 从Arm的TCS23参考设计,看明年的手机性能提升
从Arm的TCS23参考设计,看明年的手机性能提升
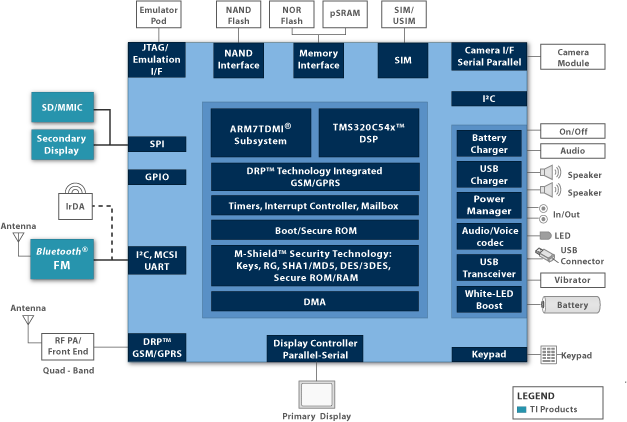
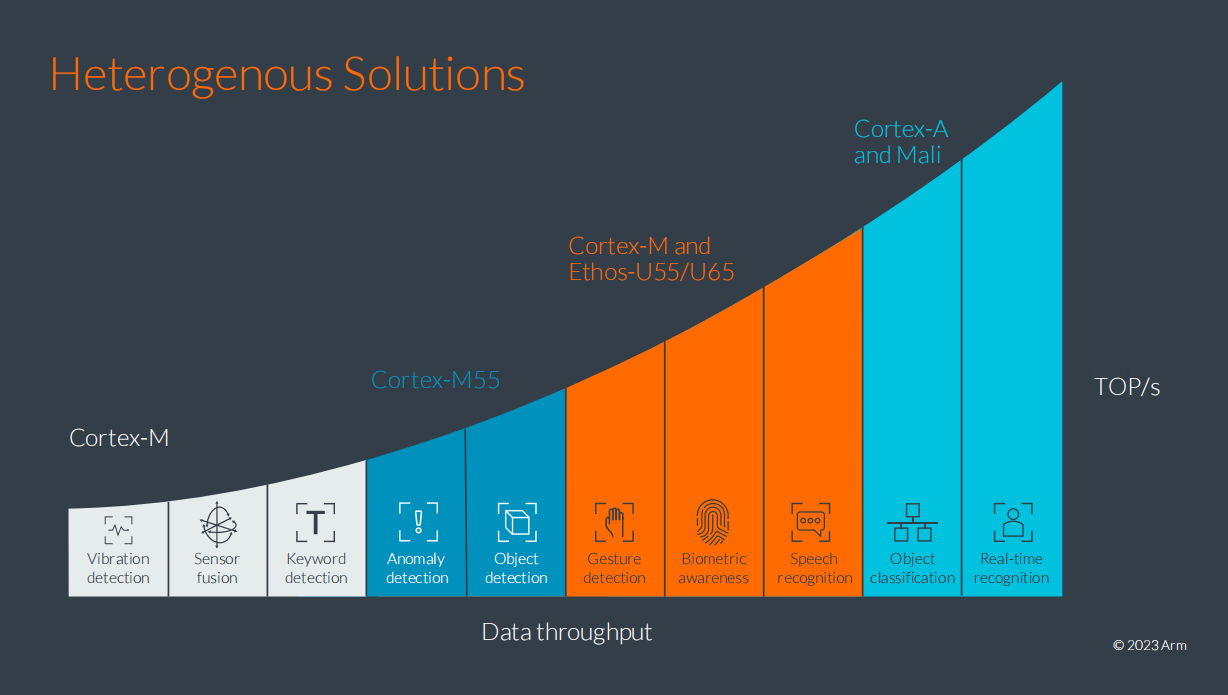
其实Arm前一阵已经正式发布了TCS23(Total Compute Solutions 23)平台,以及对应的IP产品,包括Cortex-X4、A720、A520这些Armv9架构的CPU IP,最新的Immortalis-G720——也就是基于Arm第五代GPU微架构的新IP,以及更新后的DSU。毫无疑问的,这些IP会成为接下来1-2年手机AP SoC的焦点。
最近Arm特别在中国的媒体威廉希尔官方网站
日上,花较多篇幅去谈这些IP及TCS23平台的组成细节。Arm从解决方案、CPU/GPU及相关IP、软件、安全四个方面做了比较大篇幅的分享。
几个核心IP应该是普罗大众最关心的,包括全面彻底迁往AArch64的CPU IP,新一代的Immortalis GPU,以及新版DSU-120(DynamIQ Shared Unit)。这几个组成部分,我们将另外撰文详述。
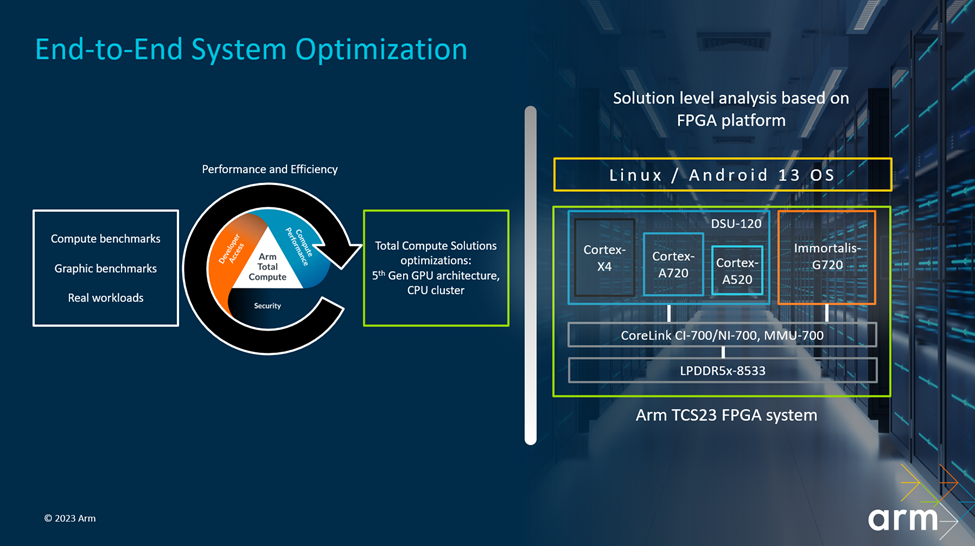
实际上Arm推的TCS23解决方案也已经是第3代了。大部分人对于“解决方案”于Arm IP这套生态的理解,应该就是将IP打包发售。但实际上,TCS是从设计角度,更综合、整体的范围去提升性能和效率的存在。
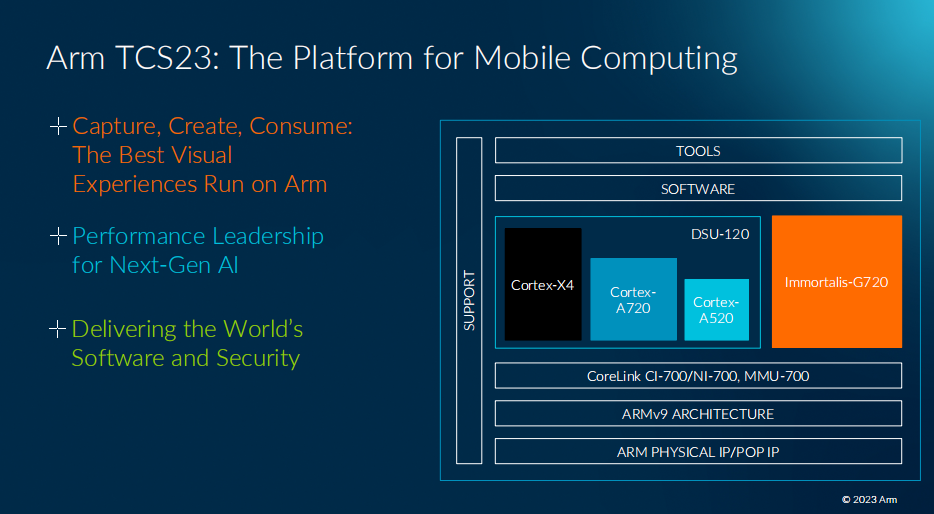
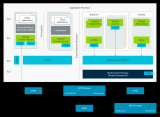
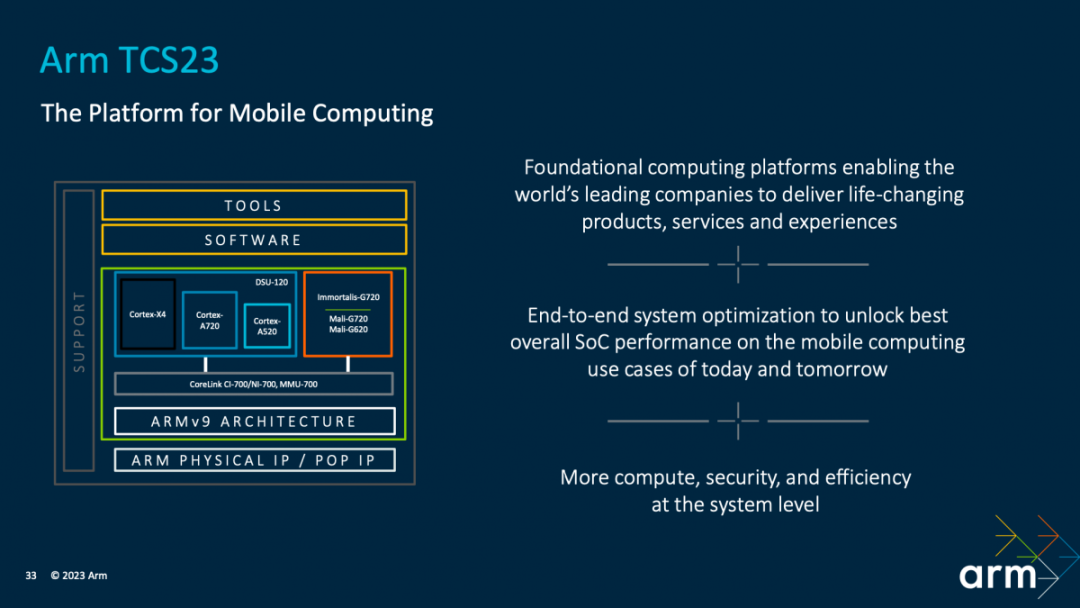 具体如上图所示,大部分人关心的是处在中间的环节,即Armv9架构及其上的存储与互联一致性、各种核心IP。实际TCS还包括图中的软件、开发工具,以及以先进工艺做Arm IP实施的物理IP。
Arm终端事业部产品管理高级总监Kinjal Dave说:“谈到解决方案,为什么 Arm 要采取这样一种全局的方法论来开发解决方案,不断推高性能、提高效率,本身变得越来越难且成本高昂。其实这对 Arm 来说,意味着我们每年推出的 TCS 在性能跟效率方面,都必须实现进步。所以,我们要采取一种平衡。”
