 TUM&谷歌提出md4all:挑战性条件下的单目深度估计
TUM&谷歌提出md4all:挑战性条件下的单目深度估计
前言
大家好, 我叫Stefano Gasperini, 在此宣传我们的ICCV 2023的工作, 更多详细信息可查看我们的论文: https://arxiv.org/abs/2308.09711, 和我们的项目网站: https://md4all.github.io.
代码:https://github.com/md4all/md4all
在CVer微信公众号后台回复:md4all,可下载本论文pdf和代码
首先请大家观看这样一个例子:
你能在彩色图片中看到树吗?

我们的单目深度估计网络在所有条件下都能输出可靠的深度估计值,即使在黑暗中也是如此!
背景
虽然最先进的单目深度估计方法在理想环境下取得了令人印象深刻的结果,但在具有挑战性的光照和天气条件下,如夜间或下雨天,这些方法却非常不可靠。

在这些情况下, 传感器自带的噪声、无纹理的黑暗区域和反光等不利因素都违反了基于监督和自监督学习方法的训练假设。自监督方法无法建立学习深度所需的像素的对应关系,而监督方法则可能从传感器真值中(如上图中的 LiDAR 与 nuScenes 的数据样本)中学习到数据瑕疵。
方法
在本文中,我们提出了 md4all 解决了这些安全关键问题。md4all 是一个简单有效的解决方案,在不利和理想条件下都能可靠运行,而且适用于不同类型的监督学习。
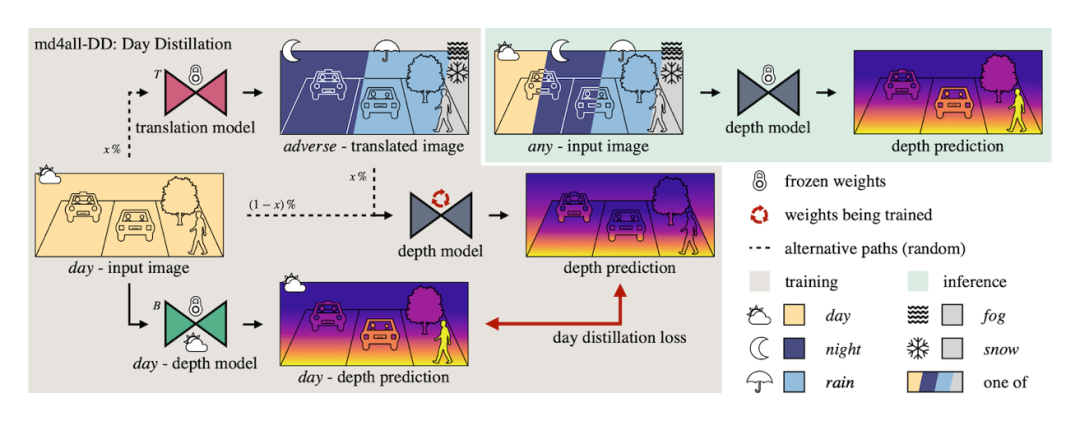
我们利用现有方法在完美设置下的工作能力来实现这一目标。因此,我们提供的有效训练信号与输入信号无关。首先,通过图像转换,我们生成一组与正常训练样本相对应的复杂样本。然后,我们通过输入生成的样本并计算相应原始图像上的标准损失,引导网络模型进行自监督学习或完全监督学习。
如上图所示,我们进一步从预先训练好的基线模型中提炼知识,该模型只在理想环境下进行推理,同时向深度模型提供理想和不利的混合输入。
我们的 GitHub 代码库中包含所提方法的实现代码, 欢迎访问:
https://github.com/md4all/md4all
结果

