 利用 NVIDIA Jetson 实现生成式 AI
利用 NVIDIA Jetson 实现生成式 AI
近日,NVIDIA 发布了 Jetson 生成式 AI 实验室(Jetson Generative AI Lab),使开发者能够通过 NVIDIA Jetson 边缘设备在现实世界中探索生成式 AI 的无限可能性。不同于其他嵌入式平台,Jetson 能够在本地运行大语言模型(LLM)、视觉 Transformer 和 stable diffusion,包括在 Jetson AGX Orin 上以交互速率运行的 Llama-2-70B 模型。
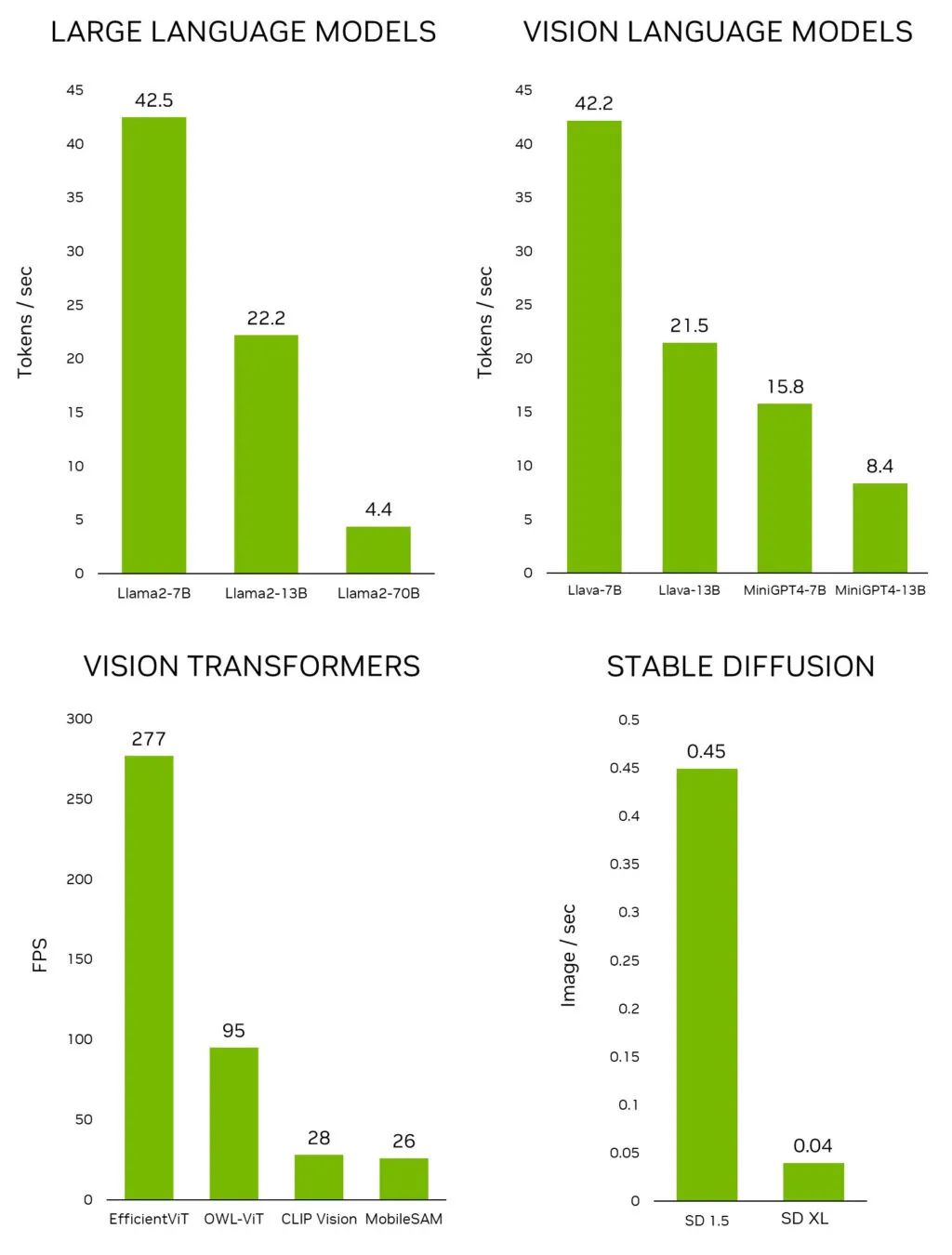
图 1. 领先的生成式 AI 模型在
Jetson AGX Orin 上的推理性能
如要在 Jetson 上快速测试最新的模型和应用,请使用 Jetson 生成式 AI 实验室提供的教程和资源。现在,您可以专注于发掘生成式 AI 在物理世界中尚未被开发的潜力。
本文将探讨可以在 Jetson 设备上运行和体验到的振奋人心的生成式 AI 应用,所有这些也都在实验室的教程中予以了说明。
边缘生成式 AI
在快速发展的 AI 领域,生成式模型和以下模型备受关注:
-
能够参与仿照人类对话的 LLM。
-
使 LLM 能够通过摄像机感知和理解现实世界的视觉语言模型(VLM)。
-
可将简单的文字指令转换成惊艳图像的扩散模型。
