 智能计算中心规划建设指南
智能计算中心规划建设指南
传统的云数据中心网络一般是基于对外提供服务的流量模型而设计的,流量主要是从数据中心到最终客户,即以南北向流量为主,云内部东西向流量为辅。承载 VPC 网络的底层物理网络架构,对于承载智算业务存在如下挑战。
本文选自“智算中心网络架构白皮书(2023)”“智能计算中心规划建设指南”,对传统网络与智算网络、两层胖树、三次胖树及全面的分析对比,并介绍了组网最佳实践。
有阻塞网络:考虑到并非所有服务器都会同时对外产生流量,为了控制网络建设成本, Leaf 交换机的下联带宽和上联带宽并非按照 1:1 设计,而是存在收敛比。一般上联带宽仅有下联带宽的三分之一。
云内部流量时延相对较高:跨 Leaf 交换机的两台服务器互访需要经过 Spine 交换机,转发路径有 3 跳。
带宽不够大:一般情况下单物理机只有一张网卡接入 VPC 网络,单张网卡的带宽比较有限,当前较大范围商用的网卡带宽一般都不大于 200Gbps。
对于智算场景,当前比较好的实践是独立建一张高性能网络来承载智算业务,满足大带宽,低时延,无损的需求。
大带宽的设计
智算服务器可以满配 8 张 GPU 卡,并预留 8 个 PCIe 网卡插槽。在多机组建 GPU 集群时,两个 GPU 跨机互通的突发带宽有可能会大于 50Gbps。因此,一般会给每个 GPU 关联一个至少 100Gbps 的网络端口。在这种场景下可以配置 4张 2*100Gbps 的网卡,也可以配置 8 张 1*100Gbps 的网卡,当然也可以配置 8 张单端口 200/400Gbps 的网卡。

无阻塞设计
无阻塞网络设计的关键是采用 Fat-Tree(胖树)网络架构。交换机下联和上联带宽采用 1:1 无收敛设计,即如果下联有64 个 100Gbps 的端口,那么上联也有 64 个 100Gbps 的端口。
此外交换机要采用无阻塞转发的数据中心级交换机。当前市场上主流的数据中心交换机一般都能提供全端口无阻塞的转发能力。
