 NVIDIA AI Enterprise 提供了简化端到端人工智能管道的软件
NVIDIA AI Enterprise 提供了简化端到端人工智能管道的软件
随着人工智能计划的进展,为企业提供可信、可扩展的支持模型的需求对于确保人工智能项目保持正轨至关重要。为了支持构建人工智能应用程序, NVIDIA AI Enterprise 提供了简化端到端人工智能管道的软件,从数据准备到模型训练,再到interwetten与威廉的赔率体系 和大规模部署。
NVIDIA AI Enterprise 是 NVIDIA 人工智能平台的软件层,包括:
优化以在加速的基础架构上运行,从而实现性能、生产效率和成本节约。
企业级支持、安全性和 API 稳定性。
人工智能工作流程和预先训练的模型,以加快生产时间。
直接在 Snowflake 数据云上启用 AI 工作流
数据是生成型人工智能的燃料,而为企业人工智能用例提供燃料的数据就存在于 Snowflake 中。 Snowpark Container Services 现在提供了 NVIDIA AI 平台,客户可以在不牺牲安全性、性能或易用性的情况下将数据投入使用。
通过 Snowpark Container Services 使用 NVIDIA AI Enterprise 加速基础设施和计算库,开发人员和数据科学家可以轻松构建加速的 AI 工作流程。
使用 Snowpark,企业可以安全地部署和处理用于人工智能和 ML 的 Python 代码。开发人员还可以扩展加速的 ML 工作负载,并在已存储数据的地方运行复杂的人工智能模型,如 LLM 。这样可以减少潜在的安全风险和延迟,特别是当移动大量数据时。
以下工作流程展示了数据科学家如何实现从数据处理到实时推理的每个阶段,作为新合作伙伴关系的一部分。本工作流程和示例用例中概述的威廉希尔官方网站 ,包括 NVIDIA RAPIDS 、 NVIDIA / Merlin 、 NVIDIA TensorRT 和 NVIDIA SGG2 ,都包含在 NVIDIA AI Enterprise 中,并可在 Snowpark Container Services 上获得。
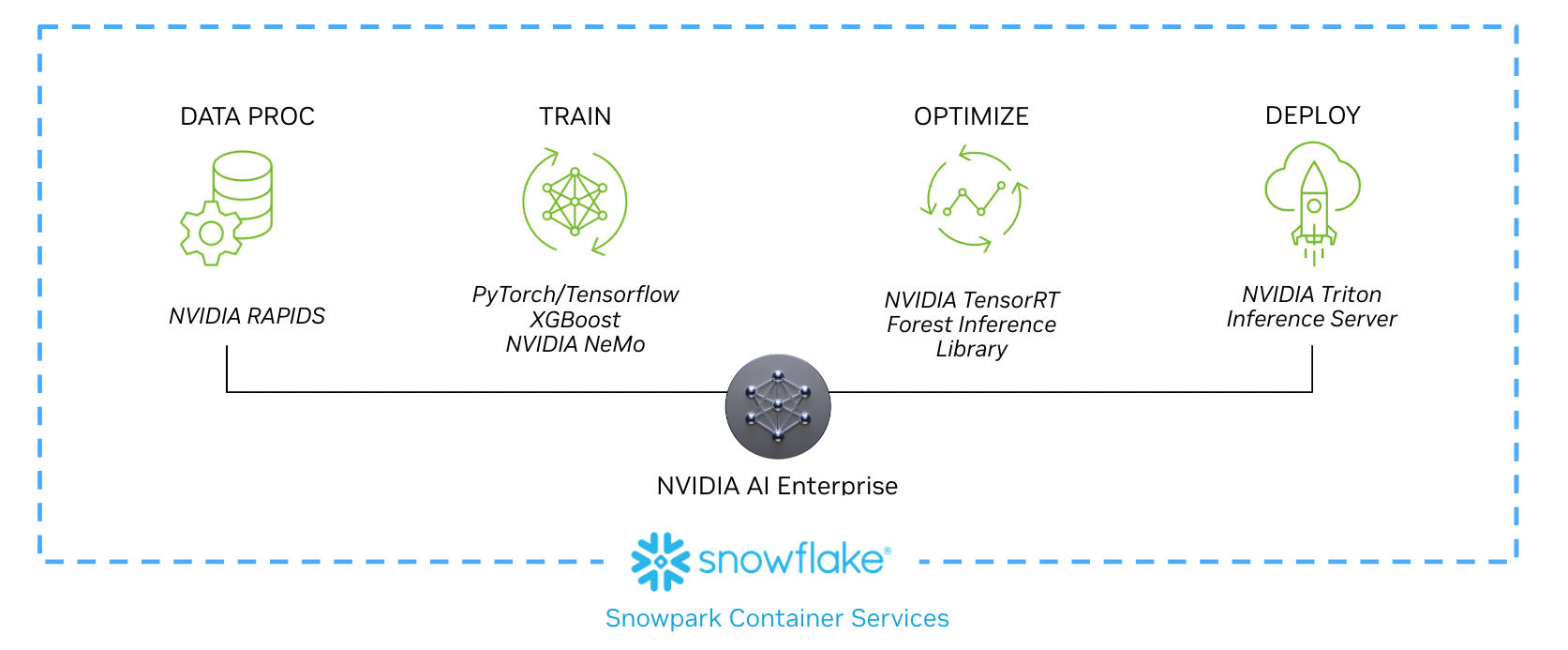
图 1 。使用 NVIDIA AI Enterprise 从 Snowpark Container Services 中存储的数据构建 AI 模型的示例工作流
示例用例:训练推荐模
基于会话的推荐系统在内容丰富的应用程序中变得越来越重要,这些应用程序旨在提供更相关的下一个项目预测。训练这些模型首先要加载数据,并使用 Snowpark Python 库进行初始 SQL 和 DataFrame 预处理。