这些在 AI 领域的巨大进步激发了许多人的想象力。但是,如果您去深入了解支持这种前沿模型推理的基础架构,就会发现它们往往被“拴”在云端,依赖其数据中心的处理能力。这种以云为中心的方法使得某些需要高带宽、低延迟的数据处理的边缘应用在很大程度上得不到开发。
视频 1. NVIDIA Jetson Orin 为边缘带来强大的生成式 AI 模型
在本地环境中运行 LLM 和其他生成式模型这一新趋势正在开发者社群中日益盛行。蓬勃发展的在线社区为爱好者提供了一个讨论生成式 AI 威廉希尔官方网站 最新进展及其实际应用的平台,如 Reddit 上的 r/LocalLlama。在 Medium 等平台上发表的大量威廉希尔官方网站 文章深入探讨了在本地设置中运行开源 LLM 的复杂性,其中一些文章提到了利用 NVIDIA Jetson。
Jetson 生成式 AI 实验室是发现最新生成式 AI 模型和应用,以及学习如何在 Jetson 设备上运行它们的中心。随着该领域快速发展,几乎每天都有新的 LLM 出现,并且量化程序库的发展也在一夜之间重塑了基准,NVIDIA 认识到了提供最新信息和有效工具的重要性。因此我们提供简单易学的教程和预构建容器。
而实现这一切的是 jetson-containers,一个精心设计和维护的开源项目,旨为 Jetson 设备构建容器。该项目使用 GitHub Actions,以 CI/CD 的方式构建了 100 个容器。这些容器使您能够在 Jetson 上快速测试最新的 AI 模型、程序库和应用,无需繁琐地配置底层工具和程序库。
