 LibTorch-based推理引擎优化内存使用和线程池
LibTorch-based推理引擎优化内存使用和线程池
由喜马拉伊·莫汉拉尔·乔里瓦尔、皮埃尔-伊夫·阿基兰蒂、维韦克·戈温丹、哈米德·舒贾纳泽里、安基思·古纳帕勒、特里斯坦·赖斯撰写
大纲大纲
在博客文章中,我们展示了如何优化基于 LibTorrch 的推论引擎,通过减少记忆用量和优化线状组合战略来最大限度地增加吞吐量。 我们将这些优化应用到音频数据模式识别引擎,例如音乐和语音识别或声波指纹。 本博客文章中讨论的优化使得内存使用率减少了50%,推论端到端的延迟度减少了37.5%。 这些优化适用于计算机视觉和自然语言处理。
音频识别推断
音频识别(AR)引擎可用于识别和识别声音模式。 例如,识别鸟类与录音的种类和种类,区分音乐与歌手的声音,或检测显示建筑物有异常故障的声音。 为了识别有兴趣的声音,AR引擎将音频处理到4个阶段:
文件校验:AR 引擎验证输入音频文件。
采掘:从音频文件中的每个部分提取特征。
推断: LibTorrch 使用 CPU 或加速器进行推论。就我们的情况而言,在 Elastic Cloud 计算( EC2) 实例中,使用 Intel 处理器进行推论。
