 大型语言模型在关键任务和实际应用中的挑战
大型语言模型在关键任务和实际应用中的挑战
大型语言模型的出现极大地推动了自然语言处理领域的进步,但同时也存在一些局限性,比如模型可能会产生看似合理但实际上是错误或虚假的内容,这一现象被称为幻觉(hallucination)。幻觉的存在使得大型语言模型在关键任务和实际应用中的可靠性受到挑战。
模型产生幻觉可能是由于模型缺乏或错误地理解了相关的知识。当人类思考和记忆事物时,本体知识在我们的思维过程中扮演着重要角色。本体知识涉及类别、属性以及它们之间的关系。它帮助我们理解世界、组织和分类信息,并且能够推导出新的知识。对于语言模型,我们可以通过设计探测任务,模型内部的隐含知识和学习偏差。
背景介绍
为了探索大模型在预训练阶段学习到的各类知识,研究者们通过设计探针任务来对这些模型进行测试。通过模型在这些任务上的表现,我们可以了解语言模型在不同方面的学习偏差、错误或限制,并尝试改进模型的性能和可靠性。然而,现有的知识探针主要研究模型对事实性知识的记忆,也就是描述具体事实、属性和关系的知识。比如,我们知道在《西游记》中“孙悟空三打白骨精”,这就是一条具体的事实性知识。
相比事实性知识,本体知识关注类和属性、以及它们之间的关系,能够描述概念之间的层级关系、属性约束等关联,为理解世界知识提供了一种结构化的方式。如下就是一个本体知识图谱,从“孙悟空三打白骨精”这样一条事实性知识,发散出了更多概念之间的关联,包括实例类型(type)、子类(subclass)、子属性(subproperty)、属性领域(domain)和属性范围(range)。
