 极致优化SSD并行读调度
极致优化SSD并行读调度
作者 | GL
导读
提升广告检索漏斗一致性,要求在粗排阶段引入更丰富的信号,这些信号的需求量已经远远超出了内存的承受能力。为此,我们考虑引入基于NVMe SSD的分层存储。本文详细探讨了一种长尾可控的方法论,以及在这个方法论的约束下,如何极致优化读调度。这些方法对于实施类似LargerThanMem的威廉希尔官方网站 也将提供有价值的启发。
01业务背景
业务需要更大存储空间,需求量预期远超过内存可承受。举例来说,客户落地页是客户营销内容的核心阵地,增强对客户落地页内容特征理解,才能实现用户兴趣和客户投放的精准匹配,提升用户体验和转化率,凤巢正排服务引入 URL 明文是关键一步。凤巢正排服务检索查询完全基于内存,内存存储着亿级别广告物料和检索线程需要的上下文。凤巢正排服务实例上万,单实例内存 Quota 已高达云原生红线,常态利用率 85+%,URL 明文引入后,即使业务上极致去重压缩,单实例还需增加数十GB,预期随广告库会继续增长,内存已远远不够。
广告检索过程引入基于 NVMe SSD 的分级存储,长尾控制尤其关键。检索效果对处理性能极为敏感,若查询超时导致检索 KPI 失效,将可能造成广告丢失,从而带来收入损失。以凤巢正排服务来看,单 PV 召回广告创意量在万级别,正排服务通过多分库分包实现并行,即使在单个包内,广告创意数量也可达数百。从检索系统的算力分配来看,针对百条 URL 明文的查询,其长尾性能空间仅为 5ms。
02威廉希尔官方网站 背景
SSD 作为内存存储扩展,缺点是读写干扰不可控。SSD[1] 的操作要求必须按页进行读写,否则会导致读写放大效应。此外,SSD 硬件特性还要求“擦除后写”,因此写数据会额外引起数据搬运损耗和擦除损耗,而擦除操作的耗时往往是读操作时间的 1000 倍!更令人担忧的是,对于那些需要极低随机读取的业务而言,SSD 就像一个无法调节的『黑匣子』,应用无法直接干预由读写干扰带来的查询长尾问题。
业界常用访盘优化手段,未能控制读长尾。业界常用软件写盘优化,确实可以显著提升吞吐,但对长尾控制力度有限,主要手段是:① 把随机写转化为对齐写、顺序写,② 整文件大块删除,③ 流量低峰期触发盘 GC。比如论文 FAST' 15《F2FS: A New File System for Flash Storage》[2] 介绍了一种面向 SSD 的全新文件系统F2FS,基于 Log-Structured File System 的威廉希尔官方网站 ,将所有的写入操作转换为日志记录,从而减少写放大效应,并提高了写入吞吐。下图中展示 F2FS v.s. ext4 在随机写场景(varmail、oltp)获得吞吐优势:
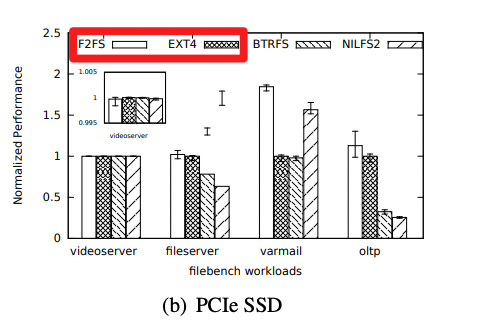
