 ChatGPT原理 ChatGPT模型训练 chatgpt注册流程相关简介
ChatGPT原理 ChatGPT模型训练 chatgpt注册流程相关简介
ChatGPT注册没有外国手机号验证怎么办?
ChatGPT作为近期火爆网络的AI项目,受到了前所未有的关注。我们可以与AI机器人实时聊天,获得问题的答案。但受ChatGPT服务器及相关政策的影响,其注册相对繁琐。那么国内如何注册ChatGPT账号?本文跟大家详细分享GPT账户注册教程,手把手教你成功注册ChatGPT。
ChatGPT是一种自然语言处理模型,ChatGPT全称Chat Generative Pre-trained Transformer,由OpenAI开发。它使用了基于Transformer的神经网络架构,可以理解和生成自然语言文本。ChatGPT是当前最强大和最先进的预训练语言模型之一,可以生成具有逻辑和语法正确性的连贯文本。它在自然语言处理的各个领域,例如对话生成、文本分类、摘要生成和机器翻译等方面都取得了非常优秀的成绩。ChatGPT的成功表明,预训练语言模型已经成为自然语言处理领域的主流威廉希尔官方网站 之一
ChatGPT原理
ChatGPT从领域上是属于自然语言处理(Natural Language Processing),简称NLP
NLP的主要目标是使计算机能够理解、分析、操作人类语言,从而实现更加智能化的自然语言交互
自然语言处理
历年发展
自然语言处理威廉希尔官方网站 的发展历程经历了从规则到统计再到深度学习的三个阶段:
规则型方法阶段(1950年代至1980年代初):该阶段主要采用人工规则来描述语言结构和语义,并通过编写一系列规则来实现自然语言处理任务。这种方法的局限性在于需要大量的人工参与,难以处理复杂的语言现象。
统计型方法阶段(1980年代中期至1990年代中期):该阶段主要采用统计模型来处理自然语言,例如基于马尔可夫模型和隐马尔可夫模型的自然语言处理威廉希尔官方网站
。这种方法依赖于大规模语料库的统计分析,可以处理一定程度上的语言不确定性,但在语义分析和生成等方面仍存在较大局限性。
深度学习方法阶段(2010年代至今):该阶段主要采用深度学习模型来处理自然语言,例如基于循环神经网络(RNN)和长短时记忆网络(LSTM)的模型,以及后来的Transformer模型。深度学习模型具有较强的表达能力和泛化能力,可以处理复杂的语言结构和语义关系,广泛应用于自然语言理解、机器翻译、文本分类、问答系统等任务中。
自然语言处理开始时是利用传统的威廉希尔官方网站 来解决问题,例如基于规则的方法、词典匹配等。但是这些传统方法需要大量手工编写规则和模式来处理自然语言,难以适应自然语言的多样性和复杂性。相比之下,人工智能威廉希尔官方网站 具有自主学习和适应数据的能力,能够更加灵活和高效地处理自然语言。因此,在解决自然语言处理问题时,人工智能威廉希尔官方网站 已经成为主流和先进的方法。