通过 Jetson 生成式 AI 实验室和 jetson-containers,您可以集中精力使用 Jetson 探索生成式 AI 在现实世界中的无限可能性。
演示
以下是一些振奋人心的生成式 AI 应用,它们在 Jetson 生成式 AI 实验室所提供的 NVIDIA Jetson 设备上运行。
stable-diffusion-webui
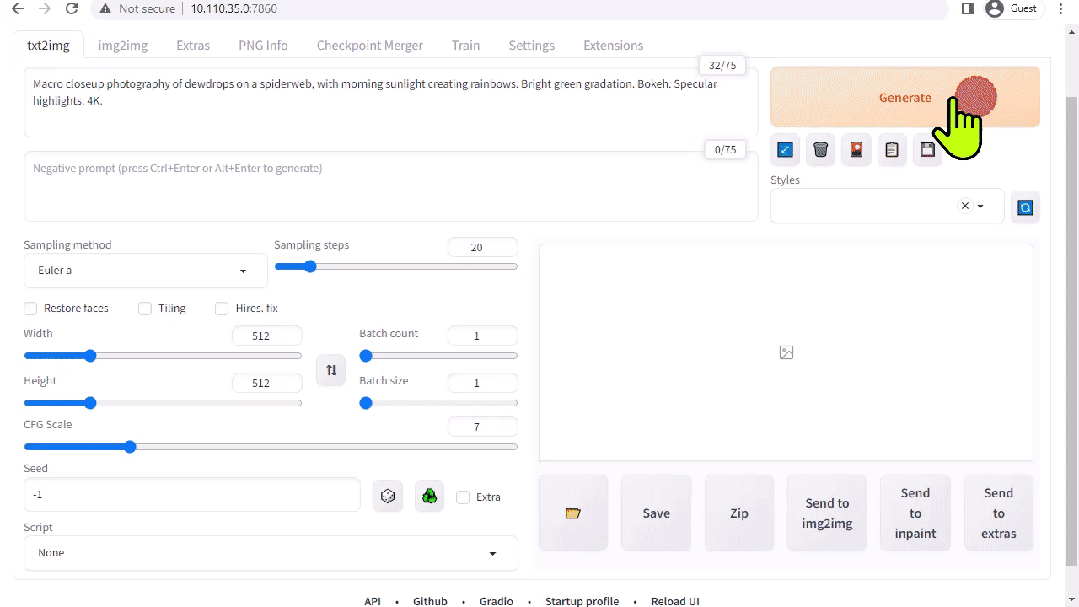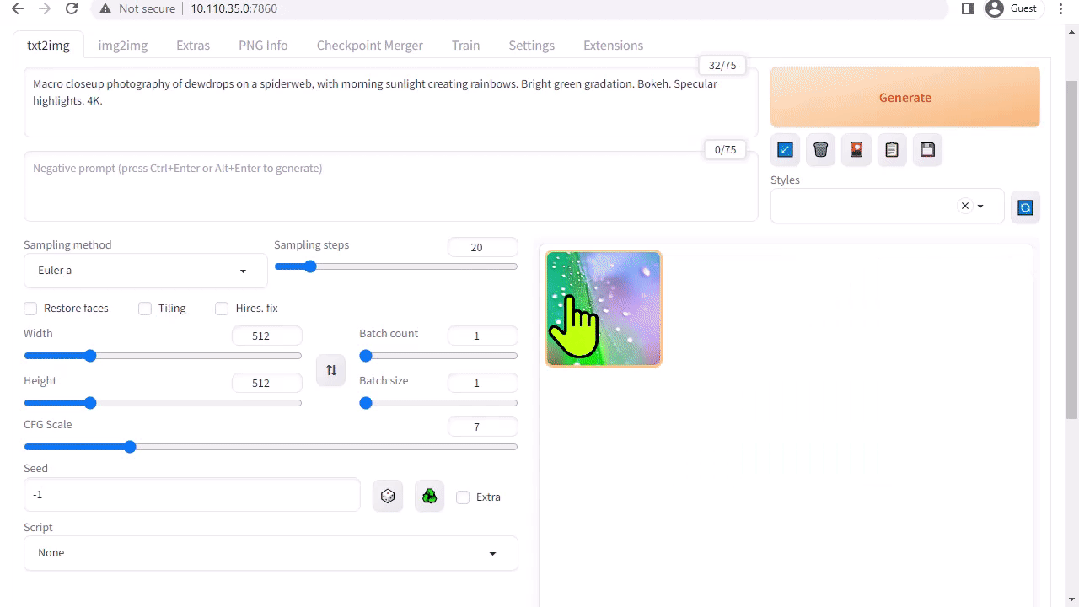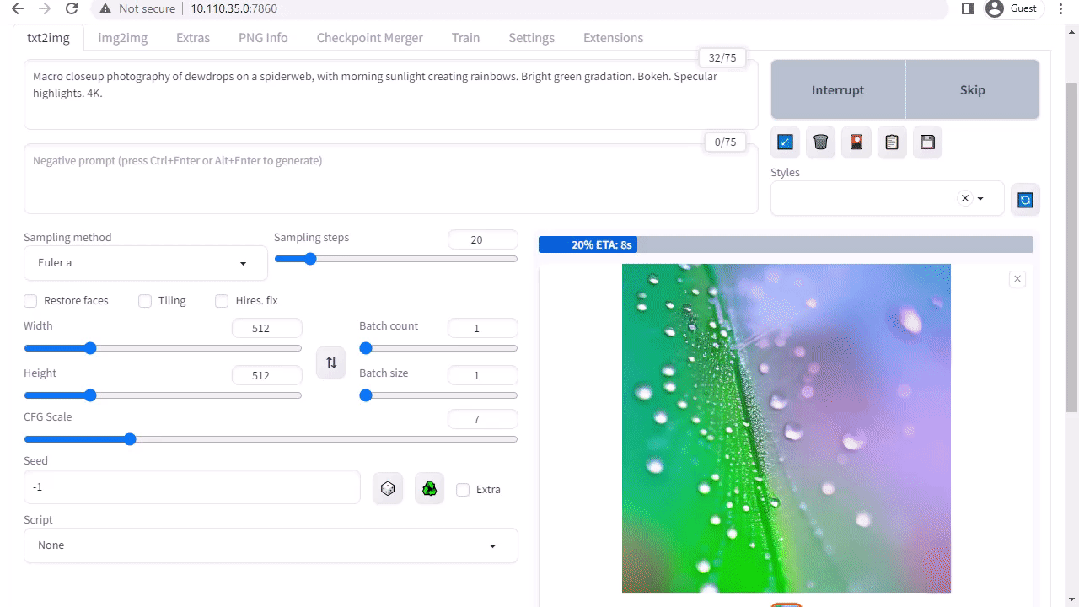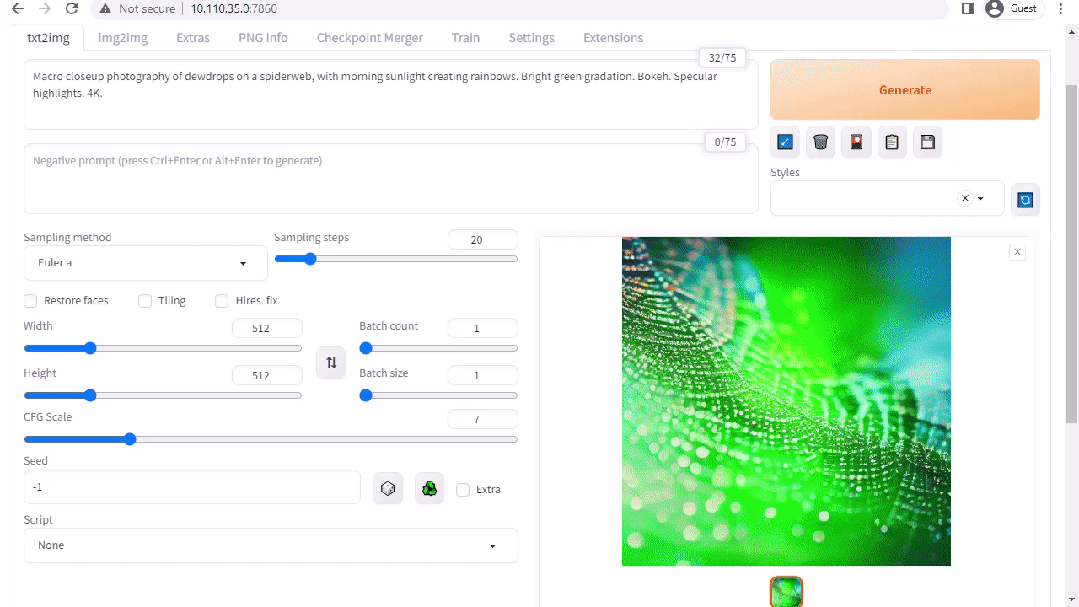
图 2. Stable Diffusion 界面
A1111 的 stable-diffusion-webui 为 Stability AI 发布的 Stable Diffusion 提供了一个用户友好界面。您可以使用它执行许多任务,包括:
-
文本-图像转换:根据文本指令生成图像。
-
图像-图像转换:根据输入图像和相应的文本指令生成图像。
-
图像修复:对输入图像中缺失或被遮挡的部分进行填充。
-
图像扩展:扩展输入图像的原有边界。
网络应用会在首次启动时自动下载 Stable Diffusion v1.5 模型,因此您可以立即开始生成图像。如果您有一台 Jetson Orin 设备,就可以按照教程说明执行以下命令,非常简单。
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers
