 Dijkstra算法和A*算法
Dijkstra算法和A*算法
在本文中,我们将主要介绍Dijkstra算法和A*算法,从成本计算的角度出发,并逐步展开讨论。
我们将从广度优先搜索开始,然后引入Dijkstra算法,与贪心算法进行比较,最终得出A*算法。
成本计算
在路径规划中,成本计算的一个主要因素是距离。距离可以作为一种衡量路径长短的度量指标,通常使用欧几里得距离、曼哈顿距离或其他合适的距离度量方法来计算。
本文主要介绍欧几里得距离与曼哈顿距离。

广度优先搜索
广度优先搜索(Breadth First Search,BFS )是一种图遍历算法,按照广度方向逐层遍历所有可达节点。
BFS的基本思想是通过维护一个队列,逐层访问节点。
具体步骤如下:
1、将起始节点放入队列中,并标记为已访问。
2、当队列非空时,执行以下步骤:
从队列中取出一个节点,记为当前节点,并标记为已访问。
如果该节点是目标节点,则返回结果。
将当前节点的所有未访问过的邻居节点放入队列中。
3、如果队列为空,则表示已经遍历完所有可达节点,算法结束。
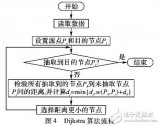
算法框图
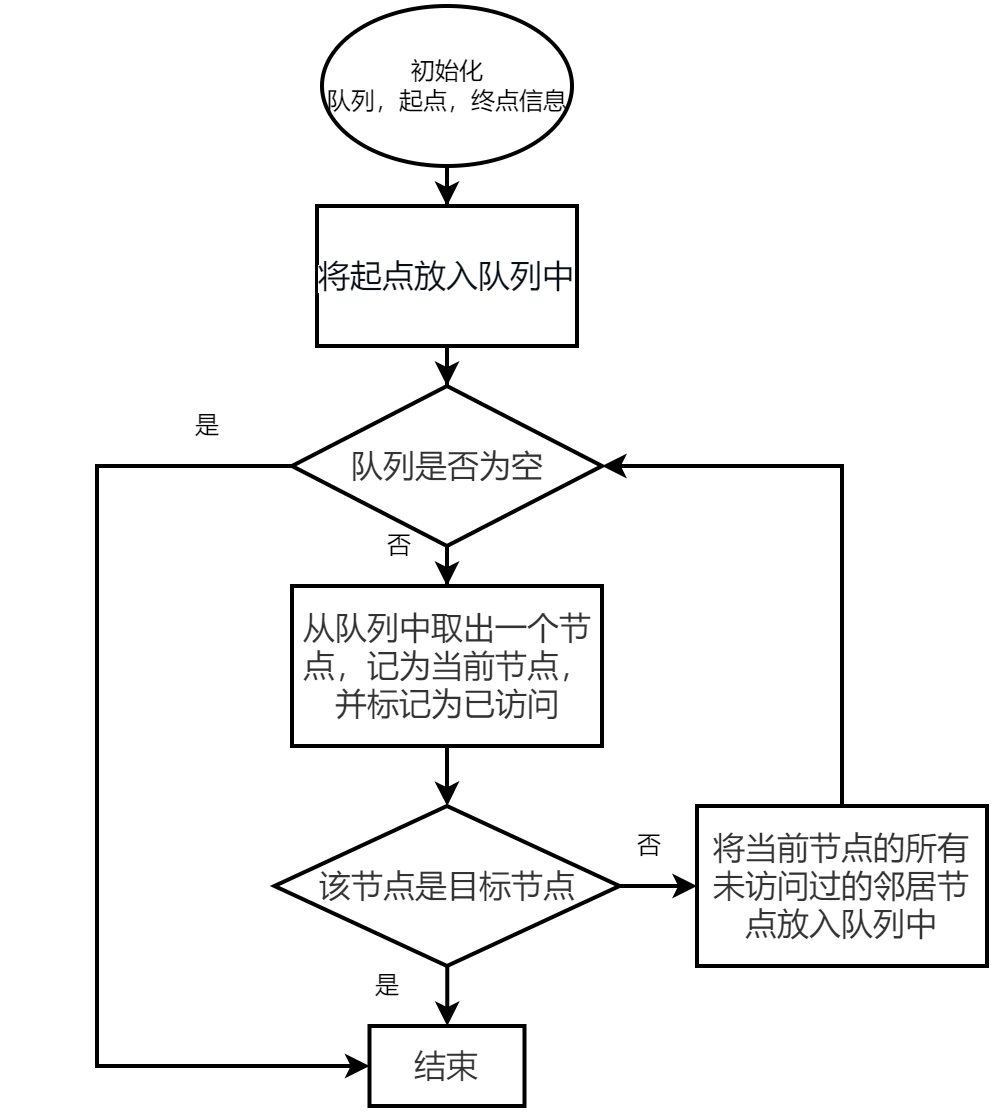
实现效果如下:
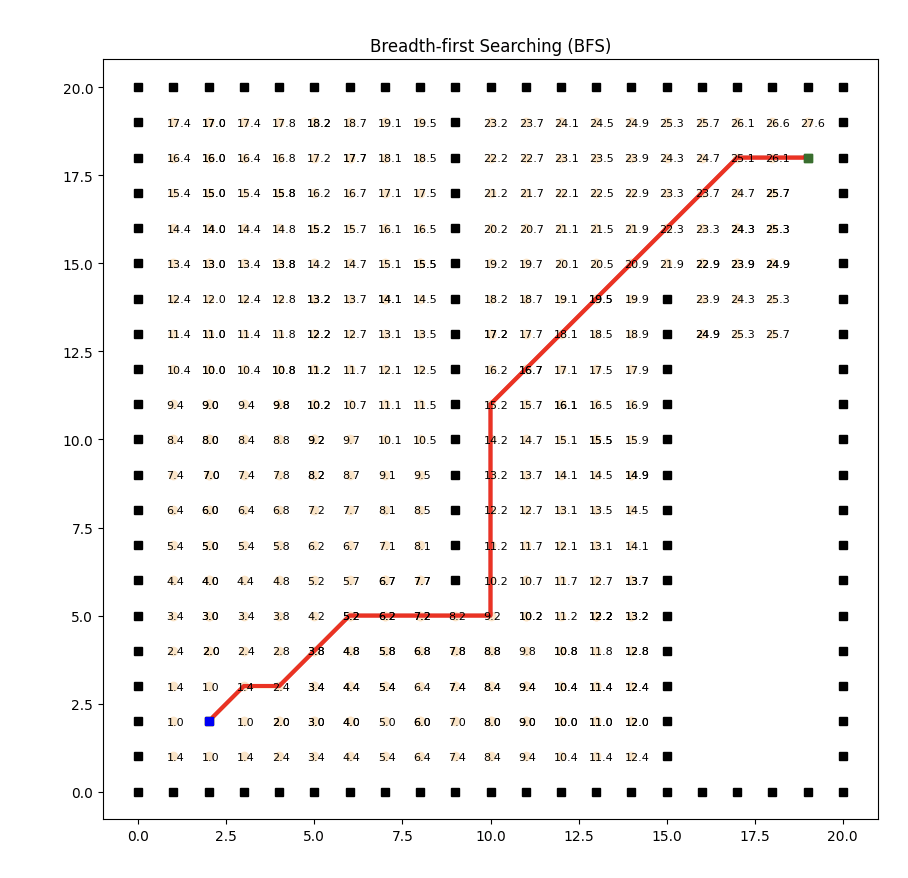