通过 md4all,我们大大超越了之前的解决方案,在各种条件下都能提供稳健的估计。值得注意的是,所提出的 md4all 只使用了一个单目模型,没有专门的分支。
上图显示了在 nuScenes 数据集的挑战性环境下的预测结果。由于场景的黑暗程度和噪声带来的影响,自监督方法 Monodepth2 无法提取有价值的特征(第一行)。有监督的 AdaBins 会学习到来自传感器数据的瑕疵,并造成道路上的空洞预测现象(第二行)。在相同的架构上应用,我们的 md4all 提高了在标准和不利条件下的鲁棒性。
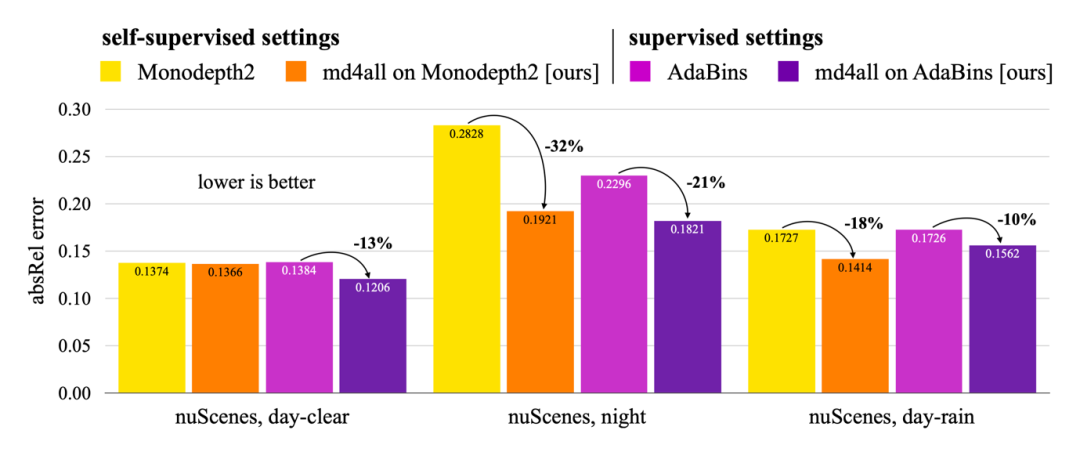
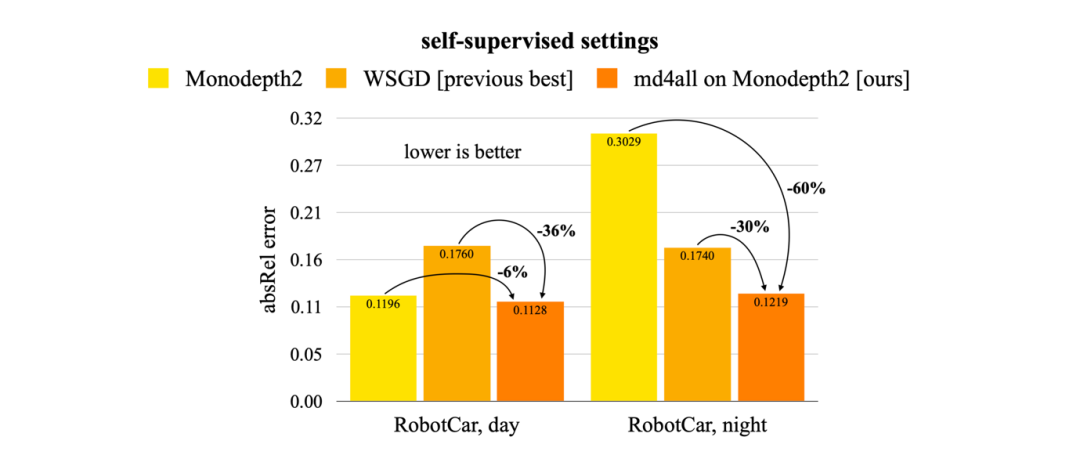
在本文中,我们展示了 md4all 在标准和不利条件下两种类型的监督下的有效性。通过在 nuScenes 和 Oxford RobotCar 数据集上的大量实验,md4all 的表现明显优于之前的作品(如上图数据所示)。
图像转换

