 HK32MCU应用笔记(五)| 关于应用HK32F030延时效率问题
HK32MCU应用笔记(五)| 关于应用HK32F030延时效率问题
用户在应用程序中可能存在死等延时的处理函数(用for或者do…while)。 对比ST同样的函数HK的芯片出现延时比ST慢,是因为HK的芯片在cpu和flash之间有一个4个word大小(编号为00,04,08,0c)的指令缓存,工程编译之后,如果函数被存放到flash的地址的尾地址没有从0开始的话,(比如函数的入口地址为0x08000004,会被放到编号04的字中,而不是编号0中),就会出现执行效率低的问题。
如何避免这种问题呢?
我们的HK030/031/04A的应用笔记中有指导说明,今天在这里用一个例子详细说明修改方法:
比如用户使用uint32_tGItimer=1000000;voidDelayTimer(void){uint32_t i;for(i=0;i
修改如下:voidDelayTimer(void){ uint32_t i; FLASH->ACR = ~(0x00000010); for(i=0;iACR |= 0x00000010; }这样修改后,就可以使调用函数延时指令执行效率与ST一样。因此用户在使用030/031/04A做开发时如果程序中存在这样死等待的延时函数,如果在时效上想与ST接近,建议采用这种方式修改。
来源:航顺芯片
审核编辑:汤梓红
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
mcu
+关注
关注
146文章
17135浏览量
351017 -
航顺芯片
+关注
关注
1文章
106浏览量
22794
发布评论请先 登录
相关推荐