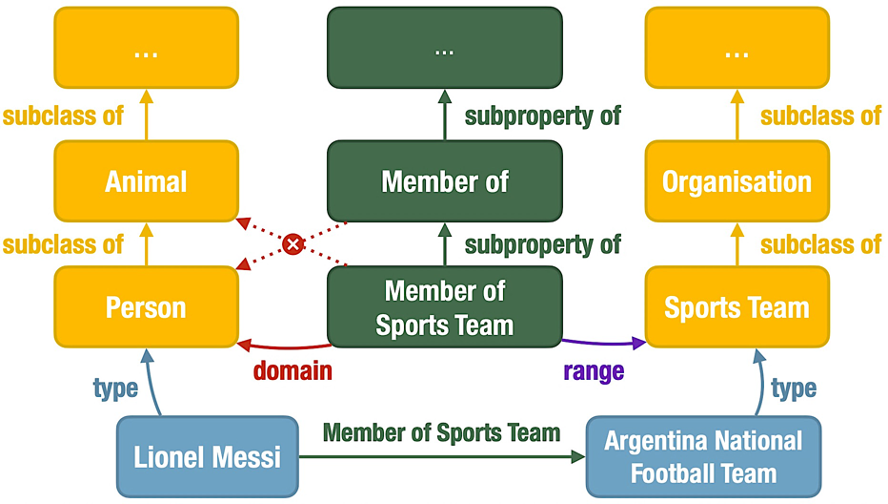
本体知识可以帮助模型更好地理解现实世界中的对象及其关系,在问答等许多 NLP 任务中起着至关重要的作用。因此,探究预训练语言模型是否记忆和理解本体知识,能够拓展学术界对语言模型认知能力的认识,在这个大模型快速发展的时代具有重要意义。
探针方法
我们研究了基于编码器的预训练语言模型 BERT 和 RoBERTa,以及基于解码器的大模型 ChatGPT。对于编码器结构模型,我们使用基于提示词(prompt)的探针方法,探究模型是否能够根据未被遮盖的上下文预测出正确的答案;而对于解码器结构模型,我们则将需要填空的提示词转化成多项选择题,探究模型是否能够给出正确的选择。2.1记忆任务
我们设计了五个记忆任务子测试,每个任务子测试都是为了探测预训练语言模型对于一种本体关系的记忆能力:
1. 给定实例的类型;
2. 给定类的上级类别;
3. 给定属性的上级属性;
4. 给定属性的领域约束;
5. 给定属性的范围约束。
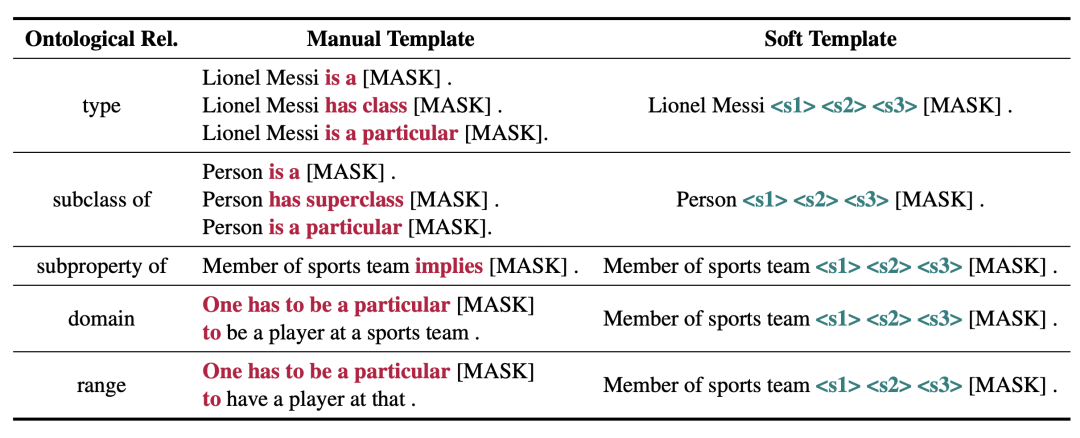
对于 BERT 模型,我们使用人工提示和可训练的软提示(soft prompt)进行探针测试,为每种本体关系设计了如下提示词。模型基于对数概率预测,对候选词进行排序。
2.2推理任务