Kinjal说Arm这些年来始终努力在benchmark和真实使用场景之间做平衡:“一方面,单独的 IP 要不断把它做强,另外一方面把这些单独的 IP 集合在一起时,总体的系统级别也要实现性能效率的双提升。” “为我们的合作伙伴提供融合了这些单独IP的系统级解决方案所带来的完整性能提升。”
随着摩尔定律的放缓,以及设计层面各种经典威廉希尔官方网站
的全面上线,这两年单独IP微架构层面带来的性能和效率提升也远不及此前那么大了,从更系统的角度来做考量也是半导体链条上各个玩家的共识。
所以这篇文章我们就从TCS23整体的角度来看看这一代平台的改进,其中会涉及到上述IP,但不会过多深入。另外很难得的是,Arm特别用一个主题演讲的章节去谈了软件改进,包括编译器、SVE2指令、Android动态性能框架等,本文也会略有涉及。
TCS23参考设计
本文就不过多提单独IP的性能与效率变化了,包括Cortex-X4相比X3性能提升15%,Cortex-A720相比A715能效提升20%,Cortex-A520相比A510能效提升22%,DSU提升动态功耗表现、针对闲置与低负载场景的新功耗模式,Immortalis-G720性能提升15%、带宽用量降低40%等等。
具体如上图所示,大部分人关心的是处在中间的环节,即Armv9架构及其上的存储与互联一致性、各种核心IP。实际TCS还包括图中的软件、开发工具,以及以先进工艺做Arm IP实施的物理IP。
Arm终端事业部产品管理高级总监Kinjal Dave说:“谈到解决方案,为什么 Arm 要采取这样一种全局的方法论来开发解决方案,不断推高性能、提高效率,本身变得越来越难且成本高昂。其实这对 Arm 来说,意味着我们每年推出的 TCS 在性能跟效率方面,都必须实现进步。所以,我们要采取一种平衡。”
Kinjal说Arm这些年来始终努力在benchmark和真实使用场景之间做平衡:“一方面,单独的 IP 要不断把它做强,另外一方面把这些单独的 IP 集合在一起时,总体的系统级别也要实现性能效率的双提升。” “为我们的合作伙伴提供融合了这些单独IP的系统级解决方案所带来的完整性能提升。”
随着摩尔定律的放缓,以及设计层面各种经典威廉希尔官方网站
的全面上线,这两年单独IP微架构层面带来的性能和效率提升也远不及此前那么大了,从更系统的角度来做考量也是半导体链条上各个玩家的共识。
所以这篇文章我们就从TCS23整体的角度来看看这一代平台的改进,其中会涉及到上述IP,但不会过多深入。另外很难得的是,Arm特别用一个主题演讲的章节去谈了软件改进,包括编译器、SVE2指令、Android动态性能框架等,本文也会略有涉及。
