 大家都在争相超过A100,无人对标的Grace Hopper性能几何?
大家都在争相超过A100,无人对标的Grace Hopper性能几何?
电子发烧友网报道(文/周凯扬)作为英伟达在CPU与GPU威廉希尔官方网站
开发上的集大成之作,Grace Hopper很大程度上象征着复杂计算领军产品。尽管英伟达竭尽所能地去堆这一“超级芯片”的性能,但英伟达还是选择将Grace Hopper(GH200)描述成了世界上最万能的计算平台,这也得益于它同时在AI计算和HPC计算领域展现的可怕性能。
AI计算性能
相信绝大多数人已经从市场疯抢A100、H100的现状,对Hopper GPU(H100)的性能有了大致的了解,但Grace Hopper作为一个异构计算平台,在与传统的x86 CPU与H100对比上,也有着不小的性能差距。
首要区别自然就是连接Grace CPU和Hopper GPU的NVLink-C2C,这一高带宽低延迟的互联威廉希尔官方网站
可谓是目前唯一能发挥H100近乎全部实力的方案。支持最高144TB内存的同时,提供900GB/s的带宽。
英伟达官方也对部分AI计算负载进行了测试,在终端应用上对比x86+Hopper与Grace Hopper的一体化方案有何异同。其性能差距可以说是巨大的,就拿最常见的大语言模型推理来说,GH200可以做到x86平台的4.5倍性能表现,而DLRM(深度学习推荐模型)训练与图神经网络(GNN)训练的性能也可以分别达到3.5倍和1.9倍。
其实这里的差异还是体现在互联方案的带宽上,例如x86+Hopper的方案还是在使用PCIe方案,该方案在batch size较小时性能落后还不算明显,一旦到了更大的batch size,PCIe的带宽就成了瓶颈,而不断以高带宽输送数据给H100的NVLink-C2C则可以实现比PCIe高出数倍的性能。
HPC计算性能
Grace Hopper的另一大应用领域自然就是HPC了。HPC主要集中在一些科学、工程的复杂计算上,比如天气预测、生命科学、流体力学等。然而与此同时,不少商业相关的HPC计算也在进一步推动HPC的发展,甚至更早用上最新的芯片威廉希尔官方网站
,比如油藏interwetten与威廉的赔率体系
等。
著名油藏模拟软件ECHELON的开发商Stone Ridge,在最近获得了早期访问权,对英伟达的H100-PCIe、H100-NVL和Grace-Hopper来了场性能测试。早在Volta和Ampere架构时,Stone Ridge就对不同架构的GPU进行了测试,而如今的H100相较这些旧GPU已经在CUDA核心、内存容量和内存带宽上有了数倍的提升。
