 进程通信的应用场景
进程通信的应用场景
进程的概念
进程是操作系统的概念,每当我们执行一个程序时,对于操作系统来讲就创建了一个进程,在这个过程中,伴随着资源的分配和释放。可以认为进程是一个程序的一次执行过程。
进程通信的概念
进程用户空间是相互独立的,一般而言是不能相互访问的。但很多情况下进程间需要互相通信,来完成系统的某项功能。进程通过与内核及其它进程之间的互相通信来协调它们的行为。
进程通信的应用场景
数据传输:一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几兆字节之间。
共享数据:多个进程想要操作共享数据,一个进程对共享数据的修改,别的进程应该立刻看到。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
资源共享:多个进程之间共享同样的资源。为了作到这一点,需要内核提供锁和同步机制。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程通信的方式
管道( pipe ):
管道包括三种:
- 普通管道PIPE:通常有两种限制,一是单工,只能单向传输;二是只能在父子或者兄弟进程间使用.
- 流管道s_pipe: 去除了第一种限制,为半双工,只能在父子或兄弟进程间使用,可以双向传输.
- 命名管道:name_pipe:去除了第二种限制,可以在许多并不相关的进程之间进行通讯.
信号量( semophore ) :
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( message queue ) :
消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
信号 ( sinal ) :
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
共享内存( shared memory ) :
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
套接字( socket ) :
套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
各进程间通信的原理
管道
管道是如何通信的
管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
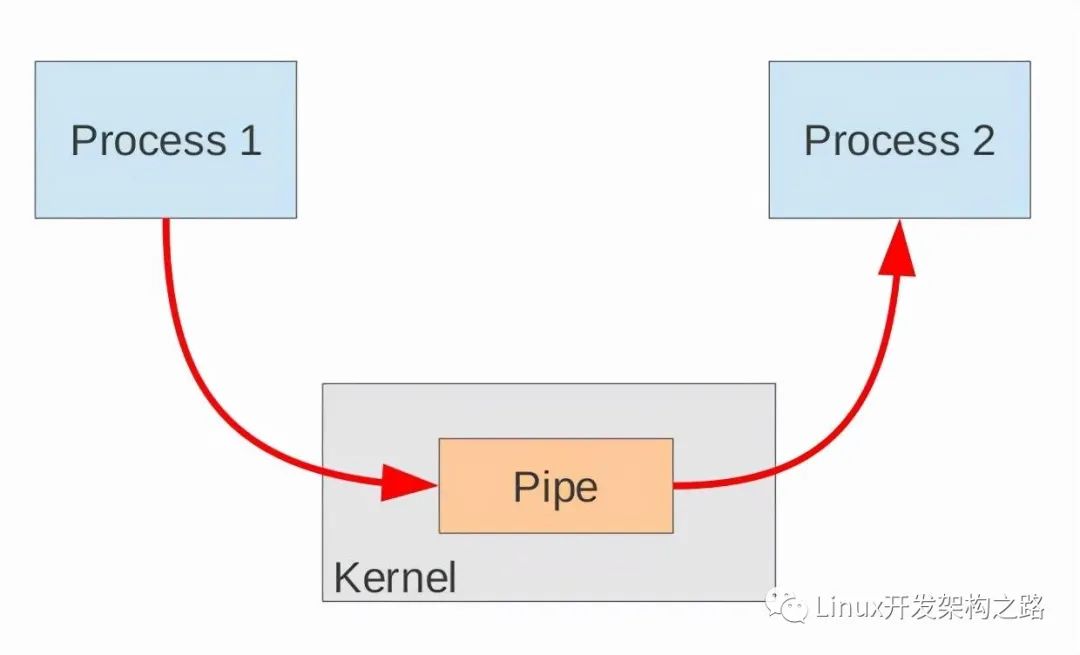
管道是如何创建的
从原理上,管道利用fork机制建立,从而让两个进程可以连接到同一个PIPE上。最开始的时候,上面的两个箭头都连接在同一个进程Process 1上(连接在Process 1上的两个箭头)。当fork复制进程的时候,会将这两个连接也复制到新的进程(Process 2)。随后,每个进程关闭自己不需要的一个连接 (两个黑色的箭头被关闭; Process 1关闭从PIPE来的输入连接,Process 2关闭输出到PIPE的连接),这样,剩下的红色连接就构成了如上图的PIPE。

管道通信的实现细节
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。如下图

有两个 file 数据结构,但它们定义文件操作进程地址是不同的,其中一个是向管道中写入数据的进程地址,而另一个是从管道中读出数据的进程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作。
关于管道的读写
管道实现的源代码在fs/pipe.c中,在pipe.c中有很多函数,其中有两个函数比较重要,即管道读函数pipe_read()和管道写函数pipe_wrtie()。管道写函数通过将字节复制到 VFS 索引节点指向的物理内存而写入数据,而管道读函数则通过复制物理内存中的字节而读出数据。当然,内核必须利用一定的机制同步对管道的访问,为此,内核使用了锁、等待队列和信号。