广度优先搜索是一种基本的图搜索算法,它按照图的广度方向逐层遍历所有可达节点。然而,BFS并不考虑边的权重,它只关注节点的层级关系。
因此,对于成本计算来说,BFS并不适用。这里为了实现到目标点的搜索,采用了曼哈顿距离计算初始点的行进成本。
代码
def searching(self):
"""
Breadth-first Searching.
path, visited order
"""
self.PARENT[self.s_start] = self.s_start # 开始节点的父节点
self.g[self.s_start] = 0 # 开始节点的成本
self.g[self.s_goal] = math.inf # 目标节点的成本
# 统一成本搜索,起点的成本是0
heapq.heappush(self.OPEN,
(0, self.s_start))
while self.OPEN:
_, s = heapq.heappop(self.OPEN) # 弹出最小的元素,优先级较高
self.CLOSED.append(s) # 将节点加入被访问元素队列,已访问
if s == self.s_goal: # 到达目标点,即停止
break
for s_n in self.get_neighbor(s): # 得到s的邻居节点
new_cost = self.g[s] + self.cost(s, s_n)
# 计算当前邻居节点s_n的成本=g(s)节点s的成本+s到s_n之间的成本
if s_n not in self.g: # 当前节点没有访问过
self.g[s_n] = math.inf # 起点到节点s_n的成本为无穷
if new_cost < self.g[s_n]: # conditions for updating Cost
self.g[s_n] = new_cost
self.PARENT[s_n] = s
# bfs, add new node to the end of the openset
# 将新的节点添加到队列的末尾
prior = self.OPEN[-1][0] + 1 if len(self.OPEN) > 0 else 0
heapq.heappush(self.OPEN, (prior, s_n))
self.f[s_n] = prior
return self.extract_path(self.PARENT), self.CLOSED, self.f
Dijkstra算法
迪杰斯特拉算法(Dijkstra)算法是一种单源最短路径算法,用于在加权图中找到从起点到所有其他节点的最短路径。
它基于贪心策略,每次选择当前距离起点最近的节点,并通过该节点更新与它相邻的节点的距离。具体步骤如下:
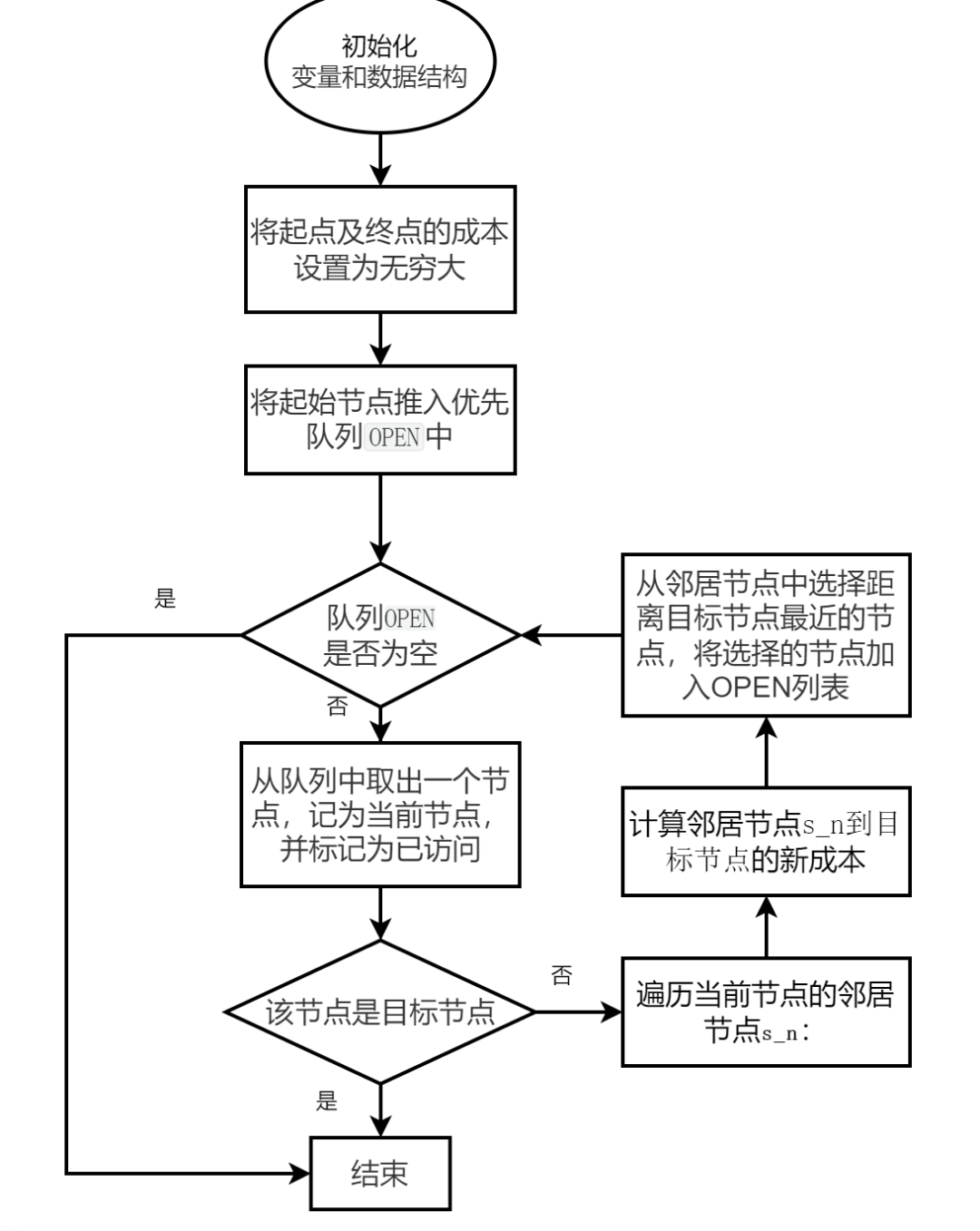