△F2FS: A New File System for Flash Storage》 图4
业界涌现出新硬件控制读长尾。硬件标准如 OpenChannel[3,4],在块存储之外还额外提供了接口,使得业务可以更加精细地控制数据位置和命令调度,从而结合业务特点,在一定程度上实现了读写隔离,进而控制了长尾效应。曾经,Linux LightNVM[5] 试图标准化对 OpenChannel 的操作,但由于难以定义合理且简单的块操作接口,最终被放弃,这也催生了 Zoned Namespace SSD(ZNS)[6] 新的硬件标准。ZNS 硬件并不是传统的块存储,而是一种称为 Zone 存储的概念。整个固态硬盘被划分为多个等长的区域,称为 Zone。Zone 内的数据必须以顺序的页对齐方式进行写入,并且在进行 Zone 内数据复写之前,需要对整个 Zone 进行 reset 操作。ZNS 硬件层面,也按 Zone 接口做了擦除单元隔离。
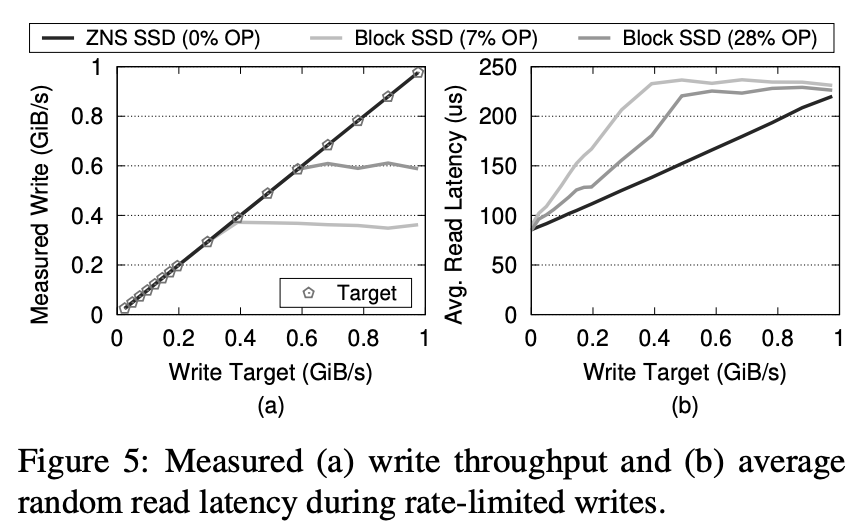
△《ZNS: Avoiding the Block Interface Tax for Flash-based SSDs》图5
新硬件的引入和打磨需要较长的周期,短期的业务需求亟需满足。从长远来看,ZNS 固态硬盘是未来的发展趋势,我们也已经和基础架构团队共同探索。然而,在当前情况下,我们需要充分利用现有的检索池中的 Nvme 存储。为此,我们发起了 Ecomm Uniform SSD Layer - SsdEngine 项目,其目标是在底层集成各种硬件(包括 NVMe、ZNS),在上层根据典型的商业业务场景封装接口,让商业业务最大限度用上硬件发展和软硬件结合的威廉希尔官方网站 红利。
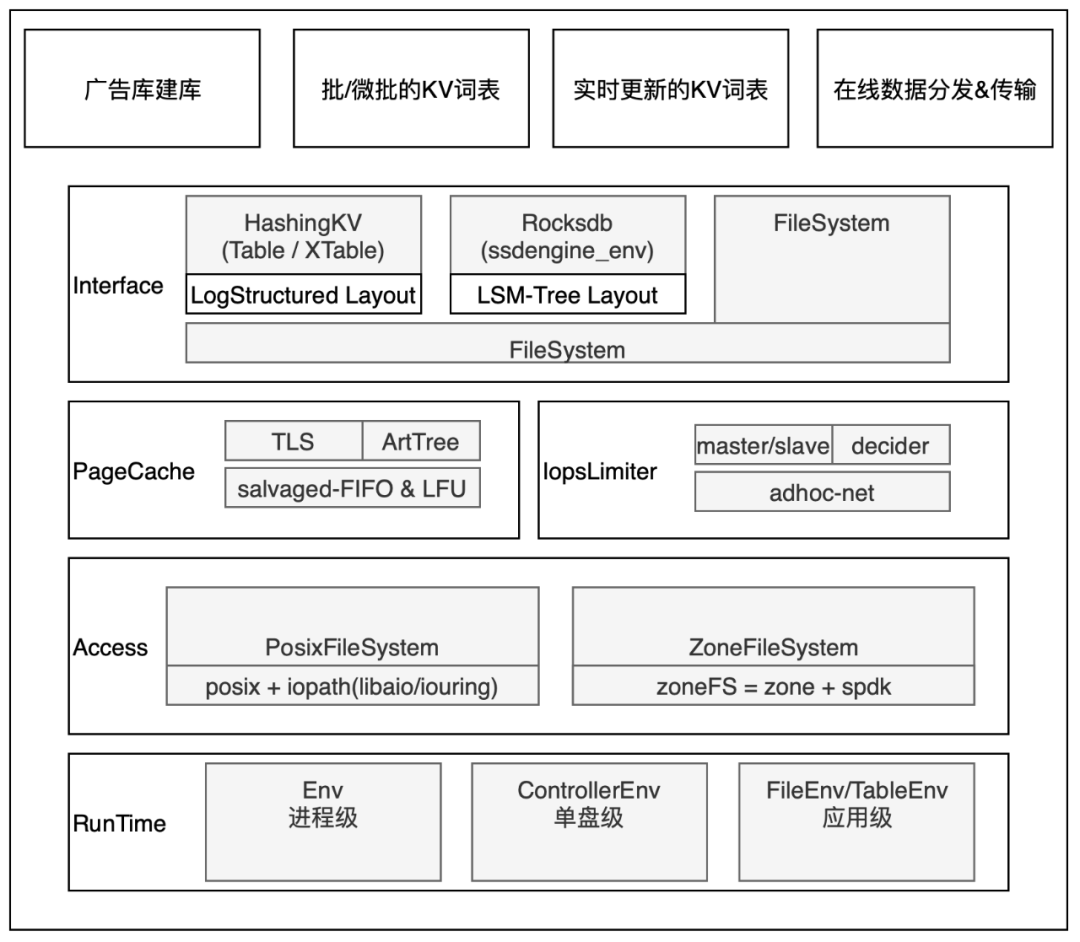
△SsdEngine整体架构
通用场景 NVMe 长尾完全不可控,检索特化场景长尾可控。Nvme SSD 在实际应用中确实受到多种读写干扰因素的影响,其主要因素包括读写单元大小(ValueSize)、读写频次(IOPS)、数据生命周期一致性(Lifetime)等等。这些影响因素的作用是复杂的,且无法简单地通过公式化加以描述 [7]。然而,检索业务也有应用特殊性:检索业务属于重读轻写的场景,在满足足够吞吐用于回溯止损的前提下,我们甚至愿意在一定程度上牺牲一部分写吞吐,以换取更为稳定的读性能。基于这一背景,结合检索业务的独特特点,我们采用了硬件友好的磁盘访问模式(Disk Access Pattern),并设计了一套基准测试(Benchmark)方案,以此来进行系统性能评测。在评测中,我们针对占检索池大头的数种 NVMe 盘型号进行了测试,最终得出以下结论:通过控制读单元大小(ValueSize = 4K)以及调整读写吞吐比(IOPS Pattern),能够有效操控读写影响,从而实现对读操作长尾的控制。下图是对于Intel P3600 盘,在读 999per 5ms 的情况下,物理盘最佳“读写配比”。
