 UniVL-DR: 多模态稠密向量检索模型
UniVL-DR: 多模态稠密向量检索模型

论文标题:
Universal Vision-Language Dense Retrieval: Learning A Unified Representation Space for Multi-Modal Retrieval
背景介绍尽管当前主流搜索引擎主要面向文本数据,然而多媒体内容的增长一直是互联网上最显着趋势之一,各种研究表明用户更喜欢搜索结果中出现生动的多模态内容。因而,针对于多模态数据的信息获取需求在用户搜索过程中尤为重要。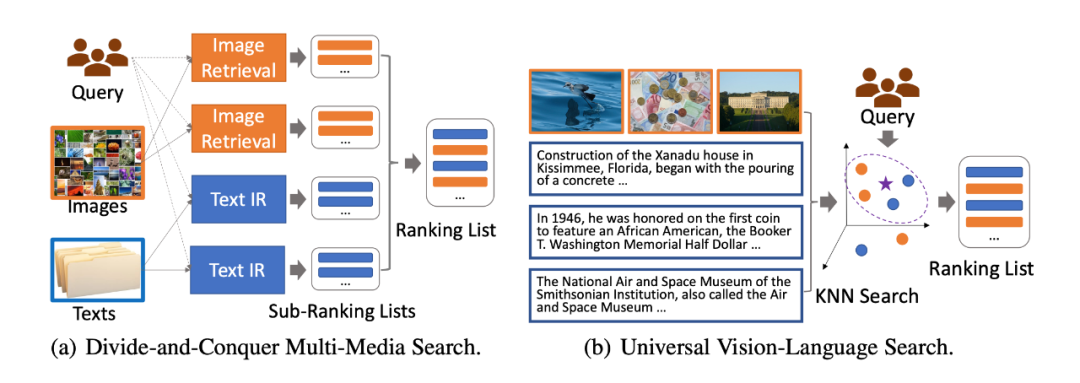 ▲图1. 不同多模态检索框架示意图
▲图1. 不同多模态检索框架示意图为了实现多模态检索过程,当前的多媒体搜索系统通常采用“分而治之”的方法。如图 1(a) 所示,这些方法首先在单个模态中进行搜索,包括文本、图像、视频等 ,然后将各个模态的检索结果融合在一起,例如,在这些单/交叉模态检索器之上构建另一个排序模块来进行模态融合。
显而易见,相关性建模(Relevance Modeling)和检索结果融合(Retrieval Result Fusion)二者的建模过程通常交织在一起,以实现更准确的多模态检索结果。然而,由于模态差距,这类模型只能以分而治之的方式进行流水线建模,这使得融合来自不同模态的检索结果具有挑战性。
在本文中,我们提出端到端多模态检索模型,通过用户查询对多模态文档进行统一的检索。如图 1(b) 所示,通用多模态检索将查询和多模态文档映射到一个统一的嵌入空间,并通过最近邻搜索检索多模态候选结果。最终,本文将相关性建模(Relevance Modeling)、跨模态匹配(Cross-Modality Matching)和检索结果融合(Retrieval Result Fusion)进行统一的建模。多模态检索任务介绍
