杂度为 。
第二次矩阵乘法是 sof tmax 的结果与 的乘积。sof tmax 输出的矩阵大小为 , 矩阵 的大小为 (公式(6), 前文假设了 ), 所以这一次矩阵乘法的复杂度为 。
因为这两次矩阵乘法是顺序执行的, 所以总的复杂度为它们各自复杂度之和。因为这两个复杂度相等, 相加只是引入了一个常数项, 所以可以忽略, 因此Softmax Attention总的复杂度就为
当我们只关心复杂度与序列长度 之间的关系时, 可以忽略 并将其写为 。
这就是通常说的Transformer计算复杂度随序列长度呈二次方增长的由来。容易看到,Transformer的空间复杂随序列长度也呈二次方增长,即空间复杂度也为 。
这一节最后,我们用一幅简单的图来说明Softmax Attention中参与每个token的Attention Score计算的其它token的位置(只考虑Decoder)。该图主要是为了与后文的一些其它复杂方法作对比。
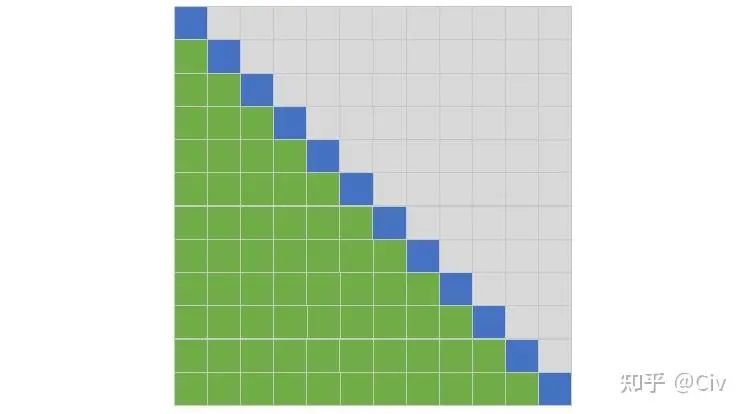
图1 Softmax Attention中参与每个token的Attention Score计算的其它token的位置
这幅图按如下方法理解:行和列都表示位置;蓝色表示当前token,绿色表示参与当前token计算的其它token的位置。
例如,图中有12行,可以看作该示例中序列长度为12。以第二行为例,它表示对于第二个位置的token(蓝色位置,当前token),只有第一个位置的token会参与它Attention Score的计算。这其实就是Transformer中Decoder采用的方式:只能看当前token左边的token。
为了简化表述,后文会使用如下方式来表述:第二行中,第二个token只能attend到第一个token。
同理,在第三行中,第三个token可以attend到第一个和第二个token。
以此类推。
同时,也会采用被动表述。例如,在第二行中,第一个token被attended到第二个token。此时,第一个token也可以被称为attended token。
2. Sparse Attention
再看一次图1中的Softmax Attention,容易看到对于每一个token,它都会attend到它前面的所有token。所以通常说Softmax Attention是密集的(dense)。
与密集相对的就是稀疏(Sparse)了。Sparse Attention的主要思路是减少每个token需要attend的token数量。
比如,Softmax Attention对于每个token都要attend它之前的所有token。那么为了减少计算量,能不能只去attend之前的部分token?
2.1 Factorized Self-Attention (Sparse Transformer)
Paper:Generating Long Sequences with Sparse Transformers (2019)
Key Contribution:提出了两种稀疏Attention方法:Strided Attention和Fixed Attention。这二者均可将Transformer的 复杂度降低至 。
Factorized Self-Attention的一个基础假设是:在Softmax Attention中,真正为目标token提供信息的attended token非常少。
换言之,该假设意味着:对于Softmax Attention,在经softmax得到的Attention Weights中,其中大部分的值都趋于0,只有少数值明显大于0。因此Attention Weight比较稀疏。
论文作者将Transformer用到了图像自回归任务中来表明他们假设的合理性,如图2.1.1所示(图2.1.1不容易懂,看后文解释)。

图2.1.1 Softmax Attention中Weight Vector稀疏性示意图
解释一下图2.1.1。作者们用了128层的Transformer在CIFRA-10上做自回归训练。自回归训练是逐行逐像素来做的。
以图a)中左上方的红色汽车图为例,图中黑色区域(下方)是mask。模型下一步需要去预测mask中的第一个点。所谓第一个点,就是逐行看,看到的一个mask黑色点。图中白色区域是Attention Weights。可以看到,有效的Attention Weights几乎全部集中在当前待预测点周围。所以此时的Attention Weights很像卷积的局部性。同时它也很稀疏,因为Attention Weights在较远的位置几乎全为0。
图2中a、b、c、d是来自不同网络层的Attention Weights。可以看到,虽然Attention Weights表现出的空间规律有所差异,但它们总体上都很稀疏:只有极少部分的位置被有效attend(Attention Weights明显大于0,即图中白色区域)。
基于这种稀疏性,作者们提出了两种Attention方法。
