 行人摔倒检测-在英特尔开发套件上基于OpenVINO™ C# API部署PP-Human
行人摔倒检测-在英特尔开发套件上基于OpenVINO™ C# API部署PP-Human

随着人口老龄化问题的加重,独居老人、空巢老人数量在不断上升,因此如何保障独居老人、空巢老人健康生活和人身安全至关重要。而对于独居老人、空巢老人,如果出现摔倒等情况而不会及时发现,将会对其健康安全造成重大影响。本项目主要研究为开发一套摔倒自动识别报警平台,使用视频监控其采集多路视频流数据,使用行人检测算法、关键点检测算法以及摔倒检测算法实现对行人摔倒自动识别,并根据检测情况,对相关人员发送警报,实现对老人的及时看护。该装置可以布置在养老院等场所,通过算法自动判别,可以大大降低人力成本以及保护老人的隐私。该项目应用场景不知可以用到空巢老人,还可以用到家庭中的孕妇儿童、幼儿园等场景,实现对儿童的摔倒检测。
项目中采用 OpenVINO 部署行人检测算法、关键点检测算法以及摔倒检测算法实现对行人摔倒自动识别算法,并在英特尔开发套件 AlxBoard 使用 OpenVINO C# API 结合应用场景部署多模型。
项目中所使用的代码全部在 GitHub 上开源,项目链接为:
https://github.com/guojin-yan/OpenVINO-CSharp-API/tree/csharp3.0/tutorial_examples/PP-Human_Fall_Detection
(复制链接到浏览器打开)
Part1
英特尔开发套件
OpenVINO 工具套件
1.1
英特尔发行版 OpenVINO工具套件基于oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO 可赋能开发者在现实世界中部署高性能应用程序和算法。

OpenVINO 2023.1 于 2023 年 9 月 18 日发布,该工具包带来了挖掘生成人工智能全部潜力的新功能。生成人工智能的覆盖范围得到了扩展,通过 PyTorch* 等框架增强了体验,您可以在其中自动导入和转换模型。大型语言模型(LLM)在运行时性能和内存优化方面得到了提升。聊天机器人、代码生成等的模型已启用。OpenVINO 更便携,性能更高,可以在任何需要的地方运行:在边缘、云中或本地。
英特尔开发套件 AlxBoard 介绍
1.2

产品定位
英特尔开发套件 AlxBoard 是英特尔开发套件官方序列中的一员,专为入门级人工智能应用和边缘智能设备而设计。英特尔开发套件 AlxBoard 能完美胜人工智能学习、开发、实训、应用等不同应用场景。该套件预装了英特尔OpenVINO 工具套件、模型仓库和演示案例,便于您轻松快捷地开始应用开发。
套件主要接口与 Jetson Nano 载板兼容,GPIO 与树莓派兼容,能够最大限度地复用成熟的生态资源。这使得套件能够作为边缘计算引擎,为人工智能产品验证和开发提供强大支持;同时,也可以作为域控核心,为机器人产品开发提供威廉希尔官方网站 支撑。
使用英特尔开发套件 AlxBoard,您将能够在短时间内构建出一个出色的人工智能应用应用程序。无论是用于科研、教育还是商业领域,英特尔开发套件 AlxBoard都能为您提供良好的支持。借助 OpenVINO工具套件,CPU、iGPU 都具备强劲的 AI 推理能力,支持在图像分类、目标检测、分割和语音处理等应用中并行运行多个神经网络。
产品参数
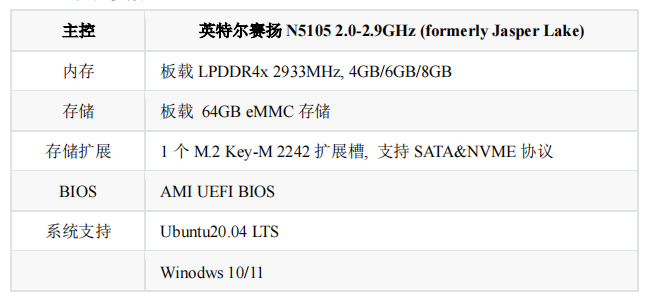
AI 推理单元
借助 OpenVINO 工具,能够实现 CPU+iGPU 异构计算推理,IGPU 算力约为 0.6TOPS