NLP的复杂性体现在以下几个方面:
多义性:自然语言中的词汇经常有多个意义,需要根据上下文确定其意义。
含糊性:自然语言中的表达往往不够准确,可能存在歧义,需要通过语境来确定其含义。
语言多样性:不同语言之间存在差异,同一语言的不同方言或口音也存在差异。
长距离依赖关系:句子中的某些词可能影响句子中很远的其他词,需要考虑整个句子的语义。
知识不完备:自然语言处理需要大量的先验知识和语言资源,而这些知识和资源往往是不完备的。
这些复杂性使得自然语言处理任务具有挑战性,需要使用先进的威廉希尔官方网站
和算法来解决。
NLP主要内容包括以下:
语音识别:将人的语音转换成可被计算机理解的文本形式。
语言理解:理解人类语言的含义,包括语法、词汇、语义和上下文。
机器翻译:将一种语言的文本自动转换成另一种语言的文本。
信息检索:在大量文本数据中查找相关信息。
文本分类:将文本数据分成不同的类别。
命名实体识别:从文本数据中识别出具有特定名称的实体,例如人名、地名、公司名等。
信息抽取:从文本数据中抽取出有用的信息,例如时间、地点、事件等。
情感分析:分析文本数据中的情感倾向,例如正面、负面或中立等。
文本生成:自动产生新的文本数据,例如文章、诗歌等。
其中ChatGPT在语言理解、机器翻译、文本分类、信息抽取、文本生成方面表现相当优秀
目前NLP的主流解决威廉希尔官方网站 方案是人工智能,人工智能的威廉希尔官方网站 要素包括数据、算法、算力、模型。他们的关系为通过数据、算法、算力求模型,通俗地理解为如同人类一样用数据找到规律。人工智能区别于传统编程开发,传统编程开发是用已知规律求数据
ChatGPT模型训练
ChatGPT是一个模型,是通过数据、算法、算力求得的一个模型,其中数据、算法、算力具体内容为:
数据:ChatGPT使用了大量的自然语言文本数据进行预训练,包括维基百科、BookCorpus等。
算法:ChatGPT使用了Transformer算法,这是一种基于自注意力机制的神经网络模型,能够有效地处理自然语言文本数据
算力:为了训练和使用ChatGPT模型,需要大量的计算资源,包括GPU和分布式计算框架等。具体来说,OpenAI在训练13亿参数的GPT-3模型时使用了数千个GPU和TPU
其原理主要包括以下几个方面:
Transformer结构:ChatGPT使用了Transformer结构作为其基本架构,通过自注意力机制实现了对输入序列的编码和对输出序列的解码。
预训练:ChatGPT使用了大规模语料库进行了预训练,从而学习到了大量的语言知识,包括词汇、语法和语义等。
微调:ChatGPT在预训练的基础上,通过针对具体任务进行微调,从而实现了在特定任务上的优秀表现。