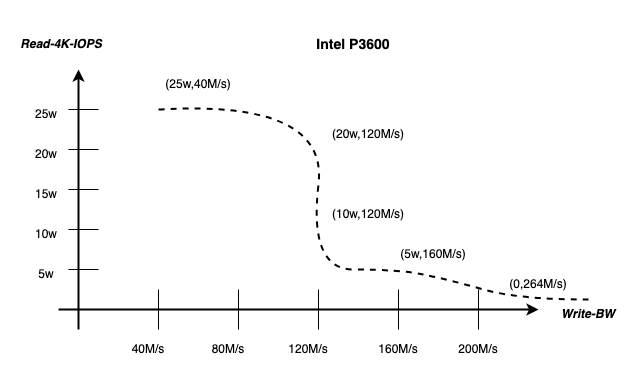
△Intel P3600 读长尾可控的读写配比
混布环境下控制单盘 IOPS 是涉及多层次的复杂问题,本文只分享单实例实践。在单个实例中,要严格控制读写吞吐,就要从默认的基于 PageCache 的读写模式,转换为使用 Direct I/O(以下简称 DIO)模式,以便获取硬件级别的读写控制权。操作系统将数据存储在 PageCache 中,以供后续的 I/O 操作直接从内存中读取或写入,从而显著提高读写性能。在切换到 DIO 读写模式时,为了弥补缺少 PageCache 的性能影响,我们引入了 Libaio/IoUring 异步访问机制,充分发挥 SSD 的并行处理能力。下图是随机读 randread 和顺序读 read 混合的评测,如果纯顺序读,那么 PageCache 吞吐可达 1+G,且具备性能优势,为此我们也进一步做了页缓存的工作,此处先按下不表。
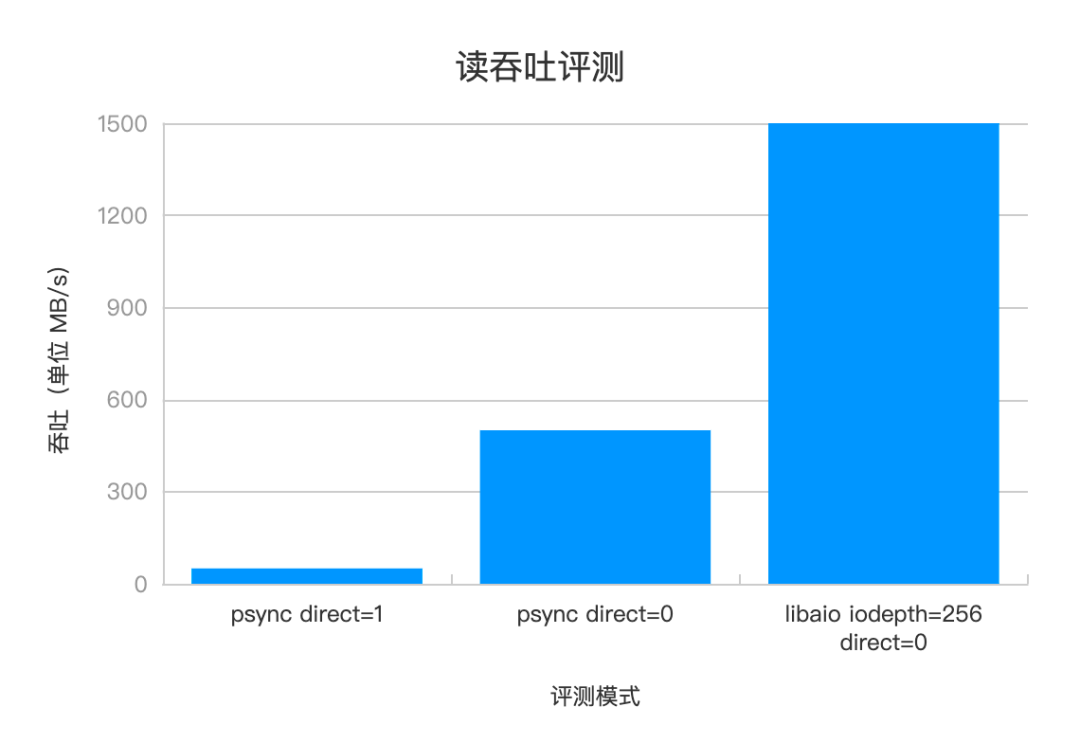
△单机吞吐评测数据
03解决方案
3.1集成 Libaio
Linux Libaio 的操作接口和工作原理十分直观。常规操作接口分三步:
(1)通过 io_prepare 准备异步请求。
(2)io_submit 发送一批请求。
(3) io_getevents 采用 polling 的方式等待所有请求结束。
工作原理层面,io_submit 将所有请求都提交给了 IO 调度器,IO 调度器做完合并、排序类调度优化后,通过对应的设备驱动程序提交给具体的设备。经过一段时间,读请求被设备处理完成,CPU 将收到中断信号,设备驱动程序注册的处理函数将在中断上下文中被调用,调用 end_request 函数来结束这次请求,将 IO 请求的处理结果填回对应的 io_event 中,唤醒 io_getevents。
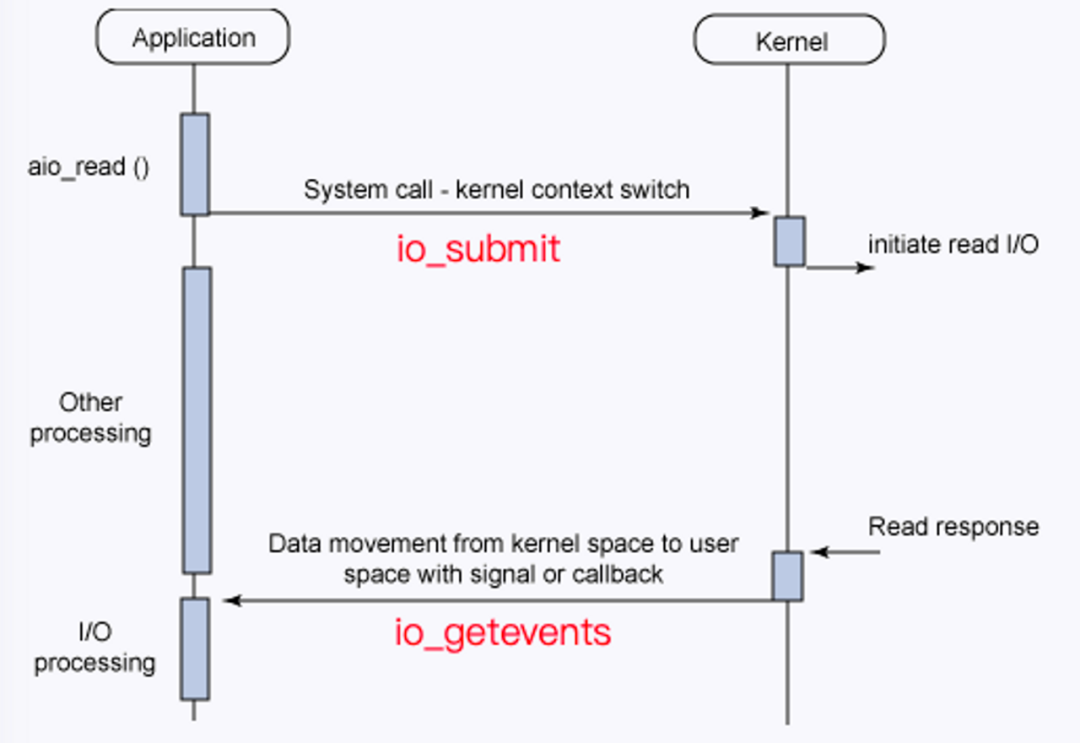
△Libaio 接口示例
SsdEngine 集成 Libaio 的方式也非常直观。
(1)初始化 IO 任务队列大小为 iodepth。
(2)批量设置 nr 个 IO 任务的读参数,包含文件的句柄、大小、偏移量。
(3)一次性提交 nr 个 IO 任务的读请求。