注:针对这篇paper的Attention方法,本文不列具体公式。这是因为,这些方法其实都非常简单,但公式反而繁琐、不直观。
第一种方法称为Strided Attention。它又由两种Attention机制构成,我们把它们分别记为SA1和SA2(原文没有这种命名法,这里只是为了指代方便):
SA1: 每个token只能Attend它左边相邻的L个token。
SA2:每个token只能Attend它左边部分token,这些attened token用如下方法选出:从自己开始往左边数,每隔L就会有一个token可以attend(参见图2.1.3,比较直观)。
为便于理解,请参见图2.1.2和图2.1.3,我们假设L=3。

图2.1.2 Strided Attention的SA1。图中每个token只能attend到它左边相邻的L个token,图中L=3。

图2.1.3 Strided Attention的SA2,图中L=3。
图2.1.2中的SA1很容易理解,每一个当前token(每一行的蓝色区域)只能attend到它左边的L个token,图中L=3。图2.1.3中的SA2稍微复杂一点,从自己开始往左边数,每隔L就会有一个token可以attend。比如图2.1.3中最后一行,从当前token(蓝色区域)开始往左边数,相隔L个空格(3个空格)处遇到第一个绿色方块可以attend(最后一行,第8列),然后再往左数L个(3个)空格,遇到第二个绿色方块可以attend(最后一行,第4列),以此类推。
Strided Attention的SA1方法和SA2方法的本质是在选择哪些token可以attend。
然后我们来看这两种Attention方法怎么用在Transformer结构中。有三种方法:
交替使用。在第1个Transformer Block中使用SA1,然后在第2个Transformer Block中使用SA2,然后在第3个Transformer Block中又使用SA1,在第4个Transformer Block中又使用SA2,以此类推。这种方法能work的原因是:虽然SA1只能看左边的L个相邻位置,但可以认为在SA1中,每个token聚合了它左边L个token的信息。因此在SA2,虽然它是跳着L个位置看的,但整体感受野等价于整个序列(因为每个attended token聚合了其左边L个token的信息)。
联合使用。将SA1选择的attended token和SA2选择的attended token合在一起使用。这个方法很简单,就是在计算Attention时,首先用SA1去选择一些token,再用SA2去选择一些token,然后计算Attention时只使用选择出的token参与计算即可。
多头使用。类似Transformer采用的多头机制,这里每个头可以使用SA1、SA2或Transformer中的Softmax Attention。
然后来看 的选择。只要将 的值设为 , 那么容易看到整个Strided Attention的计算复杂度就是 。虽然这个做法很不自然, 但是它确实能实现 的复杂度。
至此,我们介绍完了Strided Attention。
作者们提出的第二种Attention称为Fixed Attention。Fixed Attention也有两种机制,将它们分别称为FA1和FA2。为了便于理解,需要把这两种机制画到一个图里,如图2.1.4所示。
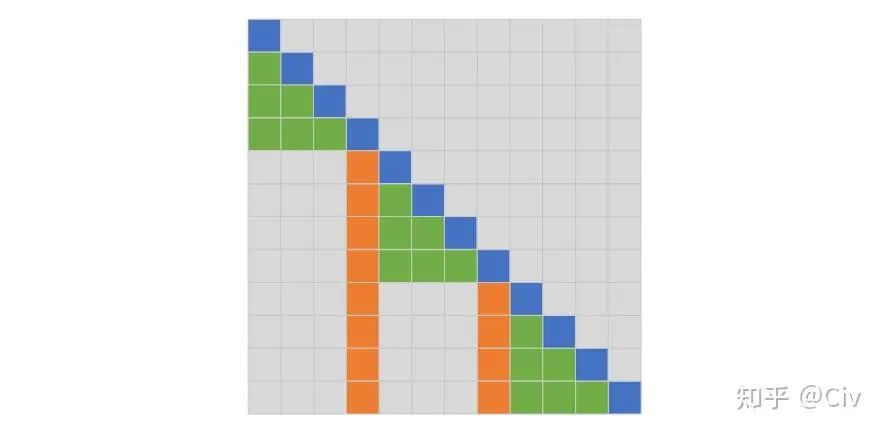
图2.1.4 Fixed Attention中的FA1(绿色)和FA2(橙色),L=3
先看FA2,如图中橙色区域。橙色区域的位置是固定的,即从左往右数,每隔L个位置,选中一个token。
理解了FA2,FA1的选择方式就会容易理解了。对于每个当前token(蓝色),往它左边遍历(绿色),直到遇到第一个FA2选中的token(橙色)。
Fixed Attention的使用方法和上文介绍的Strided Attention的三种方法一致(交替使用、联合使用、多头使用),不再赘述。
作者们的结论:Strided Attention适用于图像、音频;Fixed Attention适用于文本。
理由如下:Strided Attention在attended token的位置上做了强假设:哪些位置的token应该被attened,与当前token位置强相关。作者们认为这种适合图像、音频这类数据。而在文本上这类假设不成立。所以在Fixed Attention中,哪些位置的token应该被attened,与当前token位置无关。
讲的再简单点,图像、音频的局部信息很重要;而文本全局信息更重要。
总结:paper对新手不友好,简单的事情用了公式来解释,非常繁琐。希望本文能比原文容易理解一点。
2.2 Blockwise Self-Attention
Paper:Blockwise Self-Attention for Long Document Understanding (2019)