这些还只是表面上的变化,英伟达还引入了诸多架构改进,提高了ML和HPC应用程序的性能。而Grace Hopper相较传统的x86+GPU方案就更具优势了,首先Grace本身就是一个强大的CPU,每个内核都有四个128位适量单元,超高的内存带宽以及超大的L2+L3缓存。其次,NVLink的存在大大减少了CPU和GPU之间的通信时间。
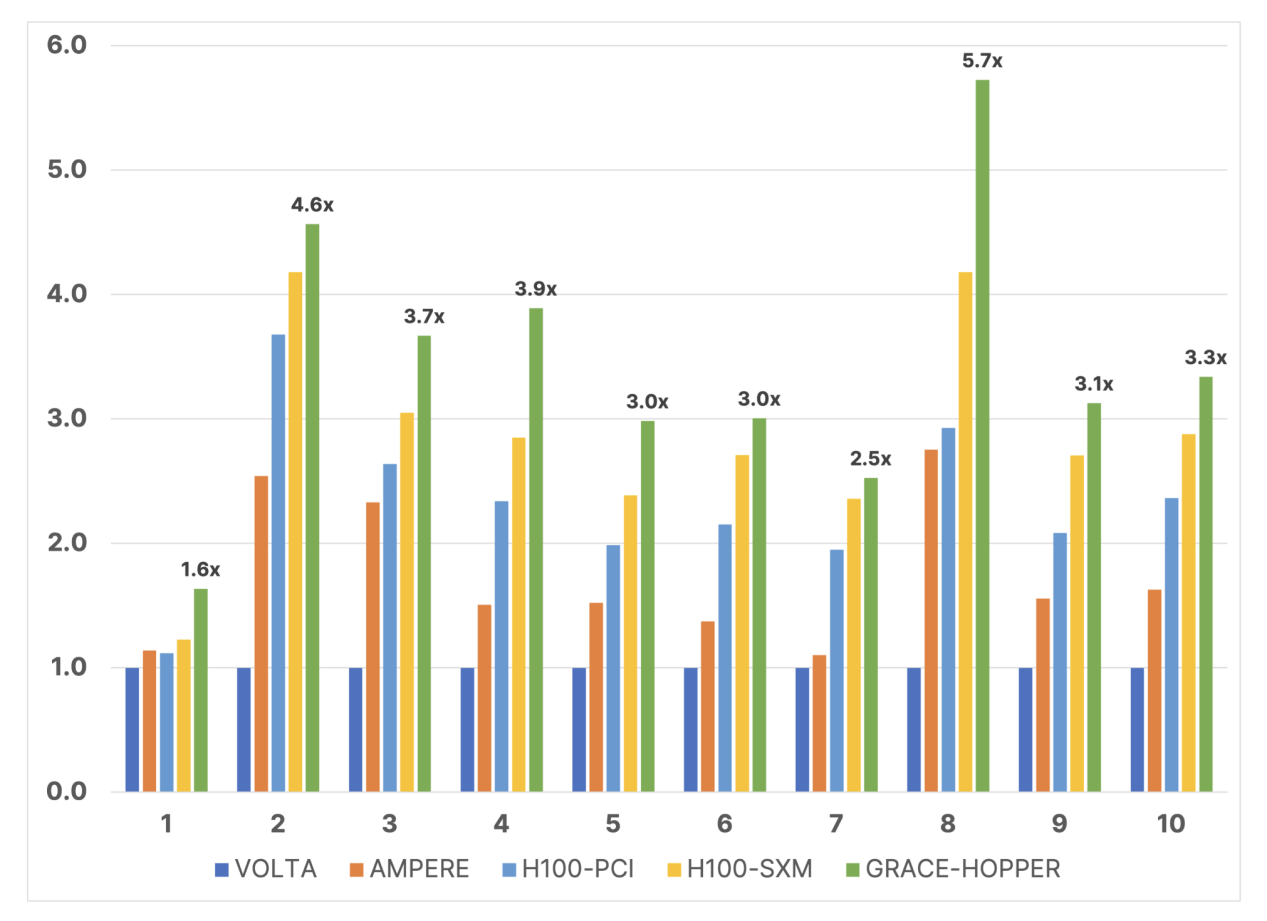
不同架构不同版本的英伟达GPU在ECHELON模型上的性能对比 / Stone Ridge
Stone Ridge选择了不同细胞规模的模型,从83000个细胞到670万个细胞,其中Grace Hopper都展现出了不俗的性能,最高可达Volta架构的V100的5.7倍。值得一提的是,由于CPU采用了新的Arm架构,所以ECHELON必须重新编译才能在系统上运行,不过对于ECHELON来说,重新编译并不要花太多力气,他们在不修改代码的情况就成功重编译在GH200上正常运行。如果对代码进行进一步优化的话,还有机会获得更高的性能表现。如此高的性能提升,意味着油藏勘探模拟的时间可以被大幅缩短,从而加快油藏评估的速度。
结语
可以说无论是A100还是H100,都只是英伟达在AI与HPC战线扩大战果的第一步棋,明年Q2交付到各大系统中的GH200才是最大的杀手锏,也很可能会成为更抢手的数据中心与超算中心硬件产品。这也恰好证明了英伟达给它的定位,世界上最万能的计算平台。
发布评论请先 登录
相关推荐
本期为大家带来的是100W氮化镓充电器详细介绍拆解。

软银升级人工智能计算平台,安装4000颗英伟达Hopper GPU
NVIDIA AI Enterprise荣获金奖

亚马逊AWS暂缓订购英伟达Grace Hopper,等待新品Grace Blackwel
亚马逊未中断英伟达订单,等待Grace Blackwell更强性能
英伟达静候新品来临,亚马逊暂缓购买Grace Hopper
NVIDIA Grace Hopper点亮AI超级计算新时代
NVIDIA通过CUDA-Q平台为全球各地的量子计算中心提供加速
美国首个Grace Hopper架构超算Venado落地:达10 exaFLOPS
Arm架构与Neoverse威廉希尔官方网站 在基础设施领域的应用与发展
NVIDIA特供中国的芯片,AI性能大降10%售价依然高
英伟达Grace-Hopper提供一个紧密集成的CPU + GPU解决方案
英伟达和华为/海思主流GPU型号性能参考






 工商网监
工商网监
评论