 一个用于周视语义占用网格感知的基准测试
一个用于周视语义占用网格感知的基准测试
摘要
语义占用网格感知对于自动驾驶至关重要,因为自动驾驶车辆需要对3D城市场景进行细粒度感知。然而,现有的相关基准测试在城市场景的多样性方面存在不足,并且仅评估前视预测感知。为了全面评估周视感知算法,我们提出了OpenOccupancy,这是第一个用于周视语义占用网格感知的基准测试方法。在OpenOccupancy基准测试中,我们通过添加稠密的语义占用网格标注来扩展大规模的nuScenes数据集。以前的标注依赖于LiDAR点云的叠加,由于LiDAR数据的稀疏,导致一些占用标签被遗漏。为了缓解这个问题,我们引入了增强与净化(AAP)流程,将标注密度提高了约2倍,其中涉及约4000个人工小时的标注过程。此外为OpenOccupancy基准测试建立了基于摄像头、LiDAR和多模态的基线模型。此外考虑到周视占用感知的复杂性在于高分辨率3D预测的计算负担,我们提出了级联占用网络(CONet)来改进粗糙预测,相对于基线模型提高了约30%的性能。我们希望OpenOccupancy基准测试能促进周视占用感知算法的发展。
主要贡献
尽管目前对于语义占用网格感知越来越受到关注,但大多数相关基准都是针对室内场景设计的,SemanticKITTI 将占用感知扩展到驾驶场景,但其数据集规模相对较小且多样性有限,这影响了开发占用感知算法的泛化和评估。此外,SemanticKITTI只评估前视图的占用网格结果,而对于安全驾驶而言,周视感知更为关键。为解决这些问题,我们提出了OpenOccupancy,这是第一个用于周视语义占用感知的基准。在OpenOccupancy基准中引入了nuScenes-Occupancy,它将大规模的nuScenes数据集与密集的语义占用标注相结合。
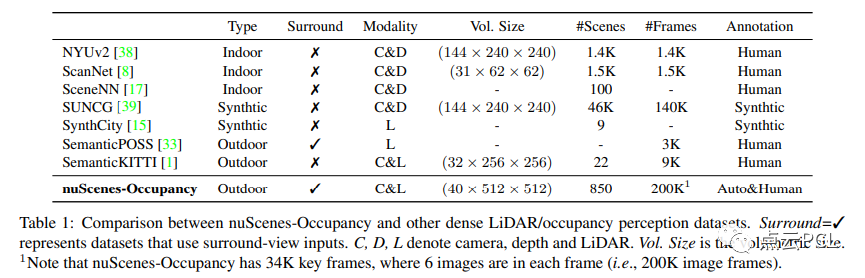
如表1所示,nuScenes-Occupancy标注的场景和帧数比多约40倍和20倍。值得注意的是,通过人工直接标注大规模的占用标签几乎是不现实的。因此引入了Augmenting And Purifying (AAP)流程,以高效地标注和稠密的占用标签。

图1:nuScenes-Occupancy为nuScenes数据集中的所有关键帧提供了稠密的语义占用网格标签,在这里展示了标注的地面真值,体积大小为(40 × 512 × 512),网格大小为0.2米。
图1展示了稠密标注的可视化效果。为了促进未来研究,我们在OpenOccupancy基准中建立了基于相机、基于LiDAR和多模式的基线。实验结果显示,基于相机的方法在小物体(如自行车、行人、摩托车)方面表现更好,而基于LiDAR的方法在大型结构区域(如行驶表面、人行道)方面表现更优。值得注意的是,多模式基线通过自适应融合两种模态的中间特征,相对提高了基于相机和基于LiDAR方法的整体性能,分别提升了47%和29%。考虑到周围占用感知的计算负担,所提出的基线只能生成低分辨率的预测。为了实现高效的占用感知,我们提出了级联占用网络(CONet),在所提出的基线之上构建了一个从粗糙到精细的流程,相对提高了性能约30%。主要贡献总结如下:
提出了OpenOccupancy,这是第一个针对驾驶场景中周围占用感知的基准。
通过nuScenes数据集引入了AAP流程,它高效地标注和稠密化了周围语义占用标签,结果形成了第一个用于周围语义占用分割的数据集nuScenes-Occupancy。
我们在OpenOccupancy基准上建立了基于相机、基于LiDAR和多模式的基线。此外,我们引入了CONet来减轻高分辨率占用预测的计算负担,相对提高了基线性能约30%。
主要内容
周视语义占用网格感知
周视语义占用感知是指生成场景的完整3D表示,包括体积占用和语义标签,与前视图感知的单目范例不同,周视占用感知算法旨在在周围视图的驾驶场景中生成语义占用,具体而言,给定360度的输入Xi(例如LiDAR扫描或周围视图图像),感知算法需要预测周围的占用标签F(Xi) ∈ R D×H×W,其中D、H、W是整个场景的体积大小。值得注意的是,周视图的输入范围比前视觉传感器覆盖的范围大约多了5倍,因此,周视占用网格感知的核心挑战在于高效构建高分辨率的占用表示。
nuScenes-Occupancy
SemanticKITTI 是首个用于室外占据感知的数据集,但在驾驶场景方面缺乏多样性,并且仅评估前视感知,为了创建一个大规模的环境占据感知数据集,我们引入了nuScenes-Occupancy,它在nuScenes数据集的基础上添加了稠密的语义占用标注。作者引入了AAP(Augmenting And Purifying)流程来高效地标注和密集化占据标签。
整个AAP流程如算法1所示。

如图2所示,伪标签对初始标注是补充的,而增强和纯化标签更密集和精确,值得注意的是增强和纯化标注中每个帧中约有40万个占据体素,比初始标注密集了约2倍。总之,nuScenes-Occupancy包含28130个训练帧和6019个验证帧,在每个帧中对占据的体素分配了17个语义标签。
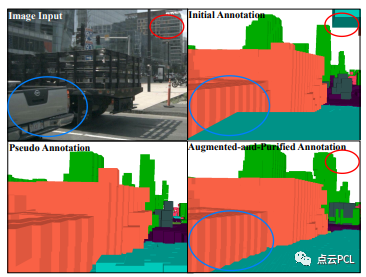
图2:初始标注、伪标注和增强纯化标注之间的对比,红圈和蓝圈突出显示增强标注更加密集和准确的区域。
OpenOccupancy基线
大多数现有的占据感知方法都是为前视感知而设计的,为了将这些方法扩展到周围的占据感知,需要对每个相机视角的输入进行单独处理,这是低效的。此外,两个相邻输出的重叠区域可能存在不一致性,为了缓解这些问题,我们建立了一致地从360度输入(例如LiDAR扫描或环视图像)中学习周围语义占据的基线,具体而言,为OpenOccupancy基准提出了基于相机的、基于LiDAR的和多模态的基线,如图3所示。
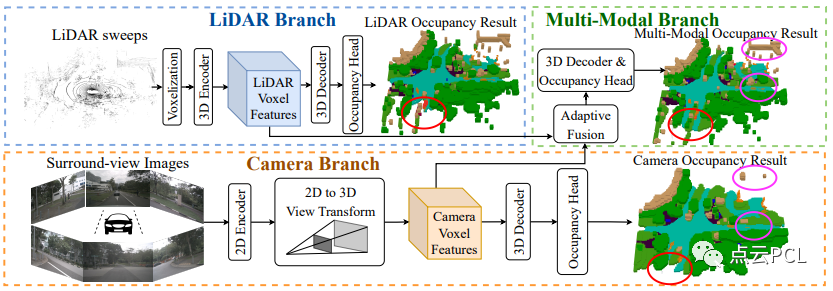
图3:三种提出的基线的整体架构,LiDAR分支利用3D编码器提取体素化的LiDAR特征,相机分支使用2D编码器学习环视图特征,然后将其转换为生成3D相机体素特征,在多模态分支中,自适应融合模块动态地集成两种模态的特征。所有三个分支都利用3D解码器和占据头来产生语义占据,在占据结果图中,红色和紫色圈圈标示出多模态分支可以生成更完整和准确的预测。