无监督学习:ChatGPT通过无监督学习的方式进行训练,即在不需要人工标注数据的情况下,通过最大化语言模型的似然函数来训练模型,从而实现了对语言知识的自动学习。
那么ChatGPT模型是如何训练的呢
ChatGPT模型的主要训练流程可以概括为以下几个步骤:
数据准备:准备大规模的文本数据作为训练数据集
模型设计:采用Transformer架构,构建多层的编码器-解码器结构,并采用自注意力机制实现对文本的建模
模型初始化:使用随机初始化的参数,构建初始的模型
模型训练:采用大规模的文本数据集对模型进行训练,以最小化损失函数为目标,让模型逐步学习输入文本的规律
模型评估:对训练好的模型进行评估,通常采用困惑度(perplexity)等指标来衡量模型的性能
模型微调:通过对模型参数进行微调,进一步提高模型的性能
模型部署:将训练好的模型部署到应用场景中,实现自然语言生成、问答等功能
训练模型
在这里插入图片描述
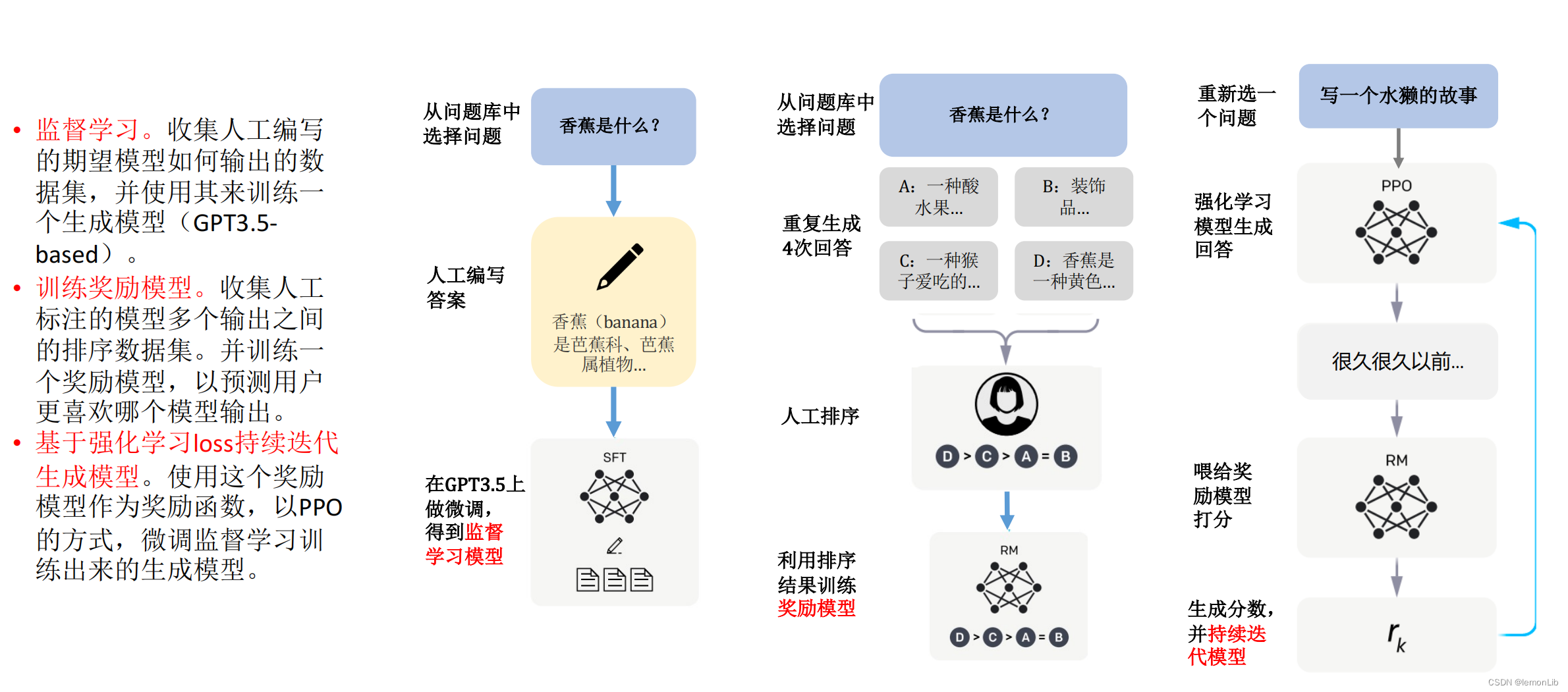
首先以监督学习方式训练能够写答案的生成模型,然后利用人工排序训练奖励模型,用于对生成模型的输出打分, 最后用奖励模型预测结果且通过 PPO 算法优化 SFT 模型得PPO-ptx模型
阶段1:利用人类的标注数据(demonstration data)去对 GPT3 进行监督训练。
1)先设计了一个prompt dataset,里面有大量提示样本,给出了各种各样的任务描述;
2)其次,标注团队对 prompt dataset 进行标注(本质就是人工回答问题);
3)用标注后的数据集微调 GPT3(可允许过拟合),微调后模型称为 SFT 模型(Supervised fine-tuning,SFT),具备了最基本的文本生成能力。
阶段2:通过 RLHF 思路训练奖励模型 RM
1)微调后的 SFT 模型去回答 prompt dataset 问题,通过收集 4 个不同 SFT 输出而获取 4 个回答;
2)接着人工对 SFT 模型生成的 4 个回答的好坏进行标注且排序;
3)排序结果用来训练奖励模型RM (Reward Model),即学习排序结果从而理解人类的偏好。
阶段3:通过训练好的 RM 模型预测结果且通过 PPO 算法优化 SFT 模型的策略。
1)让 SFT 模型去回答 prompt dataset 问题,得到策略的输出,即生成的回答;
2)此时不再让人工评估好坏,而是让阶段 2 RM 模型去给 SFT 模型的预测结果进行打分排序;
3)使用 PPO 算法对 SFT 模型进行反馈更新,更新后的模型称为 PPO-ptx。
为什么ChatGPT在语言理解、机器翻译、文本分类、信息抽取、文本生成方面表现相当优秀?