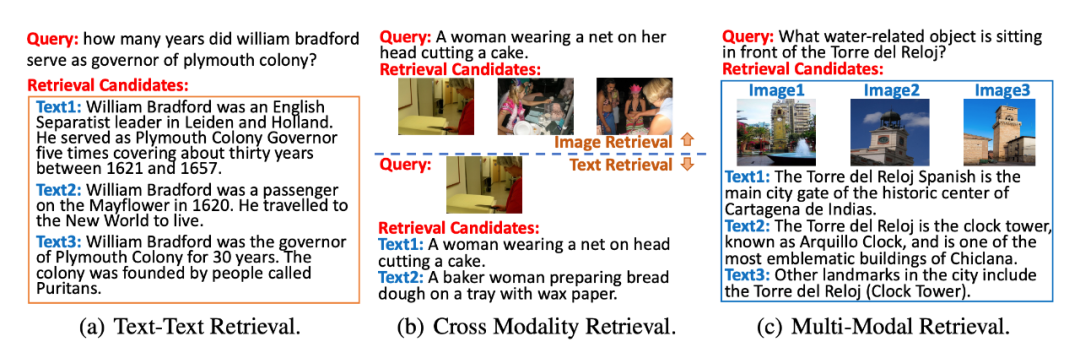
▲图2. 不同检索任务示意图
单模态检索(Single Modality Retrieval)。如图 2(a)所示,单模态检索侧重于在一个模态空间内进行相关性检索,包括文本-文本检索和图像-图像检索。文本-文本检索旨在从文本集合中检索出与查询相关的文本文档;而图像-图像检索期望于从图像集合中检索出与给定查询图像匹配度较高的图像。
跨模态检索(Cross Modality Retrieval)。如图 2(b)所示,该检索场景包含两个子任务:文本-图像检索,图像-文本检索。这两种任务要求检索模型在图像与图像对应的描述文字之间进行跨模态匹配,
例如,在图像-文本检索任务中,对于给定的图像,检索模型需要在给定的图像描述文本集合中检索出与之匹配的描述文本。这种跨模态检索场景中的任务更加侧重于文本与图像之间的跨模态语义信息匹配,不同于信息检索中的相似度搜索,这种跨模态匹配更加注重“浅层”的语义匹配,对于深层的文档理解能力要求不高。
多模态检索(Multi-Modal Retrieval)。如图 2(c)所示,该检索场景旨在包含多模态文档的数据集合中检索相关文档。在多模态检索场景下,检索模型需要同时处理查询与不同模态文档之间的相似度计算,例如,对于给定的查询,检索模型需要在给定的文档集合中检索出相似文档。
不同于单模态检索和跨模态检索,多模态检索的目的是从多模态文档集合中检索、返回相关文档。根据用户的查询,检索结果可能由文本文档、图像文档或文本文档与图像文档的混合序列组成。多模态检索更加关注查询和文档之间的关联建模,且检索过程中涉及查询与文本文档的单模态匹配、查询与图像文档的跨模态匹配以及不同模态文档与查询的相似度之间的比较,这使得这项任务具有更大的挑战性。UniVL-DR:基于统一表征空间的多模态稠密向量检索框架
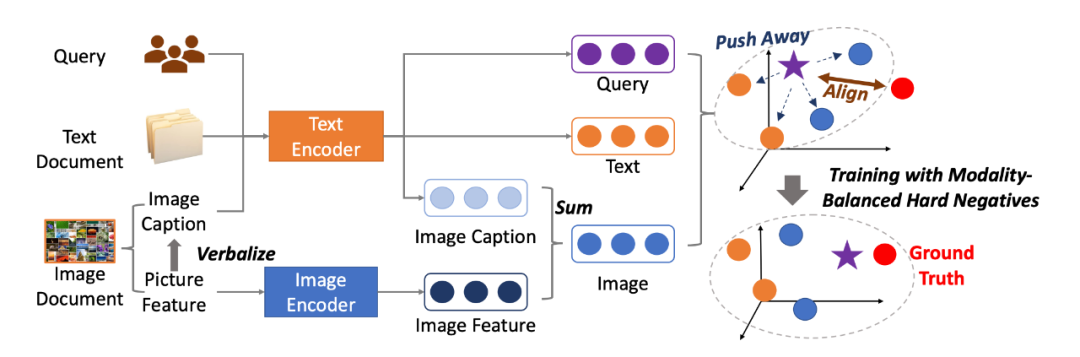