(4)针对提交的 IO 任务,我们采用分批次等待的方法,设置参数 min_wait_nr 和 batch_timeout,其中 min_wait_nr 的值为 min(nr >> 2, nr - completed) ,作用是减少 io_getevents 系统调用损耗,并实现 IO 任务与后续 CPU 任务的并行化。batch_timeout 会配合整体 timeout,控制整体超长耗时。
// 初始化 Libaio 队列
io_queue_init(iodepth, context)
// 设置 nr 个 IO 任务的读参数
for (int i = 0; i < nr; i++) {
io_prep_pread(iocb_list[i], fd, page[i], page_size[i], page_offset[i]);
}
// 提交 nr 个 IO 任务
io_submit(context, nr, iocb_list /*start*/);
// 分批次等待,设置最小等待个数 min_wait_nr,最大等待个数 max_nr - completed,以及超时 ts
while (completed < nr) {
int res = io_getevents(context, min_wait_nr, max_nr - completed/*nr*/, events, &ts);
// IO 任务正确性校验
for (int = 0; i < res; i++) {
assert(events[i] == page_size[index]);
}
completed += res;
if (total_time_cost > pv_timeout) {
io_cancel();
}
}
3.2 初步集成 IoUring
IoUring 执行过程和 Libaio 大同小异,但更高性能。IoUring 通过实现两个 Ring 结构,将其映射到用户空间并与内核共享,以降低元数据复制和系统调用开销。Submission Ring 包含应用程序发出的 I/O 请求。Completion ring 包含已完成的 I/O 请求的结果。应用程序可以通过更新 Ring 的头/尾指针来插入和检索 I/O 请求,而不需要使用系统调用。总结来说,IoUring 之所以比 Libaio 的性能更优,主要有以下三点:
1、系统调用少:Libaio 在设计上每次 IO 操作需要两个系统调用,IoUring 仅在 IO 任务提交时有系统调用,等待 IO 任务完成则不需要,比 Libaio 少一次系统调用。
2、数据复制:Libaio 存在元数据的复制,IoUring 通过用户空间和内核共享,则不需要数据复制。
3、数据中断:Libaio 依赖基于数据中断的完成通知,IoUring 在 polling 模式下不依赖硬件中断;使用 polling 需要使用内核线程 kthread,我们是混部环境,该方式不采用。
