 智能汽车如何感知和理解世界?算力+传感器、算法、数据
智能汽车如何感知和理解世界?算力+传感器、算法、数据
车辆究竟是如何做到理解这些复杂的信息?
无人驾驶车辆在运行中需要面对白天、黑夜、黄昏、大风、暴雨、雾霾等自然环境信息,以及道路上行人、车辆、红绿灯等物体信息。
本文用两个基本问题为您解答无人驾驶车辆如何感知和理解这个世界。
01、无人车如何感知和理解这个世界?
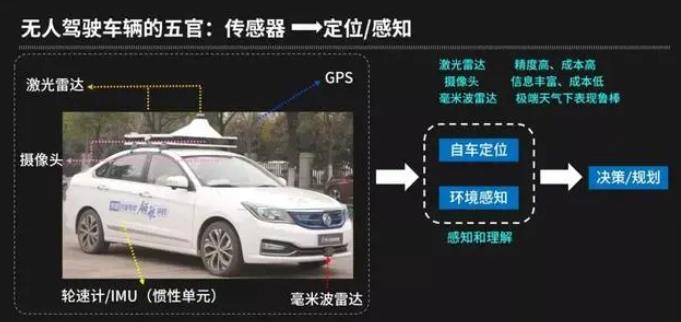
人类驾驶员的感官主要依赖于双眼,偶尔用到耳朵,而无人驾驶车辆的AI驾驶员的感官包括了激光雷达、毫米波雷达、摄像头、差分GPS、惯性单元、轮速计等传感器。还有一个核心零部件是U-Drive自动驾驶控制器,我们也称呼它为“车脑”,在“车脑”中会运行一整套的软件或者算法。
在一辆无人车上使用的各类传感器往往各有优缺点:
激光雷达:能够直接获取 3D 的点云数据,精度高,成本也高
摄像头:获取二维图像数据,信息丰富、成本低,但是对光照要求相对敏感
毫米波雷达:精度较低,极端天气下表现较好
在无人车上需要将不同的传感器融合以获取最佳的效果。当车脑收到这些传感器数据之后,就会进入两个模块:一个是自车定位,另一个是环境感知。经过这两个模块的算法处理之后把结果输出到下游的决策/规划模块使用。
问题一:定位-我在哪里?
现在人类出门开车基本上离不开导航,人类驾驶员对定位精度要求不高,只需要在10米级。而AI驾驶员要达到厘米级的高精度定位,需要让车辆自身每时每刻知道“我在哪里”,需要精确地分辨出当前车在哪个车道,距离车道的边缘有多远、方向如何,如此后面的规划/控制模块才能做出正确的选择。
实现高精度定位有以下几种方式:
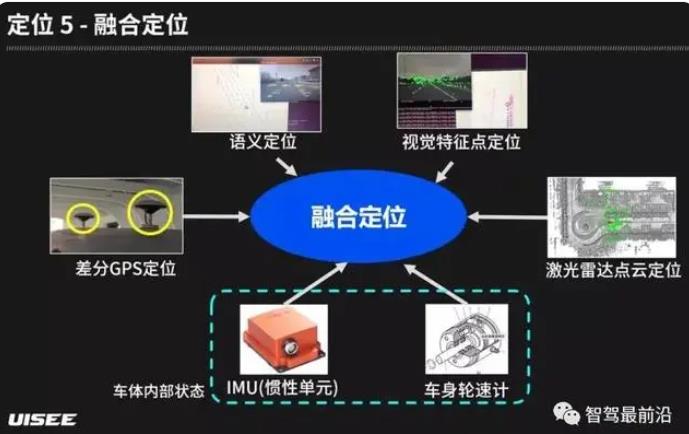
差分 GPS:差分 GPS 和手机上的普通 GPS 不一样,它是一种特殊的高精度的定位设备,它可以消除三类误差:公有误差、传播延迟误差、接收机固有误差。通过消除这些误差可以把定位精度提升到 2cm 左右。可是在现实中,道路旁边有建筑物、高架、树木,这些都会影响差分 GPS 信号的质量,所以还需要其他方式配合以获得更高精度的定位。