当写进程向管道中写入时,它利用标准的库函数write(),系统根据库函数传递的文件描述符,可找到该文件的 file 结构。file 结构中指定了用来进行写操作的函数(即写入函数)地址,于是,内核调用该函数完成写操作。写入函数在向内存中写入数据之前,必须首先检查 VFS 索引节点中的信息,同时满足如下条件时,才能进行实际的内存复制工作:
- 内存中有足够的空间可容纳所有要写入的数据;
- 内存没有被读程序锁定。
如果同时满足上述条件,写入函数首先锁定内存,然后从写进程的地址空间中复制数据到内存。否则,写入进程就休眠在 VFS 索引节点的等待队列中,接下来,内核将调用调度程序,而调度程序会选择其他进程运行。写入进程实际处于可中断的等待状态,当内存中有足够的空间可以容纳写入数据,或内存被解锁时,读取进程会唤醒写入进程,这时,写入进程将接收到信号。当数据写入内存之后,内存被解锁,而所有休眠在索引节点的读取进程会被唤醒。
管道的读取过程和写入过程类似。但是,进程可以在没有数据或内存被锁定时立即返回错误信息,而不是阻塞该进程,这依赖于文件或管道的打开模式。反之,进程可以休眠在索引节点的等待队列中等待写入进程写入数据。当所有的进程完成了管道操作之后,管道的索引节点被丢弃,而共享数据页也被释放。
Linux函数原型
#include < unistd.h >
int pipe(int filedes[2]);
filedes[0]用于读出数据,读取时必须关闭写入端,即close(filedes[1]);
filedes[1]用于写入数据,写入时必须关闭读取端,即close(filedes[0])。
程序实例:
int main(void)
{
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if(pipe(fd) 0){ /* 先建立管道得到一对文件描述符 */
exit(0);
}
if((pid = fork()) 0) /* 父进程把文件描述符复制给子进程 */
exit(1);
else if(pid > 0){ /* 父进程写 */
close(fd[0]); /* 关闭读描述符 */
write(fd[1], "nhello worldn", 14);
}
else{ /* 子进程读 */
close(fd[1]); /* 关闭写端 */
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
exit(0);
}
命名管道
由于基于fork机制,所以管道只能用于父进程和子进程之间,或者拥有相同祖先的两个子进程之间 (有亲缘关系的进程之间)。为了解决这一问题,Linux提供了FIFO方式连接进程。FIFO又叫做命名管道(named PIPE)。
实现原理
FIFO (First in, First out)为一种特殊的文件类型,它在文件系统中有对应的路径。当一个进程以读(r)的方式打开该文件,而另一个进程以写(w)的方式打开该文件,那么内核就会在这两个进程之间建立管道,所以FIFO实际上也由内核管理,不与硬盘打交道。之所以叫FIFO,是因为管道本质上是一个先进先出的队列数据结构,最早放入的数据被最先读出来,从而保证信息交流的顺序。FIFO只是借用了文件系统(file system,命名管道是一种特殊类型的文件,因为Linux中所有事物都是文件,它在文件系统中以文件名的形式存在。)来为管道命名。写模式的进程向FIFO文件中写入,而读模式的进程从FIFO文件中读出。当删除FIFO文件时,管道连接也随之消失。FIFO的好处在于我们可以通过文件的路径来识别管道,从而让没有亲缘关系的进程之间建立连接
函数原型:
#include < sys/types.h >
#include < sys/stat.h >