1、初始化:初始化变量和数据结构,创建一个包含所有节点的集合,并为每个节点设置一个距离值。将起始节点的父节点设置为自身,将起始节点的距离值设置为0,其他节点的距离值设置为无穷大(表示尚未找到最短路径)。将起始节点以成本0的优先级推入优先队列OPEN中。
2、主循环:当OPEN非空时:
弹出优先级最小(成本最低)的节点(_, s),其中_为忽略的值,s为当前节点。
将当前节点s添加到CLOSED列表中,表示已访问。
检查当前节点是否为目标节点。如果是,则跳出循环。
对于当前节点的所有邻居节点,计算通过当前节点到达邻居节点的距离,并与邻居节点的当前距离值进行比较。
如果计算得到的距离值小于邻居节点的当前距离值,则更新邻居节点的距离值为新的更小值并将邻居节点s_n以新的成本作为优先级推入优先队列OPEN中循环结束后,可以通过从目标节点回溯到起始节点,在PARENT字典中提取最短路径。
3、循环结束后,可以通过从目标节点回溯到起始节点,在PARENT字典中提取最短路径。
算法框图
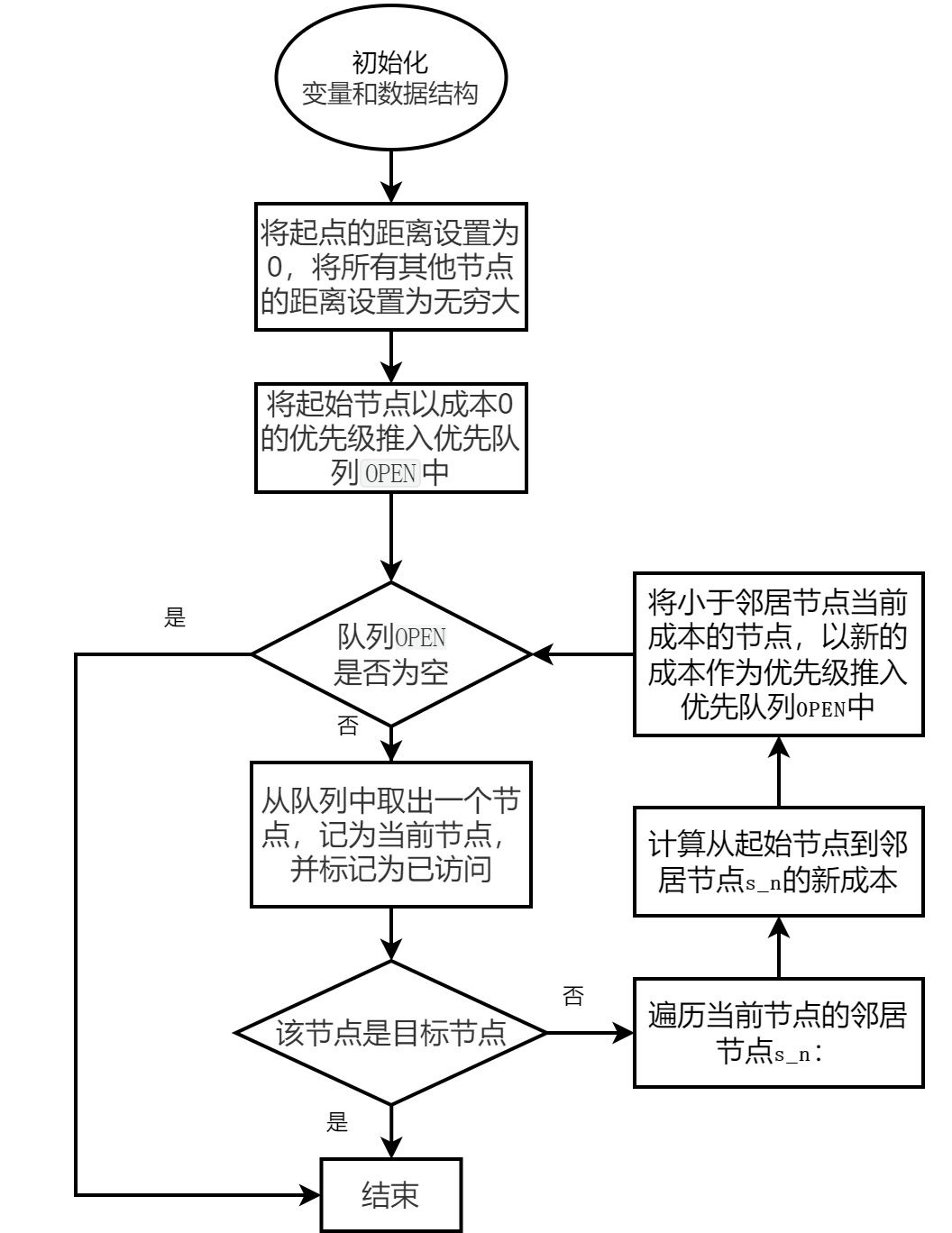
实现效果如下:
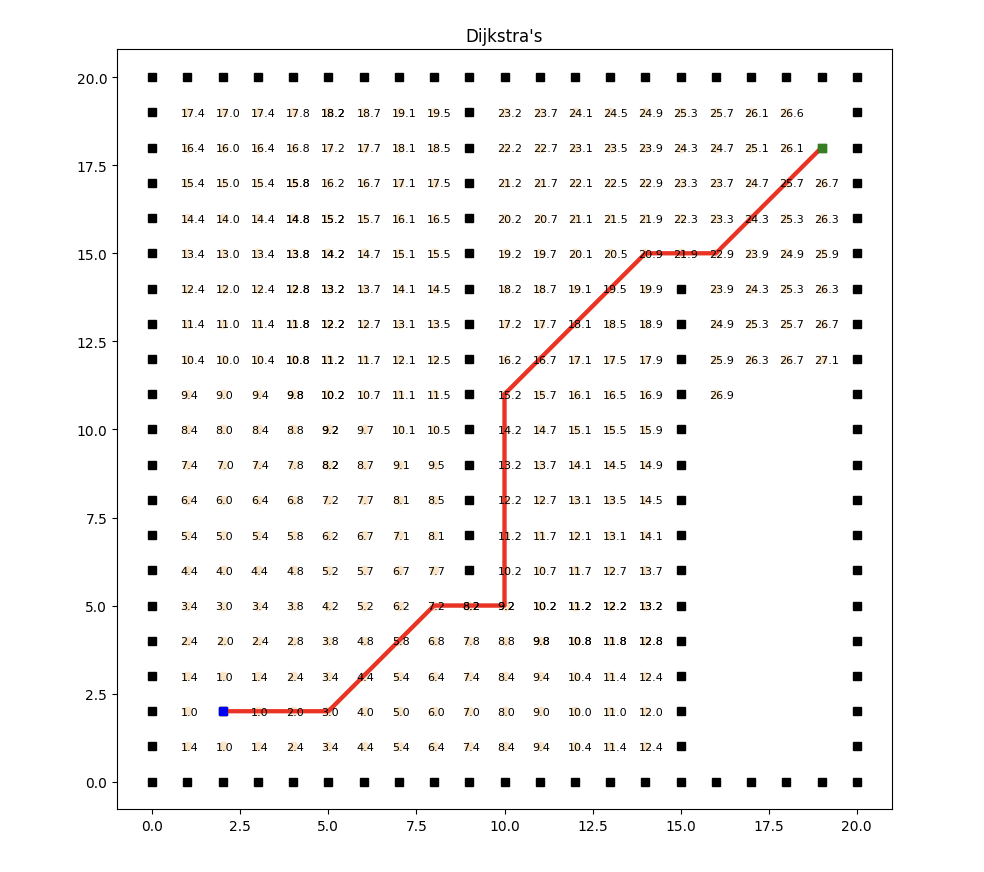
Dijkstra算法能够正确地找到起始节点到其他所有节点的最短路径。它基于贪婪策略,每次选择当前最短路径的节点,通过逐步更新节点的距离值,最终找到最短路径。
代码
def searching(self):
"""
Breadth-first Searching.
