 通过扩散模型理解不可学习样本对于数据隐私保护的脆弱性
通过扩散模型理解不可学习样本对于数据隐私保护的脆弱性
0. 背景介绍
在深度学习领域,网络上充斥着大量可自由访问的数据,其中包括像ImageNet和MS-Celeb-1M数据集这样的关键资源。然而,这些数据可能携带未经授权收集的个人信息,引发了公众对隐私的担忧。人们担心,私人数据可能会在没有所有者授权的情况下被不当地用于构建商业模型
这一问题凸显了在我们追求科技创新和性能提升的同时,更需要关注数据隐私和合理使用的问题。为了解决这些难题,越来越多的研究力量正在集中于使数据无法被滥用的方向。这些方法采用了一些巧妙的手段,比如向图像中引入难以察觉的“捷径”噪声。通过这种方式,深度学习模型不再仅仅学习有用的语义信息,而是开始学习噪声和标签之间的对应关系。因此,在这种数据上的训练得到的模型,无法准确分类干净的数据,有效地保护了用户的隐私。这种巧妙的方法被称为不可学习样本(UE),也可称之为可用性攻击。
然而,随着研究的深入,我们发现了在这种保护中的一个关键漏洞。如果无法利用的数据是唯一可访问的数据,那么这种保护就会起效果。但现实情况却并非总是如此。数据保护人员只能在他们自己的数据中添加“不可学习”的扰动,却无法阻止未经授权的用户访问其他来源的类似的未受保护数据。
因此,通过研究新收集的未受保护数据,人们仍然可以研究受保护示例的潜在分布。以人脸识别为例,虽然不可学习的样本不能直接用于训练分类器,但很容易收集到新的未受保护的人脸数据。只要新收集的未受保护数据与原始干净数据之间有足够的相似性,仍然有可能训练出能够成功对原始干净数据进行分类的分类器。
换句话说,未经授权的用户可以很容易地绕过数据保护,从新收集的未受保护数据中学习原始数据表示,即使这些数据可能规模很小,与干净的数据不同,缺乏标签注释,并且单独不适合训练分类器。为了证明上述漏洞的存在,我们设计了一种新的方法,可以将不可学习的样本转化为可学习的样本。
1. 方法
一个直接的解决方案是设计一个特定的训练方案,可以在不可利用的数据上进行训练。这是不太理想的,因为它只是对不可利用的数据进行分类,而没有揭示潜在的干净数据,即不可学习数据的未保护版本。
我们认为,最终的对策是通过将UE再次转变为可学习的方式来推断/暴露底层的干净数据,这可能会导致进一步的未经授权的利用,如标准训练或表示学习。因此,理想的可学习的非授权数据应该独立于训练方案之外,可以像原始训练数据一样正常使用。我们将可学习的未授权数据中的示例称为可学习示例(LEs)。
受扩散模型在噪声净化和图像生成中的强大功能的启发,我们提出了一种基于扩散模型的新型净化方法,用于生成可学习的示例。与常见的噪声净化(如对抗性净化)假设训练数据的可访问性不同,在没有访问训练数据的情况下训练扩散模型对去除UE保护提出了关键挑战,这是现有净化方法尚未探索的。
