 列表切片操作的特点
列表切片操作的特点
切片热身
列表的切片操作是指对其中单个或者多个索引对应元素进行的操作,具有如下几个特点:
- 切片区间是左闭右开区间
- 切片的下标可以是负数,当为负数时,意味着从后到前的位置,且-1位倒数第一个
- 默认步长是1,可通过增加第三个参数实现不同切片
- 步长是-1时,可实现倒序切片
- 下标缺省时,表示从最"前"到最"后"(这里的前后要结合上下文来看,具体后面有示例)
例如,下面这些常规操作大家应该都很熟悉:
1lyst = list(range(10))
2lyst[1:4] #[1, 2, 3]
3lyst[1:4:2] #[1, 3]
4lyst[-5:-1] #[5, 6, 7, 8]
5lyst[-1:-5:-1] #[9, 8, 7, 6]
这里重点补充对于缺省下标的理解,即列表内部是以什么原则处理缺省下标值:
1lyst = list(range(10))
2lyst[:2] #[0, 1],起始下标缺省,默认为0,等价于lyst[0:2]
3lyst[2:] #[2, 3, 4, 5, 6, 7, 8, 9],终止下标缺省,默认为n=len(lyst),等价于lyst[2:n]
4lyst[:] #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],起始和终止下标均缺省,等价于lyst[0:n]
5lyst[:2:-1] #[9, 8, 7, 6, 5, 4, 3],步长为负数时,起始下标缺省,默认为-1,等价于lyst[-1:2:-1]
6lyst[2::-1] #[2, 1, 0],步长为负数时,终止下标缺省,默认为-n-1,等价于lyst[2:-n-1:-1]
7lyst[::-1] #[9, 8, 7, 6, 5, 4, 3, 2, 1, 0],步长为负数,起始和终止下标均缺省,默认为lyst[-1:-n-1:-1]
总结来说,就是步长为正数时,首末缺省下标分别是0和n;步长为负时,首末缺省下标分别是-1和-n-1。特别地,当步长为-1、首末下标均缺省时,效果等价于lyst.reverse()或者reversed(lyst),但具体功能有区别:
1lyst = list(range(10))
2lyst[::-1] #输出[9, 8, 7, 6, 5, 4, 3, 2, 1, 0],只是输出逆序结果,lyst本身不变
3lyst.reverse() #对列表的inplace操作,无返回值,但执行后lyst变为[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
4reversed(lyst) #lyst列表不变,返回逆序结果,但返回的是一个迭代器对象
另外,列表中切片索引数值 要求均为整数 (曾有PEP提议,索引可接受任意值,然后由python进行隐式取整处理,但被reject了),且 步长索引不能为0 。
切片访问
对列表某索引对应值进行访问,当对单个索引访问时,要注意索引的合格范围;但对列表切片时则不会显式报错。其中,单索引的合格范围为-n—n-1,共2n个合格索引,其中n为列表长度;而对于范围索引时,即使访问越界也不会显式报错,而仅仅是返回结果为空:
1lyst = list(range(10))
2lyst[10] #IndexError: list index out of range
3lyst[-12] #IndexError: list index out of range
4lyst[5:15] #[5, 6, 7, 8, 9]
5lyst[10:] #[]
6lyst[-12:-1:-1] #[]
这里补充一个亲身经历的错误:要倒序返回一个列表的前n-1个值(即最后一个元素除外的所有元素倒序输出),因为可以正负索引混合使用,所以自己想当然的写下了如下语句:
1lyst[-2:-1:-1] #返回[]
我的逻辑是倒数第二个索引是-2,返回前面的所有值,第一个值是下标0,但由于索引是左开右闭区间,所以如果写0的话访问不到,那么要比0再小一个,也就是-1。但实际上,python可不这么想,它会将索引-2解释为倒数第二个值没错,但是索引-1会解释成倒数第一个值(更准确的讲,是取不到这个值),所以上面的返回结果为空,无论步长是正还是负!
