 基于生成模型的预训练方法
基于生成模型的预训练方法
I实验
总结
参考
前言
 请添加图片描述
请添加图片描述
我们这次要介绍的文章被接收在 ICCV 2023 上,题为:DreamTeacher: Pretraining Image Backbones with Deep Generative Models,我认为是个挺强挺有趣的自监督方面的工作。DreamTeacher 用于从预训练的生成网络向目标图像 Backbone 进行知识蒸馏,作为一种通用的预训练机制,不需要标签。这篇文章中研究了特征蒸馏,并在可能有任务特定标签的情况下进行标签蒸馏,我们会在后文详细介绍这两种类型的知识蒸馏。
事实上,之前已经在 GiantPandaCV 上介绍过一种 diffusion 去噪自监督预训练方法:DDeP,DDeP 的设计简单,但去噪预训练的方法很古老了。然而,DreamTeacher 开创了如何有效使用优质的生成式模型蒸馏获得相应的知识。
补充:在 DDeP 这篇文章中,经过读者纠正,我们重新表述了加噪公式:
相关工作
Discriminative Representation Learning
最近比较流行的处理方法是对比表示学习方法,SimCLR 是第一个在线性探测和迁移学习方面表现出色的方法,而且没有使用类标签,相较于监督预训练方法。随后的工作,如 MoCo,通过引入 memory bank 和梯度停止改进了孪生网络设计。然而,这些方法依赖于大量的数据增强和启发式方法来选择负例,可能不太适用于像 ImageNet 这样规模的数据集。关于 memory bank 的概念,memory bank 是 MoCo 中的一个重要组件,用于存储模型的特征向量。在 MoCo 的训练过程中,首先对一批未标记的图像进行前向传播,得到每个图像的特征向量。然后,这些特征向量将被存储到内存库中。内存库的大小通常会比较大,足够存储许多图像的特征。训练过程的关键部分是建立正负样本对。对于每个样本,其特征向量将被视为查询向量(Query),而来自内存库的其他特征向量将被视为候选向量(Candidate)。通常情况下,查询向量和候选向量来自同一张图片的不同视角或数据增强的版本。然后,通过比较查询向量与候选向量之间的相似性来构建正负样本对。此外,还有一些其他方法和概念,我们就不在这篇解读文章中介绍了。
Generative Representation Learning
DatasetGAN 是最早展示预训练 GAN 可以显著改善感知任务表现的研究之一,特别是在数据标记较少的情况下。SemanticGAN 提出了对图像和标签的联合建模。推理过程首先将测试图像编码为 StyleGAN 的潜在空间,然后使用任务头部解码标签。DDPM-seg 沿着这一研究方向,但使用了去噪扩散概率模型(DDPMs)代替 StyleGAN。这篇文章继续了这一研究方向,但重点放在从预训练的生成模型中,特别是扩散模型,向下游图像主干中提取知识,作为一种通用的预训练方式。
关于相关工作部分中涉及到的方法,如果有疑惑的推荐阅读原文(链接在文末)。