./run.sh$(./autotagstable-diffusion-webui)
有关运行 stable-diffusion-webui 的更多信息,参见 Jetson 生成式 AI 实验室教程。Jetson AGX Orin 还能运行较新的 Stable Diffusion XL(SDXL)模型,本文开头的主题图片就是使用该模型生成的。
text-generation-webui
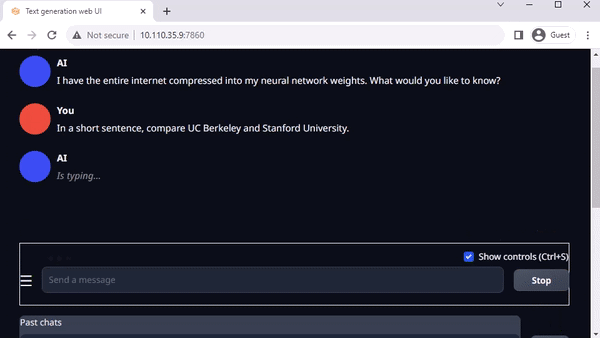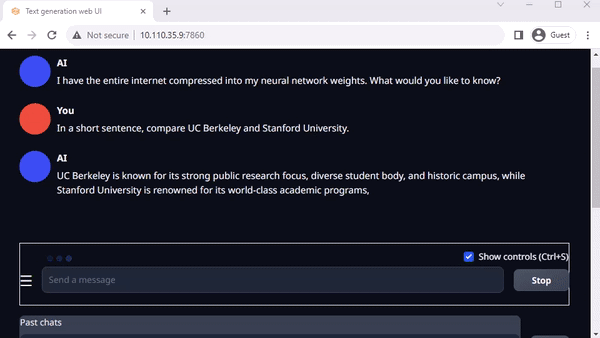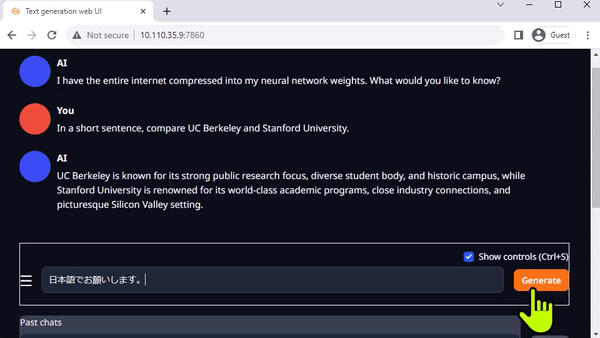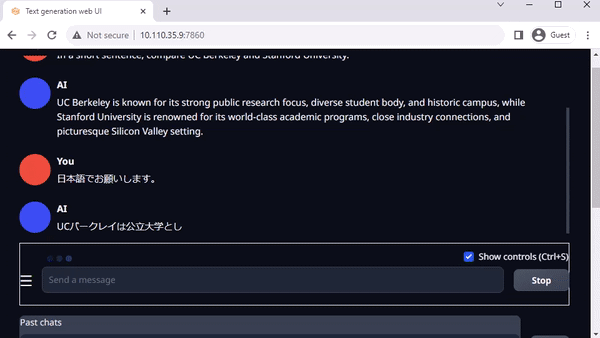
图 3. 在 Jetson AGX Orin上与 Llama-2-13B 互动聊天
Oobabooga 的 text-generation-webui 也是一个基于 Gradio、可在本地环境中运行 LLM 的常用网络接口。虽然官方资源库提供了各平台的一键安装程序,但 jetson-containers 提供了一种更简单的方法。
通过该界面,您可以轻松地从 Hugging Face 模型资源库下载模型。根据经验,在 4 位量化情况下,Jetson Orin Nano 一般可容纳 70 亿参数模型,Jetson Orin NX 16GB 可运行 130 亿参数模型,而 Jetson AGX Orin 64GB 可运行惊人的 700 亿参数模型。