其中重要的一个原因是预训练,相当于人类的通识教育
预训练的文本数据集包括维基百科、书籍、期刊、Reddit链接、Common Crawl和其他数据集,
主要语言为英文,中文只有5%,ChatGPT-3预训练数据量达45TB,参数量1750亿,对应成本也非常高,GPT-3 训练一次的费用是 460 万美元,总训练成本达 1200 万美元
注:参数量指的是模型中需要学习的可调整参数的数量,也就是神经网络中各层之间的连接权重和偏置项的数量之和。在深度学习中,参数量通常是衡量模型规模和容量的重要指标,一般来说参数量越多,模型的表达能力也就越强
ChatGPT应用场景



ChatGPT的优势和限制
ChatGPT的优势包括:
高度的自然语言处理能力:ChatGPT使用了深度学习的方法,可以对自然语言进行高度理解和处理,从而在回答问题和生成文本方面具有很高的准确性和流畅性
大规模预训练模型:ChatGPT使用了大规模预训练模型,能够学习到大量的自然语言数据,从而提高了模型的表现和效果
可扩展性和可定制性:ChatGPT的架构和预训练模型可以轻松地进行扩展和定制,以适应不同的自然语言处理任务和应用场景
ChatGPT的限制包括:
需要大量的数据和计算资源:由于ChatGPT使用了大规模的预训练模型,因此需要大量的数据和计算资源进行训练和调优
对话质量受限于数据质量:ChatGPT的对话质量受限于使用的数据集质量,如果数据集中存在噪声或错误,可能会对模型的表现和效果产生负面影响
存在一定的误差率:尽管ChatGPT的表现很优秀,但由于自然语言处理的复杂性,它仍然存在一定的误差率,需要进行不断的优化和改进
————————————————
下面开始chatgpt注册流程:
一、注册/登录环境要求
1、使用国外的网络环境,即你的网络的IP属于国外(大陆、香港、澳门等地区不可用),日本、美国、印度、韩国等区域亲测可以。