DreamTeacher 框架介绍
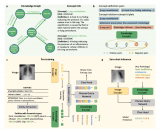
DreamTeacher 框架能在两种场景下的工作:无监督表示学习和半监督学习。在无监督表示学习中,预训练阶段没有可用的标签信息,而在半监督学习中,只有部分数据拥有标签。框架使用训练好的生成模型 G 来传递其学到的表示知识到目标图像主干 f。无论在哪种场景下,框架的训练方法和所选的生成模型 G 与图像主干 f 的选择都是一样的。首先,它创建一个包含图像和相应特征的特征数据集 。然后,通过将生成模型的特征传递到图像主干 f 的中间特征中来训练图像主干 f。作者特别关注使用卷积主干 f 的情况,而对 Transformer 的探索留给未来的研究。
Unsupervised Representation Learning
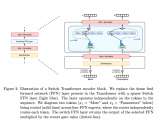
对于无监督表示学习,给定一个特征数据集 D,在图像主干 f 的不同层次上附加特征回归器,以回归出对应的生成特征 从图像 中。我们首先如何讨论创建特征数据集,然后设计特征回归器,最后介绍蒸馏目标。创建特征数据集 D 的方法有两种。一种是通过从生成模型 G 中采样图像,并记录生成过程中提取的中间特征来创建合成数据集。这种方法可以合成无限大小的数据集,但可能会出现 mode dropping(生成模型可能没有学习到分布的某些部分)的问题。另一种方法是将实际图像通过编码过程编码到生成模型 G 的潜在空间中,然后记录生成过程中提取的中间特征,创建编码数据集。合成数据集适用于采样速度快、无法编码真实图像的生成模型(如 GAN),而编码数据集适用于具有编码器网络的生成模型(如 VAE)和扩散模型。这两种方法的特征数据集可以在离线预先计算,也可以在训练过程中在线创建,以实现快速的内存访问和高效的样本生成和删除,从而适用于任何大小的数据集和特征预训练,同时增加下游Backbone 网络的鲁棒性。DreamTeacher 框架的整体流程如下图所示,图里表示创建特征数据集 D 使用的是第二种方法。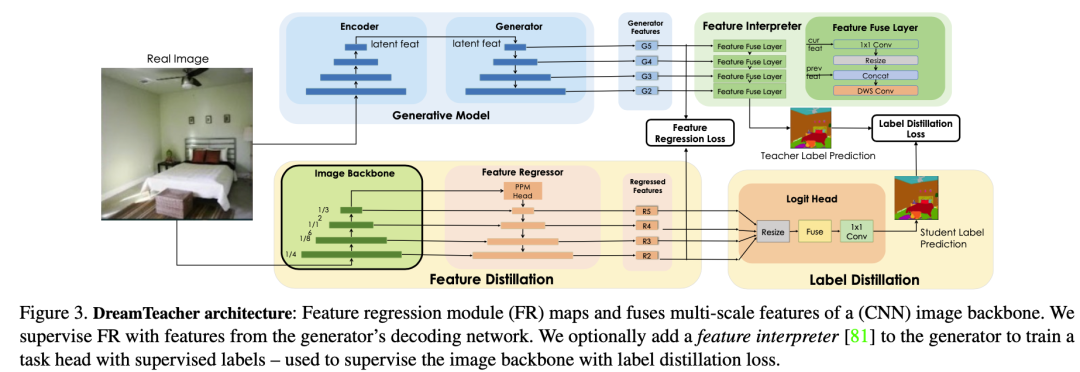 为了将生成式表示 蒸馏到通用主干 f 中,设计了一个特征回归器模块,将图像主干的多层特征映射并对齐到生成式特征上。受到 Feature Pyramid Network(FPN)的设计启发,特征回归器采用自顶向下的架构,并使用侧向跳线连接来融合主干特征,并输出多尺度特征。在图像主干的最后一层之前应用了类似于 PSPNet 中的金字塔池化模块(PPM),上图(底部)直观地描述了这个架构。接下来,我们关注如何做特征蒸馏的。将编码器 f 的不同级别的中间特征表示为 ,对应的特征回归器输出为 。使用一个 1×1 的卷积来匹配 和 的通道数,如果它们不同的话。特征回归损失非常简单,受到 FitNet 的启发,它提出了通过模拟中间特征激活将教师网络上的知识蒸馏到学生网络上:
为了将生成式表示 蒸馏到通用主干 f 中,设计了一个特征回归器模块,将图像主干的多层特征映射并对齐到生成式特征上。受到 Feature Pyramid Network(FPN)的设计启发,特征回归器采用自顶向下的架构,并使用侧向跳线连接来融合主干特征,并输出多尺度特征。在图像主干的最后一层之前应用了类似于 PSPNet 中的金字塔池化模块(PPM),上图(底部)直观地描述了这个架构。接下来,我们关注如何做特征蒸馏的。将编码器 f 的不同级别的中间特征表示为 ,对应的特征回归器输出为 。使用一个 1×1 的卷积来匹配 和 的通道数,如果它们不同的话。特征回归损失非常简单,受到 FitNet 的启发,它提出了通过模拟中间特征激活将教师网络上的知识蒸馏到学生网络上:
在这里,W 是一个不可学习的白化算子,使用 LayerNorm 实现,用于对不同层次上的特征幅值进行归一化。层数 l = {2, 3, 4, 5},对应于相对于输入分辨率的 步长处的特征。
此外,这篇文章还探索了基于激活的注意力转移(AT)目标。AT 使用一个运算符 ,对空间特征的每个维度生成一个一维的“注意力图”,其中 |Ai| 表示特征激活 A 在通道维度 C 上的绝对值和。这种方法相比直接回归高维特征可以提高收敛速度。具体来说,AT 损失函数如下:
其中分别是回归器和生成模型在第 l 层中的特征的矢量形式中的第 j 对。
最后,综合特征回归损失为:
Label-Guided Representation Learning
 在这里插入图片描述
在这里插入图片描述
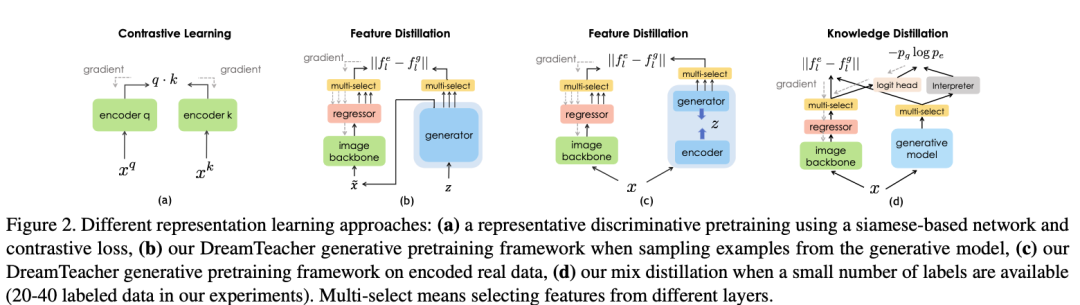
在半监督设置中,在预训练阶段在冻结的生成网络 G 之上训练了一个任务相关的分支,称为特征解释器,采用 DatasetGAN 的方法进行监督训练。与 DatasetGAN 合成用于训练下游任务网络的带标签数据集不同,DreamTeacher 改用软标签蒸馏,即在编码和合成的数据集中都包含了预测的软标签,也就是特征数据集 D 中包含了软标签。这在上图(d)中进行了可视化。
这篇文章探索了使用分割标签对解释器分支进行训练(半监督情景下),并使用交叉熵和 Dice 目标的组合来训练:
其中是特征解释器的权重,y 是任务标签。H(·, ·) 表示像素级的交叉熵损失,D(·, ·) 表示 Dice Loss。
对于标签蒸馏,使用以下损失函数:
其中 和 分别是特征解释器和目标图像主干 f 的 logits。H 是交叉熵损失,而 τ 是温度参数。
将标签蒸馏目标与特征蒸馏目标相结合,得到混合损失函数:
使用混合蒸馏损失对预训练数据集中的所有图像进行预训练,无论是带标签还是无标签的。带标签的标签仅用于训练特征解释器,而 DreamTeacher 只使用特征解释器生成的软标签对图像主干 f 进行蒸馏预训练。
实验
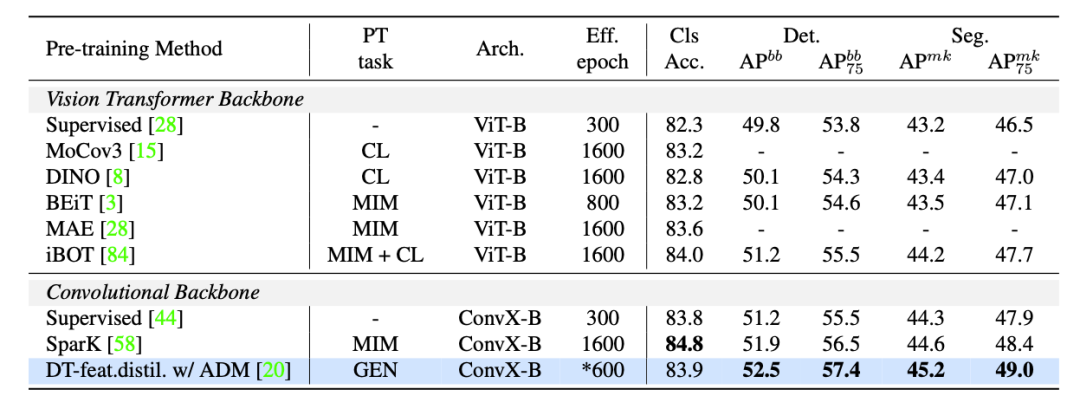