path, visited order
"""
self.PARENT[self.s_start] = self.s_start # 开始节点的父节点
self.g[self.s_start] = 0 # 开始节点的成本
self.g[self.s_goal] = math.inf # 目标节点的成本
# 统一成本搜索,起点的成本是0
heapq.heappush(self.OPEN,
(0, self.s_start))
while self.OPEN: # open_list
_, s = heapq.heappop(self.OPEN) # 弹出最小的元素,优先级较高
self.CLOSED.append(s) # 将节点加入被访问元素队列
if s == self.s_goal: # 到达目标点,即停止
break
for s_n in self.get_neighbor(s): # 得到s的邻居节点
new_cost = self.g[s] + self.cost(s, s_n) # 计算当时邻居节点s_n的成本=g(s)节点s的成本+s到s_n之间的成本
if s_n not in self.g: # 当前节点没有访问过
self.g[s_n] = math.inf # 起点到节点s_n的成本为无穷
if new_cost < self.g[s_n]: # 预估节点s_n成本
贪婪算法
贪婪算法(Greedy Algorithm)是一种常见的算法设计策略,其基本思想是在每一步选择当前最优解,而不考虑整体的最优解。贪婪算法通常以局部最优解为目标,通过不断做出局部最优选择来达到整体最优解。
贪婪算法在路径规划问题中,根据当前位置到目标位置的成本作为启发式评估准则,选择最近的节点作为下一步移动的目标。具体步骤如下:
1、初始化:设置起始节点,将起始节点的父节点设置为起始节点本身,并将起始节点和目标节点的成本初始化为无穷大,将起始节点加入开放列表,其优先级根据启发式函数值确定。
2、主循环:当OPEN非空时:
从OPEN列表中弹出具有最高优先级的节点,将其加入已访问列表(CLOSED)中。
检查当前节点是否为目标节点。如果是,则跳出循环。
获取当前节点的邻居节点,从邻居节点中选择距离目标节点最近的节点,将选择的节点加入OPEN列表,并将该节点作为当前节点。
3、循环结束后,通过从目标节点回溯到起始节点,在PARENT字典中提取最短路径。
算法框图
实现效果如下:
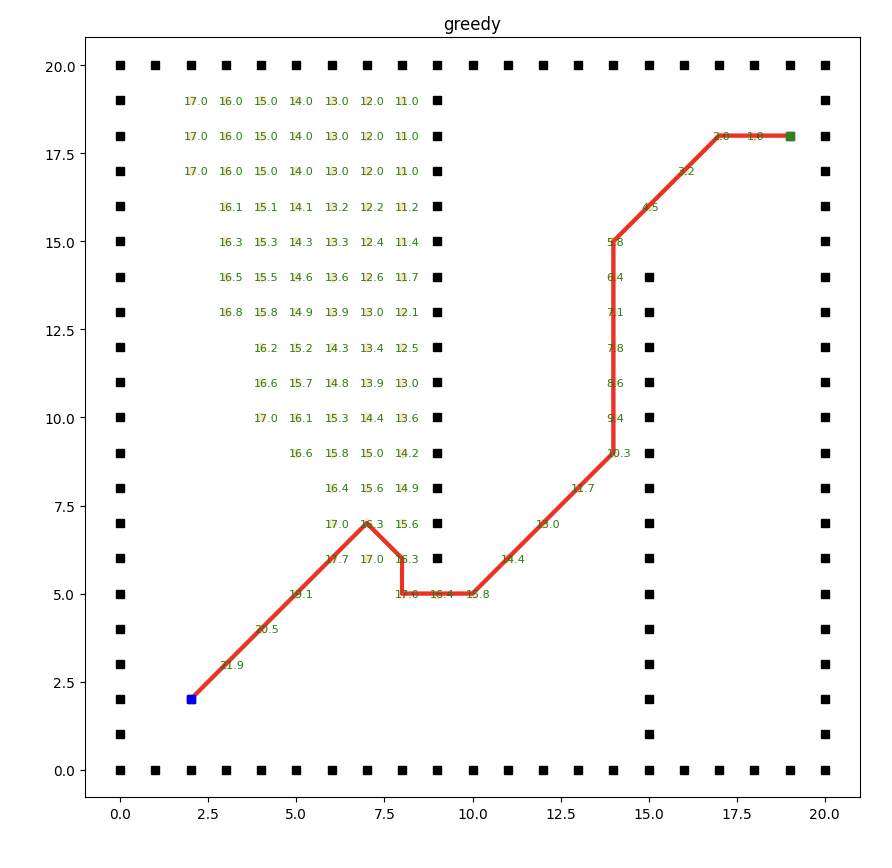
贪婪最佳优先搜索算法的局限性在于它过度依赖启发式函数(heuristic function),该函数用于估计节点到目标节点的距离。