Key Contribution:通过分块来降低Softmax Attention的计算复杂度,方法简单,且实验效果较好。
前文提到了Transformer的时间复杂度和空间复杂度都为。Blockwise Self-Attention这篇Paper对空间复杂度做了更细致的分析。
一个模型的Memory Usage主要来自三部分:Model Memory、Optimizer Memory、Activation Memory。按照Transformer模型通常使用的Adam类优化器来看,Optimizer Memory是Model Memory的三倍。这是因为Optimizer Memory需要为每个参数存储梯度、first momentum和second momentum。
Model Memory和Optimizer Memory可以直接计算出来。比如对于Model Memory,可以直接通过模型大小与参数类型(如FP16、FP32、INT8)来推算出精确值。同理,Optimizer Memory也可以精确计算出。而Activation Memory则与具体实现相关。所以在Paper中,作者们用PyTorch的内存分析工具来看训练时总的内存开销,然后减去Model Memory和Optimizer Memory,以此来估算Activation Memory。
作者们以BERT-base为例,分析了Model Memory、Optimizer Memory、Activation Memory三者的占比,其中Activation Memory独占87.6%,属于内存开销最大的部分。画一幅图来总结上面提到的内容(注意图中的memory usage的比例是针对BERT-base而言的):

图2.2.1 BERT-base中内存分布示意图
我们说的空间复杂度 主要指的就是Activation Memory这一部分。因为Model Memory和Optimizer Memory是线性复杂度 。
Blockwise Self-Attention的核心思想非常简单:将一个长度为N的序列,平均分成n个短序列。当原始序列长度N无法被n除尽时,对原始序列进行padding,使它能被除尽。举一个例子来说明Blockwise Self-Attention的计算过程。
假设序列长度 , 每个token的维度为 。在Transformer中, Q、K、V三个矩阵的大小都为 。在Blockwise Self-Attention中, 假设分块数 , 那么每个分块中的序列长度为 。所以输入序列 可以划分为 个子序列: 、 , 它们的大小都为 。同理可以把 ( 同理) 划分成 个子矩阵:、 , 它们的大小也都为 。在计算Self-Attention时, 每个 会去选择一个 和 来计算:(2.2.1)
在只有一个Attention头的情况下, 选择 和 的方法是:shifting one position。很简单, 选择 和 选择 和 选择 和 。换言之, 始终选下一个 和 ; 当 是最后一个block时, 选择 和 。这个过程可以用取余数的符号写出来, 但看着太繁琐, 所以文字描述了。
多头Attention情况下稍微麻烦一点。我们记序列 为单头Attention情况下每个 对应的 和 的编号 :(2.2.2)
仍以上面的示例为例, 在单头情况下, 的值为:(2.2.3)
它表示, 对应的 的值是2, 对应的 的值是 对应的 的值是1。
在多头情况下, 第 个头的 定义如下:(2.2.4)
例如, 按照上述示例, 第一个头的 为:(2.2.5)
第二个头的 为:(2.2.6)
因为分块数 , 所以需要取余数(注意下标从1开始, 所以余 0 时替换为 即可),得到最终的结果:(2.2.7)
过程其实很简单, 只是写出来稍微麻烦一点。
最后来分析复杂度。由本文第一部分分析Transformer复杂度的结论可知, 公式(2.2.1)中的复杂度为 。因为对每一个分块, 都需要用公式 (2.2.1) 进行计算, 所以总复杂度为:(2.2.8)
这既是计算复杂度,也是空间复杂度。
在原文中, 通常选为2。注意, 在大 计法中一般会忽略掉常数项。所以在这种意义下, Blockwise Self-Attention的复杂度仍为 。
但是大 计法的主要目的是理论分析, 并不为实际工程优化。所以即使在大 意义下复杂度没有变, 但它实际计算量仍然减少了。没有改变的 仍然意味着,Blockwise Self-Attention不能扩展到太大的 上,这就是大 计法的作用。
具体来看, 当 时, RoBERTa的训练时间由原来的9.7天减少至7.5天。
总结:相比于Sparse Transformer中的Factorized Self-Attention,Blockwise Self-Attention更简单,且从效果上来看,优于Factorized Self-Attention。
2.3 Longformer
paper:Longformer: The Long-Document Transformer (2020)