我们根据资源描述框架模式(Resource Description Framework Schema, RDFS)中规定的规则构建推理任务,每个推理子任务探索预训练语言模型按照一条三段论规则进行推理的能力。对于每个前提,我们区分模型输入中是否明确包含前提,并利用记忆任务的探针结果进一步区分这个前提是否被模型记忆,探究前提的不同形式对模型推理的影响。

为了防止模型通过对假设的记忆而非推理过程得出正确结论,我们使用生造词替换假设提示中包含的特定实例、类和属性。对于编码器结构的模型,我们通过创建没有特殊语义的词嵌入来获得预训练语言模型的生造词。
实验结果与发现
3.1记忆任务
通过对实验数据的分析,我们发现:BERT 和 RoBERTa 模型可以记忆一定的本体知识,但并不完美。
BERT和 RoBERTa 在记忆任务中击败了一个较强的频率基线模型。这表明,在预训练过程中,语言模型不仅学习了关于实体的事实性知识,而且学习了事实背后更加抽象的本体关系,这对于模型更好地组织对于世界的认识至关重要。然而,模型在五个子任务上的准确率还有很大提升空间,表明模型对本体知识记忆的局限性。
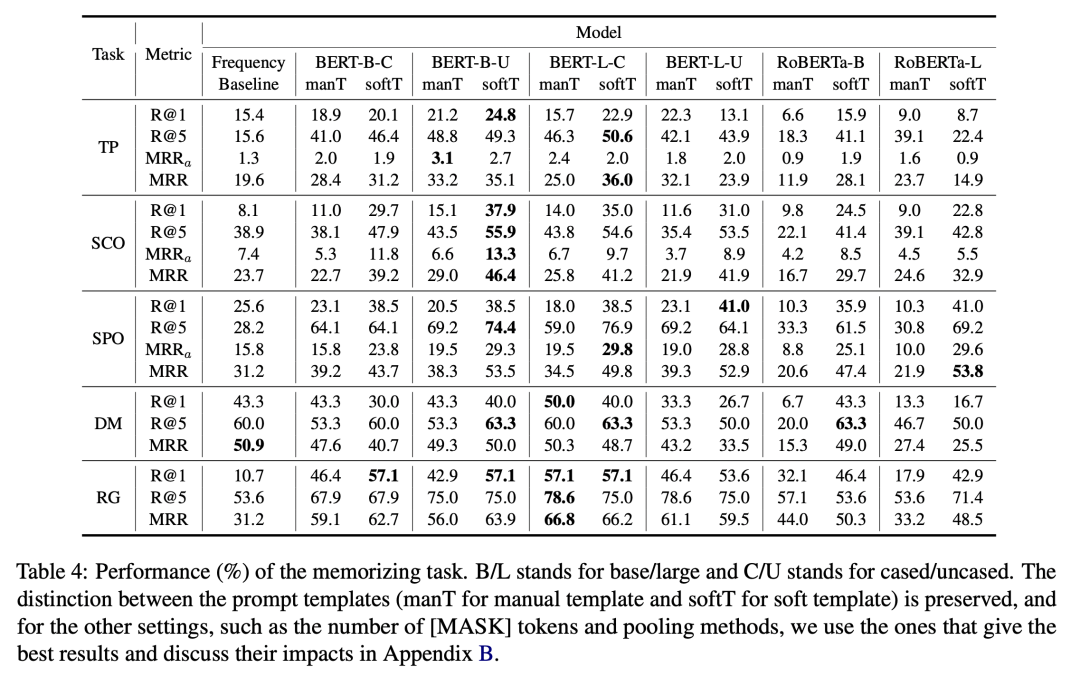
ChatGPT 相比于 BERT 模型,在记忆任务中准确率有了显著提升。
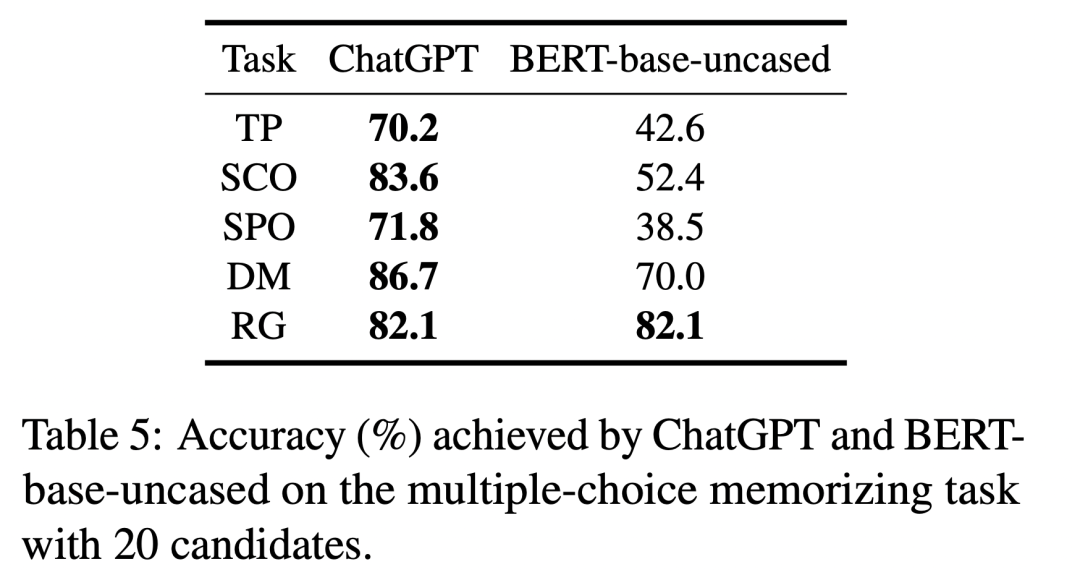
