 省成本还是省时间,AI计算上的GPU与ASIC之选
省成本还是省时间,AI计算上的GPU与ASIC之选
电子发烧友网报道(文/周凯扬)随着AI计算逐渐蚕食通用计算的份额,数据中心的硬件市场已经开始出现了微妙的变化。最抢手的目前已经成了GPU,反观CPU、ASIC和FPGA等硬件,开始成为陪衬。但高昂的售价以及强绑定的供应关系,还是让不少企业开始探索别的出路。
仍在被疯抢的GPU
在今年第一季度AI热潮高涨下,全球已经开启了一波GPU抢购。无论是借助GPU开发各自大模型应用的互联网厂商,还是想借此发展其AI服务器业务的云服务厂商,都在抢购英伟达目前主推的A100和H100两大GPU。
就连台积电哪怕第一季度业绩下滑明显,其CEO魏哲家在法说会上也表示在AI相关的需求上观察到了增量上行,将帮助其在今年实现可观的库存消化。

H100 GPU / 英伟达
在美国商务部半导体出口新规刚推出不久,A100在非正常渠道的单价就飙升至20000美元,是原价的两倍左右。为此英伟达仅仅面向中国市场推出了A800和H800,只不过将高速互联总线NVLink限制在了400GB/s,但好歹仍足以满足大部分AI计算的需求。
可好景不长,随着紧缺和抢购的趋势很快蔓延到了A800和H800上,据了解,国内市场的A800单价一周上涨了30%,从原来9万元上升至13万元,甚至连带使得搭载该卡的服务器现货同样涨价,颇有当年矿潮期显卡涨价整机一并涨价的趋势。
使其状况更加恶化的是,英伟达据传大量削减了A800的供应,而是转为推广更高端也更昂贵的H800,单价在25万元左右。高端的GPU无疑能够带来更高的性能,但性价比相对较低,大规模部署的成本也会更加难以承受。所以从全球市场的购买表现上来看,互联网公司和云服务厂商显然觉得A100或A800更香一点。
可为了更高的利润转化,英伟达决心调整A800和H800的供应比例的话,也就说得过去了。A100的市场流通率较高,而A800这种面世不久的特供产品,也更方便在供应上加以限制。
省时和省钱
既然GPU困人已久,为何不打破这一限制,转用大规模量产成本更低的ASIC产品呢?事实上,很多厂商早就有类似的心思,只不过执行起来却是寸步难行。首先对于大模型这样的AI应用来说,硬件性能只是一个方面,拥有优质的软件生态也很重要。
英伟达的CUDA成了任何进军AI产业的公司在软件生态上的一头拦路虎,迟迟没法突破。固然ASIC的方案可以省下不少硬件成本,但在软件上仍有不小的障碍。初创公司ASIC硬件的软件生态不成熟,巨头自研的产品又难以与第三方开发结合起来,或者说能打造出爆品应用的概率更低。
反观CUDA,发展这么多年积累的各种library已经逐渐趋于成熟,甚至在英伟达的GPU上优化到了最佳状态,开发者只需要调用API即可实现所需的效果。这堵墙就连同为GPU厂商的AMD等竞争对手都未能攻破,因为AI时代下省时才能抢占先机,省钱是之后采取考虑的事。
话虽如此,相关的尝试依旧没有停止,诸如谷歌的TPU、亚马逊的Trainium以及微软最近在研究的Chiplet Cloud等等,都是厂商们对ASIC持续看好的表现。可以看出,让互联网企业,尤其是芯片设计能力欠缺的企业,去走ASIC这条路线是很难的。而托管了诸多第三方芯片设计平台、大模型和AI计算负载的云服务厂商,有这个威廉希尔官方网站
积累,也有实力组建或已组建达标的芯片设计队伍,最终做到省时又省钱。
写在最后
ASIC固然前景可观,但目前厂商们在购置GPU上花的钱多半是多于自研投入的,这也就是GPU作为通用计算硬件的future proofing性质。可能在GPT爆火的今年,这款ASIC提供了远超GPU的性能或成本优势,但未来保不齐会出现其他的爆品应用。GPU可以很快调转势头,但ASIC就可能会被淘汰。所以对这些公司来说,无论是购买A100还是A800,不仅是对现在的投资,也是对未来的投资。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
asic
+关注
关注
34文章
1200浏览量
120481 -
gpu
+关注
关注
28文章
4735浏览量
128924 -
AI
+关注
关注
87文章
30839浏览量
268997
发布评论请先 登录
相关推荐
GPU是如何训练AI大模型的
在AI模型的训练过程中,大量的计算工作集中在矩阵乘法、向量加法和激活函数等运算上。这些运算正是GPU所擅长的。接下来,AI部落小编带您了解
《CST Studio Suite 2024 GPU加速计算指南》
《GPU Computing Guide》是由Dassault Systèmes Deutschland GmbH发布的有关CST Studio Suite 2024的GPU计算指南。涵盖GP
发表于 12-16 14:25
使用瑞萨AnalogPAK SLG47001/03节省开发时间
在当今快速发展的威廉希尔官方网站
市场中,对更快、更高效的产品开发的需求比以往任何时候都高。企业一直在寻找简化流程和缩短上市时间的方法。有助于节省时间、简化设计和降低成本的产品对于保持竞争力至关重要。
《算力芯片 高性能 CPUGPUNPU 微架构分析》第3篇阅读心得:GPU革命:从图形引擎到AI加速器的蜕变
CPU、GPU的演进历程,AI专用芯片或将引领未来计算平台的新方向。正如爱因斯坦所说:\"想象力比知识更重要\" —— 在芯片设计领域,创新思维带来的突破往往令人惊叹。
发表于 11-24 17:12
华迅光通AI计算加速800G光模块部署
。骨干交换机,相当于核心层交换机,直接连接到叶交换机,每个骨干交换机连接到所有叶交换机。
AI计算和800G光模块
与传统的三层拓扑结构相比,脊叶结构需要大量的端口。因此,无论是服务器还是交换机
发表于 11-13 10:16
FPGA和ASIC在大模型推理加速中的应用
随着现在AI的快速发展,使用FPGA和ASIC进行推理加速的研究也越来越多,从目前的市场来说,有些公司已经有了专门做推理的ASIC,像Groq的LPU,专门针对大语言模型的推理做了优化,因此相比