Key Contribution:设计了多种不同的Local Attention和Global Attention方法。
首先重新看一下Factorized Self-Attention (2.1小节)中的两种Attention方法:Strided Attention和Fixed Attention。在Strided Attention中,又有两种Attention机制,在前文中我们把它们分别称为SA1和SA2(参考图2.1.2和2.1.3)。SA1的作用是Local Interaction,而SA2的作用是Global Interation。类似的,在Fixed Attention中(参考图2.1.4),FA1的作用是Local Interaction,而FA2的作用是Global Interation。
在Factorized Self-Attention中,它主要依靠两类Attention的组合使用来实现长距离依赖,例如SA1+SA2(或FA1+FA2)。
Longformer的核心idea和Factorized Self-Attention很像,只是Longformer中的部分Attention只有Local Interaction,没有Global Interaction。
Longformer一共提出了三种Attention,分别是SlidingWindow basedAttention(SW-Attention)、DilatedSlidingWindow basedAttention(DSW-Attention)和GlobalAttention(G-Attention)。下面分别介绍。
先看SlidingWindow basedAttention(SW-Attention),它其实和Strided Attention中的SA1完全一样。为了方便大家查看,重新把Strided Attention的SA1图copy一份到此处。
图2.3.1 SW-Attention示意图,它和Strided Attention中的SA1完全一样。图中L=3
SW-Attention只Attend它左边的L个token。在SW-Attention中,L被称为“窗口大小”,而在Strided Attention中,L被称为“步长(Stride)”,它们本质一样。
实际上我们可以在Transformer中只使用SW-Attention来构建具有Global Interaction的网络。其方法很简单,只需要堆叠多个SW-Attention网络层即可,就如同CNN增大感受野的方式。假设窗口大小为K,一个M层的SW-Attention结构中最顶层的“感受野”大小为KM,如图2.3.2所示。
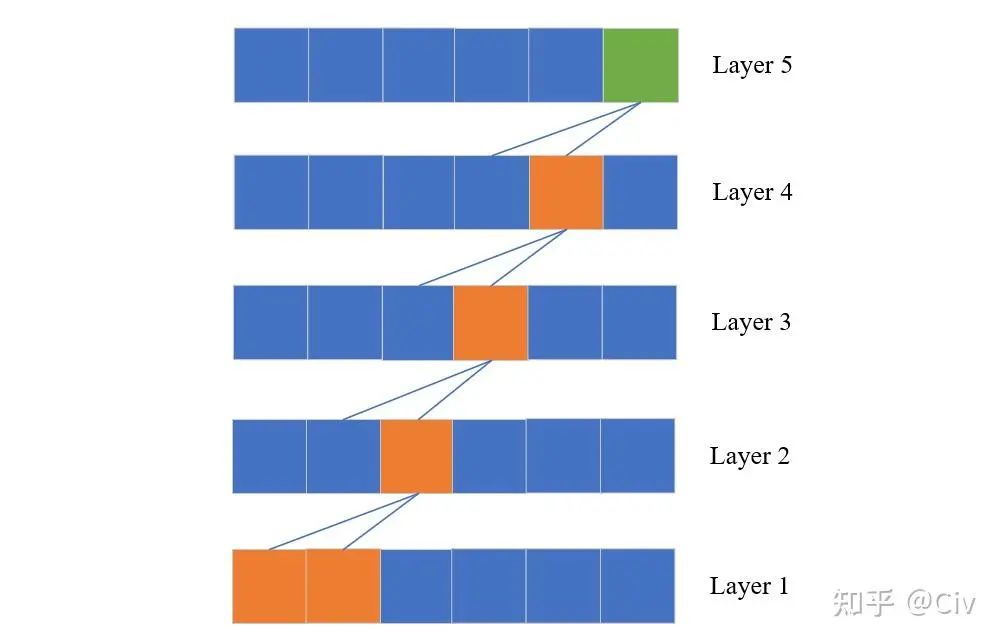
图2.3.2 基于SW-Attention构建的Transformer的Global Interaction示意图
图中绿色方块表示当前token;蓝色线表示信息流;每一层是上一层的输入;L假设为2。在第一层中,第一个token和第二个token的信息会流入第二层中的第三个token。而在第二层中,第二个token和第三个token的信息会流入下一层中的第四个token,以此类推。在最顶层(第五层),虽然当前token的信息只来自上一层的第四个token和第五个token,但从信息流的角度来看,它也隐含包含第一层中第一个和第二个token的信息。
可以看到,通过堆叠SW-Attention,Transformer也可以像CNN一样增加感受野。但是很容易想到,这种非常“间接”的方法不会有太好效果,就像CNN对长依赖建模的能力比较差一样。
再来看DilatedSlidingWindow basedAttention(DSW-Attention),它其实和Strided Attention中的SA2完全一样。为了方便大家查看,重新把Strided Attention的SA2图copy一份到此处。

图2.3.3 DSW-Attention示意图,它和Strided Attention中的SA2完全一样。图中Dilation=3。
DSW-Attention是“空洞”版的SW-Attention,就像空洞卷积和卷积之间的关系。简单来说,被attended的token不再像SW-Attention中是连续排列的,而是按等间距排列(间距称为“空洞率”,在图2.3.3中为3)。
与SW-Attention类似,通过堆叠多个DSW-Attention也能增大网络的感受野,从而实现Global Interaction。
最后再来看GlobalAttention(G-Attention)。G-Attention是SW-Attention的改进版,它的主要改动是:在SW-Attention基础上,增加了部分固定位置,使得这些位置的token需要 1)attend到其它所有token;2)被其它位置tokenattend到。如图2.3.4所示。
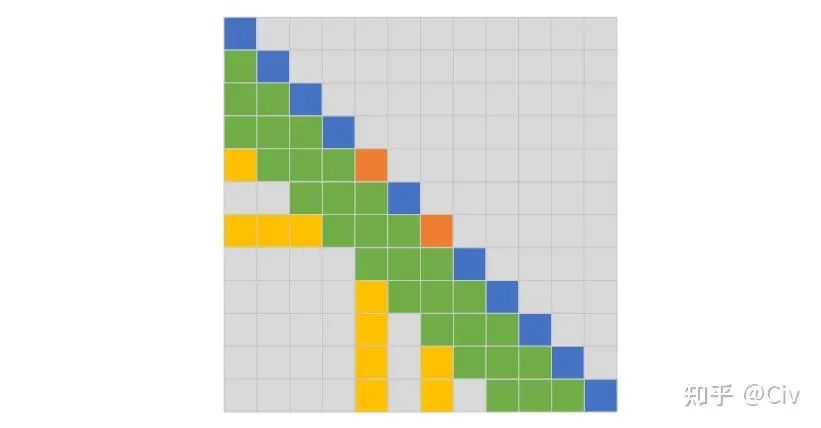