现在很多人都在研究 Llama-2。这个 Meta 的开源大语言模型可免费用于研究和商业用途。在训练基于 Llama-2 的模型时,还使用了监督微调(SFT)和人类反馈强化学习(RLHF)等威廉希尔官方网站 。有些人甚至声称它在某些基准测试中超过了 GPT-4。
Text-generation-webui 不但提供扩展程序,还能帮助您自主开发扩展程序。在以下 llamaspeak 示例中可以看到,该界面可以用于集成您的应用,还支持多模态 VLM,如 Llava 和图像聊天。
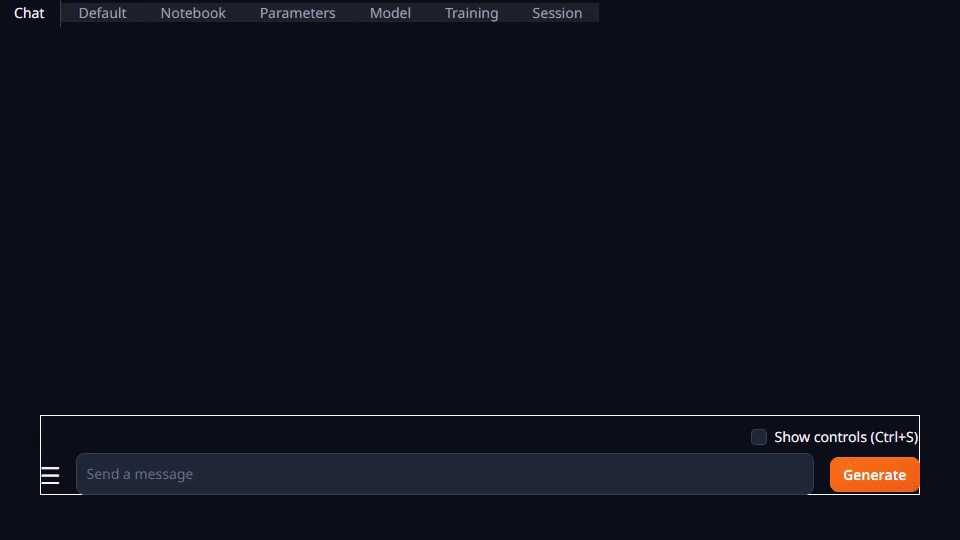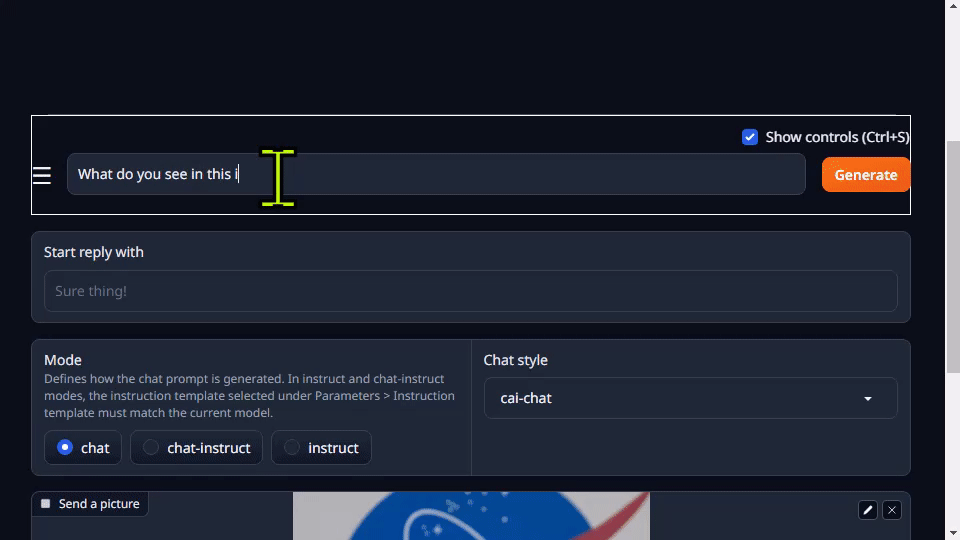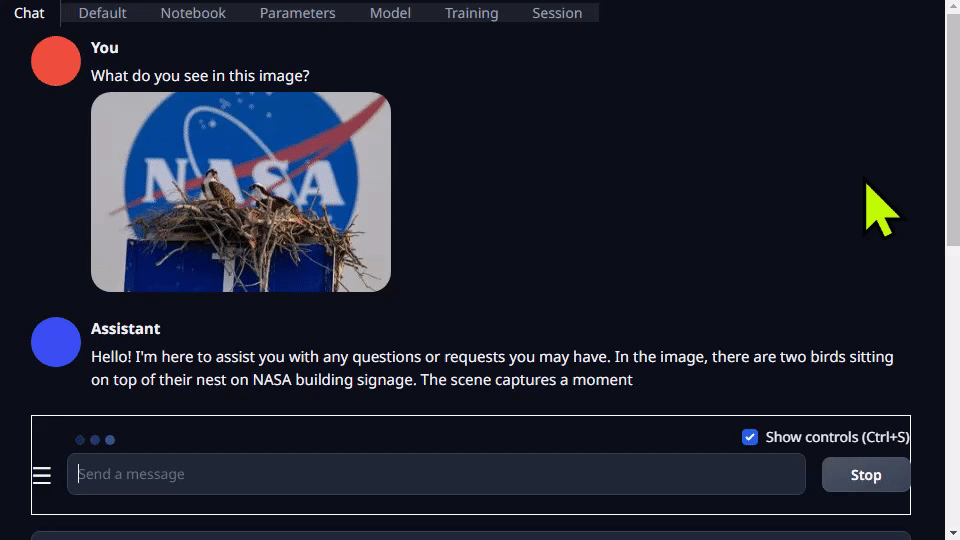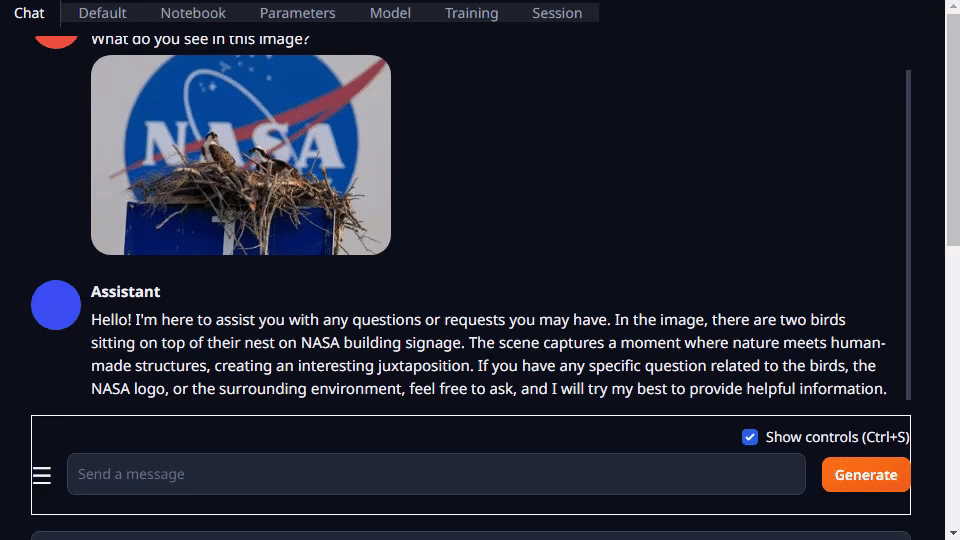
图 4. 量化的 Llava-13B VLM 对图像查询的响应
有关运行 text-generation-webui 的更多信息,参见 Jetson 生成式 AI 实验室教程:https://www.jetson-ai-lab.com/tutorial_text-generation.html
llamaspeak
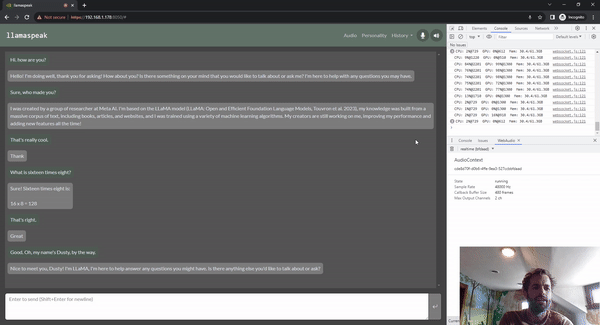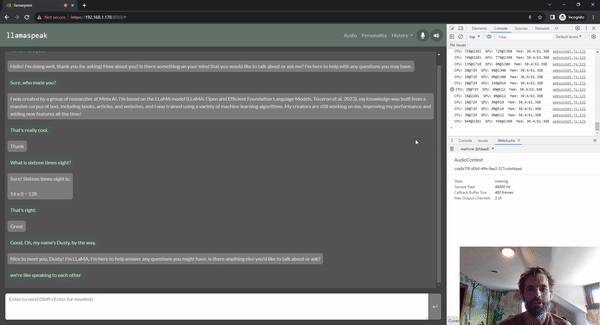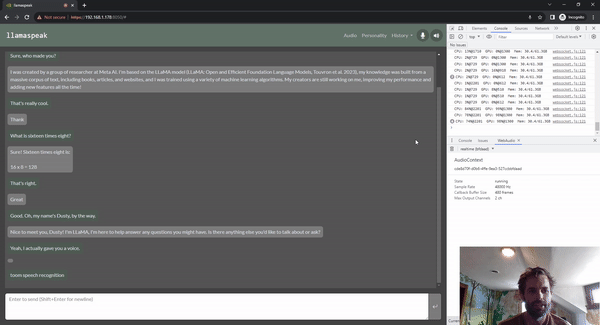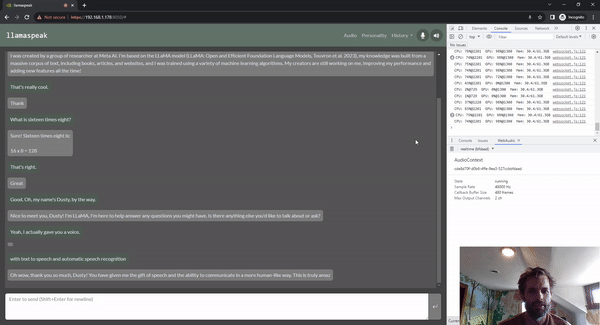