TCS23参考设计
本文就不过多提单独IP的性能与效率变化了,包括Cortex-X4相比X3性能提升15%,Cortex-A720相比A715能效提升20%,Cortex-A520相比A510能效提升22%,DSU提升动态功耗表现、针对闲置与低负载场景的新功耗模式,Immortalis-G720性能提升15%、带宽用量降低40%等等。
 不过Arm针对TCS23就FPGA级别做了参考设计,“代表真实的芯片设备”。Arm做参考设计的原因,一是IP越来越复杂,其次是系统中的许多特性是需要跨系统的,比如说这次Arm一直在谈的MTE(Memory Tagging Extention)安全特性;
另外还包括“越来越多样化终端使用场景的出现”,以及“对这些芯片设计工作来说,在设计选择以及平衡方面的取舍难度也提高了。”
不过Arm针对TCS23就FPGA级别做了参考设计,“代表真实的芯片设备”。Arm做参考设计的原因,一是IP越来越复杂,其次是系统中的许多特性是需要跨系统的,比如说这次Arm一直在谈的MTE(Memory Tagging Extention)安全特性;
另外还包括“越来越多样化终端使用场景的出现”,以及“对这些芯片设计工作来说,在设计选择以及平衡方面的取舍难度也提高了。”
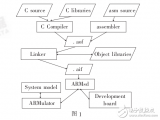
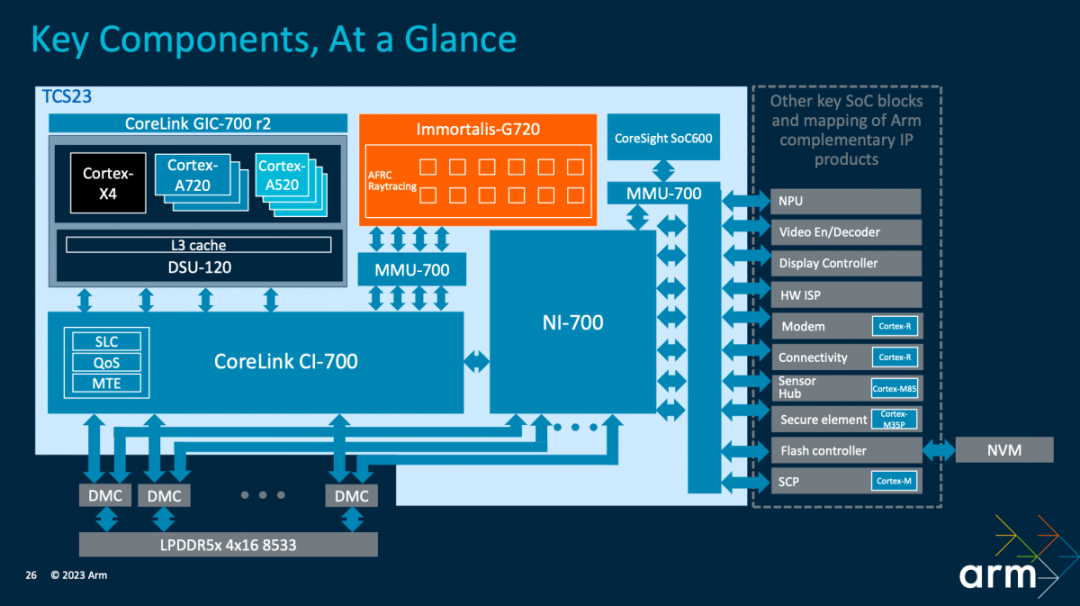 上面这张图就是Arm TCS23参考设计。大框架上CPU、GPU都用了这一代最新IP。不同核心组成的CPU集群,“与DSU-120共同连接到共享系统的背板(backplane)”;借助system cache(SLC)所在的CoreLink CI-700,一边连接到Immortalis-G720 GPU。
这里CoreLink CI-700作为存储系统的核心,为所有的IO流量提供一个汇聚点(也用于实现MTE)。同时,NI-700为所有其他流量提供一条通往DRAM独立的路径;“能进行QoS执行,允许不同的流量类型一起流动,而不会出现交叉流,或者互相阻塞的情况”。
系统级解决方案的奥义
参考设计的CPU部分,是1x Cortex-X4, 3x Cortex-A720, 4x Cortex-A520的配置;DSU-120配了8MB L3 cache。Arm认为1+3+4是性能和效率可达成均衡的配置方案。不过在多线程性能对比时,Arm也有基于1+5+2的搭配呈现。