当然,实现这一需求的方法很多,只要理解了切片的索引原则:
1lyst = list(range(10))
2lyst[-2::-1] #[8, 7, 6, 5, 4, 3, 2, 1, 0],缺省下标
3lyst[:-1][::-1] #[8, 7, 6, 5, 4, 3, 2, 1, 0],先正序访问前n-1个值再逆序
切片赋值
前面提到,列表的单索引越界访问会报错,切片访问不报错但返回结果为空。这一逻辑也类似于列表的赋值操作: 对于单索引的赋值,要求索引必须在合格范围之内,否则报错;但对于切片的赋值则"无需"考虑索引是否合法,甚至无需考虑赋值长度是否匹配 :
1a = [1,2,3,4,5]
2b = [5,6]
3a[8] = 8 #IndexError: list assignment index out of range
4a[-8] = 8 #IndexError: list assignment index out of range
5a[8:] = b #执行后,a为[1, 2, 3, 4, 5, 5, 6]
6a[-8:-6] = b #执行后,a为[5, 6, 1, 2, 3, 4, 5],注意这里限定了赋值区间首末
7a[-8:-10] = b #执行后,a也是[5, 6, 1, 2, 3, 4, 5],即便限定的区间实际上为空
8a[-8:] = b #执行后,a为[5, 6],因为a的赋值区间未限定长度,而赋值起始索引在a起始之前,所以整体都给覆盖了
实际上,由于对超出列表长度的索引位置进行切片赋值会直接拼接,所以这个操作相当于列表的extend():
1a = [1,2,3,4,5]
2b = [5,6]
3a[len(a):] = b # a为[1, 2, 3, 4, 5, 5, 6]
4a.extend(b) # a也为[1, 2, 3, 4, 5, 5, 6]
既然提到了列表的extend()操作,那么下面的insert()操作不仅不会报错,而且实际上相当于执行了append()操作:
1a = [1,2,3,4,5]
2a.insert(len(a), 100) # a为[1, 2, 3, 4, 5, 100],注意这里insert下标参数为len(a),超出合格范围,但实际效果等价于a.append(100)
切片拷贝
由于参数引用的特殊性,python中的赋值操作或许曾令人抓狂其中而不得自拔,个人也不敢说完全理解其中的原理,所以这一部分权当是抛砖引玉。
正因为python中拷贝的特殊性,所以有个专门的库叫copy,里面有2个重要的方法分别是copy.copy()和copy.deepcopy(),顾名思义,后者叫做深拷贝,前者自然就叫做浅拷贝。当然,这里不打算介绍这个库和相应方法,而只是想就此引出列表中如何通过切片实现拷贝。
如果想要对一个列表进行拷贝,且后续操作互不干扰,那么简单的直接赋值是不能完成任务的,例如执行以下语句,a和b其实管理和引用的是同一块内存,所以操作是同步的,未实现真正的拷贝:
1a = [1,2,3,4,5]
2b = a #只是a的一个分身,未拷贝
3a[0] = 100
4b #[100, 2, 3, 4, 5]
如果想要实现a、b从此毫无瓜葛,那么简单的拷贝实现有两种:
1a = [1,2,3,4,5]
2b = a[:] #真正实现拷贝
3b = list(a) #也可实现拷贝
4a[0] = 100
5b #[1, 2, 3, 4, 5]
另外,再体会下这3个例子:
- 复制列表,改某个值其他不会受到影响
1a = [0]*10
2a[1] = 1 #[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
- 嵌套复制列表,牵一发动全身
1a = [[0]*10]*2
2a[1][0] = 2 #[[2, 0, 0, 0, 0, 0, 0, 0, 0, 0], [2, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
- 推导式+复制生成嵌套列表,改1个值其他不受影响
1a = [[0]*10 for _ in range(2)]
2a[1][0] = 2 #[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [2, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
不得不说,python里面的变量赋值与引用确实有些难以理解,这个只能靠不断积累和尝试,得细品!
-
参数
+关注
关注
11文章
1832浏览量
32201 -
元素
+关注
关注
0文章
47浏览量
8429 -
索引
+关注
关注
0文章
59浏览量
10468 -
python
+关注
关注
56文章
4795浏览量
84646
发布评论请先 登录
相关推荐
Python高级特性:迭代器切片的应用
Python 切片操作的高级用法
Python学习要点:自定义序列实现切片功能
Labview列表框的功能和操作
网络切片的分类 网络切片粒度如何选择
5G 网络切片之OTN切片和FlexE切片区别
Python序列的列表类型介绍
Python列表的基本概念、常用操作及实际应用
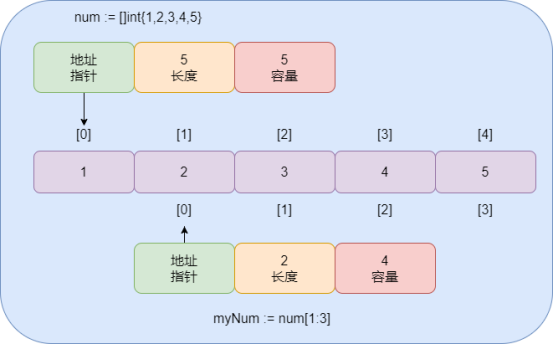
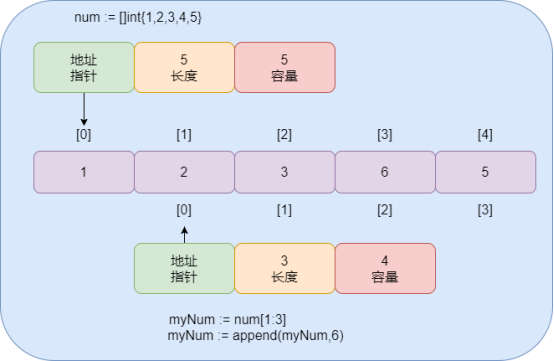
数组中如何增加切片的容量
如何对切片软件进行操作





 工商网监
工商网监
评论