后处理:后处理模式解码结果并计算用来将推断输出转换成标记或记录誊本的分数。
在这4个步骤中,推论是计算最密集的,根据模型的复杂性,推论可以占管道处理时间的50%,这意味着现阶段的任何优化都会对整个管道产生重大影响。
最优化音频识别引擎, 使用 conconconconconcondal 货币... 并不简单
输入数据是一个音频文件,由几个短声段组成(图1中的S1至S6),输出数据与按时间戳订购的标记或记录誊本相对应。
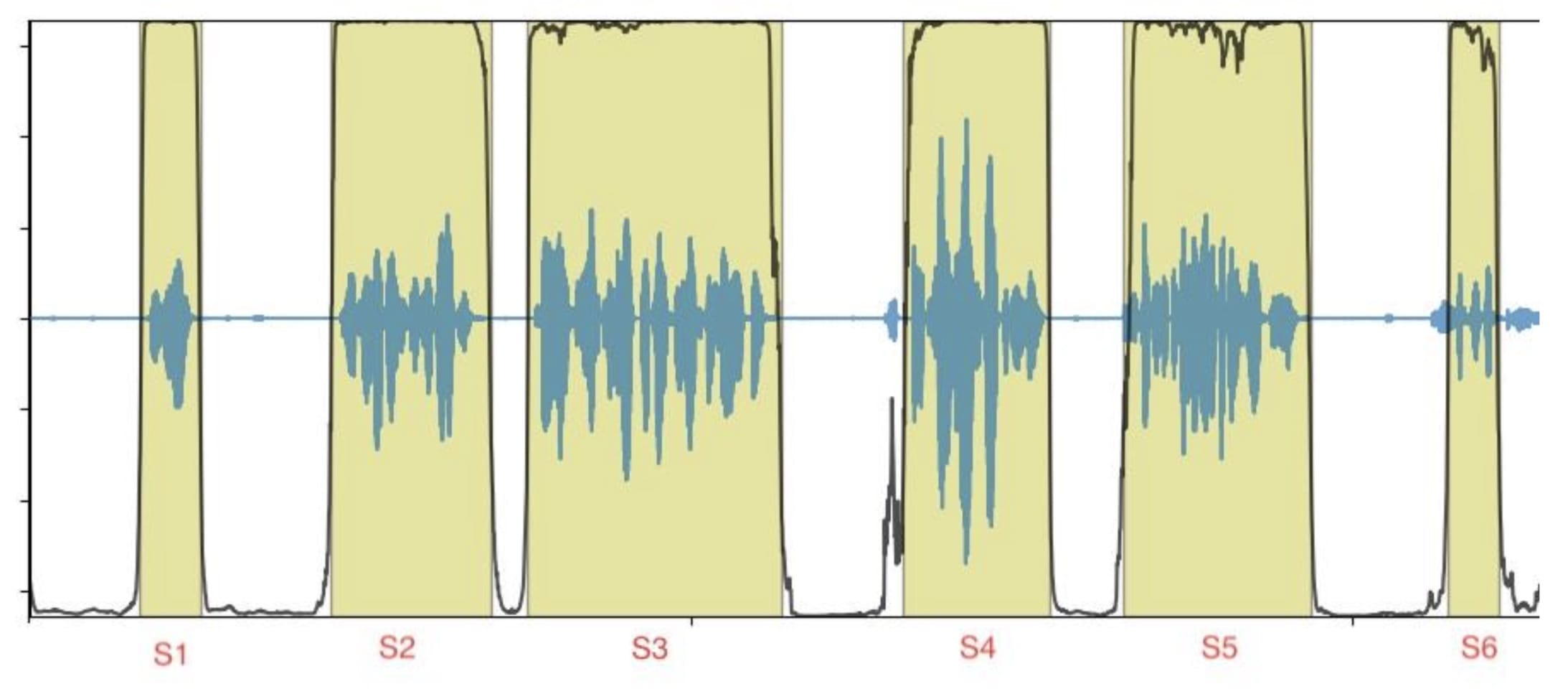
图1 图1:有段边框的音频文件示例
每一部分可以独立和不按部就班的方式处理,这样就有机会同时处理各部分,同时处理各部分,优化总体推论量,最大限度地利用资源。
实例的平行化可以通过多行( phread: std:: threads, OpenMP) 或多处理来实现。 多处理的多行的好处是能够使用共享的内存。 它使开发者能够通过共享线条的数据来尽量减少线条上的数据重复; 我们的 AR 模型( 以我们为例) ( AR 模型) 。