上面这张图就是Arm TCS23参考设计。大框架上CPU、GPU都用了这一代最新IP。不同核心组成的CPU集群,“与DSU-120共同连接到共享系统的背板(backplane)”;借助system cache(SLC)所在的CoreLink CI-700,一边连接到Immortalis-G720 GPU。
这里CoreLink CI-700作为存储系统的核心,为所有的IO流量提供一个汇聚点(也用于实现MTE)。同时,NI-700为所有其他流量提供一条通往DRAM独立的路径;“能进行QoS执行,允许不同的流量类型一起流动,而不会出现交叉流,或者互相阻塞的情况”。
系统级解决方案的奥义
参考设计的CPU部分,是1x Cortex-X4, 3x Cortex-A720, 4x Cortex-A520的配置;DSU-120配了8MB L3 cache。Arm认为1+3+4是性能和效率可达成均衡的配置方案。不过在多线程性能对比时,Arm也有基于1+5+2的搭配呈现。
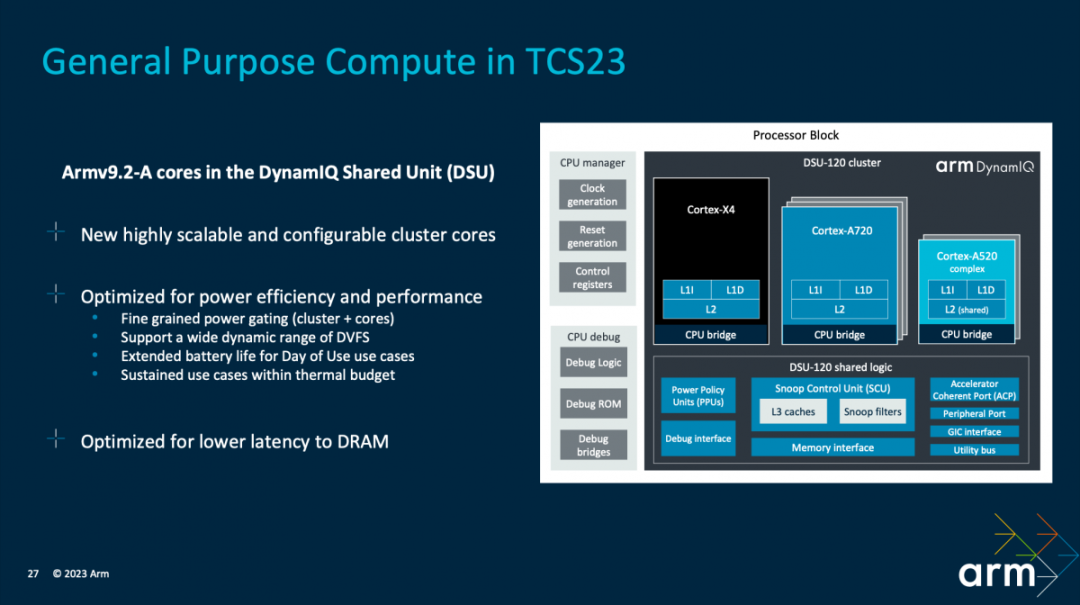 Kinjal没有细谈这部分的配置。不过这里主要看的还是系统级别的工作。他强调CPU集群的关键首先是如何利用CPU和行为架构实现跨越三个层级的性能动态范围;其次影响CPU性能很重要的因素是DRAM延迟。
对于后者,一方面,“我们进行了DRAM结构性的静态延迟优化”,“首先是DynamIQ共享单元内和通往内存的路径中的时钟配置的选择,也就是在这个领域资源的竞争”——在这个过程里,需要进行DynamIQ时钟配置优化,“同时要最小化数量的选择”;
另一方面,还需要考虑“加载系统内存层面下的动态优先级别”,包括“GPU、摄像头以及其他多媒体管道等”,“它们可能要同时访问内存”。这些都要求在进行CPU集群配置时,做相应的考量。
Kinjal没有细谈这部分的配置。不过这里主要看的还是系统级别的工作。他强调CPU集群的关键首先是如何利用CPU和行为架构实现跨越三个层级的性能动态范围;其次影响CPU性能很重要的因素是DRAM延迟。
对于后者,一方面,“我们进行了DRAM结构性的静态延迟优化”,“首先是DynamIQ共享单元内和通往内存的路径中的时钟配置的选择,也就是在这个领域资源的竞争”——在这个过程里,需要进行DynamIQ时钟配置优化,“同时要最小化数量的选择”;