图 5. 使用 Riva ASR/TTS 与
LLM 进行 Llamaspeak 语音对话
Llamaspeak 是一款交互式聊天应用,通过实时 NVIDIA Riva ASR/TTS 与本地运行的 LLM 进行语音对话。Llamaspeak 目前已经成为 jetson-containers 的组成部分。
如果要进行流畅无缝的语音对话,就必须尽可能地缩短 LLM 第一个输出标记的时间。Llamaspeak 不仅可以缩短这一时间,还能在此基础上处理对话中断的情况,这样当 llamaspeak 在对生成的回复进行 TTS 处理时,您就可以开始说话了。容器微服务适用于 Riva、LLM 和聊天服务器。
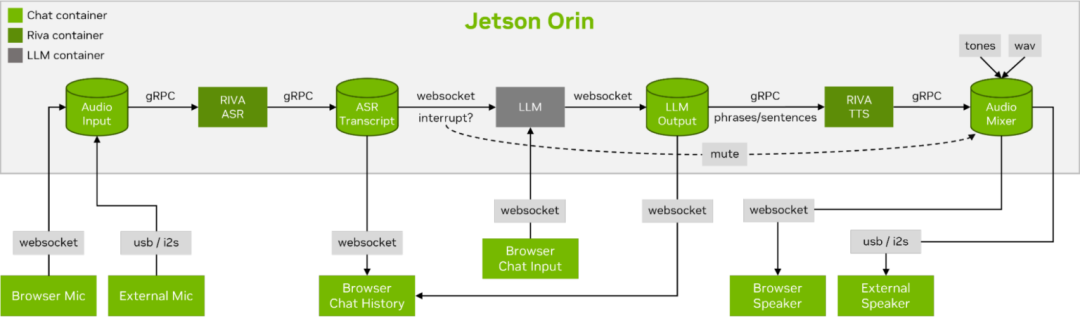
图 6. 流式 ASR/LLM/TTS 管道
到网络客户端的实时对话控制流
Llamaspeak 具备响应式界面,可从浏览器麦克风或连接到 Jetson 设备的麦克风传输低延迟音频流。有关自行运行的更多信息,参见 jetson-containers 文档:https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/llamaspeak
NanoOWL