图2 图2此外,记忆力的减少使我们能够通过增加引擎线的数量,同时运行更多的管道,以便利用我们亚马逊EC2实例中的所有小CPU(VCPU)。c5.4 宽度我们的情况是,它提供了16 VCPUs。 理论上,我们期望看到我们的AR引擎的硬件利用率更高,输送量更高。
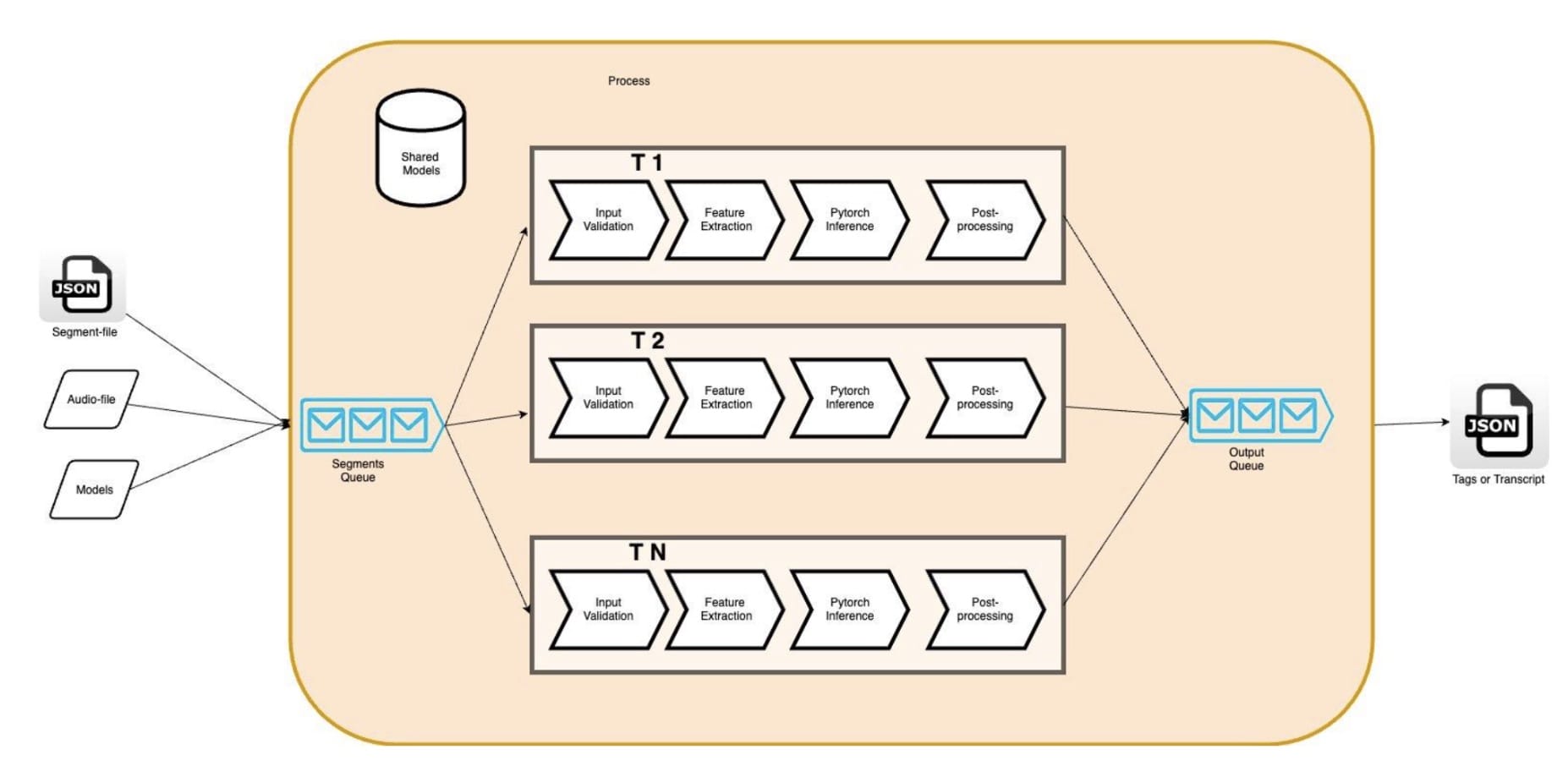
图2 图2:多读 AR 引擎
但是,我们发现这些假设是错误的。 事实上,我们发现应用程序的线条数量增加导致每个音频段端到端的延迟度增加,引擎输送量减少。 比如,将同值货币从1个线条增加到5个线条导致延缓度增加4x,这对减少吞吐量产生了相应的影响。 事实上,衡量标准显示,在管道内,单是推断阶段的延迟度就比单一线线条基线高出3x。
使用一个剖面文件 我们发现CPU旋转时间由于CPU 过度订阅会影响系统和应用性能,我们可能因此增加。 鉴于我们对应用程序多轨执行的控制,我们选择更深入地潜入堆栈,并找出与 LibTorrch 默认设置的潜在冲突。
深入了解LibTorch的多行及其对同货币的影响
LibTorch 平行执行CPU的推断依据是:全环线串联集合执行实例是跨业务和内部平行,可视模型的特性选择。在这两种情况下,都有可能设定线索数在每个线性孔中 优化潜伏和吞吐量