图2.3.4 G-Attention示意图,L=3
图中绿色token是SW-Attention会attend到的token。橙色token是在G-Attention中额外选中的token。以第五行的当前token为例(橙色),因为它是被额外选中的token,所以它会attend它左边的所有token。图中用黄色标出了相对于SW-Attention之外的额外被attended的token。此外,其它所有token也需要attend到第五个token,参见图中最后四行中的靠左黄色列。
图中第7行类似,大家可以自行对照图脑补一下这个过程。
在G-Attention中,哪些位置会被额外选中与具体下游任务相关。例如,在分类任务中,[CLS] token会被额外选中(Longformer一文中以RoBERTa为基础,将其中的Attention改为本文提到的Attention中的一种或多种);在问答任务中,所有问题的token都会被额外选中。
此外,G-Attention中有两份不同的QKV,一份用于计算由SW-Attention选中的token(图2.3.4中的绿色token),另一份用于计算由G-Attention额外选中的token(图2.3.4中的黄色token)。
上述提到的三种Attention的复杂度都为 , 因为哪些token会被attend与序列长度 无关。
2.4 Local attention and Memory-compressed attention
Paper: Generating wikipedia by summarizing long sequences (2018)
Key Contribution: 提出了Local Attention和Memory-compressed attention。Local Attention的计算复杂度随序列长度增长呈线性增长;Memory-compressed attention可以将计算复杂度减少固定常数倍(超参控制)。
2.4.1 Local Attention
前文中的2.3节也有一个Local Attention,但与此处的Local Attention方法不同。
此处Local Attention的核心思想是使用一个固定的分块大小n对输入序列进行分块,并限制self-attention的计算只能在各个分块内单独进行,如图2.4.1所示。
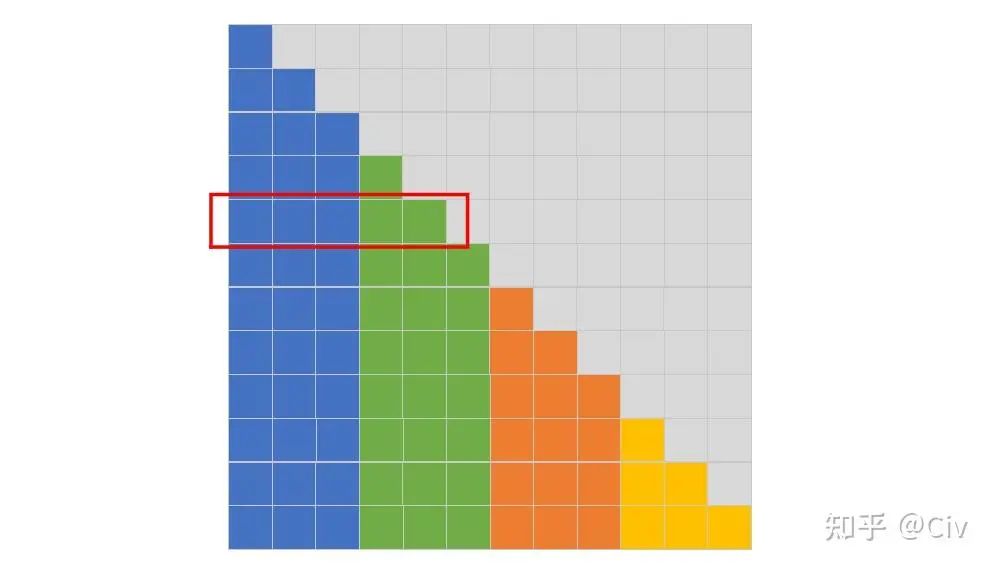
图2.4.1 Local Attention的模式图。图中假设序列长度N=12,分块大小n=3。
在图2.4.1中,每个位置的token只能attend到与它同颜色的其它token。例如图中第五行(红色标注行),它表示在Decoder结构中,对于输入序列中的第5个token的attention模式:第五行的灰色区域表示mask,这些mask表示Decoder结构中不能看到当前token之后的信息;前五个token根据颜色进行分块,每个token只能attend到同分块(同颜色)中的其它token,所以对于当前token而言(第五个token),它只能attend到第四个token和它自己(绿色部分)。
作为对比,标准的self-attention的模式图如下:
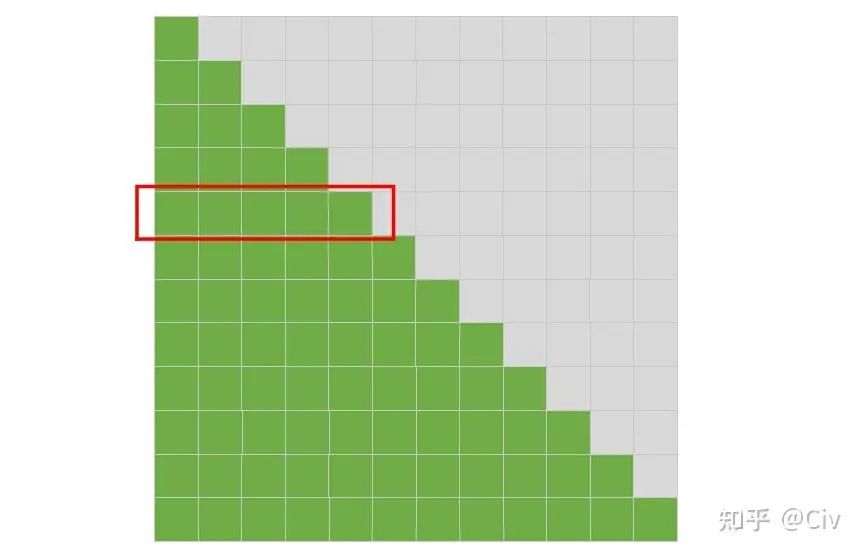
图2.4.2 标准self-attention的模式图。图中假设序列长度N=12。
标准的Decoder结构中,只有一个限制:所有token都不能attend到当前序列之后的token。
Local Attention与2.2节介绍的Blockwise Self-Attention比较类似,其核心思想都是对输入序列进行分块。Local Attention与Blockwise Self-Attention唯一的区别是:Local Attention将Self-attention的计算限制在组内;而Blockwise Self-Attention将Self-attention的计算限制在组间。
例如,考虑图2.4.1中的最后一行,在最简单的情况下,Blockwise Self-Attention的attention模式为:每个分块的token只能attend到下一个分块(蓝色token只能attend到绿色token;绿色token只能attend到橙色token;橙色token只能attend到黄色token;黄色token只能attend到蓝色token)。
下面分析一下Local Attention的复杂度。Local Attention通常选择一个固定长度的分块大小n(例如 )。假设总的序列长度为 , 那么分块数量为 。每一个分块的复杂度为 个分块的总复杂度为 。因为 为常数项, 所以Local Attention的复杂度随序列长度 呈线性增长 。
但在2.3节中, 曾分析到Blockwise Self-Attention的复杂度是 。为何两个如此相似的方法复杂度却有显著差异?