客户可以在 Snowpark Container Services 中运行的 Jupyter Notebook 中使用 NVIDIA RAPIDS 、 Merlin 和其他人工智能框架来增强数据处理和训练模型。
NVTabular 是 Merlin 的一部分,是一个加速特征工程库,旨在生成推荐系统模型训练所需的关键特征。使用 NVTabular 准备数据后, Merlin 中的其他加速计算库开始训练人工智能工作流程。
在非常大的数据集上训练模型的任务可能非常耗时。在训练过程中,当计算核心处理数据集时,数据集通常会被分块复制到内存中或从内存中复制出来。使用 GPU 训练模型可以提供更高的吞吐量和更快的模型训练,因为它们包括高带宽内存,并利用越来越多的计算核心进行并行处理。
在 Snowpark 容器服务上运营导致在具有加速计算的预测模型的训练期间提速20倍。这极大地提高了数据科学家在模型创建过程中的生产力,并通过在更短的时间内完成更多任务来降低总体拥有成本。
训练完成后,使用样本测试数据测试模型的准确性。接着,根据需要对模型进行优化和重新训练。最后,将新训练的模型发布到注册表中,例如Snowpark 模型注册表(私人预览)。
经过培训, NVIDIA AI Enterprise 提供了 TensorRT ,用于加速计算的优化。在工作流的最后阶段,模型部署并开始执行推理任务。它在 Triton 推理服务器内运行,实时消耗数据并提供见解。
-
NVIDIA
+关注
关注
14文章
5013浏览量
103245 -
AI
+关注
关注
87文章
31097浏览量
269430 -
人工智能
+关注
关注
1792文章
47409浏览量
238923
发布评论请先 登录
相关推荐
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
了解AI人工智能背后的科学?
AI智能芯片火热,全芯片产业链都积极奔着人工智能去
全语音人工智能AI耳机,或将引爆智能耳机市场
人工智能:超越炒作
人工智能芯片是人工智能发展的
Arm Neoverse NVIDIA Grace CPU 超级芯片:为人工智能的未来设定步伐
《移动终端人工智能威廉希尔官方网站 与应用开发》人工智能的发展与AI威廉希尔官方网站 的进步
《移动终端人工智能威廉希尔官方网站 与应用开发》+理论学习
VMware和Nvidia将联手加速企业人工智能应用程序的开发
NVIDIA AI Enterprise 2.1版本亮点一览
使用 NVIDIA AI Enterprise 3.0 优化生产级 AI 的性能和效率





 工商网监
工商网监
评论