另一方面,还需要考虑“加载系统内存层面下的动态优先级别”,包括“GPU、摄像头以及其他多媒体管道等”,“它们可能要同时访问内存”。这些都要求在进行CPU集群配置时,做相应的考量。
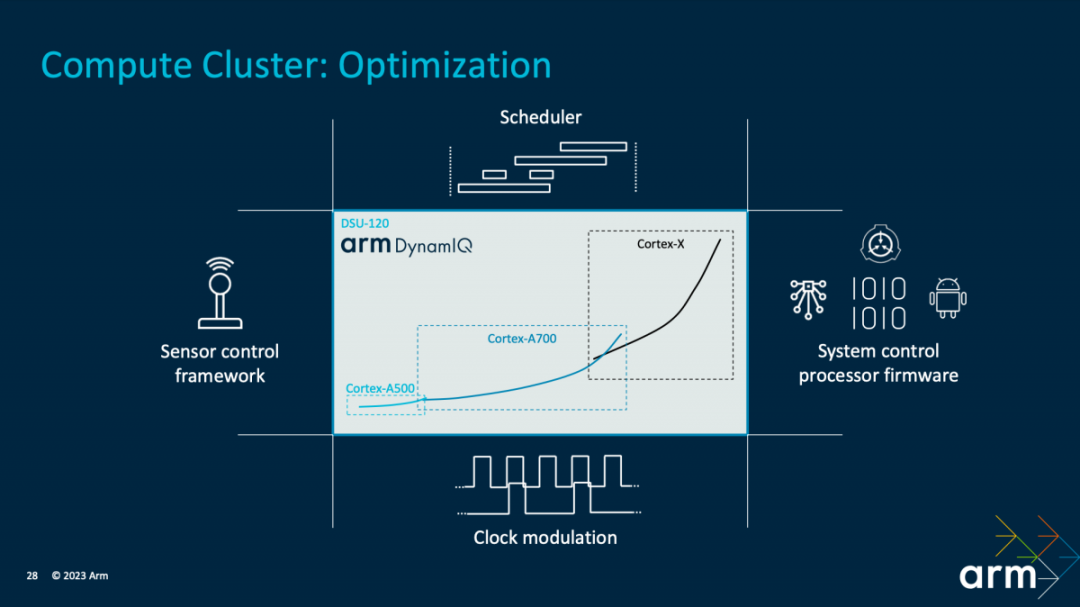 在CPU集群的优化上,首先是基于“CPU核心微架构”提供“最为广泛的动态范围”,“跨越三层(Cortex X4,Cortex A720和Cortex A520)”。其中包括DVFS动态调整,线程核心迁移等;适配各种负载场景、应对不同的性能目标。此间涵盖以最优化的效率,针对不同的运行场景,包括了分配多少CPU资源,如频率、响应、哪些核心参与等等。
“计算IP级的系统级解决方案,包括不同电源选择的模式,不同时钟选项的配置”,“在TCS23中我们添加了一个逻辑增强型降功耗的模式”。
“在解决方案层级,我们的电源控制固件的堆栈以及调度器一起工作,能实现基于不同的使用场景的选择,这点很关键。”Kinjal说,“TCS23解决方案中还有一个系统控制处理器,它能够协调传感器控制框架,在各个CPU内核以及DSU-120工作点之间移动的时候充分考虑到散热以及输电的一些限制因素。”“跨整个CPU集群,我们还实施了积极的时钟门控以及时空调节的机制,来节约动态功耗。”
在CPU集群的优化上,首先是基于“CPU核心微架构”提供“最为广泛的动态范围”,“跨越三层(Cortex X4,Cortex A720和Cortex A520)”。其中包括DVFS动态调整,线程核心迁移等;适配各种负载场景、应对不同的性能目标。此间涵盖以最优化的效率,针对不同的运行场景,包括了分配多少CPU资源,如频率、响应、哪些核心参与等等。
“计算IP级的系统级解决方案,包括不同电源选择的模式,不同时钟选项的配置”,“在TCS23中我们添加了一个逻辑增强型降功耗的模式”。
“在解决方案层级,我们的电源控制固件的堆栈以及调度器一起工作,能实现基于不同的使用场景的选择,这点很关键。”Kinjal说,“TCS23解决方案中还有一个系统控制处理器,它能够协调传感器控制框架,在各个CPU内核以及DSU-120工作点之间移动的时候充分考虑到散热以及输电的一些限制因素。”“跨整个CPU集群,我们还实施了积极的时钟门控以及时空调节的机制,来节约动态功耗。”
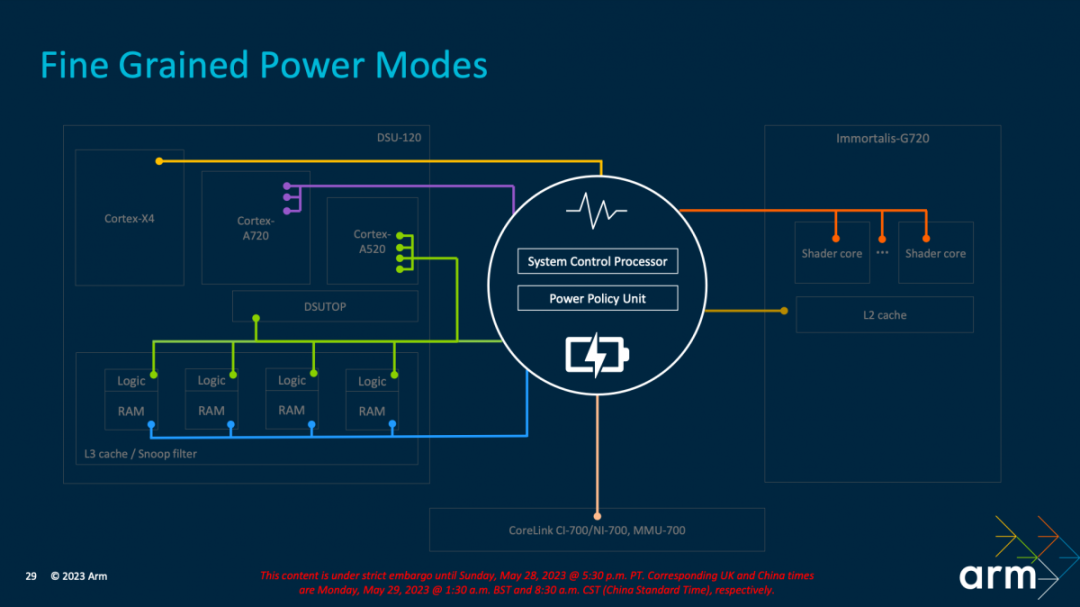 另一个关键是细粒度的电源模式——这也是当代低功耗设计的精髓所在。上面这张图每种颜色代表“单独的电源连接供电”。Arm在此的工作之一就是管理供电的复杂性,“我们有专门用于电压供应的管理、电源传输、网络控制电源控制部件。