低时延设计 AI-Pool
在低时延网络架构设计方面,百度智能云实践和落地了基于导轨(Rail)优化的AI-Pool 网络方案。在这个网络方案中,8 个接入交换机为一组,构成一个 AI-Pool。以两层交换机组网架构为例,这种网络架构能做到同 AI-Pool 的不同智算节点的 GPU 互访仅需一跳。
在 AI-Pool 网络架构中,不同智算节点间相同编号的网口需要连接到同一台交换机。如智算节点 1 的 1 号 RDMA 网口,智算节点 2 的 1 号 RDMA 网口直到智算节点 P/2 的 1 号 RDMA 网口都连到 1 号交换机。
在智算节点内部,上层通信库基于机内网络拓扑进行网络匹配,让相同编号的 GPU 卡和相同编号的网口关联。这样相同GPU 编号的两台智算节点间仅一跳就可互通。
不同GPU编号的智算节点间,借助NCCL通信库中的Rail Local威廉希尔官方网站 ,可以充分利用主机内GPU间的NVSwitch的带宽,将多机间的跨卡号互通转换为跨机间的同GPU卡号的互通。
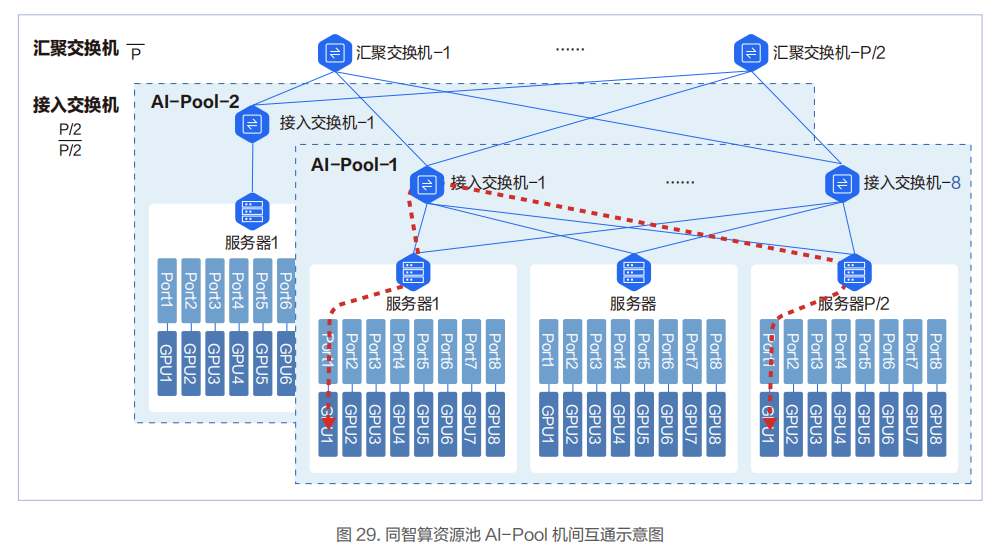
对于跨 AI-Pool 的两台物理机的互通,需要过汇聚交换机,此时会有 3 跳。
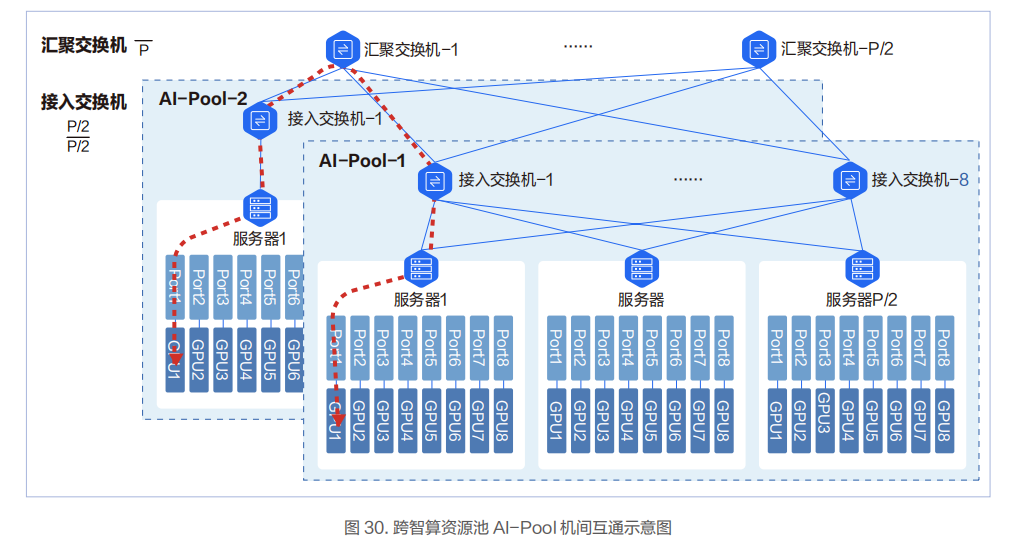
网络可承载的 GPU 卡的规模和所采用交换机的端口密度、网络架构相关。网络的层次多,承载的 GPU 卡的规模会变大,但转发的跳数和时延也会变大,需要结合实际业务情况进行权衡。
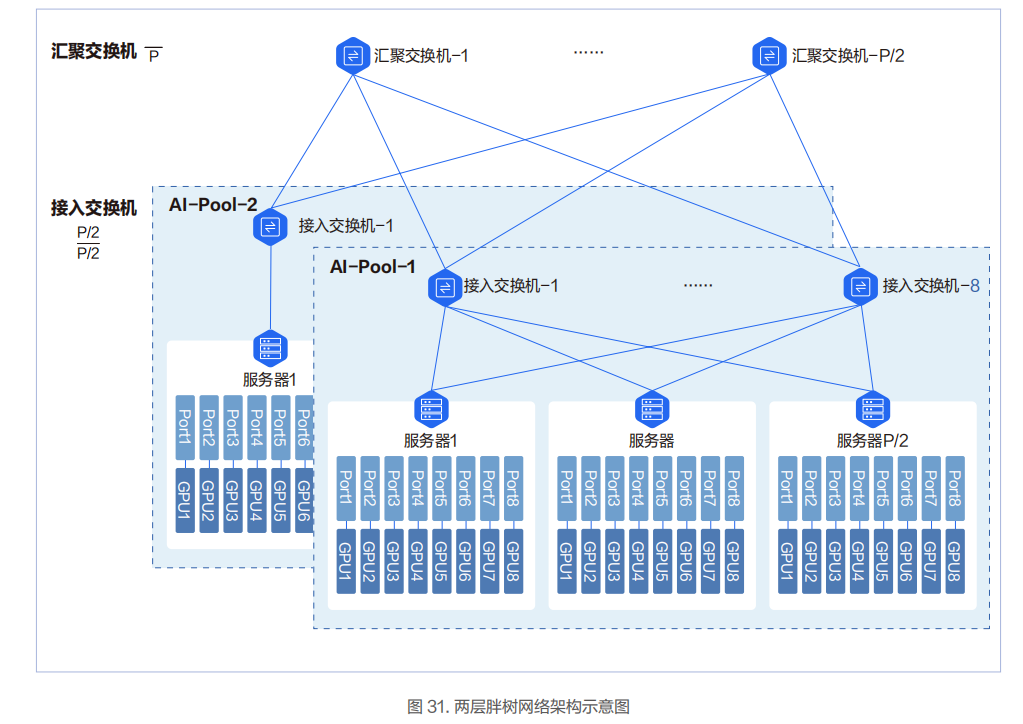
两层胖树架构
8 台接入交换机组成一个智算资源池 AI-Pool。图中 P 代表单台交换机的端口数。单台交换机最大可下联和上联的端口为P/2 个,即单台交换机最多可以下联 P/2 台服务器和 P/2 台交换机。两层胖树网络可以接入 P*P/2 张 GPU 卡。
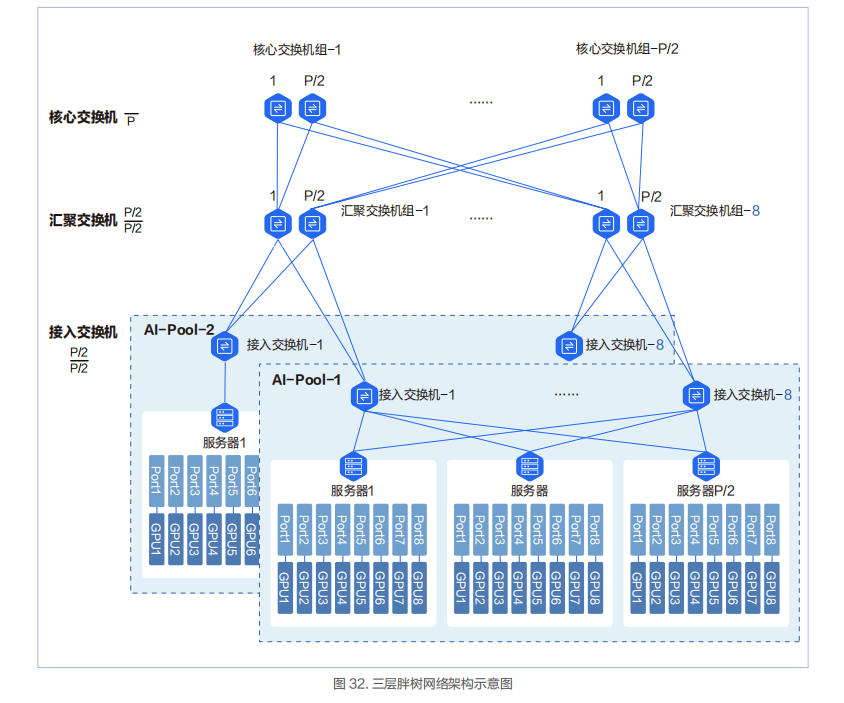