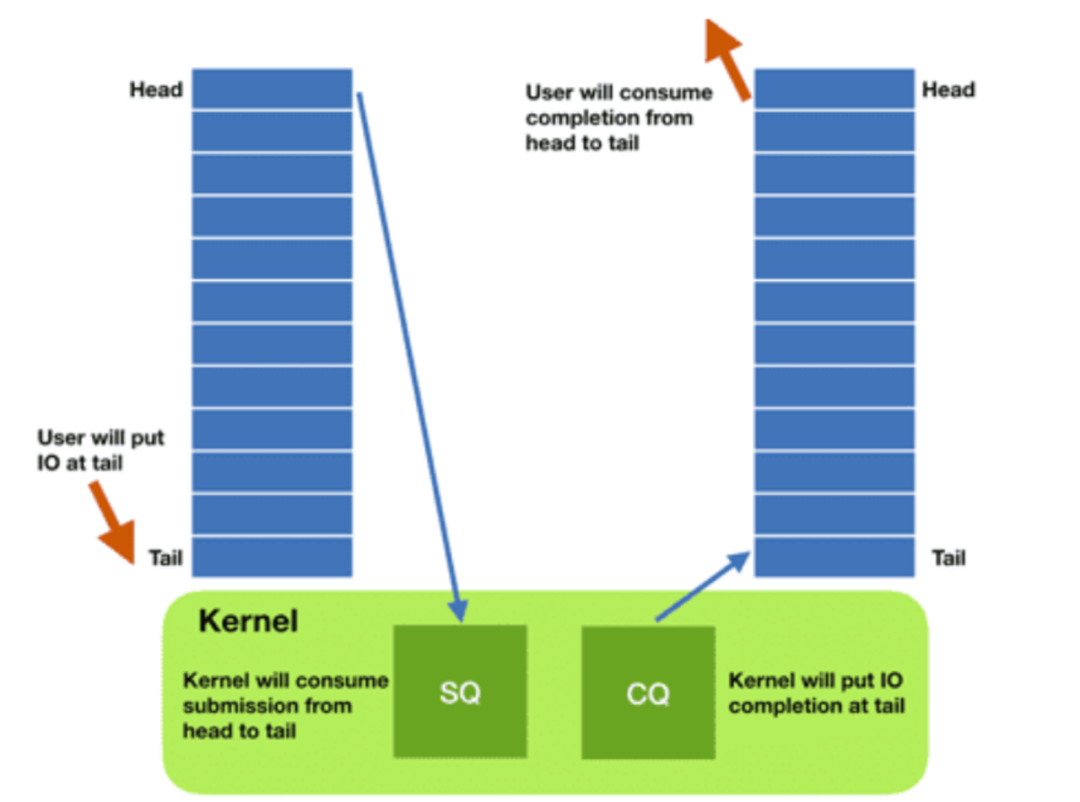
△IoUring 实现原理
SsdEngine 集成 IoUring 的过程却经历了一番探索。我们希望使用和 Libaio 同一语义的接口 io_uring_wait_cqes,IoUring Manual[14] 中解释了该函数的核心参数为,最小等待 IO 任务数 wait_nr 和等待超时 timeout,但是对 timeout 发生时,已经完成多少个 IO 任务,以及对已完成 IO 任务的处理方式没有做过多的介绍。我们先尝试参考 Libaio 同语义接口和参数,假设返回的 IO 任务都在 cqe 队列中直到 nullptr,又尝试了作者在 issue[15] 中的回答,使用宏 io_uring_for_each_cqe 处理已完成的 IO 任务,但都会在任务的结果校验环节发生错误。最终通过对 kernel 5.10 源码的跟踪,我们发现在 io_uring_wait_cqes 函数实现中增加了 io_uring_prep_timeout 超时任务,需要业务单独处理。我们还发现不同版本内核,超时任务处理并不相同。
io_uring_wait_cqes:填入 wait_nr 等待任务数和 ts 超时参数
1. __io_uring_submit_timeout(ring, wait_nr, ts);
该函数的一个重点是,给 sqe 队列添加了一个超时任务:io_uring_prep_timeout,这个任务是管理 wait_nr 和 ts 的关键
2. __io_uring_get_cqe(ring, cqe_ptr, to_submit, wait_nr, sigmask);
2.1 _io_uring_get_cqe(ring, cqe_ptr, &data);
这个函数是最终调用的主要处理逻辑
2.1.1 __io_uring_peek_cqe(ring, &cqe, &nr_available);
该函数不阻塞直接获取完成任务的队列 head,并且表明当前队列有 nr_available 个;
一个观察是在返回值没有 error, cqe 不为 null 时, nr_available 才有含义,因为通过打点,有 cqe 为 null,但 nr_aviailable 不为 0 的情况;
2.1.2 __sys_io_uring_enter2(ring->enter_ring_fd, data->submit, data->wait_nr, flags, data->arg,data->sz);
提交 sqe 队列。io_uring_submit 最终调用的也是该函数,使用该接口不需要再显示调用 io_uring_submit!