为了测试LibTorrch的平行默认执行设置是否对我们的推论延缓期产生了反作用,我们用一个35分钟的音频文件对一台16 vCPus机器进行了实验,将LibTorrch的连接线条常数保持在1(因为我们的模型没有使用操作间线条库 ) 。 我们收集了以下数据,如图3和图4所示。
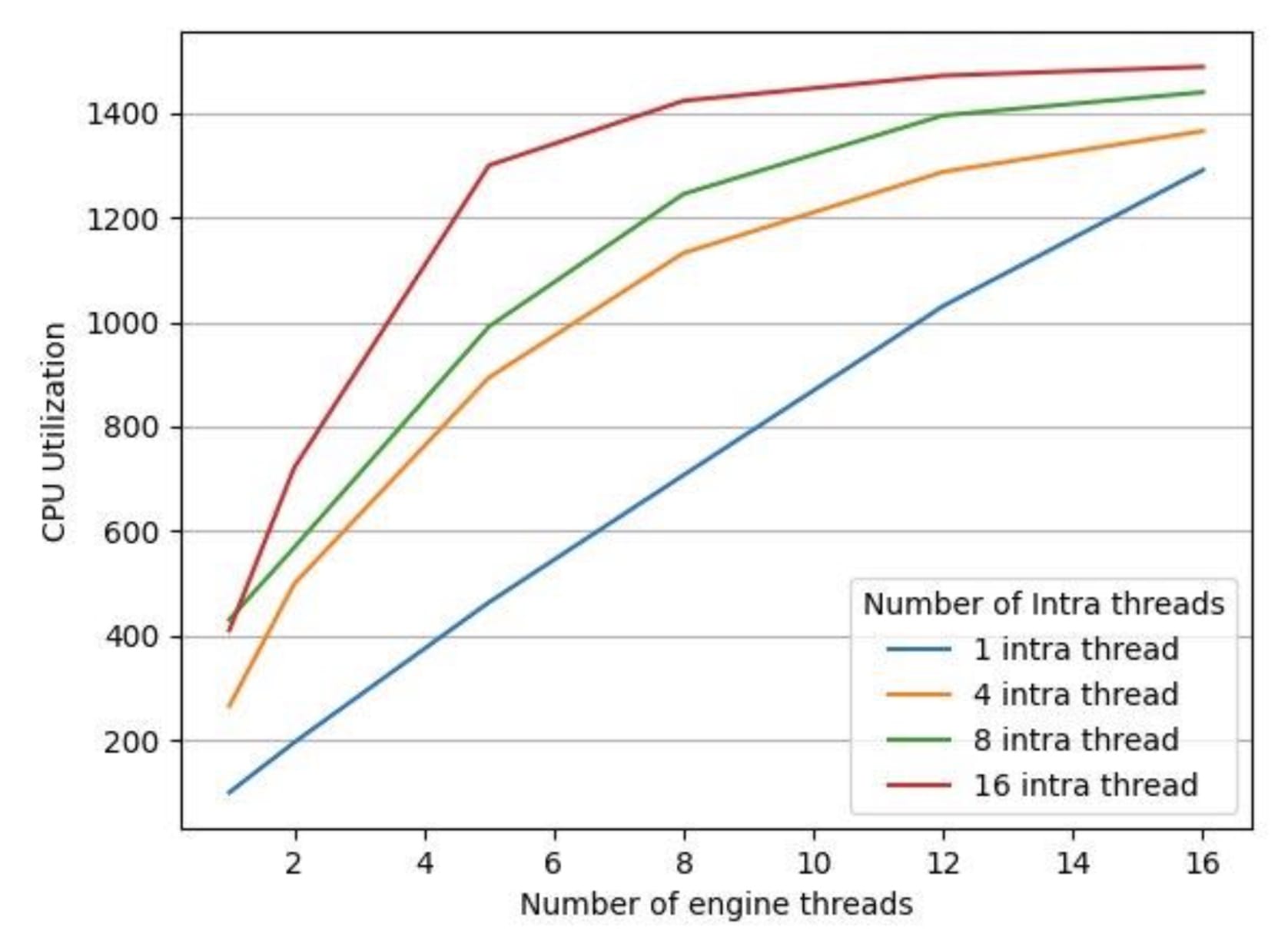
图3 图3:不同数量引擎线索的 CPU 利用率
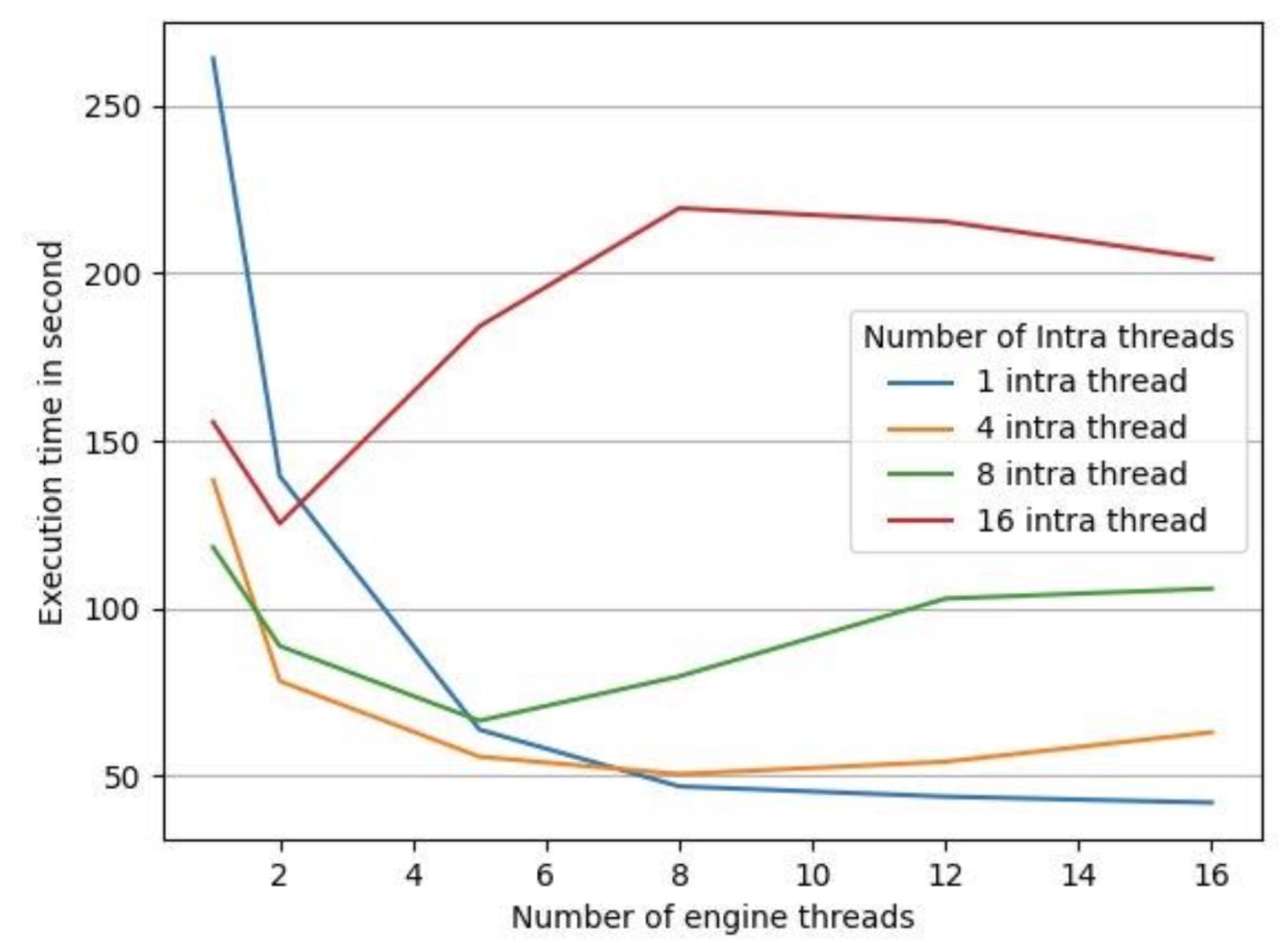
图4 图4: 不同数量引擎线索的处理时间
图4中的执行时间是处理给定音频文件所有部分的端到端处理时间。 我们有4个不同配置的 LibTorrch 内部线条内部配置为 1 、 4 、 8 、 16, 并且我们将每条线内配置的引擎线数从1 改为 16。 如图3所示, CPU的利用率随着所有 LibTorrch 内部配置的引擎线数的增加而增加。 但是, 如图4所示, CPU 利用率的增加并没有转化为较低的执行时间。 我们发现, 在除1个案例之外的所有案例中, 发动机线条数量增加, 执行时间也随之增加。 例外的是, 整个线条内库规模增加1 的情况是一个例外。