“这里电源控制部件是与调度器,以及操作系统的电源管理软件共同协调工作的。”
另一个关键是细粒度的电源模式——这也是当代低功耗设计的精髓所在。上面这张图每种颜色代表“单独的电源连接供电”。Arm在此的工作之一就是管理供电的复杂性,“我们有专门用于电压供应的管理、电源传输、网络控制电源控制部件。
“这里电源控制部件是与调度器,以及操作系统的电源管理软件共同协调工作的。”
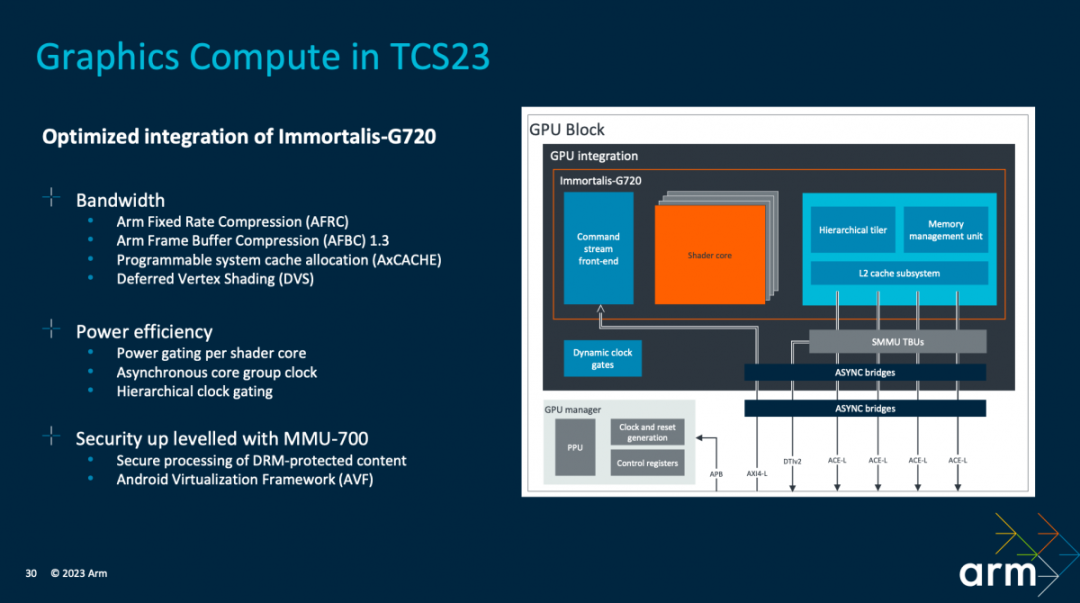 图形计算相关的部分,Arm强调了3个解决方案层面的关注点,分别是带宽、功耗,与安全性。“我们将Arm Immotalis-G720集成到TCS23解决方案中,配置了MMU-700,与GPU实现共同的优化”。其中的某些部分,也会在我们后续的IP文章GPU相关部分做更详尽的介绍——比如节约带宽的Deferred Vertex Shading延迟顶点着色。
从大方向来看,节约带宽方面的工作包括AFRC与AFBC无损压缩——管线不同阶段的数据压缩始终是GPU不变的话题之一,它对于DRAM访问需求的降低,提供更大的发热空间都有价值;IO一致性,将缓存维护开销降到最低,并由CoreLink CI-700与Immortalis-G720合作,来达成性能的提升;以及利用大型系统高速缓存(system cache),而且还有个“内存分配提示,优先考虑哪部分要存在高速缓存中”。
能效优化部分,一方面是利用针对每个shader核心的power gating,另外就是核心群组的节电模式等。“TCS23解决方案提供了一套完整的参考:Immortalis-G720驱动如何与我们的参考固件堆栈协同,实现电源控制、动态电压与频率的调节。”另外,“我们在GPU中也实施了积极的clock gating方案,用以管理动态功耗。”
安全性方面,MMU-700的集成对于支持DRAM保护内容的安全处理,以及支持Android虚拟化框架是至关重要的。
图形计算相关的部分,Arm强调了3个解决方案层面的关注点,分别是带宽、功耗,与安全性。“我们将Arm Immotalis-G720集成到TCS23解决方案中,配置了MMU-700,与GPU实现共同的优化”。其中的某些部分,也会在我们后续的IP文章GPU相关部分做更详尽的介绍——比如节约带宽的Deferred Vertex Shading延迟顶点着色。