由于多项选择与填空的难度并不直接可比,我们将多项选择形式的提示词输入给 BERT-base-uncased 模型,并与 ChatGPT 进行比较。从下表可以看出,在大多数与本体知识相关的记忆任务中,ChatGPT 在准确性方面明显优于 BERT-base-uncased,展现出更强的本体知识记忆能力。
3.2推理任务
通过对实验数据的分析,我们发现:BERT 和 RoBERTa 模型对本体知识的理解也是比较有限的。
下图展示了对所有推理规则和 BERT 与 RoBERTa 模型取平均之后的推理表现。当输入文本中明确给出 时,模型能够显著提高正确答案的排名。由于 包含了需要预测的正确答案,这就使人怀疑表现的提升并非通过逻辑推理获得的,而是因为模型倾向于预测输入中出现的词及相关词汇。 当前提被隐式给定时,MRR 高于前提末给定时。这意味着一定程度上,预训练语言模型可以利用编码的本体知识,选择正确的推理规则进行推理。但是,所有的前提组合都不能给出近乎完美(MRR 接近 1)的推理表现,说明预训练语言模型对本体知识的理解能力仍具有局限性。
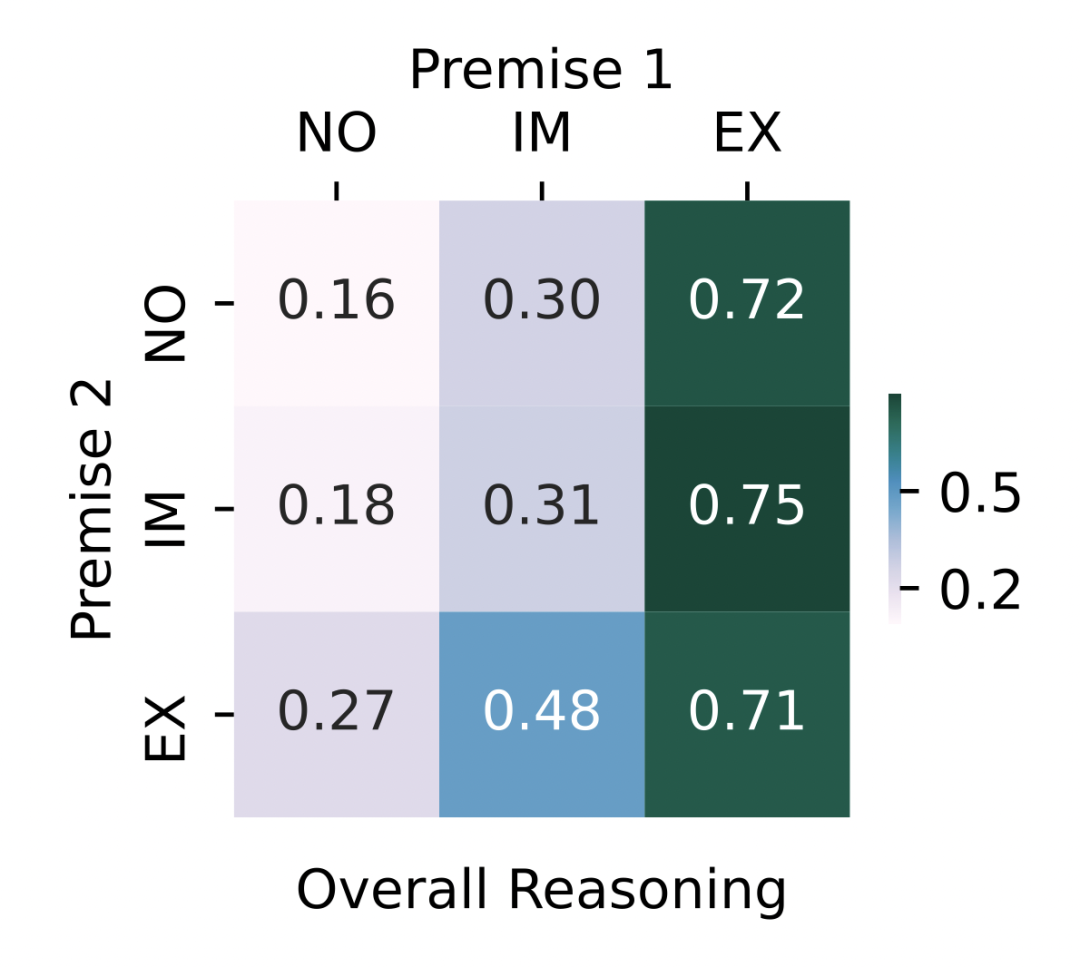
ChatGPT 具有更强大的推理和理解本体知识的能力。
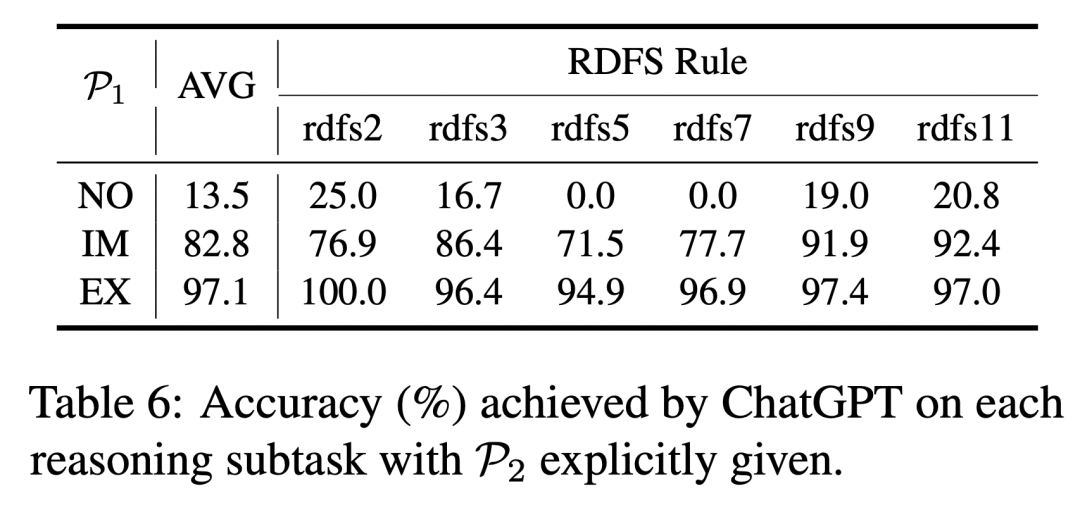
当模型输入或记忆中包含推理前提时,ChatGPT 在各项推理子任务中展现出了很高的准确性。同时,与 BERT-base-uncased 模型相比,ChatGPT 的显式推理能力也更加优秀(97.1% vs 88.2%)。
总结