Part2
PaddleDetection
实时行人分析工具 PP-Human
飞桨 (PaddlePaddle) 是集深度学习核心框架、工具组件和服务平台为一体的威廉希尔官方网站 先进、功能完备的开源深度学习平台,已被中国企业广泛使用,深度契合企业应用需求,拥有活跃的开发者社区生态。提供丰富的官方支持模型集合,并推出全类型的高性能部署和集成方案供开发者使用。是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。
PaddleDetection 是一个基于 PaddlePaddle 的目标检测端到端开发套件,内置 30+ 模型算法及 250+ 预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量级产业级 SOTA 模型、冠军方案和学术前沿算法,并提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案。在提供丰富的模型组件和测试基准的同时,注重端到端的产业落地应用,通过打造产业级特色模型|工具、建设产业应用范例等手段,帮助开发者实现数据准备、模型选型、模型训练、模型部署的全流程打通,快速进行落地应用。

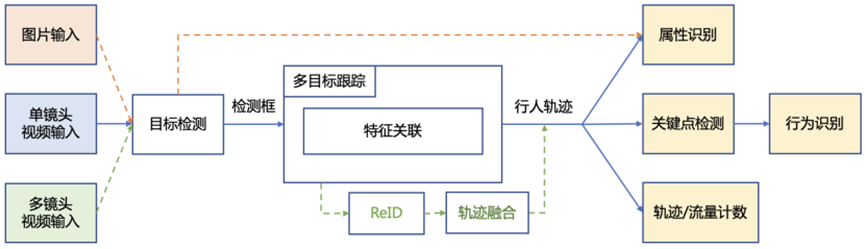
在实际应用中,打架、摔倒、异常闯入等异常行为的发生率高、后果严重,使得其成为了安防领域中重点监控的场景。飞桨目标检测套件 PaddleDetection 中开源的行人分析工具 PP-Human 提供了五大异常行为识别、26 种人体属性分析、人流计数、跨镜 ReID 四大产业级功能,其中异常行为识别功能覆盖了对摔倒、打架、打电话、抽烟、闯入等行为的检测。

