 与GPU能效齐平,低功耗AI公司的转型
与GPU能效齐平,低功耗AI公司的转型
电子发烧友网报道(文/周凯扬)随着LLM在内的AI模型从规模和计算复杂性上成倍增加,与数年前相比,训练优秀AI模型的成本已经上升到了一个新的高度。从最近不断溢价、缺货抢货的GPU市场也可以看出,硬件成本已经成了AI发展的最大瓶颈。
为了训练高质量的AI模型,堆硬件数量几乎是避无可避的。为此,越来越多的AI芯片厂商看到了这个缺口,力求以自己的高性能硬件产品来填补竞品造成的缺口。甚至不少此前专注在低功耗/边缘AI计算的半导体公司,也计划冲击着更高的算力。
Leapmind
Leapmind是一家来自日本的边缘AI公司,其主要产品为超低功耗的AI推理加速器IP,Efficiera。Efficiera专门针对FPGA和ASIC/ASSP设备上的CNN推理计算进行了优化,仅需极小的面积和功耗就能实现优异的算力,所以很适合集成在边缘设备中。
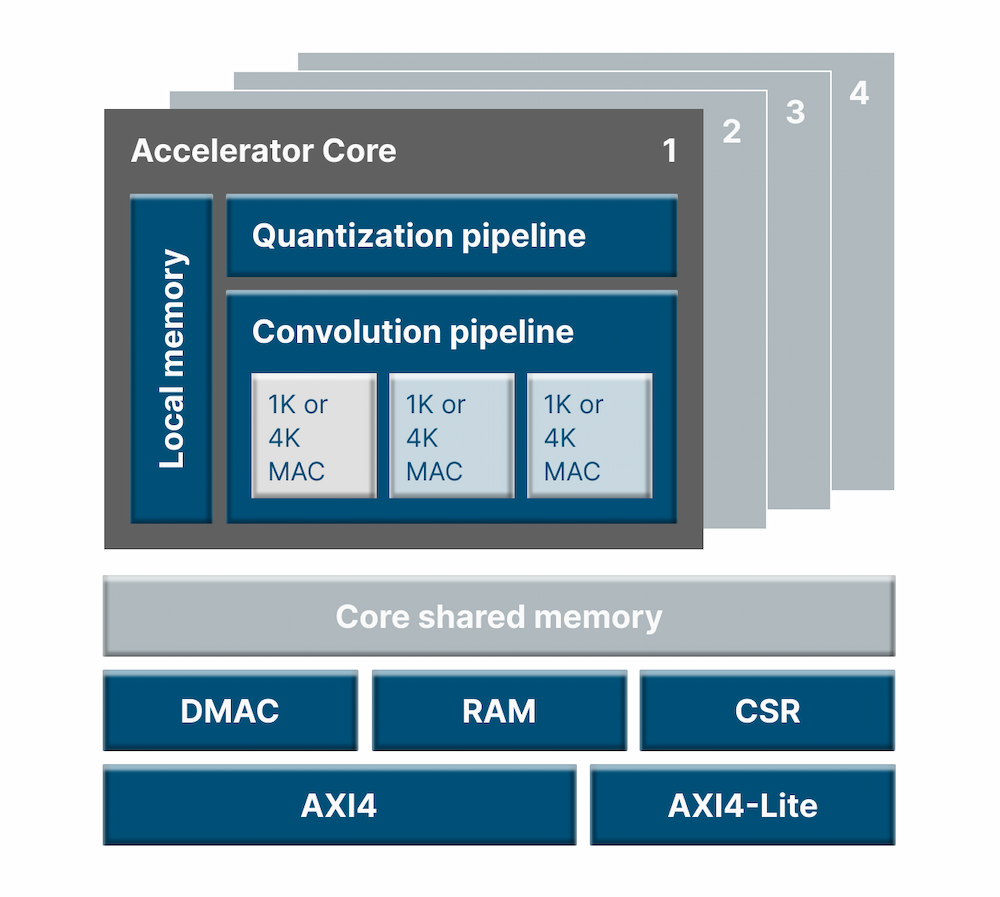
虽然主打超低功耗,但Efficiera的性能表现却一点都不差,根据Leapmind的综合测试,在7nm工艺和533MHz的主频下,Efficiera可以实现107.8TOPS/W的能效表现。加上Efficiera对CNN的优化,使其非常适合用于图像识别类的应用,比如AR/VR、智能相机等。据Leapmind透露,他们已经在台积电28nm和12nm上用此IP完成了数个SoC开发项目。
不过,Leapmind的野心并没有止步于此,他们同样看中了LLM大模型市场,计划开发一款新的AI芯片来解决性能瓶颈问题。Leapmind指出,新的AI芯片将专注于AI模型训练和推理,目标性能是2PFLOPS,且旨在实现与同等性能GPU 10倍差距的性价比。
这一AI芯片的特点包括,与Efficiera一样,强调低精度计算下的性能表现,比如FP8等,从而减少所需的晶体管数量,也减少DRAM的带宽压力。同时Leapmind也会开源相关的驱动程序和编译器,毕竟开发AI模型所需的软件栈绝对不是Leapmind这个体量的公司能解决的问题。
Mythic
数字AI芯片的竞争或许异常激烈,但interwetten与威廉的赔率体系 AI芯片却是Mythic的主战场。他们打造的模拟矩阵处理器M1076芯片,可以实现单芯片25TOPS的性能,标准功耗却只有3W到4W左右。
其模拟存内计算架构利用高密度的模拟内存来片上存储神经网络,而不是像数据芯片一样需要片外数据交换,这种架构为其提供了远低于数字芯片的功耗和延迟,为此更适合用于图像传感类的应用,比如物体识别等。