从大方向来看,节约带宽方面的工作包括AFRC与AFBC无损压缩——管线不同阶段的数据压缩始终是GPU不变的话题之一,它对于DRAM访问需求的降低,提供更大的发热空间都有价值;IO一致性,将缓存维护开销降到最低,并由CoreLink CI-700与Immortalis-G720合作,来达成性能的提升;以及利用大型系统高速缓存(system cache),而且还有个“内存分配提示,优先考虑哪部分要存在高速缓存中”。
能效优化部分,一方面是利用针对每个shader核心的power gating,另外就是核心群组的节电模式等。“TCS23解决方案提供了一套完整的参考:Immortalis-G720驱动如何与我们的参考固件堆栈协同,实现电源控制、动态电压与频率的调节。”另外,“我们在GPU中也实施了积极的clock gating方案,用以管理动态功耗。”
安全性方面,MMU-700的集成对于支持DRAM保护内容的安全处理,以及支持Android虚拟化框架是至关重要的。
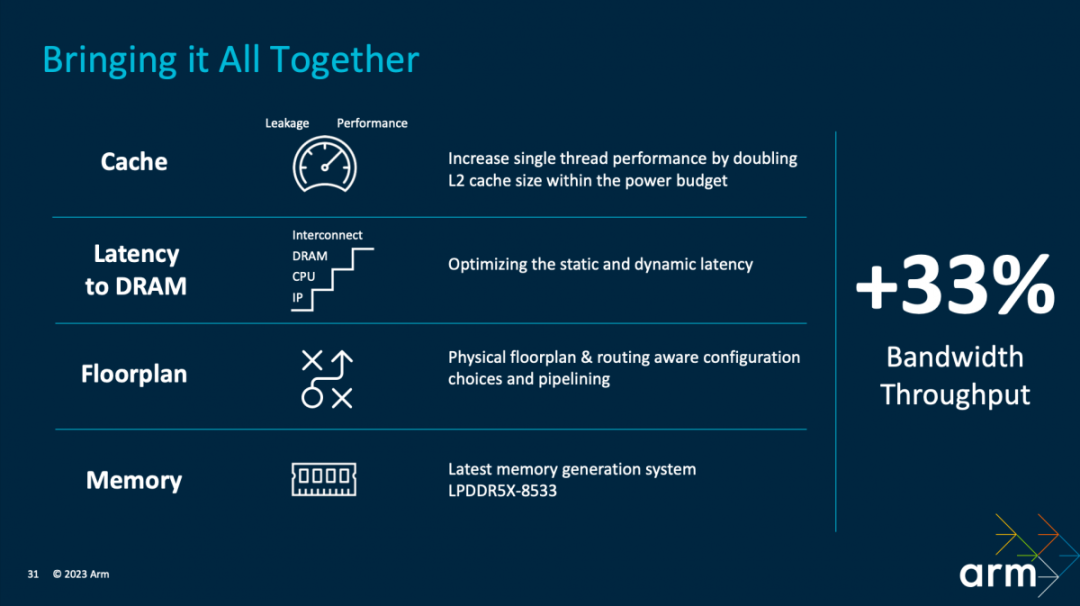 结合包括cache、连接至内存的延迟、floorplan以及内存支持方面的变化,参考设计达成综合的带宽吞吐,相比于前代提升了33%。
所以在总结性发言里,Kinjal再度强调的一点就是基于TCS全面计算解决方案,“Arm已经超越单个IP产品,为客户实现端到端系统级的优化,从而释放整个SoC系统全面性能”。这是TCS存在的核心价值。
软件带来的性能提升
除了这些比较多人关注的IP之外,如文首所述,TCS作为解决方案还涵盖了工具、软件、物理/POP IP等。这里我们再谈一谈工具和软件,TCS23不仅升级了IP,也升级了软件与工具。Arm终端事业部生态系统及工程高级总监Geraint North说Arm的工程师中,超过45%都是软件工程师,底层部分涵盖了驱动、Linux内核,往上则有软件框架、性能分析工具、开发者教学、最佳实践等。
结合包括cache、连接至内存的延迟、floorplan以及内存支持方面的变化,参考设计达成综合的带宽吞吐,相比于前代提升了33%。
所以在总结性发言里,Kinjal再度强调的一点就是基于TCS全面计算解决方案,“Arm已经超越单个IP产品,为客户实现端到端系统级的优化,从而释放整个SoC系统全面性能”。这是TCS存在的核心价值。
软件带来的性能提升