为了克服这一挑战,获得可学习示例背后的关键思想是从其他类似数据中学习一个可学习的数据流形,然后将不可学习的示例投射到该流形上。然而,学习到的数据流形通常与原始数据流形不同,导致净化样本与原始干净样本相比语义偏差。为了缓解这一问题,我们进一步提出了一种新的联合条件扩散净化方法,以捕获从不可学习样本到相应的干净样本的映射。
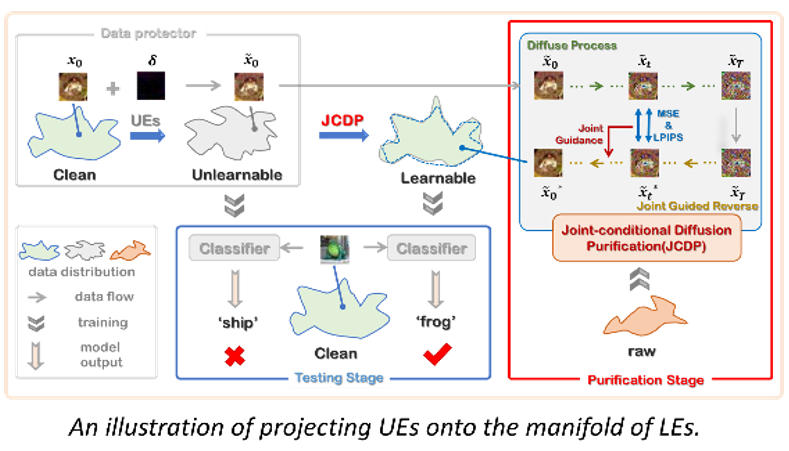
我们首先向不可学习图像中逐步注入一定量的高斯噪声,直到它们的不可学习扰动被高斯噪声淹没。接下来,我们为去噪过程提供了一个新的联合条件,在保持图像语义的同时加快了去噪速度。联合条件由不可学习样本与其相应去噪版本之间的像素距离和神经感知距离参数化构成。这是基于这样的观察,即不可学习的样本通常与干净样本在像素距离上表现出很小的差异,而这种差异对人类视觉来说是难以察觉的。因此,通过最小化与不可学习样本的视觉差异,降噪后的图像应该与原始样本非常相似。
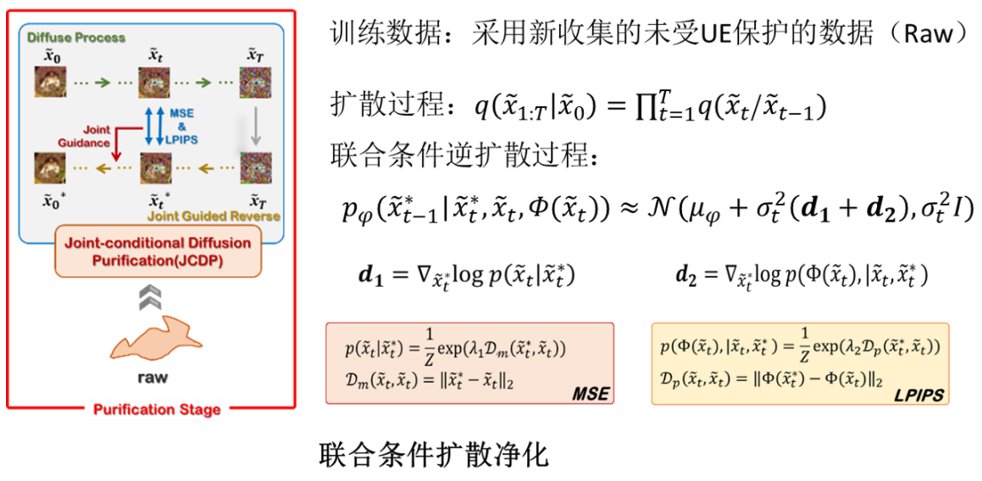
2. 结果与讨论
我们在许多基准数据集上广泛评估了我们在监督和无监督UE上的方法,并将其与现有的对抗方法进行了比较。结果表明,LE是唯一一种在监督学习和无监督学习下都保持有效性的方法,更重要的是,我们的LE不像现有的对策那样与特定的训练方案捆绑在一起,我们的可学习样例是独立的,可以作为原始的干净的训练数据正常使用。

令人惊讶的是,我们发现即使新收集的数据(用于训练可学习的数据流形)和干净的数据之间存在很大的分布差异,我们的方法仍然保持有效性。换句话说,训练数据和收集的原始数据之间的分布可以是不同的,我们仍然可以将不可学习的例子变成可学习的。

这无疑进一步加深了我们对UE保护脆弱性的担忧,因为训练数据和收集的原始数据之间的分布即使是不同的,我们仍然可以将不可学习的样本变成可学习的。
最后,我们做了消融实验,说明了联合条件净化相比于直接应用简单扩散模型净化的有效性。

审核编辑:刘清
-
深度学习
+关注
关注
73文章
5503浏览量
121139
发布评论请先 登录
相关推荐
基于数据流的脆弱性静态分析
基于差分隐私的数据匿名化隐私保护模型
电网脆弱性综合评估
网络脆弱性扩散分析方法
一种非脆弱性同步保性能控制方法
改进DEAHP的支路综合脆弱性评估
基于链路已用率的电力通信网脆弱性分析
SCADA系统该如何解决脆弱性泄露问题?
人工智能:机器学习模型存在着对抗样本的安全威胁
通过扩散模型理解不可学习样本对于数据隐私保护的脆弱性





 工商网监
工商网监
评论