由于启发式函数的估计可能不准确或不全面,算法可能会在搜索过程中陷入局部最优解,导致得到的路径并不是最短的。
代码
def searching(self):
self.PARENT[self.s_start] = self.s_start # 开始节点的父节点
self.h[self.s_start] = math.inf # 开始节点的成本
self.h[self.s_goal] = math.inf # 目标节点的成本
# heappush 函数能够按照 h 值的大小来维护堆的顺序,这意味着self.OPEN堆中的节点将按照 h 值的升序排列,h 值较小的节点将具有较高的优先级。
heapq.heappush(self.OPEN,
(self.heuristic(self.s_start), self.s_start))
while self.OPEN: # 当不为空时,即存在未探索区域
_, s = heapq.heappop(self.OPEN) # 弹出最小的元素,优先级较高
self.CLOSED.append(s) # 将节点加入被访问元素队列
if s == self.s_goal: # stop condition,到达目标点,即停止
break
for s_n in self.get_neighbor(s): # 得到s的邻居节点
new_cost = self.heuristic(s_n) + self.cost(s, s_n) # 计算当时邻居节点s_n的成本=g(s)节点s的成本+s到s_n之间的成本
if s_n not in self.h: # 下一个节点没有遍历过
self.h[s_n] = math.inf # 起点到节点s_n的成本为无穷
if new_cost < self.h[s_n]: # 预估节点s_n成本
A*算法
Dijkstra算法没有考虑到目标节点的位置,因此可能会浪费时间在探索那些与目标节点相距较远的方向上。贪婪最佳优先搜索算法会优先选择离目标节点更近的节点进行扩展。
这样做的好处是它能够更快地找到到达目标节点的路径,但无法保证找到的路径是最短路径,因为它只考虑了节点到目标节点的距离,没有综合考虑到起点到目标节点的实际距离。
A*算法是一种综合了Dijkstra算法和贪婪最佳优先搜索的启发式搜索算法。A*算法同时使用了节点到起点的实际距离(表示为g值)和节点到目标节点的估计距离(表示为h值)。
它通过综合考虑这两个值来评估节点的优先级,并选择优先级最高的节点进行扩展。
A算法通过选择合适的启发式函数来平衡搜索的速度和路径的优劣。当启发式函数满足一定条件时,A算法能够保证找到最短路径。
Dijkstra与贪婪搜索算法对比