▲图3. UniVL-DR模型结构图
在多模态信息检索场景下,本文提出了 Universal Vision-Language Dense Retrieval (UniVL-DR) 模型来建模多模态检索过程。如图 3 所示,对于给定用户查询和多模态文档,UniVL-DR 将用户查询、文本文档和图像文档编码在一个统一的向量表征空间中,并在该表征空间中进行用户查询与相关文档的相关性建模以及多模态文档向量表征建模。
UniVL-DR 由两个编码器构成:文本编码器和图像编码器。查询、图像文档和文本文档均通过这两个编码器编码得到稠密向量表示。
查询编码:如公式(1)所示,本文算法直接通过文本编码器对查询进行编码,得到查询的表征向量:
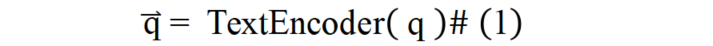
文本文档编码:如公式(2)所示,对于文本文档,本文算法将其经过文本编码器得到文本文档的稠密表征向量:
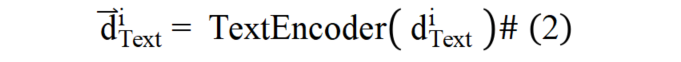
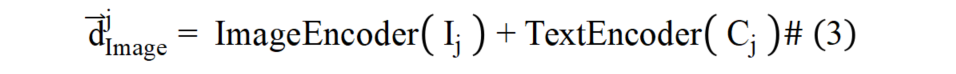
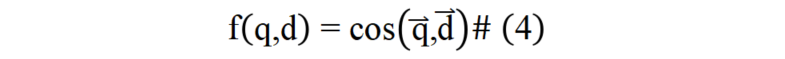
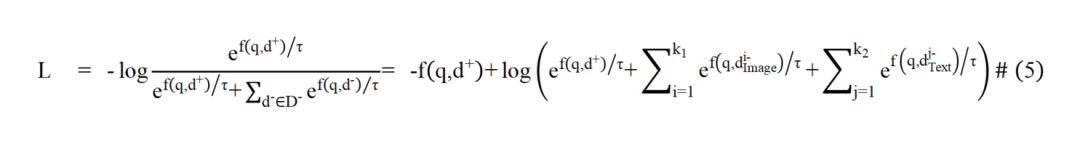
为解决图像文档与文本文档在表征上的模态屏障,本文提出通过图像的语言化拓展来弥合不同模态文档间表征鸿沟的方法。
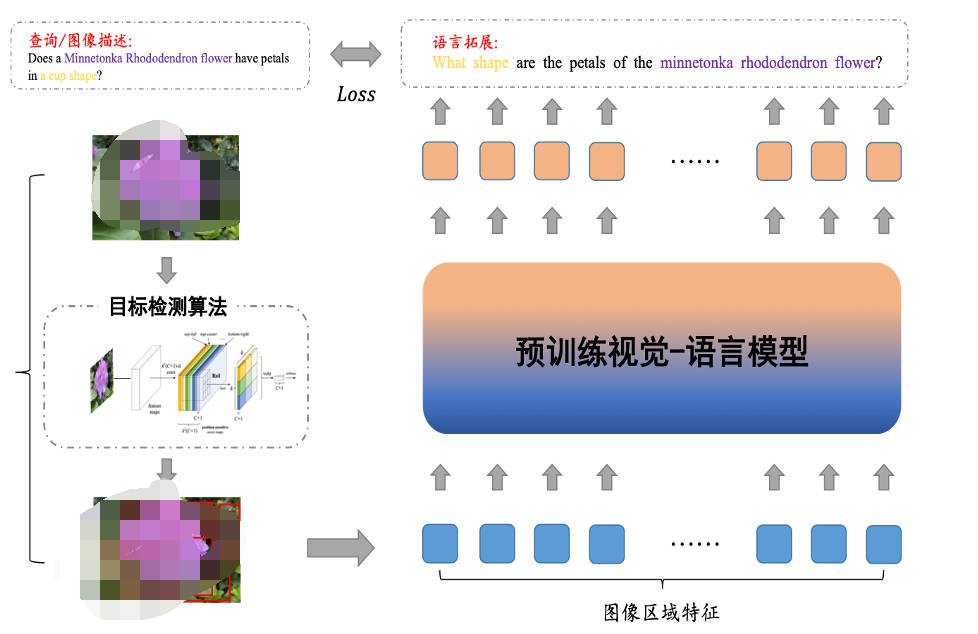
▲图4. 图像的语言拓展算法示意图
本文借鉴信息检索领域中的文档拓展威廉希尔官方网站 对图像进行语言化拓展,增强图像的语义表示。如图(4)所示,首先对图像进行目标检测,得到图像的区域特征和检测出的区域文本标签集合。本文首先将由图像和目标检测得到的区域标签生成图像描述形式的语言化拓展,输入结构如公式(6)所示:
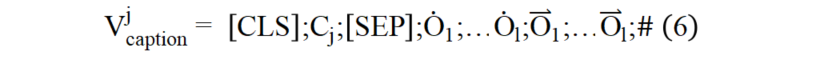
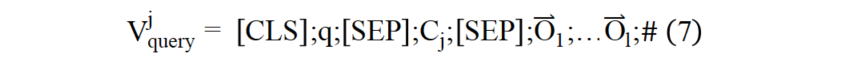
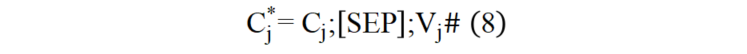
实验结果
实验结果如表 2 所示。UniVL-DR 在性能评估上比所有基线模型提高了 7% 以上,显著的检索性能提升说明了本文算法在构建面向多模态文档的信息检索系统方面的有效性。相比较分而治之的策略,UniVL-DR 甚至超过了 BM25&CLIP-DPR(Oracle Modality)模型,该模型利用了数据集中标注的与用户问题相关的文档模态信息进行模态路由。证明统一化的多模态文档向量建模能够很好地建模多模态检索任务。
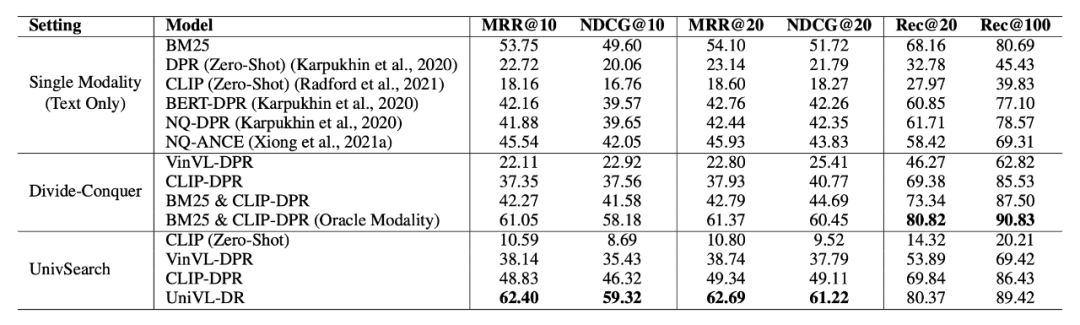
▲表2. 主实验结果
如表 3 所示,本文展示了模型的消融试验结果。在实验中我们发现针对于多模态检索任务,图像文档的标题信息相比较像素信息更加重要。同时,在图像文档标题信息的基础上加入图像像素信息能够进一步提升检索的效果。
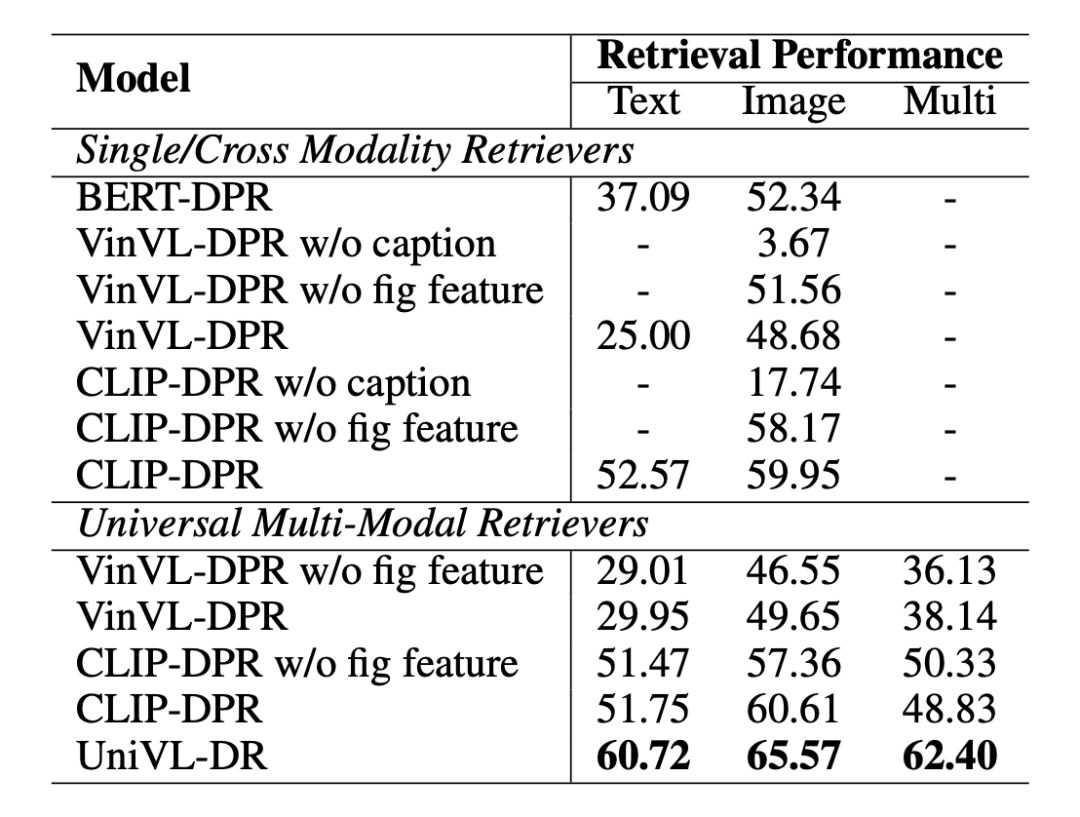
▲表3. 消融实验结果
如图 5 所示,在用户问题中,往往会出现与图片所描述内容相关的实体,例如:明尼通卡杜鹃花(Minnetonka Rhododendron flower),然而,现有的图片编码器(例如:CLIP)往往缺少此类的背景知识,因而导致在多模态检索过程中图像文本的像素编码向量的作用不大。此原因导致了在多模态检索过程中图片像素的语义信息对检索精度的提升贡献不大的现象。
▲图5. 图片检索样例
进一步我们通过不同负例选取方式训练得到的多模态检索模型的向量空间可视化,如图 6 所示。我们的实验结果发现,通过模态平衡难负例训练的检索模型学习的向量空间更加的均匀。同时,通过对难负例的模态进行平衡可以很好地缓解检索模型对于模态的偏见问题。