基于视觉特征点的定位是基于图像中局部灰度的变化来发现图像中一些稳定的特征点,利用这些特征点对图像进行编码,通过对环境持续观察以达到实现对自车的精准定位。再通过重定位找到最佳定位匹配点。此外,在无人驾驶车辆行驶中会通过定位跟踪模式持续获得精准位姿。

激光雷达定位:激光雷达点云定位是激光雷达通过扫描得到一系列单帧的点云,通过匹配位姿优化生成地图。和基于视觉特征点的定位方式一致,激光雷达也需要进行重定位找到最佳定位匹配点。
语义定位:语义定位是对道路环境中存在的人类可识别的高级特征标识进行识别并做自车定位,比如车道线、立柱、箭头等各种标识。同样,语义建图包含三步:第一步,通过激光雷达与摄像头融合的数据进行三维重建,得到彩色的点云;第二步,对三维重建结果进行语义分割,标记点云属于什么分类;第三步,自动提取出语义标识,从而完成语义地图的构建。最终自车根据语义地图来实现定位。
融合定位:融合定位是将所有的定位源输出的结果和车体内部状态融合在一起,如 IMU(惯性单元)、车身轮速计等,最终得出统一的自车定位信息发送给下游模块使用。
问题二:感知-我的周围是什么
无人驾驶车辆接收到摄像头、激光雷达以及其他感知设备输入的数据,通过这些数据可以获取周围的目标物的位置、尺寸、分类信息(车辆、行人等)和跟踪信息(速度、加速度、角速度等),还有未知分类的障碍物、目标车的尾灯、护栏、红绿灯、植被等都需要被感知到。所有这些信息都会输出到到决策/规划模块使用。
目标检测中都会使用深度学习的方法,深度学习首先通过网络学习激光雷达三维点云中的背景信息、目标物和分类信息。此外,无人车上有多种传感器,最主要的是激光雷达和摄像头,将二者融合会在目标检测的距离精度、分类精度、尺寸精度等方面都有显著提升。
无人车要能够安全、平顺的行驶,对每个目标物的准确跟踪、速度、加速度等都是必不可少的,这些信息必须要连续帧上获取,因此我们必须要目标检测机制上进行匹配跟踪、速度估计等等一系列工作。我们会获得T – 1(上一帧)时刻的目标检测结果,也会获得当前时刻的结果,这些结果可以通过卡尔曼滤波算法得出当前帧预测结果,再把这个预测结果和当前帧检测结果通过相似度计算和匈牙利匹配关联,可以通过这速度工具来获取场景中目标物编号、速度、运动方向等信息,这些信息对车辆决策/规划模块相当重要。