在Blockwise Self-Attention中, 的含义不是分块大小, 而是分块数量。所以每个分块的大小就为 。那么每个分块的attention计算复杂度就是 。又因一共有 个分块, 所以总复杂度是 。
这里之所以把这两个复杂度拿出来对比,是想说明:小心对待复杂性分析中的常量。不同视角可能会导致不同的分析结果。
复杂度唯一能体现的仅仅是:计算量与变量之间的关系。
在上面的例子中,我们关心的变量是序列长度N,所以直接忽略了常数项n。但如果我们要比较这两个复杂度所对应的计算量时,常数项不能轻易忽略。
2.4.2 Memory-compressed Attention
在通常的基于Transformer的模型中,我们使用不同的线性变换来将输入序列x映射为Q、K、V。这三者的尺寸通常一样(维度一样,长度也一样)。
Memory-compressed Attention的思路是使用额外的卷积来降低K和V的序列长度,这样整体Self-Attention的计算量就降低了。这样的卷积很容易实现。假设输入序列长度为N,维度为D,且K和V的尺寸都为[N, D]。我们只需要使用一个步长大于1的卷积,让它沿着序列长度维度进行滑动即可,如下图所示。
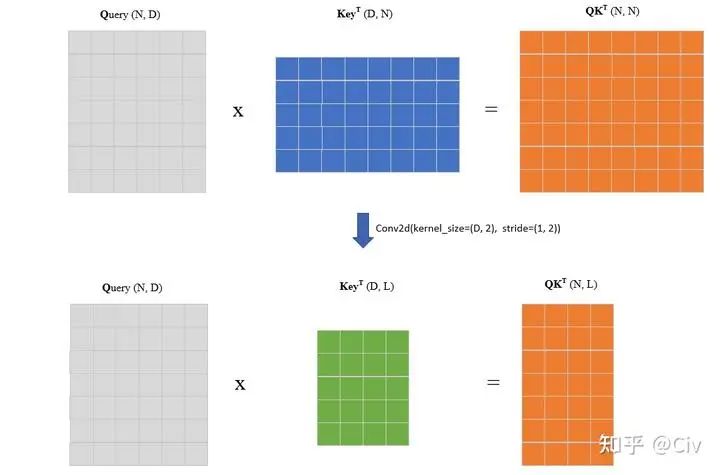
图2.4.3 Query与Key的矩阵乘积示意图。
图中上部分表示标准Query与Key的计算示意图。在Memory-compressed Attention中, 首先使用一个沿着序列长度维度滑动的卷积对该维度进行下采样,得到一个更小的Key的矩阵,如图中下部分所示。假设下采样后的序列长度为 , 可知此时矩阵乘法的复杂度为 , 而标准Q、K计算的复杂度为 。一般来说, L在量级上并不会与N有明显差异, 所以Memory-compressed Attention虽然能降低计算量, 但并不能显著降低复杂度。
2.5 Reformer
paper: Reformer: the efficient Transformer
Key contribution: 1) 提出了LSH-attention, 能够将Transformer的复杂度由 降低至 ;2) 将Transformer中的跳跃连接改为了“可逆跳跃连接", 这样在网络的前向过程中不用为后续的梯度计算存储激活值, 能够极大降低训练过程的存储开销。
从最原始的研究动机来看,Reformer主要考虑的是:降低基于Transformer的模型在训练阶段的存储开销。
神经网络在训练过程中,最大的存储开销主要来自两方面。一是网络参数本身的存储开销;二是整个前向过程中产生的激活值。由存储激活值而导致的开销只会在训练阶段产生,因为训练中为了计算每一层的梯度,需要用到当前层的激活值。而在推理阶段,因为不需要再通过梯度信息来更新网络,所以自然也就不用存储每一层的激活值了。
基于这两个部分,先来看一下基于标准Self-attention的单层Transformer的所涉及的存储开销:
以当时(2020年)最大的单层Transformer为例,它的参数量是0.5B。每个参数32位,也就是4Byte,所以总的内存开销就是2GB。
假设输入序列长度为 , embedding大小为 , batch size为 8 , 那么单个self-attention激活值所占的存储开销是 。同理, 每个激活值也是4Byte, 所以总的内存开销也是 。
上述两点涉及到的存储开销并不大,加起来一共也才4GB。但实际上除了这两点,就单层Transformer而言,它还包含另外两点最大的开销:
在标准Transformer结构中,除了self-attention部分,在其后还有两个全连层。两个全连层的激活值的数量加起来通常远大于self-attention的激活值。例如,在标准Transformer中,第一个全连层的激活值数量是self-attention的四倍,第二个全连层与self-attention相同。那么两个全连层总的激活值就是self-attention的五倍。按照上面第二点中的计算方法,两个全连层总的存储开销就是10GB。
self-attention的计算中包含 的矩阵乘法计算, 它的计算复杂度和空间复杂度都是 。例如, 当输入序列长度为 时, 的输出矩阵大小为 , 内存消耗约 16GB。
上述还仅仅是单层网络的开销(注:上述也并没有计算完单层所有的激活开销),对于一个N层的Transformer,这个开销还得乘以N倍。Reformer主要采用了两种方法来降低整体存储开销,分别是LSH-attention和“可逆跳跃连接”。
2.5.1 Locality-Sensitive Hashing Attention(LSH-attention)

图2.5.1 在Self-attention中(左图),当前token可以attend到它之前(包括自身)的所有token;LSH-attention中(右图),当前token只attend到部分“重要”的token。
在标准的self-attention中(以decoder为例),每一个位置的token可以attend到它之前的所有token(包括它自己)。但实际上,因为softmax主要由较大的那些值所主导,所以由softmax输出的weight vector中可能会比较稀疏。也就是说,很多位置的权重很小,只有少部分位置的权重较大。因此,一个自然的想法是不是只要找到那些产生较大权重的token即可,而不用让所有token都参与计算?这个想法的示意如图2.5.1所示。
在self-attention的计算中, 与当前Query越相似的Key, 它们点乘的值也会更大, 从而产生的权重也更大。为了后续描述方便, 对于某个token , 它对应的Query记为 。如果某个token 所对应的Key 能与 产生较大的点乘结果, 我们就说“token 对于token 是重要的”。
这里我们并没有定义“较大的点乘结果”究竟是多大。这可以认为是具体策略问题, 只要使用的策略能够区分"较大"和"不较大"就行。