在实验中,使用的生成模型包含:unconditional BigGAN、ICGAN、StyleGAN2;对于基于扩散的模型,使用了 ADM 和 stable diffusion 模型。使用的数据集包含:bdd100k、ImageNet-1k(IN1k-1M)、LSUN 和 ffhq。下表将 DreamTeacher 与 ImageNet 和 COCO 上的自监督学习的 SOTA 方法进行比较:
 在这里插入图片描述
在这里插入图片描述
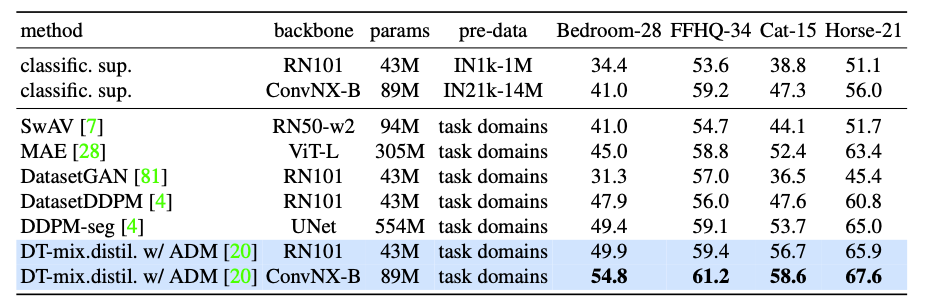
对于 Label-efficient 的语义分割 benchmark。下表将 DreamTeacher与各种表示学习基线进行比较。
 下图是使用 DreamTeacher 特征蒸馏预训练的 ConvNX-B 模型在 LSUN-cat 无标签图像上的定性结果。
下图是使用 DreamTeacher 特征蒸馏预训练的 ConvNX-B 模型在 LSUN-cat 无标签图像上的定性结果。
在这里插入图片描述
总结
这篇文章的研究聚焦于提出一种名为 DreamTeacher 的框架,旨在从生成模型向目标图像 Backbone 传递知识(知识蒸馏)。在这个框架下,进行了多个实验,涵盖了不同的 settings ,包括生成模型、目标图像 Backbone 和评估 benchmark。其目标是探究生成式模型在大规模无标签数据集上学习语义上有意义特征的能力,并将这些特征成功地传递到目标图像 Backbone 上。
通过实验,这篇文章发现使用生成目标的生成网络能够学习到具有意义的特征,这些特征可以有效地应用于目标图像主干。与现有自监督学习方法相比,这篇文章基于生成模型的预训练方法表现更为优异,这些 benchmark 测试包括 COCO、ADE20K 和 BDD100K 等。
这篇文章的工作为生成式预训练提供了新的视角和方法,并在视觉任务中充分利用了生成模型。在近两年的论文中,生成式预训练威廉希尔官方网站 是一个比较有趣的方向。
责任编辑:彭菁
-
图像
+关注
关注
2文章
1084浏览量
40455 -
模型
+关注
关注
1文章
3229浏览量
48813 -
网络设计
+关注
关注
0文章
14浏览量
7778 -
数据集
+关注
关注
4文章
1208浏览量
24691
原文标题:ICCV 2023:探索基于生成模型的 Backbone 预训练
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】大语言模型的预训练
微软在ICML 2019上提出了一个全新的通用预训练方法MASS

新的预训练方法——MASS!MASS预训练几大优势!

检索增强型语言表征模型预训练
一种侧重于学习情感特征的预训练方法

介绍几篇EMNLP'22的语言模型训练方法优化工作
基于医学知识增强的基础模型预训练方法
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?

混合专家模型 (MoE)核心组件和训练方法介绍





 工商网监
工商网监
评论