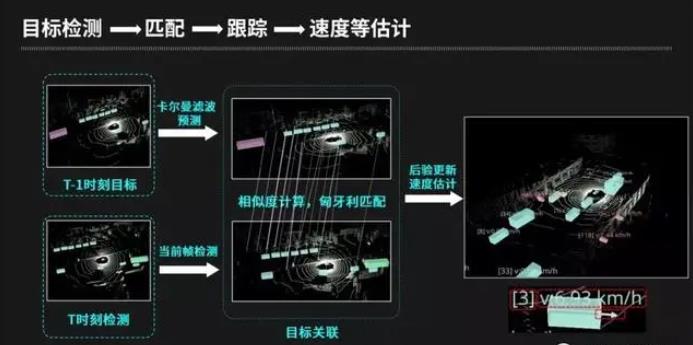
*卡尔曼滤波可以有效在时间线上对测量和预测进行合理加权的算法。
*匈牙利算法是一种求解最大匹配的算法。
除了常见的目标检测之外,环境中还有一些其他要素需要感知,比如之前提到的植被,无法用一个矩形框来表示,因此需要语义分割威廉希尔官方网站 ,它能够获得精细的感知结果。最终我们将目标检测、跟踪和语义分割融合在一起,作为整体输出给下个模块。
02、无人车的定位感知能力如何持续进化
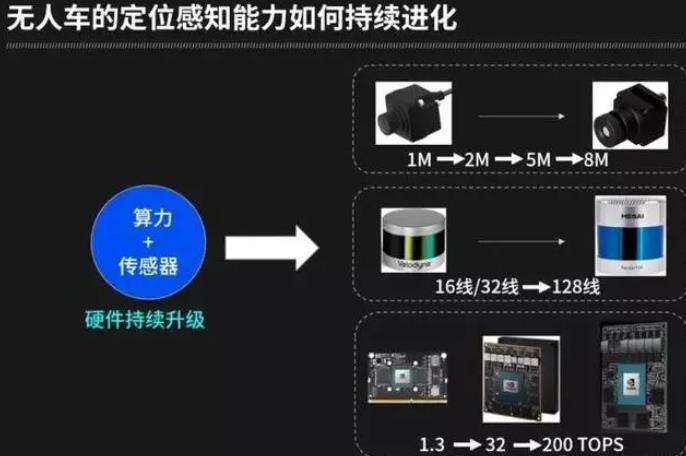
无人驾驶系统几个最核心的要素:算力+传感器、算法、数据。
算力+传感器主要依赖硬件持续升级驱动,其中包括车载控制芯片(每一代新的芯片诞生,算力都有数量级提升)、激光雷达(激光雷达性能越来越强,成本也逐步降低,进而推动定位感知能力的提升)、摄像头(分辨率不断提升,进而为算法提升奠定基础)。
算法主要依赖人脑驱动演进,从第一个角度看,深度学习依然是目前最重要的方法,但是我们在继续演进的路上也面临很多挑战,后续网络规模还会变得更大、更复杂(现在最大的网络已经在接近小型哺乳动物的神经元个数),从而具有更高精度和更强功能;从第二个角度看,在工业界的实践中,深度学习方法需要和其他的机器学习方法、非学习方法结合,以得到实际可用的、功能边界清晰的、可靠的系统;从第三个角度看,需要持续扩展“运行设计域”(ODD)。
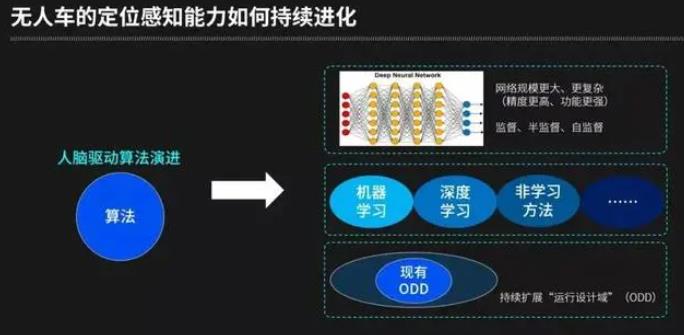
运行设计域简单来说就是可正常运行的范围,包含以下几个要素:天气(雨、雪、雾等极端天气)、光照(黄昏、夜晚、阴天等)、道路(隧道、机坪、高架)、区域(园区、城区、高速),无人驾驶车辆需要在这些要素范围内,从易到难进行持续扩展。
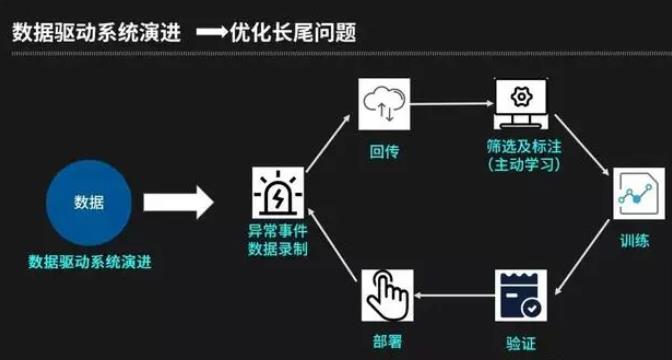
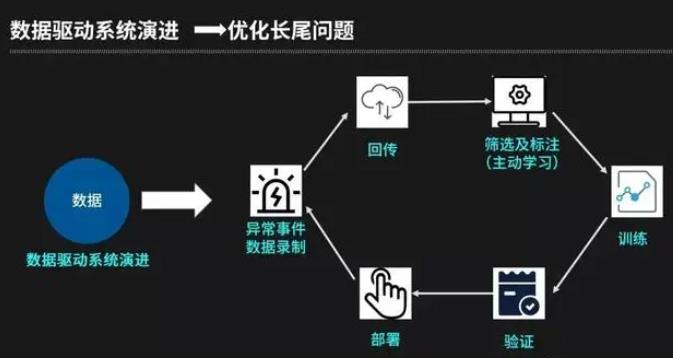