面向 io_uring_wait_cqes 实现的 kernel 版本自适应编程。总之,我们遇到的问题是在不同内核版本中 io_uring_wait_cqes 的内部实现方式有所不同。具体而言,在 kernel 5.10 及其之前的版本,会在函数实现中新增 io_uring_prep_timeout 任务处理超时,等待超时退出时,用户需要感知并单独处理该超时任务。而在 kernel 5.11 及其之后的版本中,函数实现则不再添加 io_uring_prep_timeout 任务。我们线上使用的内核版本属于前者,因此,在集成 IoUring 时,我们采取添加超时任务标识(LIBURING_UDATA_TIMEOUT)判断的方式来兼容这两个内核版本。在超时退出时,低版本内核生成的超时任务会匹配 LIBURING_UDATA_TIMEOUT 的条件分支,此时我们会跳过对该任务的额外处理。而高版本内核则不会触发这个条件分支。
// 初始化 IoUring 队列
io_uring_queue_init(iodepth, io_uring, 0 /*flags*/);
// 设置 nr 个 IO 任务的读参数
for (int i = 0; i < nr; i++) {
io_uring_prep_readv(sqe, fd, iovecs[i], 1, page_offset[i]);
}
// 一次性提交任务【debug 之后发现,使用 io_uring_wait_cqes 接口不需要再显示的提交任务】
// - io_uring_submit(io_uring);
// 设置 ts 超时参数, wait_nr 等待任务数限制;该函数的返回,要么等到 wait_nr 个任务结束,要么等待超时
while (completed < nr) {
io_uring_wait_cqes(_s_p_local_io_uring, &wait_cqe, wait_nr, &ts, nullptr /*sigmask*/);
io_uring_for_each_cqe(io_uring, head, cqe) {
// 判断是否为超时 IO 任务
if (cqe->user_data == LIBURING_UDATA_TIMEOUT) {
continue;
}
process(cqe);
io_uring_cq_advance(io_uring, 1);
completed++;
}
}
3.3 自适应切换 Libaio/IoUring
IoUring 有 8% 性能优势。无论是 FIO 压测效果,还是 SsdEngine 集成效果,都能看出在厂内机器环境下,IoUring 较 Libaio 可提升 8% 的吞吐。
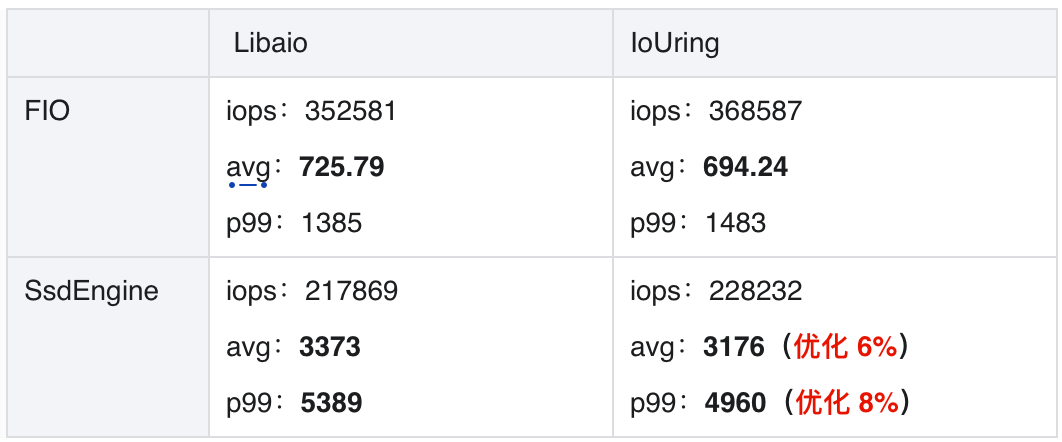
SsdEngine 要尽可能使用 IoUring。但 IoUring 依赖内核版本升级,这也是个较长期的过程。为此我们实现了自适应切换并行调度器,在 5 系之下内核的机器上,自动切换为 Libaio,在 5 系之上内核的机器,自动切换为 IoUring,并且优先 IoUring。
if (io_uring_queue_init(env_test_iodepth, &ring, 0) == 0) {
io_uring_queue_exit(&ring);
return new(std::nothrow) UringPageScheduler;
} else {
return new(std::nothrow) AioPageScheduler;
}
3.4流水线设计
在分层存储中,存在两种经典的索引方式:HashKV[8,9] 和 LSM[10]。HashKV 一般是全内存索引,基于哈希函数将键映射到存储位置,因此适用于快速查找,但在范围查询上表现相对较差。相比之下,LSM(Log-Structured Merge)索引采用多层次、顺序写入的方式,适合高吞吐量的写入操作和范围查询,但可能在单个键查找上略显繁琐。对于检索多读少写且点查的场景下,我们采用了 HashKV。