如图所示,PP-Human 支持单张图片、图片文件夹单镜头视频和多镜头视频输入,经目标检测以及特征关联,实现属性识别、关键点检测、轨迹/流量计数以及行为识别等功能。此处基于 OpenVINO 模型部署套件,进行多种模型联合部署,实现实时行人行为识别,此处主要实现行人摔倒识别。
Part3
预测模型获取与转换
PP-YOLOE 行人跟踪
3.1
模型介绍
PP-YOLOE 是基于 PP-YOLOv2 的卓越的单阶段 Anchor-free 模型,超越了多种流行的 YOLO 模型,可以通过 width multiplier 和 depth multiplier 配置。PP-YOLOE 避免了使用诸如 Deformable Convolution 或者 Matrix NMS 之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。此处主要利用 PP-Yoloe 模型进行行人跟踪。
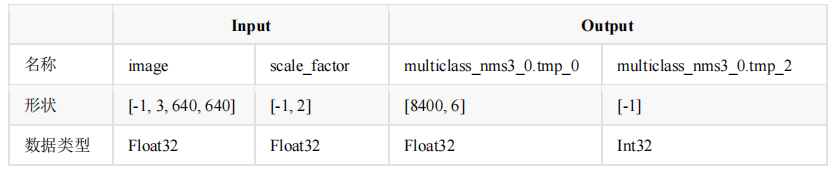
表2 PP-Yoloe Paddle 格式模型信息
表 2 为 Paddle 格式下 PP-YOLOE 模型的输入与输出相关信息,该模型包括两个输入与两个输出,可以实现行人识别,该模型可以直接在飞桨平台下载。但由于 PP-Yoloe 模型无法在 OpenVINO 平台直接部署,需要进行节点裁剪,即裁剪掉 scale_factor 输入节点,裁剪后模型结构如表 3 所示,具体如何裁剪后续讲解。
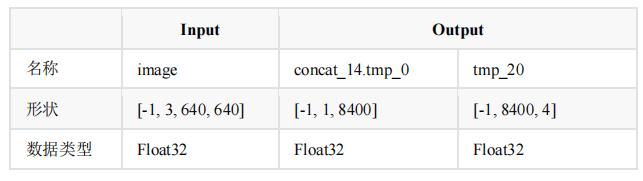
表3 PP-YOLOE Paddle 格式模型信息
模型下载与转换
(1) PaddlePaddle 模型下载与裁剪:
PP-Human 提供了训练好的行人跟踪模型,此处只需要下载,并将其解压到指定文件夹中:
weget https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip
此处模型裁剪主要是在 Paddle 模型格式下进行裁剪,裁剪方式参考的jiangjiajun [1]提供的模型裁剪方式,为了方便使用,当前项目提供了模型裁剪工具包,在 “./paddle_model_process/” 文件夹下,利用命令进行模型裁剪:
python prune_paddle_model.py --model_dir mot_ppyoloe_l_36e_pipeline --model_filename model.pdmodel --params_filename model.pdiparams --output_names tmp_16 concat_14.tmp_0 --save_dir export_model
如表 4 所示,提供了模型裁剪命令说明,大家可以根据自己设置进行模型裁剪,当前命令裁剪的模型目前已经进行测试,完全符合当前阶段的要求。
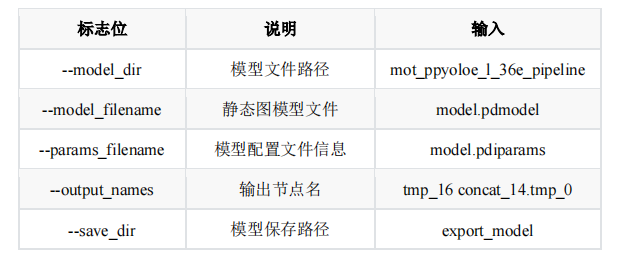
表4模型裁剪命令说明
(2)转换为 ONNX 格式:
该方式需要安装 paddle2onnx和onnxruntime 模块。导出方式比较简单,可以进行模型输入固定,此处使用的都为 bath_size=1,在命令行中输入以下指令进行转换:
paddle2onnx --model_dir mot_ppyoloe_l_36e_pipeline --model_filename model.pdmodel --params_filename model.pdiparams --input_shape_dict "{'image':[1,3,640,640]}" --opset_version 11 --save_file mot_ppyoloe_l_36e_pipeline.onnx
(3)转成 IR 格式
IR 格式为 OpenVINO 原生支持的模型格式,此处主要通过 OpenVINO 工具进行转换,直接在命令行输入以下指令即可:
mo --input_model mot_ppyoloe_l_36e_pipeline.onnx
PP-TinyPose 人体姿态识别
3.2
模型介绍
PP-TinyPose 是 PaddlePaddle 提供了关键点识别模型,PP-TinyPose 在单人和多人场景均达到性能 SOTA,同时对检测人数无上限,并且在微小目标场景有卓越效果,助力开发者高性能实现异常行为识别、智能健身、体感互动游戏、人机交互等任务。同时扩大数据集,减小输入尺寸,预处理与后处理加入 AID、UDP 和 DARK 等策略,保证模型的高性能。实现速度在 FP16 下 122FPS 的情况下,精度也可达到 51.8%AP,不仅比其他类似实现速度更快,精度更是提升了 130%。此处使用的是 dark_hrnet_w32_256x192 模型,该模型输入与输出如下表所示。