数据主要通过数据驱动系统演进驱动,数据驱动要解决的第一个问题就是长尾问题(长尾问题概念来自于互联网,指个性化、零散的总和却又比较大的客户需求,在无人驾驶领域指很少见的场景,但是总和同样较大)。长尾问题之所以难解决,算法能力不够强大是一个维度,这需要工业界和学术界进行持续提升,另一个维度是在现有算法能力范围内,需要通过无人驾驶系统来收集到最有价值的数据,用数据驱动的方式来迭代和提升系统能力。
数据驱动是如何解决长尾问题的?通过异常事件数据录制-回传-筛选及标注-模型训练-模型验证-部署,从而完成模型升级的迭代过程,异常事件包括人工接管(Robotaxi)、无人运营车辆的剐蹭、急刹车、目标物分类跳变等。
数据驱动的另一个方面:场景、业务、传感器类别非常多。无人车会在不同的城市、不同的道路和区域、承担不同的业务(物流、出租车等),同时每种车型上的传感器配置也不一样,这几方面因素都会导致数据有明显差异。因此我们提出了一个数据驱动的跨场景、业务和传感器的统一框架。这个框架可以综合考虑不同场景、业务、传感器的数据,可以高效地、最大程度复用各场景中的数据价值,节省标注工作成本,并提升效率。
无人驾驶车辆感知与理解这个世界的背后是一项复杂的工程系统,惟有适者方能生存,在不停地认识世界的过程中无人驾驶车辆也在不停地实现自身的进化与演进,向着下一个进化节点跨步前进。
来源:电控公众号智驾最前沿公众号陈云培
-
传感器
+关注
关注
2551文章
51125浏览量
753767 -
算法
+关注
关注
23文章
4612浏览量
92930 -
激光雷达
+关注
关注
968文章
3975浏览量
189945 -
无人驾驶
+关注
关注
98文章
4061浏览量
120534 -
智能汽车
+关注
关注
30文章
2855浏览量
107290
发布评论请先 登录
相关推荐
《具身智能机器人系统》第1-6章阅读心得之具身智能机器人系统背景知识与基础模块
传感器:开启智能生活的新篇章
美新半导体亮相2024世界传感器大会
感知世界,智创未来 灵途科技受邀参加2024世界传感器大会

传感器的多功能应用:精准感知,智能控制

压敏传感器和力敏传感器的区别
数据世界的触角:传感器的主要功能有什么?
百亿级传感器赛道诞生,这家国产力传感器龙头公司如何掘金?
未来已来,多传感器融合感知是自动驾驶破局的关键
智能算力规模超通用算力,大模型对智能算力提出高要求






 工商网监
工商网监
评论