2、一个可以接收验证码的国外手机号,同样地区也是如上述网络环境之外的手机号,使用第三方接码平台。
二、网络环境配置
通过合法合规的科学上网工具进行网络的连接。选择多个地区的节点,如美国、韩国、德国、日本等地区的节点。
三、ChatGPT帐户注册流程
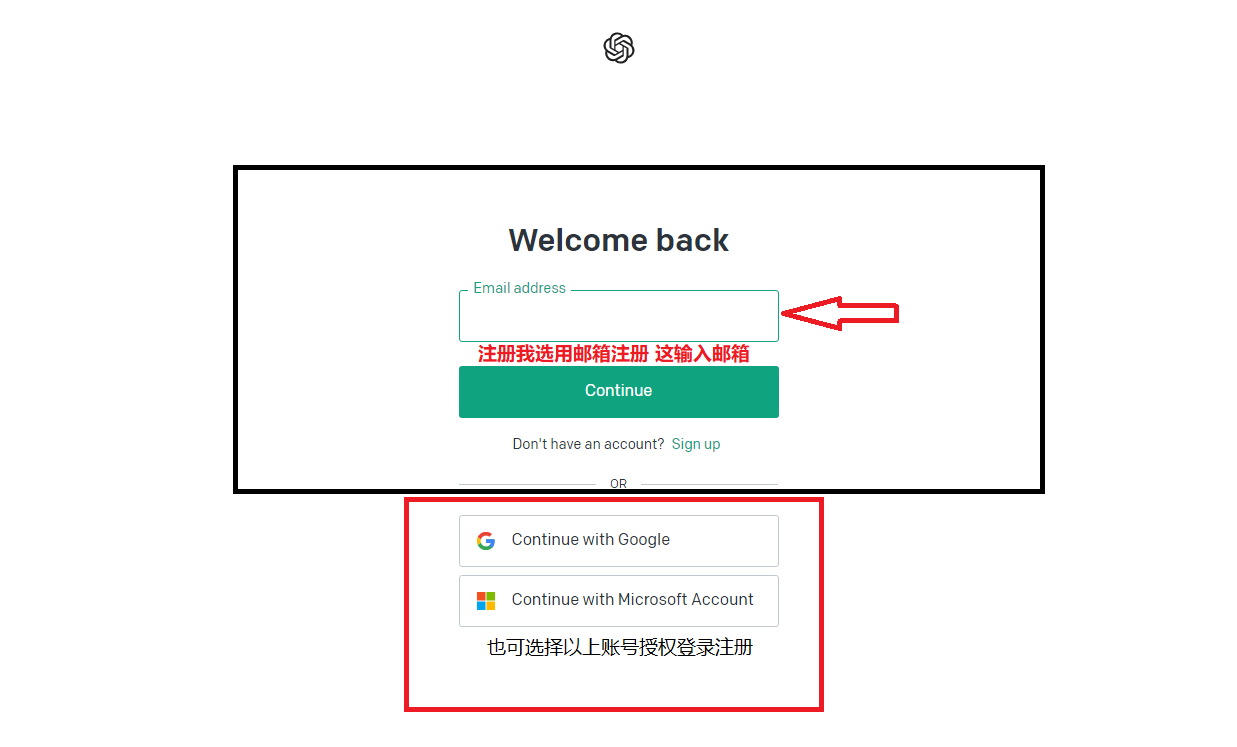
1、打开ChatGPT(chat.openai.com)的官方网站,使用上述所说的网络节点,开全局模式,建议使用谷歌无痕浏览或清理下浏览器cookie再次尝试。然后点击【Sign Up】进入下一步。
2、注册方式为邮箱注册,已有注册微软(Outlook、hotmail邮箱)或谷歌帐号的可直接登录,国内或者其他邮箱地址(QQ)如果出现无法注册,就是被官方限制,请改用国外邮箱注册,如雅虎。

3、设置名称,然后下一步准备进行手机验证,目前国内的手机号都无法注册,这里需要用到虚拟号码进行验证,通过CHatGPT的电话号码验证,这里不支持中国手机号 86的号码验证,所以要填入一个海外号码验证。
注册ChatGPT账号很多小伙伴肯定遇到了一个难点,就是注册一半发现需要国外手机号验证,很多教程推荐的又不靠谱,那怎么办呢?可以参考我的用过的是Tevfans

因为SMS的很多虚拟INdia号码都是滥用的,输入都会因为网络问题而出现 Your account was flagged for potential abuse. If you feel this is an error, please contact us at .help.openai.com. (中文提示:您的帐户被标记为可能存在滥用行为。所以这一步比较难点。
4、输入号码后,ChatGPT会出现最新的人机图案验证,点 开始答题 即可验证完成。


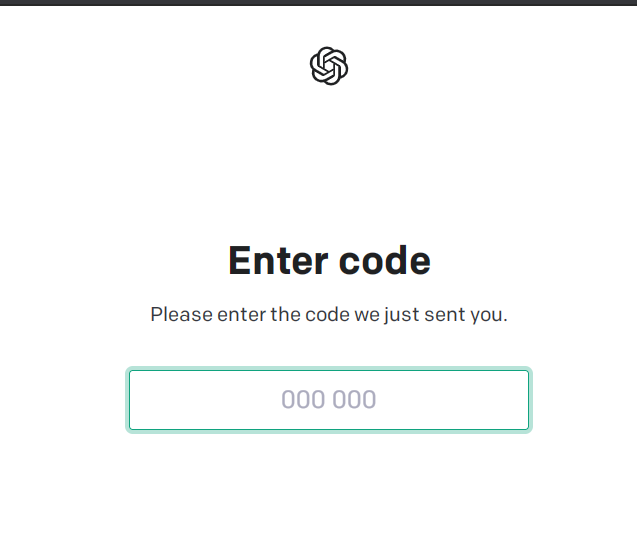
5、验证完成后,你会收到验证码,填进验证框即可,点下一步即可完成ChatGPT的注册了!