int mkfifo(const char *filename, mode_t mode);
int mknode(const char *filename, mode_t mode | S_IFIFO, (dev_t) 0 );
其中filename是被创建的文件名称,mode表示将在该文件上设置的权限位和将被创建的文件类型(在此情况下为S_IFIFO),dev是当创建设备特殊文件时使用的一个值。因此,对于先进先出文件它的值为0。
程序实例:
#include < stdio.h >
#include < stdlib.h >
#include < sys/types.h >
#include < sys/stat.h >
int main()
{
int res = mkfifo("/tmp/my_fifo", 0777);
if (res == 0)
{
printf("FIFO created/n");
}
exit(EXIT_SUCCESS);
}
信号量
什么是信号量
为了防止出现因多个程序同时访问一个共享资源而引发的一系列问题,我们需要一种方法。比如在任一时刻只能有一个执行线程访问代码的临界区域。临界区域是指执行数据更新的代码需要独占式地执行。而信号量就可以提供这样的一种访问机制,让一个临界区同一时间只有一个线程在访问它,也就是说信号量是用来调协进程对共享资源的访问的。
信号量是一个特殊的变量,程序对其访问都是原子操作,且只允许对它进行等待(即P(信号变量))和发送(即V(信号变量))信息操作。最简单的信号量是只能取0和1的变量,这也是信号量最常见的一种形式,叫做二进制信号量。而可以取多个正整数的信号量被称为通用信号量。
信号量的工作原理
由于信号量只能进行两种操作等待和发送信号,即P(sv)和V(sv),他们的行为是这样的:
- P(sv):如果sv的值大于零,就给它减1;如果它的值为零,就挂起该进程的执行
- V(sv):如果有其他进程因等待sv而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加1.
举个例子,就是两个进程共享信号量sv,一旦其中一个进程执行了P(sv)操作,它将得到信号量,并可以进入临界区,使sv减1。而第二个进程将被阻止进入临界区,因为当它试图执行P(sv)时,sv为0,它会被挂起以等待第一个进程离开临界区域并执行V(sv)释放信号量,这时第二个进程就可以恢复执行。
Linux的信号量机制
Linux提供了一组精心设计的信号量接口来对信号进行操作,它们不只是针对二进制信号量,下面将会对这些函数进行介绍,但请注意,这些函数都是用来对成组的信号量值进行操作的。它们声明在头文件sys/sem.h中。
semget函数
它的作用是创建一个新信号量或取得一个已有信号量,原型为:
int semget(key_t key, int num_sems, int sem_flags);
第一个参数key是整数值(唯一非零),不相关的进程可以通过它访问一个信号量,它代表程序可能要使用的某个资源,程序对所有信号量的访问都是间接的,程序先通过调用semget函数并提供一个键,再由系统生成一个相应的信号标识符(semget函数的返回值),只有semget函数才直接使用信号量键,所有其他的信号量函数使用由semget函数返回的信号量标识符。如果多个程序使用相同的key值,key将负责协调工作。
第二个参数num_sems指定需要的信号量数目,它的值几乎总是1。
第三个参数sem_flags是一组标志,当想要当信号量不存在时创建一个新的信号量,可以和值IPC_CREAT做按位或操作。设置了IPC_CREAT标志后,即使给出的键是一个已有信号量的键,也不会产生错误。而IPC_CREAT | IPC_EXCL则可以创建一个新的,唯一的信号量,如果信号量已存在,返回一个错误。
semget函数成功返回一个相应信号标识符(非零),失败返回-1.