在路径规划中,贪婪算法关注的是当前节点到目标节点的距离(启发式函数值),它倾向于选择离目标节点最近的节点作为下一步。
Dijkstra算法关注的是从起点到各个节点的距离,通过不断更新节点的最短距离来逐步扩展路径。
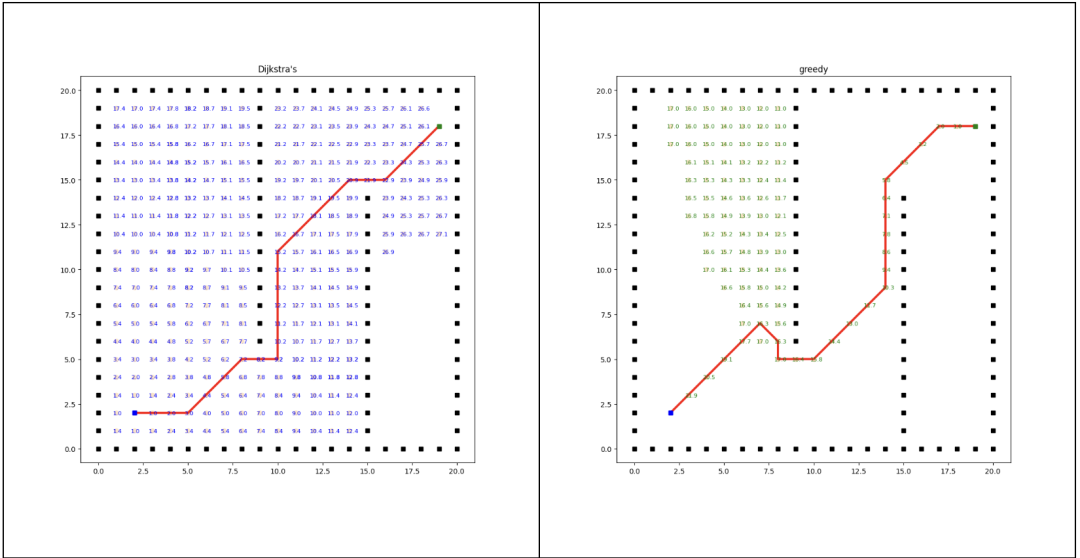
A*算法的成本函数是由两部分组成:g(n)和h(n)。
g(n)表示从起点到达节点n的实际距离(也称为已知最短路径的代价),表示为g(n)。——Dijkstra
h(n)表示从节点n到目标节点的预估距离(也称为启发式函数),表示为h(n)。——贪婪搜索
A算法使用这两个值来评估节点的优先级。具体地,A算法为每个节点计算一个估计总代价f(n),计算公式为:
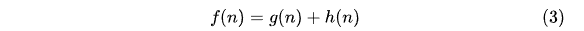
其中,f(n)表示从起点经过节点n到达目标节点的预估总代价。
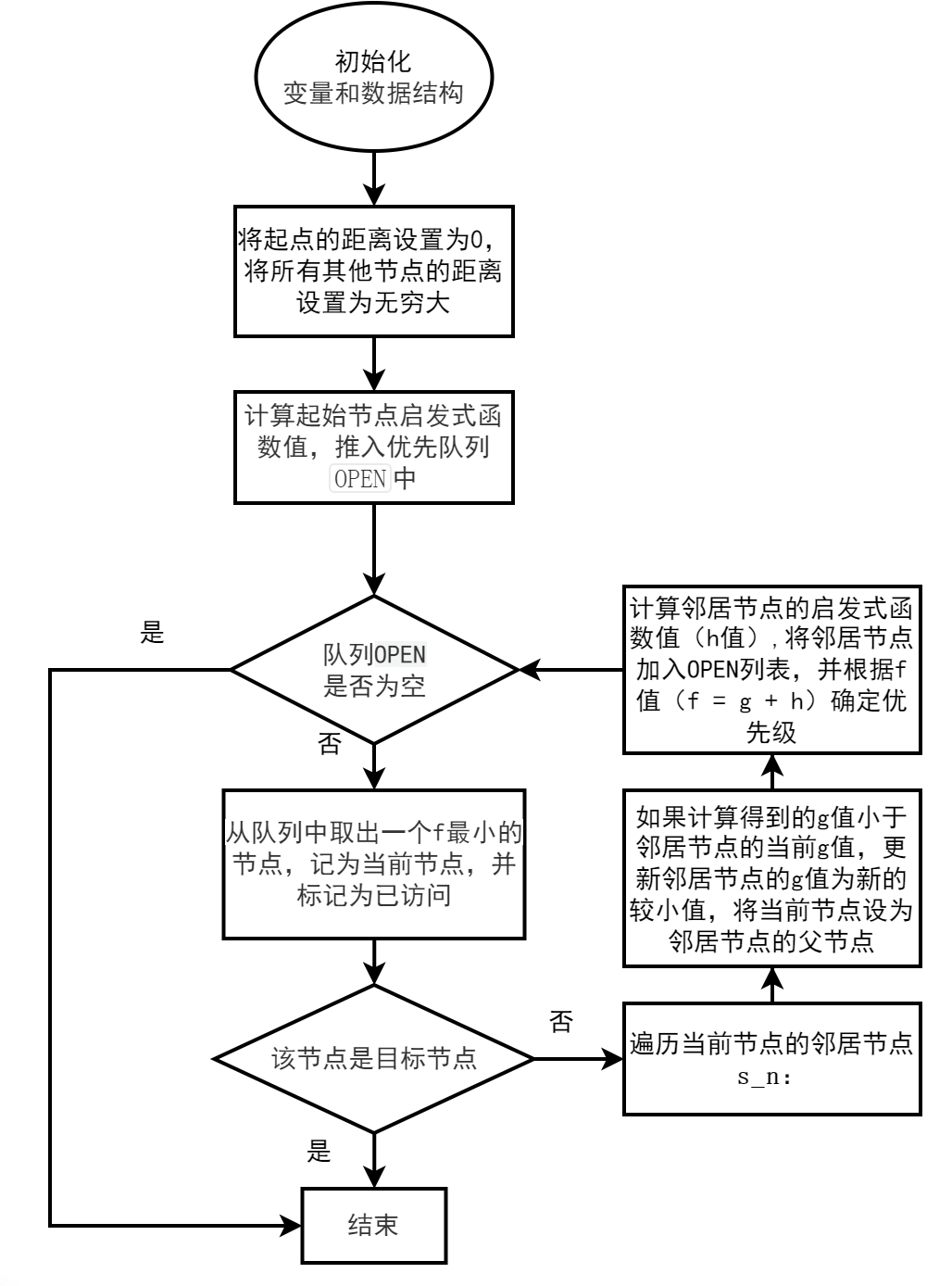
具体步骤如下:
1、初始化:设置起始节点,将起始节点的父节点设置为起始节点本身,将起始节点的成本设置为0,将目标节点的成本设置为无穷大,将起始节点加入到OPEN列表中,使用节点的f值作为优先级。
2、主循环:当OPEN非空时:
从OPEN列表中弹出具有最高优先级的节点,将其加入已访问列表(CLOSED)中。
检查当前节点是否为目标节点。如果是,则跳出循环。
获取当前节点的邻居节点。
对于每个邻居节点,执行以下步骤:
计算从起始节点经过当前节点到达邻居节点的实际距离,即g值。
如果邻居节点不在g字典中,将其g值初始化为无穷大。
如果计算得到的g值小于邻居节点的当前g值,更新邻居节点的g值为新的更小值,并将当前节点设为邻居节点的父节点。
计算邻居节点的启发式函数值,即h值。
将邻居节点加入OPEN列表,并根据f值(f = g + h)确定其优先级。
3、循环结束后,通过从目标节点回溯到起始节点,在PARENT字典中提取最短路径。
算法框图
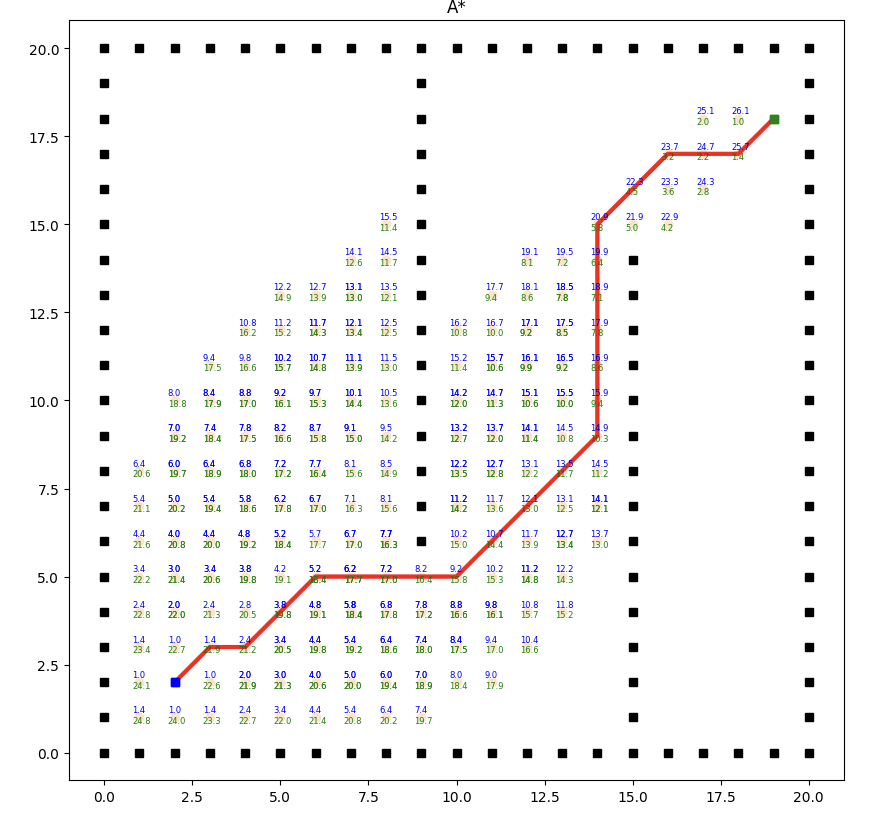
实现效果如下:
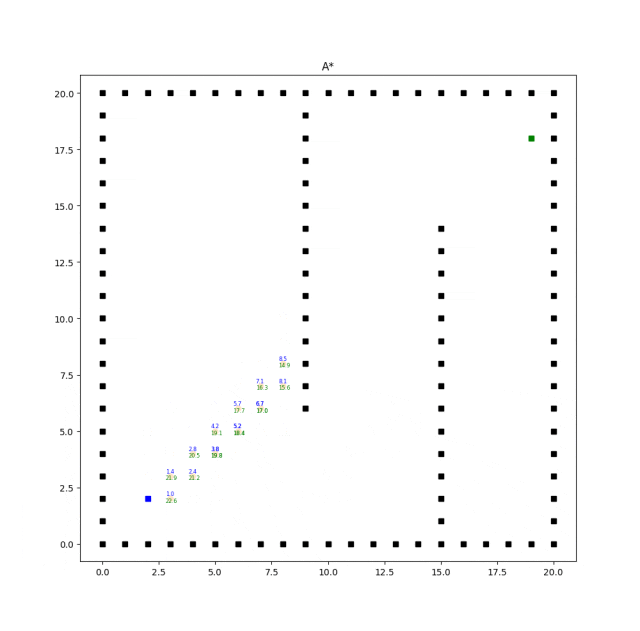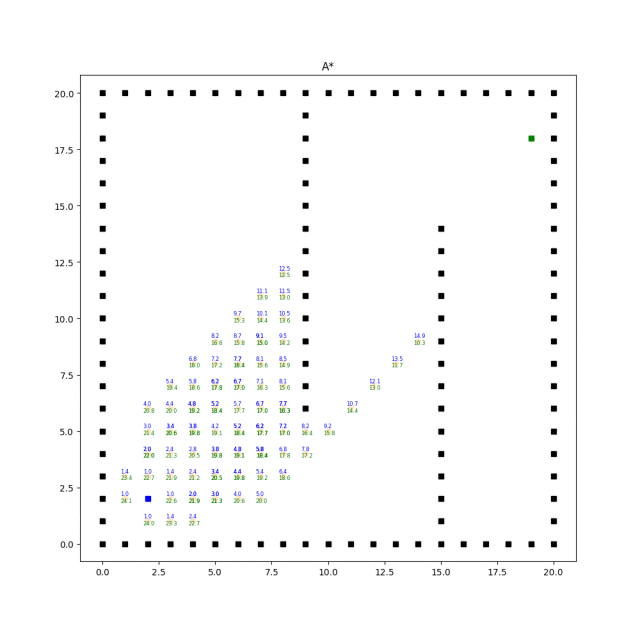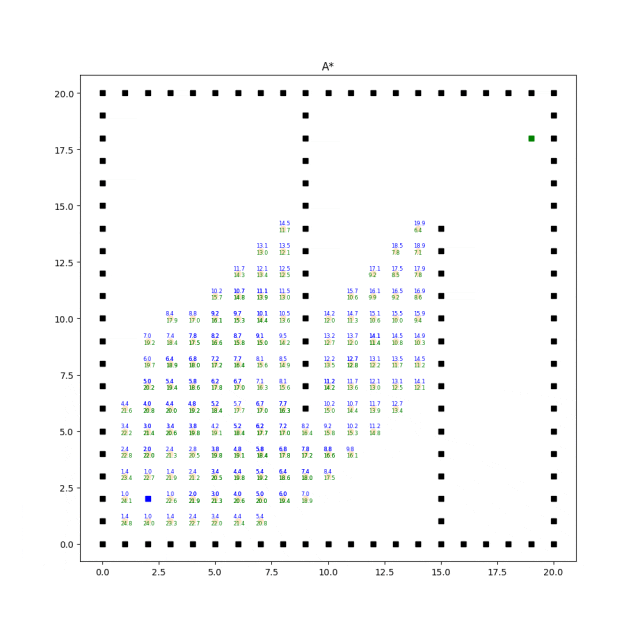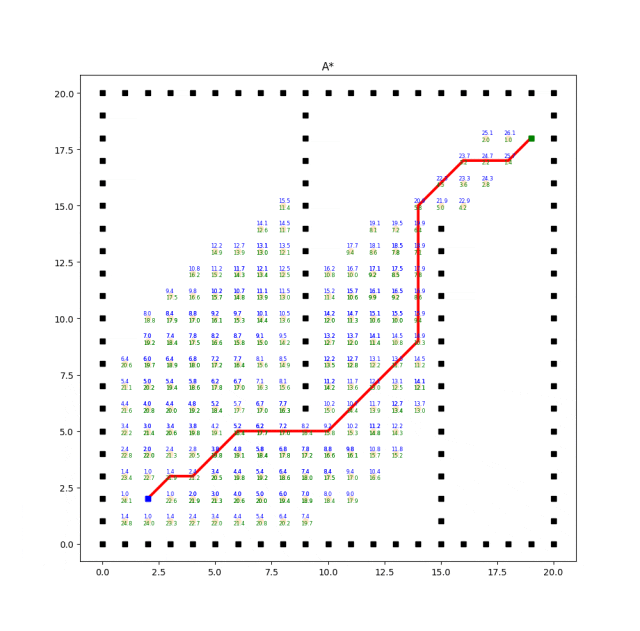
A*算法的效率和质量受启发式函数的选择影响较大。合理选择启发式函数能够提供更好的搜索引导,但不同问题可能需要设计不同的启发式函数。
代码
def searching(self):