LSH-attention的核心思路是, 对于当前token , 找到对它“重要的”所有token集合 , 并限制 在self-attention的计算中只能attend到集合 中的token。简而言之, 对于当前token , 我们希望知道哪些 与 的点乘会比较大。这些 对于的token 就构成了集合 。
寻找集合 中token的本质是相似度问题。计算两个向量相似度最简单的办法是计算它们的余弦相似度。但这不可取, 因为我们的目的就是为了避免计算和一些可能导致低权重的token的点乘来降低计算量。但如果为了找到它们又需要计算余弦相似度, 而余弦相似度的计算又包含点乘, 那么后续节约的计算实际上预先发生了, 所以这样没意义。
真正要解决的问题是找到一种高效的计算方法来判断两个向量是否相似。LSH-attention采用的方法是Locality sensitive hashing(局部敏感哈希)。
一个“局部敏感”的哈希算法指的是非常相似的向量具有相同的哈希值。LSH-attention使用的方法如图2.5.2所示。
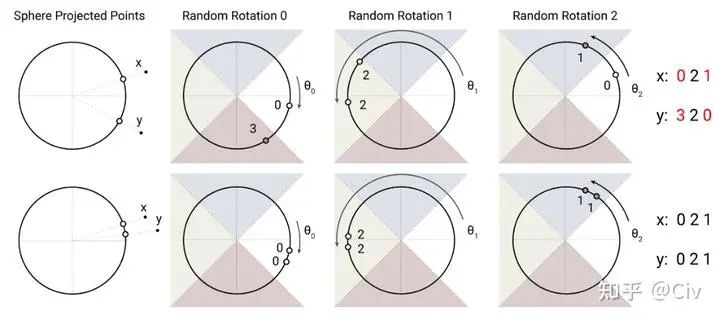
图2.5.2 Locality sensitive hashing示意图。图来自原论文。
解释一下图2.5.2。先看图的上半部分。假设有相距较远的两个点x和y,首先把它们投影到一个圆上(高维空间中对应超球面)。然后用一个随机的旋转将圆上的两个投影点进行旋转,并记录它们落在的区域编号。图中区域由四个不同颜色的三角形区域构成,从右沿着逆时针方向编号为0、1、2、3。所以在第一次旋转后(对应于图中Random Rotation 0),x落在的区域0,y落在区域3。然后再次随机旋转,并记录第二次旋转后落在的区域。图中一共进行了三次旋转,x分别落在区域0、2、1,因此它的哈希值就是021。而y三次分别落在区域3、2、0,所以它的哈希值是320。两个哈希值021和320不同,那么认为x和y不相似。
图2.5.2中的下半部分中用了两个更接近的点作为示例,不再展开解释了。LSH方法直觉上非常简单,它也有一些高效的实现方法。这里简单提一个要点:判断一个点落在哪个区域可以通过argmax操作实现(这实际上也同时隐含地确定了空间划分方法,但解释起来相对麻烦,故此文不展开)。
在二维平面中,如果一个点的坐标是[x, y] (与上面例子中的x、y无关),我们可以把它扩展成一个四维向量[x, y, -x, -y]。然后对这个向量使用argmax,也就是最大值对应的索引。这个索引编号就是点[x, y]对应的区域。
要证明这点只需要注意空间的划分是依靠y=x和y=-x这两条线实现的即可完成。
基于LSH,整个LSH-attention的计算可由下图描述。
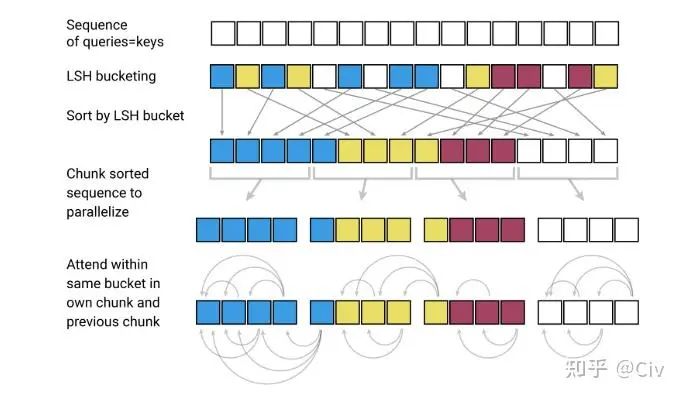
图2.5.3 LSH-attention计算示意图
图2.5.3从上至下来解释。
图中第一行。在LSH-attention中,Query和Key是相同的,这和标准self-attention有所区别。
图中第二行。使用LSH Hashing将token进行分组,具有相同Hash值的token被分为同一组(相同颜色表示)。
图中第三行。按照分组对token进行重排序。同组中的token按照它们在原始序列中的位置进行排序:越靠后的排在越后面。
图中第四行。按照固定长度对重排后的序列进行分块。分块的目的主要是为了并行化。
图中第五行。每个token只能attend到同组(同颜色)之前的token。如果某个组被分成了多块,那么后一块中的token只能attend到前一个块中同组的token(如果一个组被分成了三个块,最后一个块中的token不能attend到第一个块中的token,即使它们是同组的)。
LSH-attention的优势在于它降低了每一个token可以attend到的token数量。原论文中没有详细分析为什么LSH-attention的复杂度是 。从LSH-attention的形式来看, 它的复杂度介于 和 之间。
LSH-attention主要解决了前文中提到标准self-attention开销中的第四点: self-attention的计算中包含 的矩阵乘法计算, 它的计算复杂度和空间复杂度都是 。例如, 当输入序列长度为 时, 的输出矩阵大小为 , 内存消耗约 。
2.5.2 Reversible Transformer
因为基于反向传播的梯度计算需要用到网络前向过程产生的激活值,所以在训练过程中必须将这些激活值存储起来。对于较大的模型而言,这些激活值造成的存储开销相当巨大。
一种朴素的解决方案是利用checkpoint。在每次反向计算过程中,当需要层i的激活值时,使用上一次的checkpoint进行一次前向计算,直到层i,然后取激活值。虽然基于checkpoint方法能在存储不足时让模型跑起来,但增加了太多额外计算量。
另一种方法是让网络变得“可逆”。也就是说,我们可以由后一层的激活值来推出前一层的激活值。基于这种方法的一个经典工作是RevNet,它让ResNet变得可逆。
Reversible Transformer基本照搬了RevNet的思想。在整个前向过程中,网络始终处理两个序列 和 :(2.5.1) (2.5.2) FeedForward
输出 和 构成下一层的输入。对于网络输入层, 和 可由两个线性层变换得到。对于任意一层, 当知道它的输出 和 时, 利用公式 (2.5.2) 可以恢复出 :(2.5.3) FeedForward
代价是需要重新计算一次 FeedForward 。
当恢复出 后, 可以用公式(2.5.1)再恢复出 :(2.5.4)
代价是需要重新计算一次 。
如果整个网络使用的激活函数也是可逆的,那么在前向过程中不需要存储任何激活值。
Reformer的论文中没有讲用的激活函数是什么。在一些开源实现中有使用Gelu的,也有使用ReLU的。它们都不是可逆的激活函数。
所以对于这些激活函数而言,它们之前的输入仍需要存储,因为单靠激活函数的输出无法恢复出输入。
Reversible Transformer可以解决前文提到的第二点和第三点:
假设输入序列长度为 , embedding大小为 , batch size为 8 , 那么单个self-attention激活值所占的存储开销是 。同理, 每个激活值也是4Byte, 所以总的内存开销也是2GB。
在标准Transformer结构中,除了self-attention部分,在其后还有两个全连层。两个全连层的激活值的数量加起来通常远大于self-attention的激活值。例如,在标准Transformer中,第一个全连层的激活值数量是self-attention的四倍,第二个全连层与self-attention相同。那么两个全连层总的激活值就是self-attention的五倍。按照上面第二点中的计算方法,两个全连层总的存储开销就是10GB。
2.6 Adaptive Attention
paper:Adaptive Attention Span in Transformers
Key contribution:提出了一种对不同attention head自适应选择attention长度的方法。
在标准self-attention中,不同attention head的attention模式完全一样,即每一个token能attend到它之前的token(包含自己)。Adaptive Attention的假设是:不同head可以具有不同的attention模式,比如有的head可能更关注较近的token,有些head可能会更注重远距离依赖,所以可以通过学习来让不同head自适应调整head可以attend到的token长度。
这个思路与2.5.1节中介绍的LSH-attention的相似点是都在尝试选择部分token来attend,以减少参与计算的总token数。区别在于,adaptive attention选择的是一个连续的子序列,而LSH-attention没有这个要求,如图2.6.1所示。

图2.6.1 LSH-attention v.s. Adaptive-attention
可以把adaptive attention理解为是在选一个“距离”:最远可attend到的token离当前token的距离。只要这个距离确定了,那么可以被attend到的token就被确定了。
Adaptive attention的实现方法是为每一个attend到的token再加一个soft mask。下面详细介绍。
在标准的self-attention中, 记当前token为 , 它的Query和Key分别记为 和 。对于某个目标token , 它对 的权重由如下公式计算得到:
Adaptive attention中,在计算公式(2.6.1) 中的权重时,会为每一个位置再加上一个soft mask:
简单解释一下。 是一个mask函数, 它的输入是“距离”, 输出是一个0到1的值。例如公式 (2.6.2) 的分子中, 是当前token与目标token之间的距离。mask函数 根据这个距离计算出对应的mask值。
我们说这个mask是soft的, 是因为它的输出并不是0或1, 而是0到1, 这与平时的hard mask有所区别。
在Adaptive attention中, mask函数 定义为:
其中 是超参, 是需要学习的参数。公式很不优雅, 可以借助mask函数 的图像来理解:
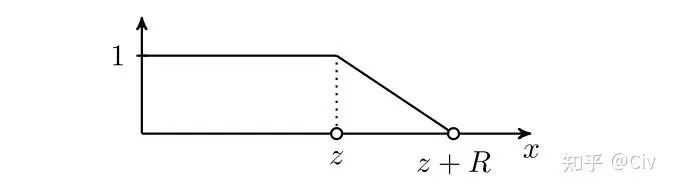
图2.6.1 mask函数的图像
模型会自动学习到一个合适的 , 这个 可理解为“有效token的距离”。与当前token距离 的所有token的soft mask值都为 1 , 表明它们都是有效的token。
超参数 表示一个“soft距离"。在距离 至 的范围内, soft mask由1线性衰减到0, 表示它们的重要性逐渐降低。超过 距离的token的soft mask值为 0 , 表示它们为无效token。
对于multi-head attention中的每个head, 都需要单独为它训练一个 。所以不同head可以attend 到的token距离也就不同。
Adaptive attention的最核心思路就是这样。下面再介绍两个其它细节。
首先,Adaptive attention采用的是相对位置编码的方法,所以公式(2.6.2)需要更改为:
(2.6.3)
其中 表示与当前token距离为 的位置编码, 它是相对的, 且直接靠学习得到。相对位置编码虽然简单, 但在后续的很多其它改进版的Transformer结构中应用非常广泛。
其次, Adaptive attention还提出了一种更复杂的参数化 的方法。在公式 (2.6.3) 中, 直接作为一个可学习参数参与训练, 由模型直接优化。对 的一种新的参数化方法如下:
其中 表示当前token; 表示最远可attend到的token距离, 可设置为一个期望的值, 或直接让它等于 和 是可学习的参数; 是sigmoid函数。
公式 (2.6.4) 的含义是为每一个当前token单独计算它的 , 而不仅仅是为每一个head计算一个
-
矩阵
+关注
关注
0文章
423浏览量
34530 -
线性
+关注
关注
0文章
198浏览量
25148 -
Transformer
+关注
关注
0文章
143浏览量
5997
原文标题:降低Transformer复杂度O(N^2)的方法汇总
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
业务复杂度治理方法论--十年系统设计经验总结
时间复杂度为 O(n^2) 的排序算法

如何降低LMS算法的计算复杂度,加快程序在DSP上运行的速度,实现DSP?
时间复杂度是指什么
各种排序算法的时间空间复杂度、稳定性
降低高条件数信道下的球形译码算法复杂度的方法
图像复杂度对信息隐藏性能影响分析
Transformer的复杂度和高效设计及Transformer的应用
如何求递归算法的时间复杂度
算法时空复杂度分析实用指南2
算法时空复杂度分析实用指南(上)
算法时空复杂度分析实用指南(下)
如何计算时间复杂度






 工商网监
工商网监
评论