semop函数
它的作用是改变信号量的值,原型为:
int semop(int sem_id, struct sembuf *sem_opa, size_t num_sem_ops);
sem_id是由semget返回的信号量标识符,sembuf结构的定义如下:
struct sembuf{
short sem_num;//除非使用一组信号量,否则它为0
short sem_op;//信号量在一次操作中需要改变的数据,通常是两个数,一个是-1,即P(等待)操作,
//一个是+1,即V(发送信号)操作。
short sem_flg;//通常为SEM_UNDO,使操作系统跟踪信号,
//并在进程没有释放该信号量而终止时,操作系统释放信号量
};
semctl函数
int semctl(int sem_id, int sem_num, int command, ...);
如果有第四个参数,它通常是一个union semum结构,定义如下:
union semun{
int val;
struct semid_ds *buf;
unsigned short *arry;
};
前两个参数与前面一个函数中的一样,command通常是下面两个值中的其中一个
SETVAL:用来把信号量初始化为一个已知的值。p 这个值通过union semun中的val成员设置,其作用是在信号量第一次使用前对它进行设置。
IPC_RMID:用于删除一个已经无需继续使用的信号量标识符。
消息队列
什么是消息队列
消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列是随内核持续的。
每个消息队列都有一个队列头,用结构struct msg_queue来描述。队列头中包含了该消息队列的大量信息,包括消息队列键值、用户ID、组ID、消息队列中消息数目等等,甚至记录了最近对消息队列读写进程的ID。读者可以访问这些信息,也可以设置其中的某些信息。
结构msg_queue用来描述消息队列头,存在于系统空间:
struct msg_queue {
struct kern_ipc_perm q_perm;
time_t q_stime; /* last msgsnd time */
time_t q_rtime; /* last msgrcv time */
time_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
pid_t q_lspid; /* pid of last msgsnd */
pid_t q_lrpid; /* last receive pid */
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
};
结构msqid_ds用来设置或返回消息队列的信息,存在于用户空间:
struct msqid_ds {
struct ipc_perm msg_perm;
struct msg *msg_first; /* first message on queue,unused */
struct msg *msg_last; /* last message in queue,unused */
__kernel_time_t msg_stime; /* last msgsnd time */
__kernel_time_t msg_rtime; /* last msgrcv time */
__kernel_time_t msg_ctime; /* last change time */
unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */
unsigned long msg_lqbytes; /* ditto */
unsigned short msg_cbytes; /* current number of bytes on queue */
unsigned short msg_qnum; /* number of messages in queue */
unsigned short msg_qbytes; /* max number of bytes on queue */
__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */
__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
消息队列与内核的联系
下图说明了内核与消息队列是怎样建立起联系的:

从上图可以看出,全局数据结构 struct ipc_ids msg_ids 可以访问到每个消息队列头的第一个成员:struct kern_ipc_perm;而每个struct kern_ipc_perm能够与具体的消息队列对应起来是因为在该结构中,有一个key_t类型成员key,而key则唯一确定一个消息队列。 kern_ipc_perm结构如下:
struct kern_ipc_perm{ //内核中记录消息队列的全局数据结构msg_ids能够访问到该结构;
key_t key; //该键值则唯一对应一个消息队列
uid_t uid;
gid_t gid;
uid_t cuid;
gid_t cgid;
mode_t mode;
unsigned long seq;
}
消息队列的操作
打开或创建消息队列
息队列的内核持续性要求每个消息队列都在系统范围内对应唯一的键值,所以,要获得一个消息队列的描述字,只需提供该消息队列的键值即可;
注:消息队列描述字是由在系统范围内唯一的键值生成的,而键值可以看作对应系统内的一条路经。
读写的操作
消息读写操作非常简单,对开发人员来说,每个消息都类似如下的数据结构:
struct msgbuf{
long mtype;
char mtext[1];
};
mtype成员代表消息类型,从消息队列中读取消息的一个重要依据就是消息的类型;mtext是消息内容,当然长度不一定为1。因此,对于发送消息来说, 首先预置一个msgbuf缓冲区并写入消息类型和内容,调用相应的发送函数即可;对读取消息来说,首先分配这样一个msgbuf缓冲区,然后把消息读入该缓冲区即可。
获得或设置消息队列属性:
消息队列的信息基本上都保存在消息队列头中,因此,可以分配一个类似于消息队列头的结构,来返回消息队列的属性;同样可以设置该数据结构。

信号
信号本质
信号是在软件层次上对中断机制的一种interwetten与威廉的赔率体系 ,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。信号是异步的,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。
信号是进程间通信机制中唯一的异步通信机制,可以看作是异步通知,通知接收信号的进程有哪些事情发生了。信号机制经过POSIX实时扩展后,功能更加强大,除了基本通知功能外,还可以传递附加信息。
信号来源
信号事件的发生有两个来源:硬件来源(比如我们按下了键盘或者其它硬件故障);软件来源,最常用发送信号的系统函数是kill, raise, alarm和setitimer以及sigqueue函数,软件来源还包括一些非法运算等操作。
信号的种类
可以从两个不同的分类角度对信号进行分类:(1)可靠性方面:可靠信号与不可靠信号;(2)与时间的关系上:实时信号与非实时信号。
可靠信号和不可靠信号
不可靠信号
Linux信号机制基本上是从Unix系统中继承过来的。早期Unix系统中的信号机制比较简单和原始,后来在实践中暴露出一些问题,因此,把那些建立在早期机制上的信号叫做”不可靠信号”,信号值小于SIGRTMIN(Red hat 7.2中,SIGRTMIN=32,SIGRTMAX=63)的信号都是不可靠信号。这就是”不可靠信号”的来源。它的主要问题是:
- 进程每次处理信号后,就将对信号的响应设置为默认动作。在某些情况下,将导致对信号的错误处理;因此,用户如果不希望这样的操作,那么就要在信号处理函数结尾再一次调用signal(),重新安装该信号。
- 信号可能丢失 因此,早期unix下的不可靠信号主要指的是进程可能对信号做出错误的反应以及信号可能丢失。
- Linux支持不可靠信号,但是对不可靠信号机制做了改进:在调用完信号处理函数后,不必重新调用该信号的安装函数(信号安装函数是在可靠机制上的实现)。因此,Linux下的不可靠信号问题主要指的是信号可能丢失。
可靠信号
- 随着时间的发展,实践证明了有必要对信号的原始机制加以改进和扩充,力图实现”可靠信号”。由于原来定义的信号已有许多应用,不好再做改动,最终只好又新增加了一些信号,并在一开始就把它们定义为可靠信号,这些信号支持排队,不会丢失。
- 信号值位于SIGRTMIN和SIGRTMAX之间的信号都是可靠信号,可靠信号克服了信号可能丢失的问题。Linux在支持新版本的信号安装函数sigation()以及信号发送函数sigqueue()的同时,仍然支持早期的signal()信号安装函数,支持信号发送函数kill()
注意:可靠信号是指后来添加的新信号(信号值位于SIGRTMIN及SIGRTMAX之间);不可靠信号是信号值小于SIGRTMIN的信号。信号的可靠与不可靠只与信号值有关,与信号的发送及安装函数无关。
实时信号与非实时信号
非实时信号都不支持排队,都是不可靠信号,编号是1-31,0是空信号;实时信号都支持排队,都是可靠信号。
进程对信号的响应
- 忽略信号,即对信号不做任何处理,其中,有两个信号不能忽略:SIGKILL及SIGSTOP;
- 捕捉信号。定义信号处理函数,当信号发生时,执行相应的处理函数;
- 执行缺省操作,Linux对每种信号都规定了默认操作
注意:进程对实时信号的缺省反应是进程终止。
信号的发送和安装