三层胖树架构
三层网络架构中会新增汇聚交换机组和核心交换机组。每个组里面的最大交换机数量为 P/2。汇聚交换机组最大数量为 8,核心交换机组的最大数量为 P/2。三层胖树网络可以接入 P*(P/2)*(P/2)=P*P*P/4 张 GPU 卡。
在三层胖树组网中,InfiniBand 的 40 端口的 200Gbps HDR 交换机能容纳的最多 GPU 数量是 16000。这个 16000GPU 卡的规模也是目前 InfiniBand 当前在国内实际应用的 GPU 集群的最大规模网络,当前这个记录被百度保持。
两层和三层胖树网络架构的对比
可容纳的 GPU 卡的规模
两层胖树和三层胖树最重要的区别是可以容纳的 GPU 卡的规模不同。在下图中 N 代表 GPU 卡的规模,P 代表单台交换机的端口数量。比如对于端口数为 40 的交换机,两层胖树架构可容纳的 GPU 卡的数量是 800 卡,三层胖树架构可容纳的 GPU 卡的数量是 16000 卡。

转发路径
两层胖树和三层胖树网络架构另外一个区别是任意两个节点的网络转发路径的跳数不同。
对于同智算资源池 AI-Pool 的两层胖树架构,智算节点间同 GPU 卡号转发跳数为 1 跳。智算节点间不同 GPU 卡号在没有做智算节点内部 Rail Local 优化的情况下转发跳数为 3 跳。
对于同智算资源池 AI-Pool 的三层胖树架构,智算节点间同 GPU 卡号转发跳数为 3 跳。智算节点间不同 GPU 卡号在没有做智算节点内部 Rail Local 优化的情况下转发跳数为 5 跳。

典型实践
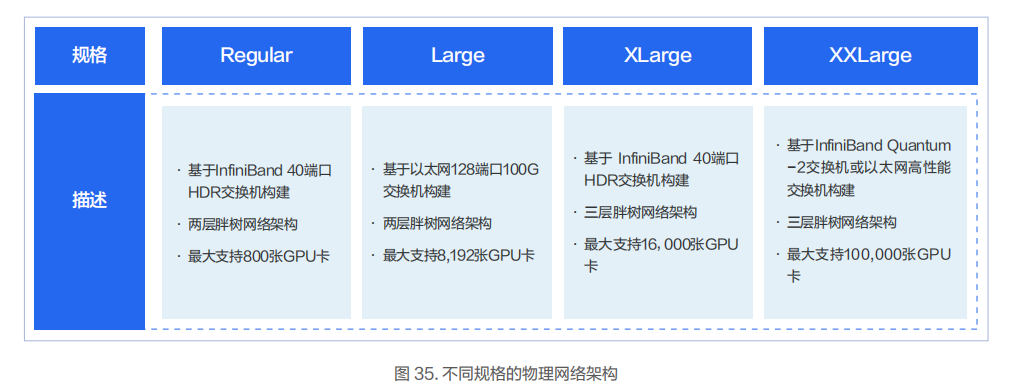
不同型号的 InfiniBand/RoCE 交换机和不同的网络架构下所支持的 GPU 的规模不同。结合当前已成熟商用的交换机,我们推荐几种物理网络架构的规格供客户选择。
Regular:InfiniBand 两层胖树网络架构,基于 InfiniBand HDR 交换机,单集群最大支持 800 张 GPU 卡。