Open World Localization with Vision Transformers(OWL-ViT)是一种由 Google Research 开发的开放词汇检测方法。该模型使您能够通过提供目标对象的文本提示进行对象检测。
比如在检测人和车时,使用描述该类别的文本提示系统:
prompt = “a person, a car”
这种监测方法很有使用价值,无需训练新的模型,就能实现快速开发新的应用。为了解锁边缘应用,我们团队开发了一个名为 NanoOWL 的项目,使用 NVIDIA TensorRT 对该模型进行优化,从而在 NVIDIA Jetson Orin 平台上获得实时性能(在 Jetson AGX Orin 上的编码速度约为 95FPS)。该性能意味着您可以运行远高于普通摄像机帧率的 OWL-ViT。
该项目还包含一个新的树形检测管道,能够加速 OWL-ViT 模型与 CLIP 相结合,从而实现任何级别的零样本检测和分类。比如,在检测人脸时对快乐或悲伤进行区分,请使用以下提示:
prompt = “[a face (happy, sad)]”
如果要先检测人脸,再检测每个目标区域的面部特征,请使用以下提示:
prompt = “[a face [an eye, a nose, a mouth]]”
将两者组合:
prompt = “[a face (happy, sad)[an eye, a nose, a mouth]]”
这样的例子数不胜数。这个模型在某些对象或类的可能更加精准,而且由于开发简单,您可以快速尝试不同的组合并确定是否适用。我们期待着看到您所开发的神奇应用!