表5 dark_hrnet_w32_256x192 Paddle模型信息
表 5 为 Paddle 格式下 dark_hrnet_w32_256x192 模型的输入与输出相关信息,除此以外,飞桨还提供了输入大小为 128×96 的模型,这两类模型在部署时所有操作基本一致,主要差别就是输入与输出的形状不同。分析模型的输入和输出可以获取以下几个点:
第一模型的输入与 conv2d_585.tmp_1 节点输出形状,呈现倍数关系,具体是输入的长宽是输出的四倍,因此我们可以通过输入形状来推算输出的大小。
第二模型 argmax_0.tmp_00 节点输出为预测出的 17 个点的灰度图,因此后续在进行数据处理是,只需要寻找到最大值所在位置,就可以找到近似的位置。
模型下载与转换
(1)PaddlePaddle 模型下载方式:
命令行直接输入以下代码,或者浏览器输入后面的网址即可。
wget https://bj.bcebos.com/v1/paddledet/models/pipeline/dark_hrnet_w32_256x192.zip
下载好后将其解压到文件夹中,便可以获得 Paddle 格式的推理模型。
(2)转换为 ONNX 格式:
该方式需要安装 paddle2onnx 和 onnxruntime 模块。在命令行中输入以下指令进行转换,其中转换时需要指定 input_shape,否者推理时间会很长:
paddle2onnx --model_dir dark_hrnet_w32_256x192 --model_filename model.pdmodel --params_filename model.pdiparams --input_shape_dict "{'image':[1,3,256,192]}" --opset_version 11 --save_file dark_hrnet_w32_256x192.onnx
(3)转换为 IR 格式
利用 OpenVINO 模型优化器,可以实现将 ONNX 模型转为 IR 格式。在 OpenVINO 环境下,切换到模型优化器文件夹,直接使用下面指令便可以进行转换。
cd .openvino ools
mo --input_model paddle/model.pdmodel --input_shape [1,3,256,192]
经过上述指令模型转换后,可以在当前文件夹下找到转换后的三个文件。
由于 OpenVINO TM 支持 FP16 推理,此处为了对比推理时间,也已并将模型转为 FP16 格式:
mo --input_model paddle/model.pdmodel --data_type FP16 --input_shape [1,3,256,192]
ST-GCN 基于关键点的行为识别
3.3
模型介绍
摔倒行为识别模型使用了 ST-GCN,并基于 PaddleVideo 套件完成模型训练,此处可以直接下载飞桨提供的训练好的模型。
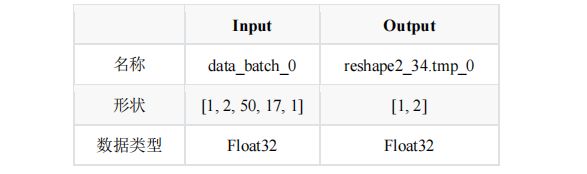
表6 ST-GCN Paddle模型信息
表6 为 Paddle 格式下 ST-GCN 模型的输入与输出相关信息,该模型输入为人体骨骼关键识别,由于摔倒是一个连续的过程,因此需要同时输入 50 帧的关键点结果,因此该模型不支持单张图片的预测,只支持视频的推理预测;其模型输出为是否摔倒的概率。
模型下载与转换
(1)PaddlePaddle 模型下载方式:
命令行直接输入以下代码,或者浏览器输入后面的网址即可。
wget https://bj.bcebos.com/v1/paddledet/models/pipeline/STGCN.zip
下载好后将其解压到文件夹中,便可以获得 Paddle 格式的推理模型。
(2)转换为 ONNX 格式:
该方式需要安装 paddle2onnx和onnxruntime 模块。在命令行中输入以下指令进行转换:
paddle2onnx --model_dir STGCN --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file STGCN.onnx
(3)转换为IR格式
利用 OpenVINO 模型优化器,可以实现将 ONNX 模型转为 IR 格式。在 OpenVINO 环境下,切换到模型优化器文件夹,直接使用下面指令便可以进行转换。
cd .openvino ools
mo --input_model paddle/model.pdmode
经过上述指令模型转换后,可以在当前文件夹下找到转换后的三个文件。
由于 OpenVINO 支持 FP16 推理,此处为了对比推理时间,也已并将模型转为 FP16 格式:
mo --input_model paddle/model.pdmodel --data_type FP16
Part4
配置 PP-Human_Fall_Detection 项目
项目中所使用的代码已经放在 GitHub 仓库 PP-Human_Fall_Detection[2],大家可以根据情况自行下载和使用,下面我将会从头开始一步步构建 PP-Human_Fall_Detection 项目。
环境配置
4.1
在该项目中主要需要配置 .NET 编译运行环境、OpenVINO Runtime、OpenCvSharp 环境,其配置流程可以参考上一篇文章:【2023 Intel 有奖征文】英特尔开发套件 AlxBoard 使用 OpenVINO C# API 部署 Yolov8 模型 [3]。
创建 PP-Human_Fall_Detection项目
4.2
在该项目中,我们需要使用 OpenCvSharp,该依赖目前在 Ubutun 平台最高可以支持 .NET Core 3.1,因此我们此处创建一个 .NET Core 3.1 的项目,使用 Terminal 输入以下指令创建并打开项目文件:
dotnet new console --framework "netcoreapp3.1" -o PP-Human_Fall_Detection
cd PP-Human_Fall_Detection
添加项目源码
4.3
前文中我们已经提供了项目源码链接,大家可以直接再在源码使用,此处由于篇幅限制,因此此处不对源码做太多的讲解,只演示如何使用项目源码配置当前项目。将项目源码中的 PP-Human 文件夹和 HumanFallDown.cs、Program.cs 文件复制到当前项目中,最后项目的路径关系如下所示:
PP-Human_Fall_Detection
├──── PP-Human
| ├──── Common.cs
| ├──── PP-TinyPose.cs
| ├──── PP-YOLOE.cs
| └──── STGCN.cs
├──── HumanFallDown.cs
├──── PP-Human_Fall_Detection.csproj
└──── Program.cs
添加OpenVINO C# API
4.4
OpenVINO C# API 目前只支持克隆源码的方式实现,首先使用 Git 克隆以下源码,只需要在 Terminal 输入以下命令:
git clone https://github.com/guojin-yan/OpenVINO-CSharp-API.git
然后将该项目文件夹下的除了 src 文件夹之外的文件都删除掉,然后项目的文件路径入下所示:
PP-Human_Fall_Detection
├──── OpenVINO-CSharp-API
| ├──── src
| └──── CSharpAPI
├──── PP-Human
| ├──── Common.cs
| ├──── PP-TinyPose.cs
| ├──── PP-YOLOE.cs
| └──── STGCN.cs
├──── HumanFallDown.cs
├──── PP-Human_Fall_Detection.csproj
└──── Program.cs
最后在当前项目中添加项目引用,只需要在 Terminal 输入以下命令:
dotnet add reference ./OpenVINO-CSharp-API/src/CSharpAPI/CSharpAPI.csproj