我们还显示了为训练 md4all 而生成的图像转换示例 (如上图所示)。我们通过向模型提供原始样本和转换样本的混合数据进行数据增强。这样一个模型就能在不同条件下恢复信息,而无需在推理时进行修改。
在此,我们开源共享所有不利条件下生成的图像,这些图像与 nuScenes 和牛津 Robotcar 训练集中的晴天和阴天样本相对应。欢迎访问:
https://forms.gle/31w2TvtTiVNyPb916
这些图像可用于未来深度估计或其他任务的稳健方法。
-
传感器
+关注
关注
2550文章
50951浏览量
752802 -
谷歌
+关注
关注
27文章
6157浏览量
105248 -
模型
+关注
关注
1文章
3206浏览量
48793
原文标题:ICCV 2023 | TUM&谷歌提出md4all:挑战性条件下的单目深度估计
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何在芯片内同时捕获不同触发条件下的信号
在各种负载条件下保持高效率的电源控制器
基于单目图像的深度估计算法,大幅度提升基于单目图像深度估计的精度

欧拉 Summit 2021 安全&amp;可靠性&amp;运维专场:主流备份威廉希尔官方网站 探讨

满足当今外壳设计具有挑战性的性能和散热要求
密集单目SLAM的概率体积融合概述
一种用于自监督单目深度估计的轻量级CNN和Transformer架构
介绍第一个结合相对和绝对深度的多模态单目深度估计网络
一种利用几何信息的自监督单目深度估计框架
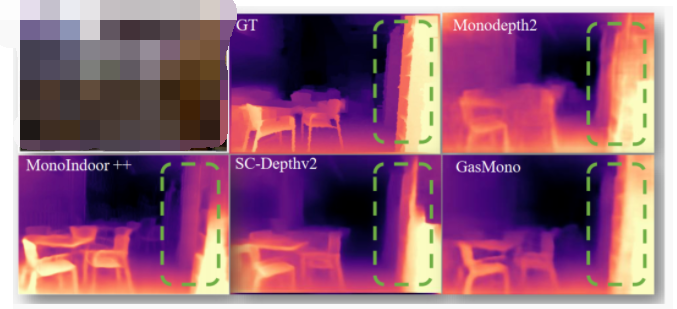
动态场景下的自监督单目深度估计方案
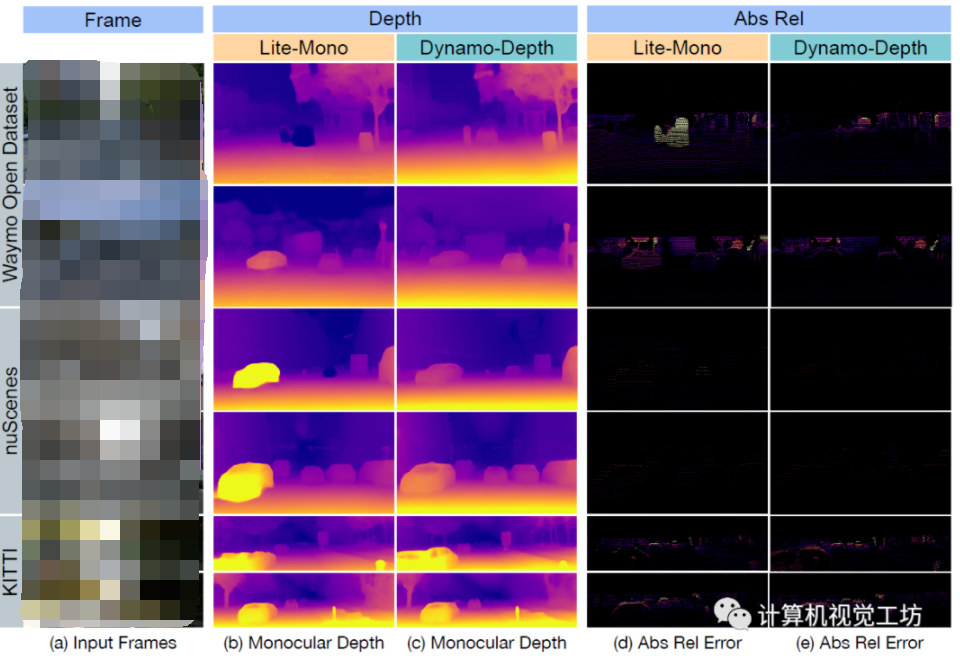






 工商网监
工商网监
评论