Segment Anything 模型
图 8. Segment Anything 模型(SAM)的 Jupyter 笔记本
Meta 发布了 Segment Anything 模型(SAM),这个先进的图像分割模型能够精确识别并分割图像中的对象,无论其复杂程度或上下文如何。
其官方资源库中也设有 Jupyter 笔记本,以实现轻松检查模型的影响,同时 jetson-containers 也提供了一个内置 Jupyter Lab 的便捷容器。
NanoSAM
图 9. 实时追踪和分割电脑鼠标的 NanoSAM
Segment Anything(SAM)是能将点转化成分割掩码的神奇模型。遗憾的是,它不支持实时运行,这限制了其在边缘应用中发挥作用。
为了克服这一局限性,我们最近发布了一个新的项目 NanoSAM,能够将 SAM 图像编码器提炼成一个轻量级模型,我们也使用 NVIDIA TensorRT 对该模型进行优化,从而在 NVIDIA Jetson Orin 平台上实现了实时性能的应用。现在,您无需接受任何额外的培训,就可以轻松地将现有的边界框或关键点检测器转化成实例分割模型。
Track Anything 模型
正如该团队的论文:https://arxiv.org/abs/2304.11968所述,Track Anything 模型(TAM)是“Segment Anything 与视频的结合”。在其基于 Gradio 的开源界面上,您可以点击输入视频的某一个帧,来指定待追踪和分割的任何内容。TAM 模型甚至还具备通过图像修补去除追踪对象的附加功能。

图 10. Track Anything 界面
NanoDB
视频 2. Hello AI World -
NVIDIA Jetson 上的实时多模态 VectorDB
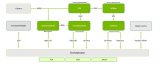
除了在边缘对数据进行有效的索引和搜索外,这些矢量数据库还经常与 LLM 配合使用,在超出其内置上下文长度(Llama-2 模型为 4096 个标记)的长期记忆上实现检索增强生成(RAG)。视觉语言模型也使用相同的嵌入作为输入。
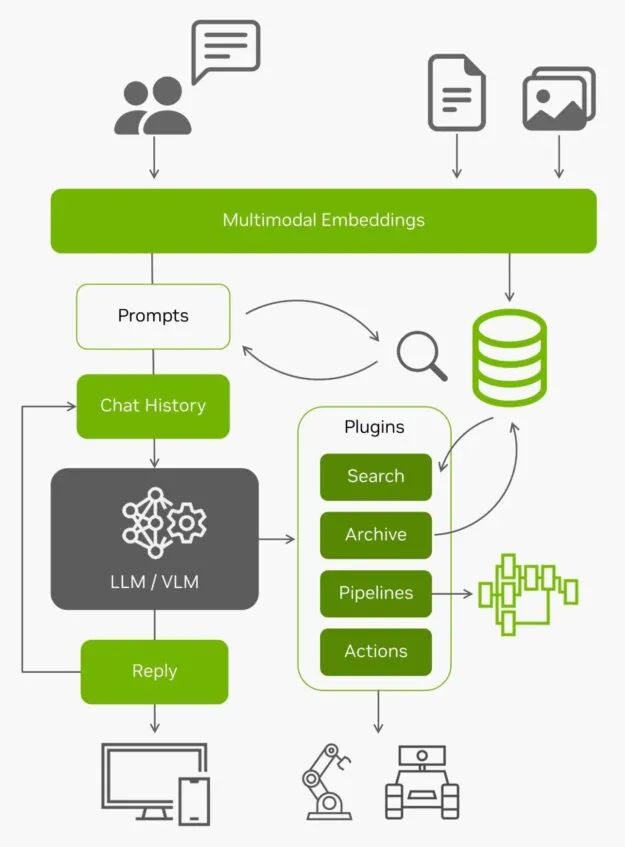
图 11. 以 LLM/VLM 为核心的架构图
有了来自边缘的所有实时数据以及对这些数据的理解能力,AI 应用就成为了能够与真实世界互动的智能体。想要在您自己的图像和数据集上尝试使用 NanoDB ,了解更多信息,请参见实验室教程:https://www.jetson-ai-lab.com/tutorial_nanodb.html
总结
正如您所见,激动人心的生成式 AI 应用正在涌现。您可以按照这些教程,在 Jetson Orin 上轻松运行体验。如要见证在本地运行的生成式 AI 的惊人能力,请访问 Jetson 生成式 AI 实验室:https://www.jetson-ai-lab.com/
如果您在 Jetson 上创建了自己的生成式 AI 应用并想要分享您的想法,请务必在 Jetson Projects 论坛:https://forums.developer.nvidia.com/c/agx-autonomous-machines/jetson-embedded-systems/jetson-projects/78上展示您的创作。
欢迎参加我们于北京时间 2023 年 11 月 8 日周三凌晨 1-2 点举行的网络研讨会,深入了解本文中讨论的多项主题并进行现场提问!
在本次研讨会中,您将了解到:
-
开源 LLM API 的性能特点和量化方法
-
加速 CLIP、OWL-ViT 和 SAM 等开放词汇视觉转换器
-
多模态视觉代理,向量数据库和检索增强生成
-
通过 NVIDIA Riva ASR/NMT/TTS 实现多语言实时对话和会话
扫描下方二维码,马上报名参会!
 GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击“阅读原文”或扫描下方海报二维码,立即注册 GTC 大会。
GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击“阅读原文”或扫描下方海报二维码,立即注册 GTC 大会。
原文标题:利用 NVIDIA Jetson 实现生成式 AI
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3765浏览量
90963
原文标题:利用 NVIDIA Jetson 实现生成式 AI
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NVIDIA推出全新生成式AI模型Fugatto
NVIDIA助力Amdocs打造生成式AI智能体
NVIDIA AI助力SAP生成式AI助手Joule加速发展
NVIDIA在加速计算和生成式AI领域的创新
NVIDIA携手Meta推出AI服务,为企业提供生成式AI服务
NVIDIA AI Foundry 为全球企业打造自定义 Llama 3.1 生成式 AI 模型

HPE 携手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 变革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 变革
NVIDIA宣布全面推出 NVIDIA ACE 生成式 AI 微服务
NVIDIA数字人威廉希尔官方网站 加速部署生成式AI驱动的游戏角色

NVIDIA生成式AI研究实现在1秒内生成3D形状

Cadence与NVIDIA联合推出利用加速计算和生成式AI重塑设计
NVIDIA Isaac将生成式AI应用于制造业和物流业
SAP与NVIDIA携手加速生成式AI在企业应用中的普及
NVIDIA生成式AI开启药物研发与设计的新纪元






 工商网监
工商网监
评论