实验
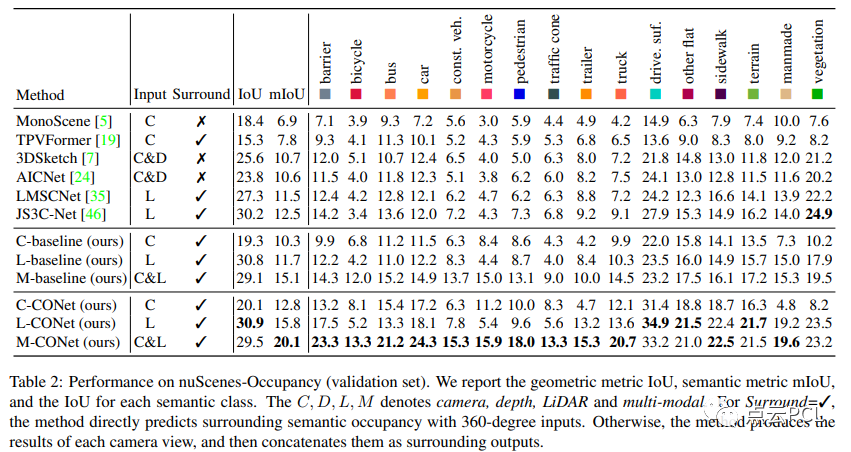
在OpenOccupancy基准测试中,基于nuScenes-Occupancy评估周围语义占据感知性能,对提出的基线、CONet和现代占据感知算法进行全面实验。所有模型在8个A100 GPU上以8个批次大小进行训练,共训练24个时期。利用OpenOccupancy基准测试,我们分析了六种现代方法(MonoScene ,TPVFormer,3DSketch ,AICNet ,LMSCNet,JS3C-Net )以及提出的基线和CONet的周围占据感知性能,从表2的结果可以看出:
与单视图方法相比,周围占据感知范式表现出更好的性能。
提出的基线对周围占据感知具有适应性和可扩展性。
相机和LiDAR的信息相互补充,多模态基线显著提高了性能。
周视占据感知的复杂性在于高分辨率3D预测的计算负担,这可以通过提出的CONet来减轻。
这里提供可视化结果(见图5)来验证CONet可以基于粗糙预测生成精细的占据网格结果。
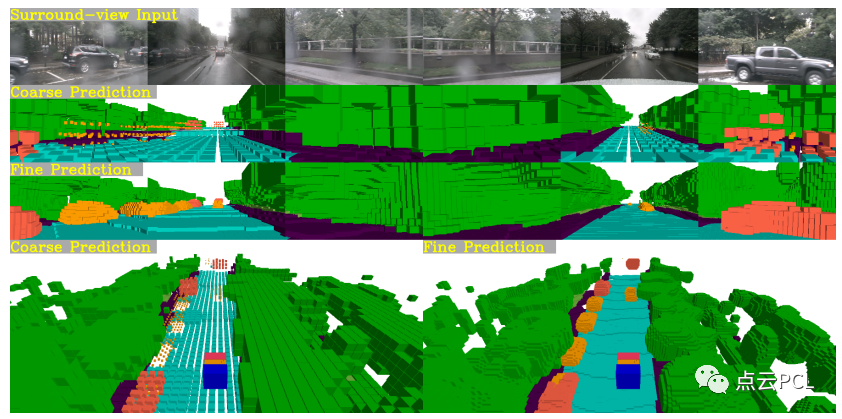
图5:语义占据预测的可视化,第1行是周视图像。第2行和第3行显示了由多模态基线和多模态CONet生成的相机视图的粗糙和精细占据,第4行比较了它们的全局视图预测。
总结
本文提出了OpenOccupancy,这是首个用于驾驶场景中周视语义占据感知的基准测试,具体而言引入了nuScenes-Occupancy,它基于提出的AAP流水线扩展了nuScenes数据集,带有稠密的语义占据标注,在OpenOccupancy基准测试中建立了基于相机、基于LiDAR和多模态的基线。此外还提出了CONet来减轻高分辨率占据预测的计算负担。在OpenOccupancy基准测试中进行了全面的实验,结果显示基于相机和基于LiDAR的基线相互补充,而多模态基线进一步提高了性能,分别提高了47%和29%。此外所提出的CONet相对于基线提高了约30%,并且延迟开销最小。我们希望OpenOccupancy基准测试对于周视语义占据感知的发展有所帮助。
审核编辑:刘清
-
传感器
+关注
关注
2550文章
51050浏览量
753174 -
编码器
+关注
关注
45文章
3639浏览量
134444 -
视觉传感器
+关注
关注
3文章
249浏览量
22876 -
自动驾驶
+关注
关注
784文章
13787浏览量
166408 -
LiDAR芯片
+关注
关注
1文章
17浏览量
3211
原文标题:OpenOccupancy:一个用于周视语义占用网格感知的基准测试
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
未来已来,多传感器融合感知是自动驾驶破局的关键
集成语义和多Agent 的网格资源发现模型
基于语义与事务属性的QoS感知的服务优化选择
基于语义的文本语义分析
一套全新的手机系统测试基准
如何使用语义感知来进行图像美学质量评估的方法






 工商网监
工商网监
评论