检索过程中,一次请求会有多个 KV 查询操作,引入异步并行 IO 的简易模式是:基于内存串行查询 HashTable 获取 value 存储地址,一次性发起并行访盘 IO 操作,再等待任务结束。
特别说明:
(1)对于跨多页的大 Value,在构造查询任务时候,会拆分为多个按页大小子查询任务。
(2)不足一页按页查询。
(3)一次 PV 中重复页面查询会被去重。
简易查询模式抽象如下图。横轴代表时间线,纵轴从上到下依次为应用层代码的调用顺序,在一次批量查询 IO 任务个数 batch_size 大于并行 IO 队列的大小(iodepth)时,会重复进行调度流程:schedule- 批量(iodepth 个)查询内存中的 HashKV 获取 value 存储地址, pread - 批量(iodepth 个)设置 IO 任务的参数,submit- 批量(iodepth 个)提交 IO 任务进行处理,wait- 根据 min_nr/max_nr 和 timeout 参数分批次等待 IO 任务的完成,在等待 IO 任务的过程中,并行进行这部分的数据校验,直到等到所有(iodepth 个)IO 任务的完成。

△简单查询模式
我们的优化思路是:把当前的串行的 schedule-submit-wait 模式,改为流水线,增加 IO 和 CPU 的处理并行度。具体实现上,分批次提交任务,等待任务的过程中,执行 HashTable 查询。面向用户接口方面,我们额外引入了两个流水线控制参数,这样业务可选择均衡小批量带来的系统调用开销和性能提升:
1、batch_submit,一次性提交的 IO 任务数。默认等于 iodepth,即一次性提交任务。
2、iodepth_low,默认等于 1,流水线跑起来之后,IO 任务队列中低于 iodepth - iodepth_low 个任务的时候,就开始后续任务的填充。
引用流水线后,查询模式抽象见下图。核心变化集中在: submit - 原本攒够 iodepth 个才提交任务,变成攒够 batch_submit 个就提交任务,这使得 IO 任务可以提前进入 wait 状态。wait- 原本等完 iodepth 个任务,变成等待 iodepth_low 个任务。schedule- 查询 HashTable 也因此流水线起来,提升了整体的 IO 任务和 CPU 任务的并行空间(灰色区域)。

△流水线查询模式
3.5流水线效果评测
评测环境
评测均采用单线程运行的进程,运行环境机型是 CPU INTEL Xeon Platinum 8350C 2.6GHZ ,L1d cache: 48K,L1i cache 32K,L2 cache:1280K,L3 cache:49152K,内核是 64 位 5.10 系,编译器是 GCC 8.2,编译优化选项是 -O2。
评测内容
为了充分验证流水线效果,我们评测了两种读盘场景:场景一、海量 KV,大量读盘和 HashTable 查询;场景二、超大 Value,大量读盘,但极少量 HashTable 查询。
场景一、海量KV
设置一次查询 pv 会发起 1024 次 kv,其中 value 大小为 4K,基本对应到 1024 次 HashTable 访存查询和 1024 个访盘 IO 任务。设置 iodepth=512,iodepth_low=1,调整 batch_submit 为 512、256、128、64、32,观察不同参数下,IO 任务的平响(io_us)、99 分位(io_us_99) ,评测数据见下。
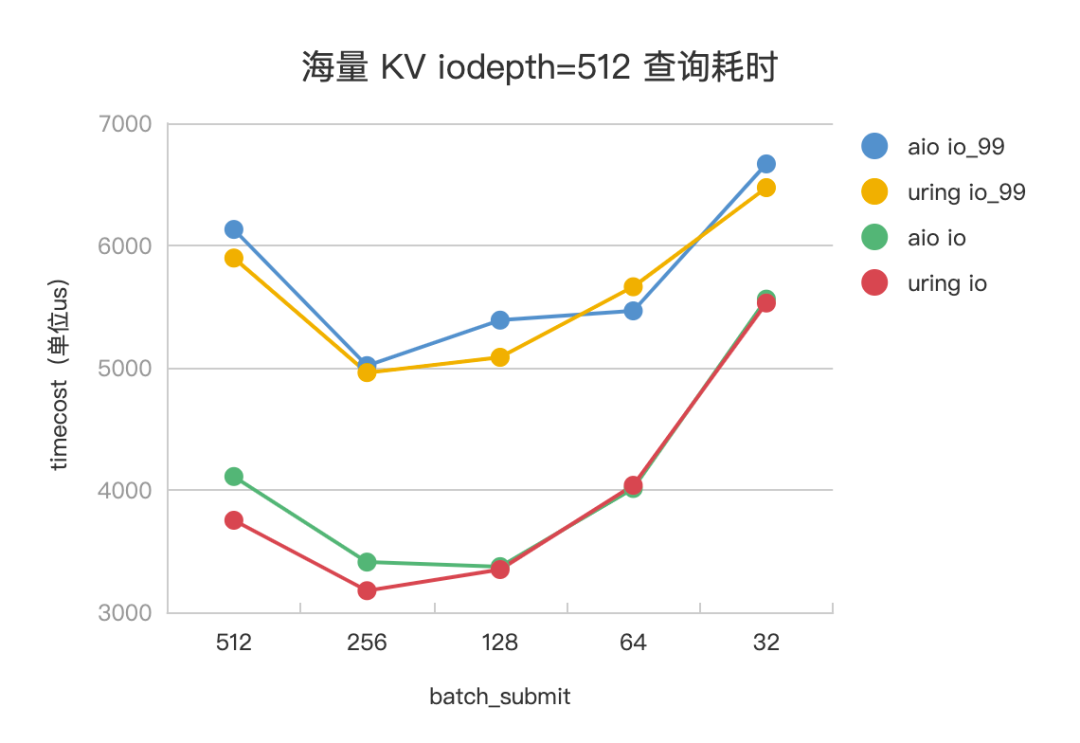
△海量 KV 查询耗时
场景二、超大Value
设置一次查询 pv 会发起 20 个 kv 查询,其中 value 大小为 1M,基本对应到 20 次 HashTable 访存查询和 245*20=4900 个访盘 IO 任务。设置 iodepth=512,iodepth_low=1,调整 batch_submit 为 512、256、128、64、32,观察不同参数下,IO 任务的平响(io_us)、99 分位(io_us_99) ,评测数据见下。