如何计算上拉电阻的值
,但在对性能有更高要求或特定条件下,则需要通过更为精确的计算来确定电阻值。本文将详细介绍如何计算上拉电阻的值。 首先,我们需要理解上拉电阻在I2C总线中的基本作用。在I2C的开漏输出设计中,上拉电阻负责在无设备驱动总线时,将SC
人工智能在项目管理中的应用:Atlassian Intelligence六大自动化任务方法详解,让Jira与Confluence效率翻倍
的情况下节省时间和金钱的有效方法之一。无论是设置提醒还是改进写作,AI都可以帮助您高效地完成工作。AtlassianIntelligence将AI的强大功能与At

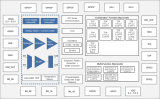
AI服务器异构计算深度解读
AI服务器按芯片类型可分为CPU+GPU、CPU+FPGA、CPU+ASIC等组合形式,CPU+GPU是目前国内的主要选择(占比91.9%)。
发表于 04-12 12:27
•617次阅读

FPGA在深度学习应用中或将取代GPU
基础设施,人们仍然没有定论。如果 Mipsology 成功完成了研究实验,许多正受 GPU 折磨的 AI 开发者将从中受益。
GPU 深度学习面临的挑战
三维图形是 GPU 拥有如此
发表于 03-21 15:19
GPU理想成本揭秘,性价比之选
如果新的 GPU 能够为频繁和不频繁升级的玩家提供最佳性能提升,从而满足最广泛的 PC 游戏玩家的需求,那么这一代将被认为更加成功。
发表于 03-15 11:15
•668次阅读
到底什么是ASIC和FPGA?
?
最后,我们还是要绕回到AI芯片的话题。
上一期,小枣君埋了一个雷,说AI计算分训练和推理。训练是GPU处于绝对领先地位,而推理不是。我
发表于 01-23 19:08
FPGA、ASIC、GPU谁是最合适的AI芯片?
CPU、GPU遵循的是冯·诺依曼体系结构,指令要经过存储、译码、执行等步骤,共享内存在使用时,要经历仲裁和缓存。 而FPGA和ASIC并不是冯·诺依曼架构(是哈佛架构)。以FPGA为例,它本质上是无指令、无需共享内存的体系结构。
发表于 01-06 11:20
•1645次阅读






 工商网监
工商网监
评论