⑤ 大约1-2分钟内,会收到验证码(如下图箭头所示),这时我们将验证码输入到OpenAI界面,提交后即注册成功。如果出现没有收到验证码的情况,请重新选择一个国家的号码来收验证码,记得OpenAI手机验证界面要改国家。
PS:以下注册成功进入的是聊天GPT账户,希望生成图片的用户可以访问:labs.openai.com,这是Openai DALL-E,基于文本描述生成图像的系统。

这东西用来学习入门新领域真的无敌,今天之前我完全没接触过人脸识别,通过不断询问问题,拼凑代码,20分钟不到就做出来个能追踪人脸的框还能显示标签的那种。程序debug还可以,英文会好很多,模型已经算顶级了,等迭代一波!如果觉得太折腾很繁琐过不了OpenAI的也可以看看腾讯云这篇笔记:https://share.weiyun.com/5VAf4rF0
四、注册常见问题
1、注册完成后,使用时可能会遇到GPT页面出错的现象,这时过几秒刷新进入就可以,不要退出账号,因为再次登录也很繁琐,可能会遇到地区的限制。
2、如果你的代理比较慢,登录以后就可以把代理关了使用,只有登录的时候会验证 IP,使用过程中没关系。
3、如果注册的时候忘记开全局代理,并且浏览器不是无痕模式,被拒绝访问了,可以重新设置全局并且浏览器用无痕模式(Chrome)或来宾身份浏览(Microsoft Edge)。
五、ChatGPT能做什么
1、生成页面标题、描述。
2、用多个方式改写一段内容,要求不重复并且保留原意。
3、拓展文字内容。
4、做数学题。
5、生成代码。
6、撰写求职信、学习面试技巧。
7、写论文/写歌词/写文章/做视频文案。
常见问题
FAQ
ChatGPT需要人工标注吗
作为一种大规模预训练语言模型,ChatGPT的训练需要依赖大量的无监督文本数据。在模型预训练完成后,如果要将其应用于某个具体任务,比如问答系统、机器翻译等,通常需要用到一些有标注的数据集进行微调。这些标注数据可以通过人工标注获得,也可以通过其他方法生成,如利用规则、自动标注等。因此,ChatGPT在预训练阶段不需要人工标注,但在应用阶段需要借助标注数据进行微调和优化。
ChatGPT训练之后还有什么成本吗
训练一个大型的语言模型像ChatGPT需要大量的计算资源和时间。但是一旦训练完成,部署和使用的成本就相对较低了。部署方面,可以选择在云端或者本地部署,云端部署可以更加灵活和便捷,而本地部署则可以提高一定的安全性和隐私性。
在使用过程中,ChatGPT仍然需要一定的计算资源来运行和生成文本,特别是当输入的序列长度和生成文本的长度增加时,所需的计算资源也会相应增加。此外,如果要对ChatGPT进行微调,需要准备大量的数据和进行反复的实验,这也需要一定的成本。
-
ChatGPT
+关注
关注
29文章
1560浏览量
7597
发布评论请先 登录
相关推荐
ChatGPT:怎样打造智能客服体验的重要工具?
如何评估 ChatGPT 输出内容的准确性
怎样搭建基于 ChatGPT 的聊天系统
如何使用 ChatGPT 进行内容创作
华纳云:ChatGPT 登陆 Windows
大模型LLM与ChatGPT的威廉希尔官方网站 原理
llm模型和chatGPT的区别
用launch pad烧录chatgpt_demo项目会有api key报错的原因?
使用espbox lite进行chatgpt_demo的烧录报错是什么原因?
名单公布!【书籍评测活动NO.34】大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
探索ChatGPT模型的人工智能语言模型





 工商网监
工商网监
评论