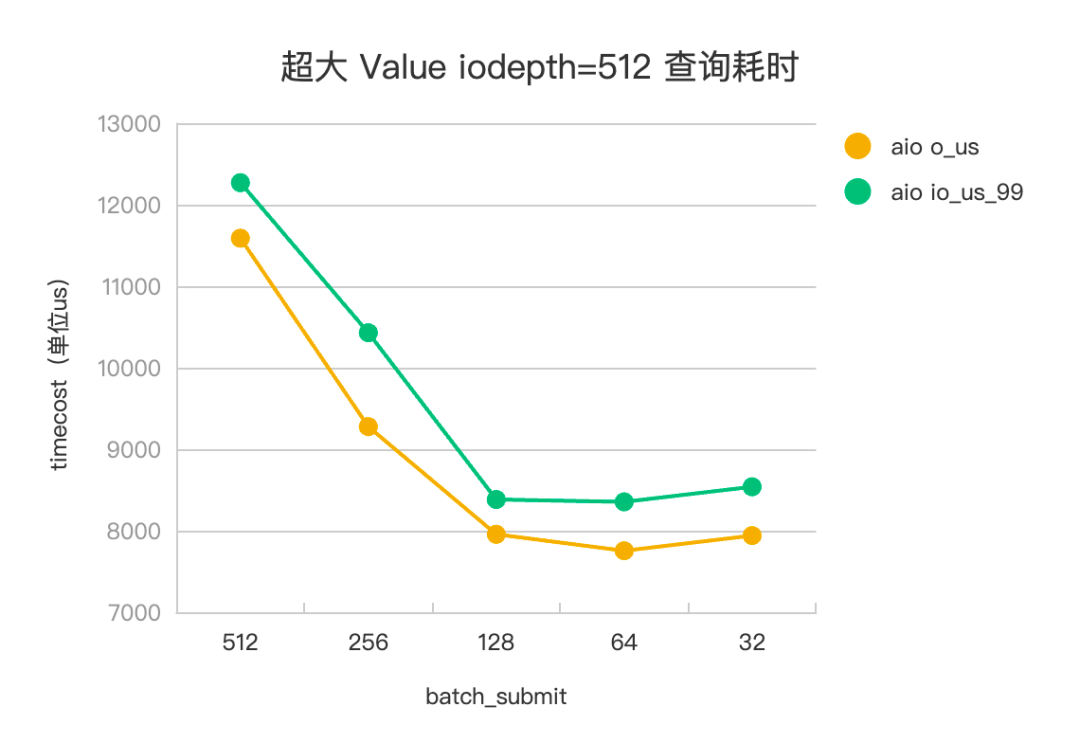
△超大 Value 查询耗时
评测结论
以 Libaio 评测数据为例。在海量 KV 场景下,batch_submit=512(iodepth) 时,没有开启流水线,IO 任务平响 4110us,batch_submit=128 时,是开启流水线的最佳平响参数,IO 任务平响 3373us,有 15%+ 的平响优化。在超大 Value 场景下,batch_submit=512 (iodepth)时,没有开启流水线,IO 任务平响 11.5ms, batch_submit=64 时,是开启流水线的最佳平响参数,IO 任务平响 7.7ms,有 30%+ 的平响优化。IoUring 和 Libaio 的评测效果趋势一致。
04应用场景
正如背景中所指出的,引入落地页信号对于用户体验和总体收入都具有积极的影响。然而,在过去迫于凤巢正排服务的内存容量限制,粗排环节仅能使用 64 位的签名 Sign 推导出归一化 URLID,整条计算链路环节过多,带来了一致性方面的问题。经过最近一个季度的努力,通过在凤巢正排服务中引入URL明文,得到了准确的 URLID,我们显著提高了体验评估的 QLQ 准确性,实验组相较对照组提升了10.8pp,业务收入也得到了明显增长。未来,我们还将把落地页信号引入到更多的粗排 Q 中,进一步提升总体收入。
05相关工作
广告基础检索系统的模块,可被视为一种业务特化的内存数据库。我们观察到,在内存数据库领域中出现了类似的发展趋势:在上世纪 90 年代,随着内存成本的降低和容量的增加,内存数据库得到了发展。然而,随着业务存储量的不断增加,内存的限制逐渐显现。进入 2010 年代,LargerThanMem 分支应运而生[11,12,13],从历届论文看,该分支还比较学术,主要研究两个关键问题:
1、如何引入分层存储,但又避免引入过多的 I/O 开销,即研究热/冷执行路径(Hot/Cold Execution Path)。
2、在分层存储后,如何设计自适应的冷热数据淘汰和检索策略。
问题 1 是系统设计的威廉希尔官方网站 问题,而当前的 SsdEngine 设计主要关注了这一问题,我们在缓存、调度和访盘等方面都有明确的规划和实现。在广告检索业务中,冷热数据的分布特性明显存在。当前,我们只针对广告库的场景,通过商业广告同步系统的旁路实现,实现了业务分层。未来,在词表场景中,我们还将探索问题 2 的解决方案。
长尾控制在某些特定生产环境中才会成为一个突出问题,我们可以将其视为 LargerThanMem 在广告检索中所特有的挑战。如上所述,在混合部署的环境中,对单盘的 IOPS 进行控制是一个涉及多个层次的复杂任务。广告基础检索服务的特点是写少读多且具备稳定量化的局部性,单实例频控 + 超时控制,已足够控制读长尾。但随着 SsdEngine 进一步推广应用,包括单盘的 Adhoc 组网通信以及集群按照 IOPS 分配,也需要应用起来。
审核编辑:汤梓红
-
存储
+关注
关注
13文章
4291浏览量
85778 -
内存
+关注
关注
8文章
3015浏览量
73983 -
SSD
+关注
关注
21文章
2855浏览量
117345 -
文件系统
+关注
关注
0文章
284浏览量
19900 -
nvme
+关注
关注
0文章
219浏览量
22618
原文标题:极致优化SSD并行读调度
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SSD之优化篇
粒子群算法城镇能源优化调度问题
基于MAPSO算法的水库优化调度与仿真
SCADA系统在供水优化调度中的应用
城市轨道交通调度优化
并行调度能耗优化算法
基于MES作业计划与调度优化

什么是指令调度(上)

什么是指令调度(下)
智能优化算法总结:数字孪生下的车间调度






 工商网监
工商网监
评论