"""
A_star Searching.
path, visited order
"""
self.PARENT[self.s_start] = self.s_start # 开始节点的父节点
self.g[self.s_start] = 0 # 开始节点的成本
self.g[self.s_goal] = math.inf # 目标节点的成本
# heappush 函数能够按照 f 值的大小来维护堆的顺序,这意味着self.OPEN堆中的节点将按照 f 值的升序排列,f 值较小的节点将具有较高的优先级。
heapq.heappush(self.OPEN,
(self.f_value(self.s_start), self.s_start))
while self.OPEN: # 当不为空时,即存在未探索区域
_, s = heapq.heappop(self.OPEN) # 弹出最小的元素,优先级较高
self.CLOSED.append(s) # 将节点加入被访问元素队列
if s == self.s_goal: # stop condition,到达目标点,即停止
break
for s_n in self.get_neighbor(s): # 得到s的邻居节点
new_cost = self.g[s] + self.cost(s, s_n) # 计算当时邻居节点s_n的成本=g(s)节点s的成本+s到s_n之间的成本
if s_n not in self.g:
self.g[s_n] = math.inf # 起点到节点s_n的成本为无穷
if new_cost < self.g[s_n]: # 预估节点s_n成本
-
算法
+关注
关注
23文章
4608浏览量
92844 -
Dijkstra
+关注
关注
0文章
13浏览量
8441
原文标题:自动驾驶 | 路径规划算法Dijkstra与A*
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自动驾驶路径规划威廉希尔官方网站 之A-Star算法
经典算法大全(51个C语言算法+单片机常用算法+机器学十大算法)
基于OpenHarmony的智能助老服务系统
基于Dijkstra的PKI交叉认证路径搜索算法
基于有向非负极图数据DIJKSTRA算法
基于Dijkstra最短路径的抽样算法
基于改进Dijkstra的端端密钥协商最优路径选择算法
基于Dijkstra算法的配电网孤岛划分
使用英特尔编译器优化Dijkstra最短路径图算法

全文详解A*算法及其变种

中国铁路网的Dijkstra算法实现案例





 工商网监
工商网监
评论