Large:RoCE 两层胖树网络架构,基于 128 端口 100G 数据中心以太交换机,单集群最大支持 8192 张 GPU 卡。
XLarge:InfiniBand 三层胖树网络架构,基于 InfiniBand HDR 交换机,单集群最大支持 16000 张 GPU 卡。
XXLarge:基于 InfiniBand Quantum-2 交换机或同等性能的以太网数据中心交换机,采用三层胖树网络架构,单集群最大支持 100000 张 GPU 卡。
Large智算物理网络架构实践
支撑上层创新应用和算法落地的关键环节之一是底层的算力,而支撑智算集群的算力发挥其最大效用的关键之一是高性能网络。度小满的单个智算集群的规模可达 8192 张 GPU 卡,在每个智算集群内部的智算资源池 AI-Pool 中可支持 512张 GPU 卡。通过无阻塞、低时延、高可靠的网络设计,高效的支撑了上层智算应用的快速迭代和发展。
XLarge智算物理网络架构实践
为了实现更高的集群运行性能,百度智能云专门设计了适用于超大规模集群的 InfiniBand 网络架构。该网络已稳定运行多年,2021 年建设之初就直接采用了 200Gbps 的 InfiniBand HDR 交换机,单台 GPU 服务器的对外通信带宽为1.6Tbps。
责任编辑:彭菁
-
带宽
+关注
关注
3文章
926浏览量
40913 -
服务器
+关注
关注
12文章
9129浏览量
85341 -
交换机
+关注
关注
21文章
2638浏览量
99546 -
数据中心
+关注
关注
16文章
4764浏览量
72100 -
智能计算
+关注
关注
0文章
177浏览量
16460
原文标题:智算中心网络架构设计实践(2023)
文章出处:【微信号:架构师威廉希尔官方网站 联盟,微信公众号:架构师威廉希尔官方网站 联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论