在本研究中,我们对预训练语言模型是否能够在预训练过程中对本体知识进行有效编码以及是否能够深入理解语义内容进行了全面系统的探讨,发现语言模型确实具备一定的能力来记忆和理解本体知识,并且能够根据这些隐含的知识遵循本体知识推理规则进行一定程度的推理。然而,模型的记忆和推理都具有局限性。同时,ChatGPT 在两个任务上的亮眼表现证明了模型对本体知识的记忆和理解仍具有进一步提升的可能。
责任编辑:彭菁
-
解码器
+关注
关注
9文章
1143浏览量
40725 -
数据
+关注
关注
8文章
7010浏览量
88972 -
语言模型
+关注
关注
0文章
522浏览量
10271 -
自然语言处理
+关注
关注
1文章
618浏览量
13554 -
大模型
+关注
关注
2文章
2436浏览量
2662
原文标题:ACL 2023杰出论文 | 探测语言模型对本体知识的记忆与理解
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》
【大语言模型:原理与工程实践】核心威廉希尔官方网站 综述
【大语言模型:原理与工程实践】大语言模型的基础威廉希尔官方网站
【大语言模型:原理与工程实践】大语言模型的评测
【大语言模型:原理与工程实践】大语言模型的应用
基因组学大型语言模型在多项任务中均展现出卓越的性能和应用扩展空间
大型语言模型能否捕捉到它们所处理和生成的文本中的语义信息

大型语言模型的应用
大语言模型推断中的批处理效应

FP8数据格式在大型模型训练中的应用






 工商网监
工商网监
评论