▲图6. 稠密向量可视化
总结本文提出了 UniVL-DR,UniVL-DR 构建了统一的多模态向量表征空间,将单模态、跨模态匹配和检索结果融合建模在一起,实现端到端的多模态信息检索。具体来讲,本文的主要贡献有以下两点:1)通过模态均衡的难负例选取策略进行统一多模态表征空间的对比优化。2)利用图像语言化方法弥合了原始数据空间中图像和文本之间的模态差距。实验表明,UniVL-DR 可以通过图像语言化威廉希尔官方网站 弥合模态差距,并通过模态均衡的难负例选取策略避免过度拟合某一种模态的训练监督信号。 ·
-
物联网
+关注
关注
2909文章
44578浏览量
372880
原文标题:UniVL-DR: 多模态稠密向量检索模型
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网威廉希尔官方网站 研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
商汤日日新多模态大模型权威评测第一
一文理解多模态大语言模型——下

一文理解多模态大语言模型——上

利用OpenVINO部署Qwen2多模态模型
云知声山海多模态大模型UniGPT-mMed登顶MMMU测评榜首

Meta发布多模态LLAMA 3.2人工智能模型
云知声推出山海多模态大模型
依图多模态大模型伙伴CTO精研班圆满举办
李未可科技正式推出WAKE-AI多模态AI大模型

AI机器人迎来多模态模型
苹果发布300亿参数MM1多模态大模型
蚂蚁集团推出20亿参数多模态遥感基础模型SkySense
机器人基于开源的多模态语言视觉大模型

自动驾驶和多模态大语言模型的发展历程

从Google多模态大模型看后续大模型应该具备哪些能力





 工商网监
工商网监
评论