HK32MCU应用笔记(五)| 关于应用HK32F030延时效率问题 应用笔记
如何避免这种问题呢?HK030/031/04A的应用笔记中有指导说明,今天在这里用一个例子详细说明修改方法。
发表于 02-08 15:18
•7次下载

HK32MCU应用笔记(二十)| HK32F103xC/D/E USB枚举情况分析(二)
HK32MCU应用笔记(二十)| HK32F103xC/D/E USB枚举情况分析(二)
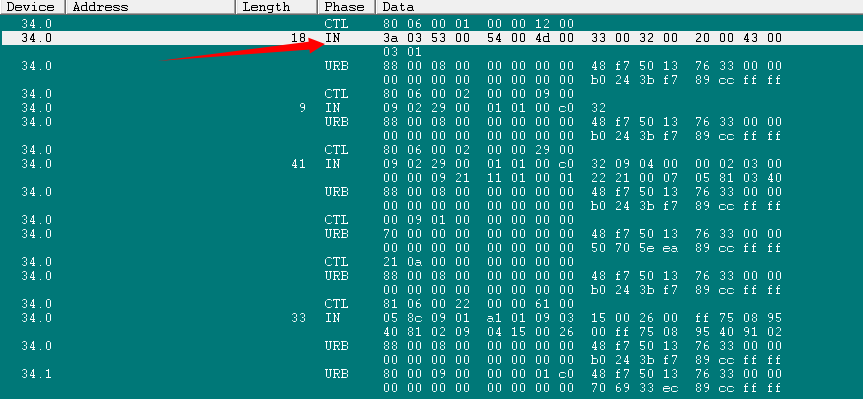
HK32MCU应用笔记(十九)| HK32F103xC/D/E USB枚举情况分析
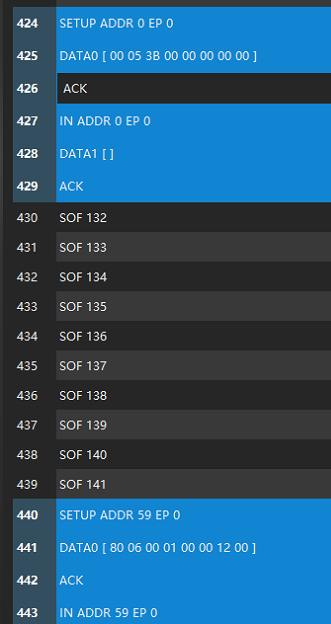
HK32MCU应用笔记(十九)| HK32F103xC/D/E USB枚举情况分析
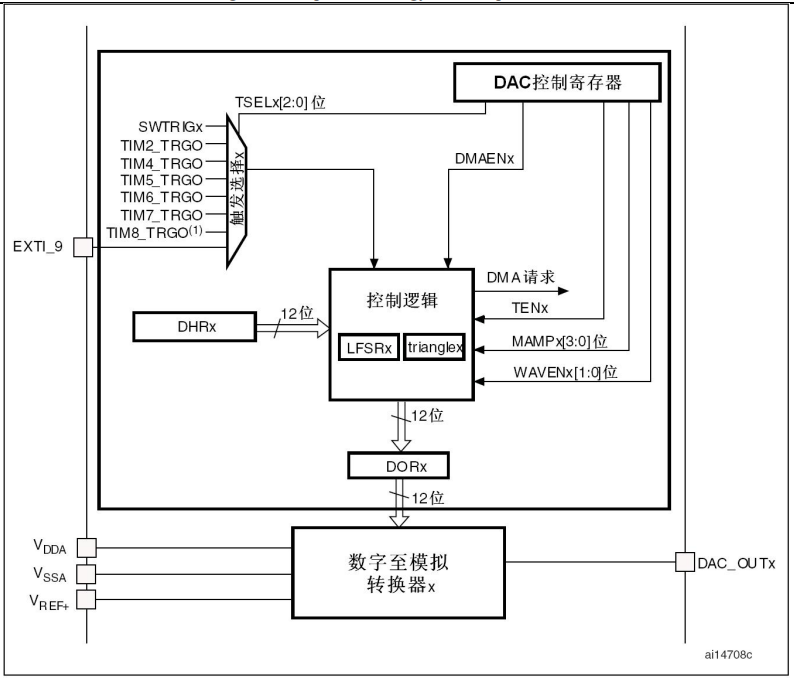
HK32MCU应用笔记(十八)| HK32F103xC/D/E-DAC的应用及注意事项
HK32MCU应用笔记(十八)| HK32F103xC/D/E-DAC的应用及注意事项
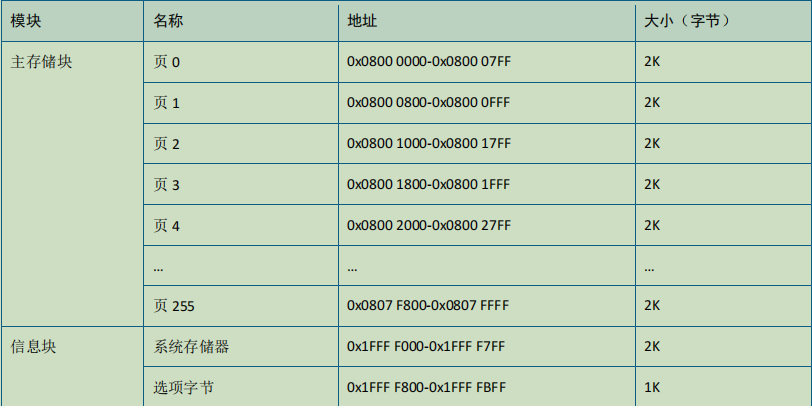
HK32MCU应用笔记(十七)| HK32F103xC/D/E-flash擦写应用及注意事项
HK32MCU应用笔记(十七)| HK32F103xC/D/E-flash擦写应用及注意事项
HK32MCU应用笔记(十六)| HK32F103xC/D/E-Timer的应用及注意事项
HK32MCU应用笔记(十六)| HK32F103xC/D/E-Timer的应用及注意事项
HK32MCU应用笔记(十四)| HK32F103x/C/D/E-TIM1的应用及注意事项