不过M1076的推出似乎并没有给这家公司带来足够的客户和利润,哪怕他们甚至打入了洛克希德马丁的供应链。从去年底开始,就有报道称Mythic已经耗尽资金,无力进行下一代模拟存内计算架构的研发。直到今年3月,现有投资者和Catapult Ventures等新投资者为其再度注入了1300万美元的资金,才将其从危机中挽救回来。
获得新一轮融资后的Mythic的目标仍是做边缘端的AI计算,但他们已经准备好对标桌面级GPU的算力表现了,为AR头显等算力需求持续拔高的机器视觉应用提供硬件支持。Mythic表示,新的M2000将进一步降低大小、功耗和成本,同时具备部署高性能机器视觉的能力,进一步扩大应用领域。
写在最后
其实对于多数AI初创芯片公司来说,虽然竞争对手数量庞大,但低功耗AI芯片仍是一个相对更容易入局的市场。反倒是到了与GPU拼性能的时候,他们的竞争对手往往变成了GPU大厂或云服务厂商,所以必须得具备独一无二的特性和足够高的性价比,才能吸引到客户以及投资。但这也恰好证明了多数AI芯片的扩展性,同样的架构在边缘AI芯片上实现后,也能广泛用于更大规模的高性能AI芯片上,但他们的差异化战略能否一并成功延续过来,仍需要接受局面完全不同的市场考验。
-
gpu
+关注
关注
28文章
4729浏览量
128899 -
AI
+关注
关注
87文章
30763浏览量
268906 -
低功耗
+关注
关注
10文章
2398浏览量
103677
发布评论请先 登录
相关推荐
大联大控股世平推出基于瑞芯微RV1106的低功耗AOV IPC方案
训练AI大模型需要什么样的gpu
新思科技Foundation IP:AI芯片低功耗设计必选项

低功耗SOC芯片的优势
智慧水务综合能效管理系统-实时了解水务配电系统运行状况
智慧水务综合能效管理系统-提高污水厂能效
天玑9400 GPU拿下能效霸主,实测直线满帧冰凉手感

栅极驱动芯片选型低功耗原因
安森美引领数据中心能效革命
利用AI和加速计算提升天气预报效率和能效
芯品#MAX78002 新型AI MCU,能够使神经网络以超低功耗运行
天玑9300旗舰芯:全大核CPU架构,性能与能效的提升
17pin航空插头需具备低功耗特性吗






 工商网监
工商网监
评论