- 发送信号的主要函数有:kill()、raise()、 sigqueue()、alarm()、setitimer()以及abort()。
- 如果进程要处理某一信号,那么就要在进程中安装该信号。安装信号主要用来确定信号值及进程针对该信号值的动作之间的映射关系,即进程将要处理哪个信号;该信号被传递给进程时,将执行何种操作。
注意:inux主要有两个函数实现信号的安装:signal()、sigaction()。其中signal()在可靠信号系统调用的基础上实现, 是库函数。它只有两个参数,不支持信号传递信息,主要是用于前32种非实时信号的安装;而sigaction()是较新的函数(由两个系统调用实现:sys_signal以及sys_rt_sigaction),有三个参数,支持信号传递信息,主要用来与 sigqueue() 系统调用配合使用,当然,sigaction()同样支持非实时信号的安装。sigaction()优于signal()主要体现在支持信号带有参数。
共享内存
共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式。是针对其他通信机制运行效率较低而设计的。两个不同进程A、B共享内存的意思是,同一块物理内存被映射到进程A、B各自的进程地址空间。进程A可以即时看到进程B对共享内存中数据的更新,反之亦然。由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以。
系统V共享内存原理
进程间需要共享的数据被放在一个叫做IPC共享内存区域的地方,所有需要访问该共享区域的进程都要把该共享区域映射到本进程的地址空间中去。系统V共享内存通过shmget获得或创建一个IPC共享内存区域,并返回相应的标识符。内核在保证shmget获得或创建一个共享内存区,初始化该共享内存区相应的shmid_kernel结构体的同时,还将在特殊文件系统shm中,创建并打开一个同名文件,并在内存中建立起该文件的相应dentry及inode结构,新打开的文件不属于任何一个进程(任何进程都可以访问该共享内存区)。所有这一切都是系统调用shmget完成的。
系统V共享内存API
shmget()用来获得共享内存区域的ID,如果不存在指定的共享区域就创建相应的区域。shmat()把共享内存区域映射到调用进程的地址空间中去,这样,进程就可以方便地对共享区域进行访问操作。shmdt()调用用来解除进程对共享内存区域的映射。shmctl实现对共享内存区域的控制操作。
套接字(socket)
最早出现在UNIX系统中,是UNIX系统主要的信息传递方式。
Socket相关概念
两个基本概念:客户方和服务方。当两个应用之间需要采用SOCKET通信时,首先需要在两个应用之间(可能位于同一台机器,也可能位于不同的机器)建立SOCKET连接。
发起呼叫连接请求的一方为客户方
在客户方呼叫连接请求之前,它必须知道服务方在哪里。所以需要知道服务方所在机器的IP地址或机器名称,如果客户方和服务方事前有一个约定就好了,这个约定就是PORT(端口号)。也就是说,客户方可以通过服务方所在机器的IP地址或机器名称和端口号唯一的确定方式来呼叫服务方。
接受呼叫连接请求的一方成为服务方。
在客户方呼叫之前,服务方必须处于侦听状态,侦听是否有客户要求建立连接。一旦接到连接请求,服务方可以根据情况建立或拒绝连接。当客户方的消息到达服务方端口时,会自动触发一个事件(event),服务方只要接管该事件,就可以接受来自客户方的消息了。
Socket类型
流式Socket(STREAM):是一种面向连接的Socekt,针对面向连接的TCP服务应用,安全,但是效率低;
数据报式Socket(DATAGAM):是一种无连接的Socket,对应于无连接的UDP服务应用。不安(丢失,顺序混乱,在接受端要分析重排及要求重发),但效率高。
Socket一般应用模式(服务端和客户端)

Socket通信基本流程图

-
通信
+关注
关注
18文章
6030浏览量
135975 -
Linux
+关注
关注
87文章
11302浏览量
209418 -
函数
+关注
关注
3文章
4329浏览量
62588
发布评论请先 登录
相关推荐
NanoEdge AI的威廉希尔官方网站 原理、应用场景及优势
智能IC卡测试设备的威廉希尔官方网站 原理和应用场景
实时示波器的威廉希尔官方网站 原理和应用场景
无线通信测试平台的威廉希尔官方网站 原理和应用场景
OTA测试暗箱的威廉希尔官方网站 原理和应用场景
系统放大器的威廉希尔官方网站 原理和应用场景
倍频器的威廉希尔官方网站 原理和应用场景
CP-OFMD调制波形应用场景
uwb定位威廉希尔官方网站 原理及应用场景
蓝牙多连接应用场景举例
SMT组装工艺流程的应用场景
labview 和 wincc 的区别 使用场景
Linux进程的概念及进程通信的应用场景





 工商网监
工商网监
评论