添加OpenCvSharp
4.5
安装 NuGet Package
OpenCvSharp 可以通过 NuGet Package 安装,只需要在 Termina l输入以下命令:
dotnet add package OpenCvSharp4_.runtime.ubuntu.20.04-x64
dotnet add package OpenCvSharp4
添加环境变量
将以下路径添加到环境变量中:
export LD_LIBRARY_PATH=/home/ygj/Program/ OpenVINO-CSharp-API/tutorial_examples/AlxBoard_deploy_yolov8/bin/Debug/netcoreapp3.1/runtimes/ubuntu.20.04-x64/native
/bin/Debug/netcoreapp3.1/runtimes/ubuntu.20.04-x64/native 是项目编译后生成的路径,该路径下存放了 libOpenCvSharpExtern.so 文件,该文件主要是封装的 OpenCV 中的各种接口。也可以将该文件拷贝到项目运行路径下。
Part5
测试PP-Human_Fall_Detection项目
创建视频读取器
5.1
当前项目测试内容为视频,此处主要通过 OpenCV的VideoCapture 类进行读取,实现逐帧读取测试图片。
// 视频路径
string test_video = @"E:Git_space基于Csharp和OpenVINO部署PP-Humandemo摔倒.mp4";
// string test_video = @"E:Git_space基于Csharp和OpenVINO部署PP-Humandemo摔倒2.mp4";
// 视频读取器
VideoCapture video_capture = new VideoCapture(test_video);
// 视频帧率
double fps = video_capture.Fps;
// 视频帧数
int frame_count = video_capture.FrameCount;
Console.WriteLine("video fps: {0}, frame_count: {1}", Math.Round(fps), frame_count);
行人识别
5.2
利用创建好的视频读取器逐帧读取视频图片,将其带入到 yoloe_predictor 预测器中进行预测,并将预测结果绘制到图片上,期预测结果存放到 ResBboxs 类中,方便进行数据传输。
// 读取视频帧
if (!video_capture.Read(frame))
{
Console.WriteLine("视频读取完毕!!{0}", frame_id);
break;
}
// 复制可视化图片
visualize_frame = frame.Clone();
// 行人识别
ResBboxs person_result = yoloe_predictor.predict(frame);
// 判断是否识别到人
if (person_result.bboxs.Count < 1)
{
continue;
}
// 绘制行人区域
yoloe_predictor.draw_boxes(person_result, ref visualize_frame);
通过上述代码,可以实现视频所有帧图片预测,将预测结果保存到本地,如图所示,经过预测器预测,可以很好的捕获到运动的行人。