HK32MCU应用笔记(十四)| HK32F103x/C/D/E-TIM1的应用及注意事项
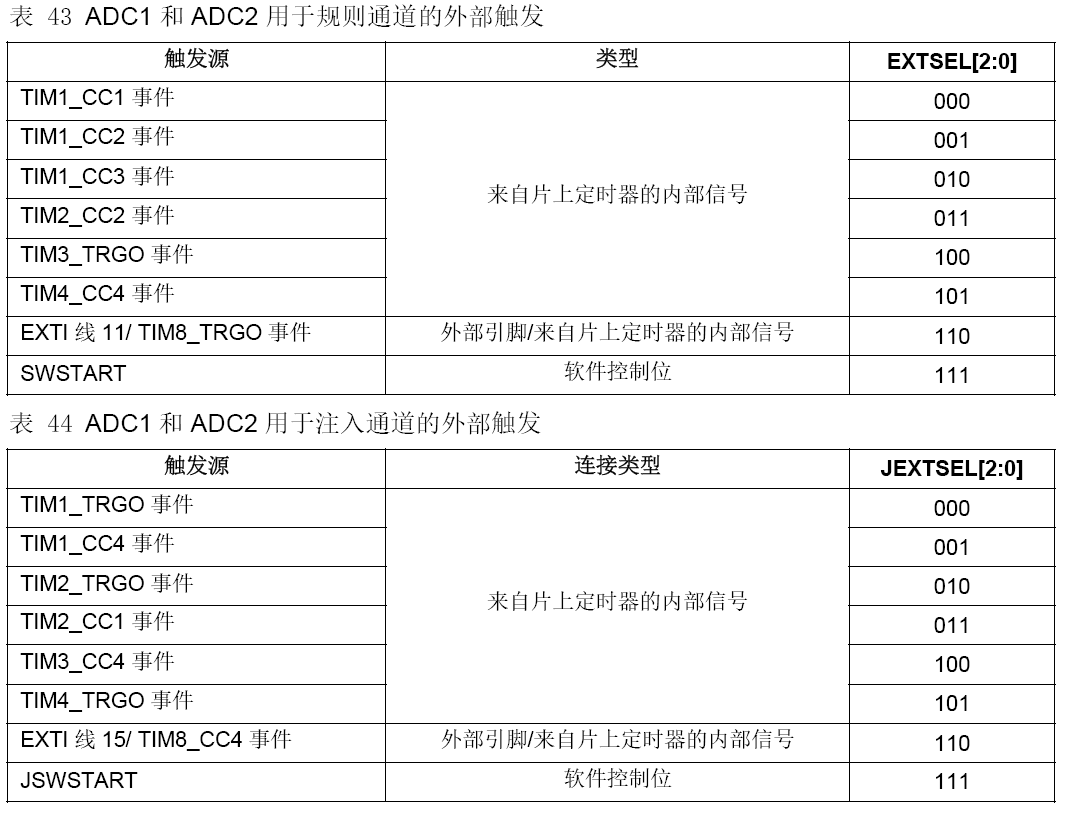
HK32MCU应用笔记(十三)| HK32F103xC/D/E-ADC的应用及注意事项
HK32MCU应用笔记(十三)| HK32F103xC/D/E-ADC的应用及注意事项
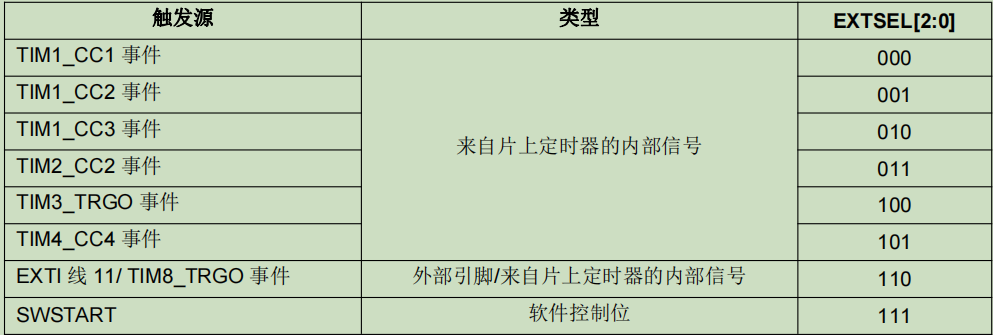
HK32MCU应用笔记(十二)| HK32F103xC/D/E的GPIO的应用及注意事项
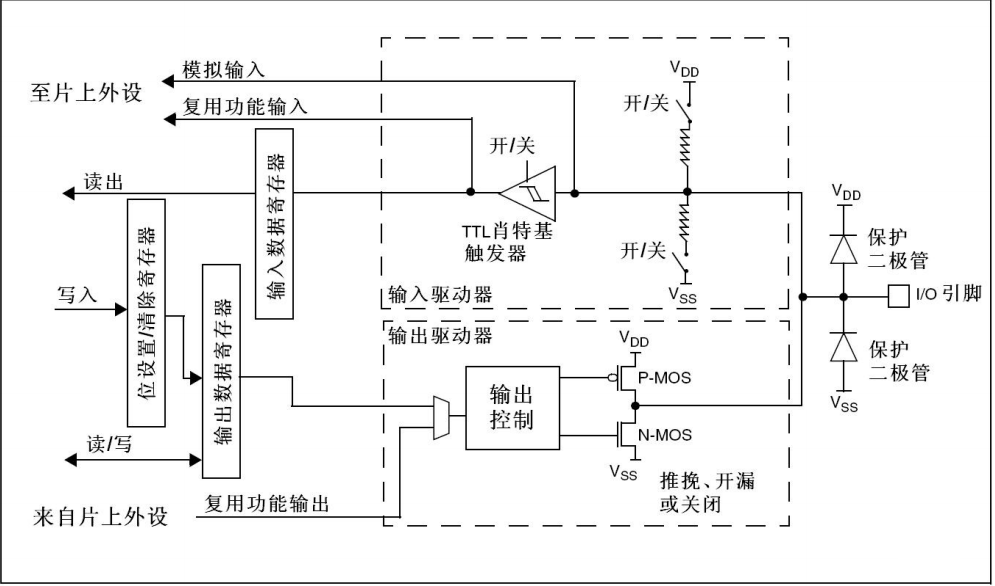
HK32MCU应用笔记(十二)| HK32F103xC/D/E的GPIO的应用及注意事项
HK32MCU应用笔记(十一)| HK32F103xC/D/E的flash读保护应用及注意事项
HK32MCU应用笔记(十一)| HK32F103xC/D/E的flash读保护应用及注意事项

HK32MCU应用笔记(九)| HK32F103x8xB系列CAN的应用解决方案
HK32MCU应用笔记(九)| HK32F103x8xB系列CAN的应用解决方案
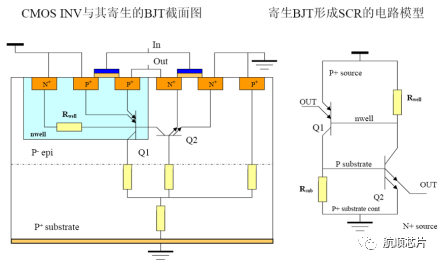
HK32MCU应用笔记(七)| 航顺HK32MCU闩锁效应问题研究及预防措施
HK32MCU应用笔记(七)| 航顺HK32MCU闩锁效应问题研究及预防措施
HK32MCU应用笔记(四)| 关于老版本HK32F103串口USART偶尔出现数据错误
HK32MCU应用笔记(四)| 关于老版本HK32F103串口USART偶尔出现数据错误





 工商网监
工商网监
评论