解决全球线索池问题
与全球线索库使用过多的线索导致性能退化,并造成订阅过多问题。全球连托全球联线人才库,很难与多过程发动机的性能相匹配。
将LibTorrch全球线条库拆解, 简单到将操作内部/操作间平行线线设置为 1, 如下表所示:
:set_num_threads(1) // 禁用内部线条库 :set_ num_interop_threads(1) 。 / 禁用内部线条库 。
如图4所示,当LibTorch全球线条池被禁用时,最低处理时间是测量的。
这一解决方案在若干情况下改善了AR发动机的吞吐量。 然而,在评价长数据集(在负荷测试中超过2小时的Audio文件)时,我们发现发动机的记忆足迹开始逐渐增加。
优化内存使用
我们用两个小时长的音频文件对系统进行了负荷测试,发现观察到的内存增加是多轨LibTorch推论中内存破碎的结果。我们用这个方法解决了这个问题。杰梅洛c,这是一个通用的商场(3)执行,强调避免分散和可缩放的货币支持。使用 Jemalloc我们的峰值内存使用率平均下降了34%,平均内存使用率下降了53%。
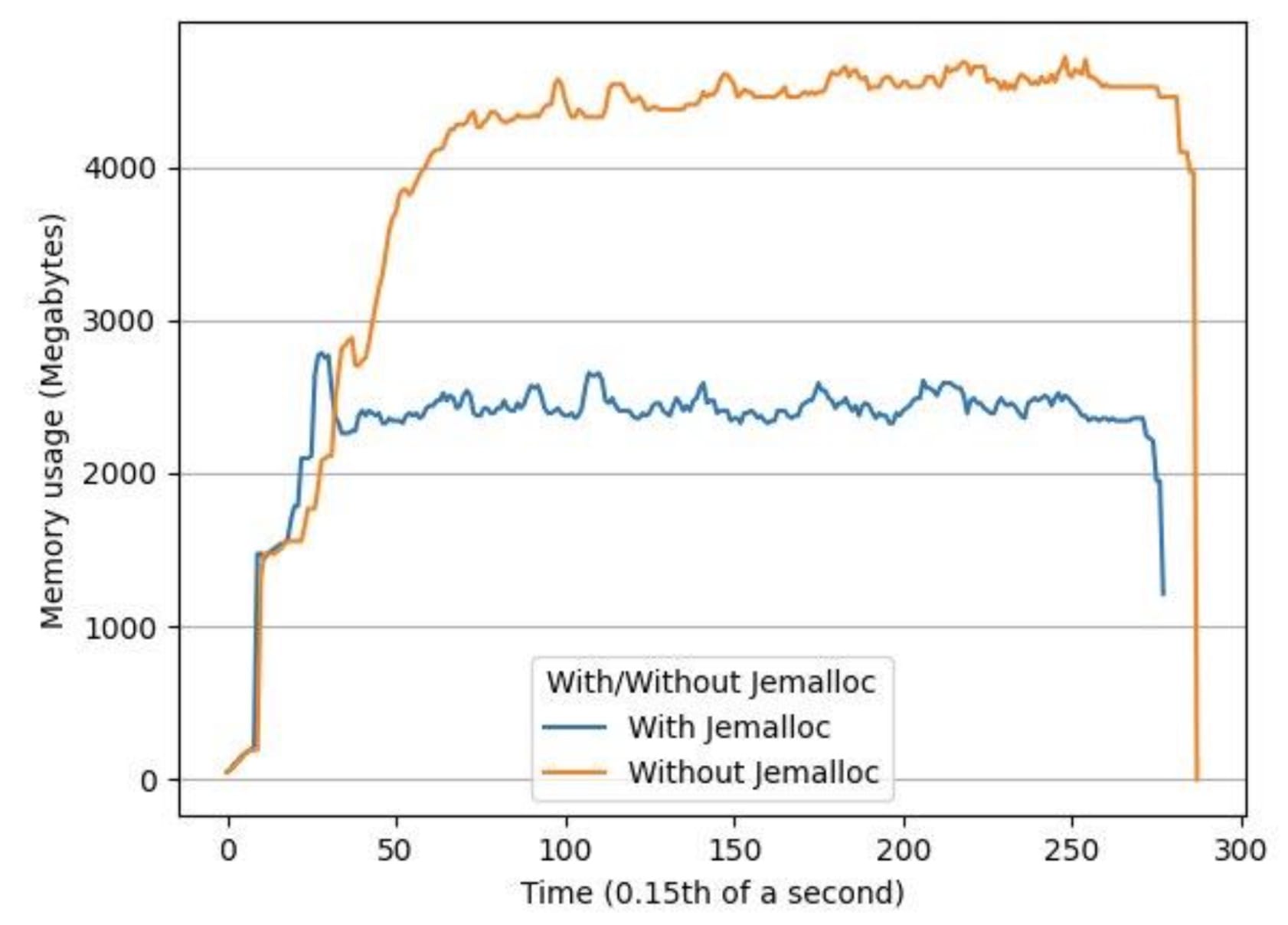
图5 图5:使用有 Jemalloc 和没有 Jemalloc 的同一输入文件,随着时间的推移内存使用量
摘要摘要
为了优化基于 libTorrch 的多轨 LibTorrch 推断引擎的性能,我们建议核实LibTorrch 中不存在过量订阅问题。 就我们而言,多轨引擎中的所有线条都是共享 LibTorrch 全球线条库,这造成了一个过量订阅问题。 这一点通过让全球线条库失效而得到纠正: 我们通过将线条设为 1 来禁用内部和内部全球线条库。 为了优化多轨引擎的内存, 我们建议使用 Jemalloc 来作为记忆分配工具, 而不是默认的时钟功能 。
审核编辑:汤梓红
-
cpu
+关注
关注
68文章
10859浏览量
211698 -
内存
+关注
关注
8文章
3023浏览量
74030 -
线程池
+关注
关注
0文章
57浏览量
6846 -
pytorch
+关注
关注
2文章
808浏览量
13219
发布评论请先 登录
相关推荐
多线程之线程池

线程池的线程怎么释放
Spring 的线程池应用

高并发内存池项目实现





 工商网监
工商网监
评论