关键点识别
5.3
上一步通过行人跟踪,捕捉到了行人,由于行人是在不断运动的,因此在进行关键点预测时,需要先进行裁剪,将行人区域按照指定要求裁剪下来,并根据裁剪结果对行人关键点进行预测,此处使用的是 bath_size=1 的预测,适合单人预测,如果出现多人时,可以采用同时预测。
// 裁剪行人区域
List point_rects;
List person_rois = tinyPose_predictor.get_point_roi(frame, person_result.bboxs, out point_rects);
for (int p = 0; p < person_rois.Count; p++)
{
// 关键点识别
float[,] person_point = tinyPose_predictor.predict(person_rois[p]);
KeyPoints key_point = new KeyPoints(frame_id, person_point, point_rects[p]);
//Console.WriteLine(key_point.bbox);
flag_stgcn = mot_point.add_point(key_point);
tinyPose_predictor.draw_poses(key_point, ref visualize_frame);
}
经过模型预测,第一会将预测结果存到结果容器“mot_point”中,用于后面的摔倒识别;另一点将模型预测结果绘制到图像中,如图所示。

摔倒识别
5.4
摔倒识别需要同时输入 50 帧人体关键点识别结果,所以在开始阶段需要积累 50 帧的关键点识别结果,此处采用自定义的结果保存容器 “MotPoint” 实现,该容器可以实现保存关键点结果,并将关键点识别结果与上一帧结果进行匹配,当容器已满会返回推理标志,当满足识别条件是,就会进行依次模型预测;同时会清理前 20 帧数据,继续填充识别结果等待下一次满足条件。
if (flag_stgcn)
{
List> predict_points = mot_point.get_points();
for (int p = 0; p < predict_points.Count; p++)
{
Console.WriteLine(predict_points[p].Count);
fall_down_result = stgcn_predictor.predict(predict_points[p]);
}
}
stgcn_predictor.draw_result(ref visualize_frame, fall_down_result, person_result.bboxs[0]);
摔倒识别结果为是否摔倒以及对应的权重,此处主要是在满足条件的情况下,进行一次行为识别,并将识别结果绘制到图像上。
模型联合部署实现行人摔倒识别
5.5
通过行人跟踪、关键点识别以及行为识别三个模型联合预测,可以实现行人的行为识别,其识别效果如图 14 所示。在该图中分别包含了三个模型的识别结果:行人位置识别与跟踪是通过 PP-YOLOE 模型实现的,该模型为下一步关键点识别提供了图像范围,保证了关键点识别的结果;人体骨骼关键点识别时通过 dark_hrnet 模型实现,为后续行为识别提供了输入;最终的行为识别通过 ST-GCN 模型实现,其识别结果会知道了行人预测框下部,可以看到预测结果与行人是否摔倒一致。

Part6
总结
在该项目中,基于 C# 和 OpenVINO 联合部署 PP-YOLOE 行人检测模型、dark_hrnet 人体关键点识别模型以及 ST-GCN 行为识别模型,实现行人摔倒检测。
在该项目中,主要存在的难点一是 PP-YOLOE 模型无法直接使用 OpenVINO 部署,需要进行裁剪,裁剪掉无法使用的节点,并根据裁剪的节点,处理模型的输出数据;难点二是处理好行人预测与关键点模型识别内容的关系,在进行多人识别时,要结合行人识别模型进行对应的人体关键点识别,并且要当前帧识别结果要对应上一帧行人识别结果才可以保证识别的连续性。
-
英特尔
+关注
关注
61文章
9953浏览量
171702 -
视频监控
+关注
关注
17文章
1710浏览量
64958 -
语言模型
+关注
关注
0文章
521浏览量
10268
原文标题:行人摔倒检测 - 在英特尔开发套件上基于 OpenVINO™ C# API 部署 PP-Human | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于C#和OpenVINO™在英特尔独立显卡上部署PP-TinyPose模型
介绍英特尔®分布式OpenVINO™工具包
英特尔BOOT Loader开发套件-高级嵌入式开发基础

产业级预训练模型的实时行人分析工具PP-Human
C#调用OpenVINO工具套件部署Al模型项目开发项目
基于OpenVINO™工具包部署飞桨PP-Human的全流程
基于OpenVINO在英特尔开发套件上实现眼部追踪
基于英特尔开发套件的AI字幕生成器设计
OpenVINO™ C# API详解与演示

基于OpenVINO C# API部署RT-DETR模型
基于英特尔哪吒开发者套件平台来快速部署OpenVINO Java实战
【转载】英特尔开发套件“哪吒”快速部署YoloV8 on Java | 开发者实战

使用英特尔哪吒开发套件部署YOLOv5完成透明物体目标检测






 工商网监
工商网监
评论