除了这些比较多人关注的IP之外,如文首所述,TCS作为解决方案还涵盖了工具、软件、物理/POP IP等。这里我们再谈一谈工具和软件,TCS23不仅升级了IP,也升级了软件与工具。Arm终端事业部生态系统及工程高级总监Geraint North说Arm的工程师中,超过45%都是软件工程师,底层部分涵盖了驱动、Linux内核,往上则有软件框架、性能分析工具、开发者教学、最佳实践等。
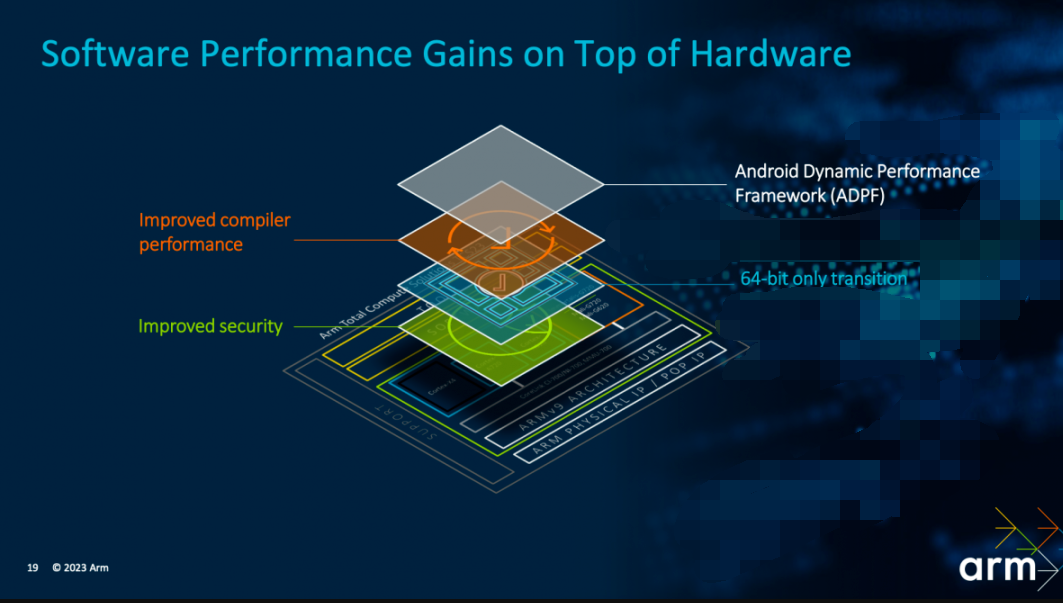 软件自然是位于硬件之上的层级,这部分Geraint主要谈了64bit完全迁移、compiler编译器性能提升,以及ADPF(Android自适应性能框架)带来的软件层面的性能提升。
实际上就软件相关的主题演讲,Arm还特别花篇幅去谈了安全,包括MTE、PAC/BTI威廉希尔官方网站
及对应生态——谈到与谷歌、Unity在安全特性上的合作,甚至在MTE(Memory Tagging Extension)威廉希尔官方网站
上,还特别找来快手、联发科、vivo这些合作伙伴站台。不过这次我们不会把笔墨放在安全问题上,即便这个问题就当代移动威廉希尔官方网站
而言正变得格外重要。
有关64位生态迁移的话题,桎梏并不在芯片和操作系统厂商身上,而在最上层的App开发者身上。自11年以前,CPU层面提供64位支持(Cortex-A57/A53),以及2年后Android操作系统跟进,一直到今年Pixel 7作为纯64位Android配置的手机问世,这仍然是个相当漫长的过程。而TCS23是彻底构建起纯64bit支持集群的一代。
软件自然是位于硬件之上的层级,这部分Geraint主要谈了64bit完全迁移、compiler编译器性能提升,以及ADPF(Android自适应性能框架)带来的软件层面的性能提升。
实际上就软件相关的主题演讲,Arm还特别花篇幅去谈了安全,包括MTE、PAC/BTI威廉希尔官方网站
及对应生态——谈到与谷歌、Unity在安全特性上的合作,甚至在MTE(Memory Tagging Extension)威廉希尔官方网站
上,还特别找来快手、联发科、vivo这些合作伙伴站台。不过这次我们不会把笔墨放在安全问题上,即便这个问题就当代移动威廉希尔官方网站
而言正变得格外重要。
有关64位生态迁移的话题,桎梏并不在芯片和操作系统厂商身上,而在最上层的App开发者身上。自11年以前,CPU层面提供64位支持(Cortex-A57/A53),以及2年后Android操作系统跟进,一直到今年Pixel 7作为纯64位Android配置的手机问世,这仍然是个相当漫长的过程。而TCS23是彻底构建起纯64bit支持集群的一代。
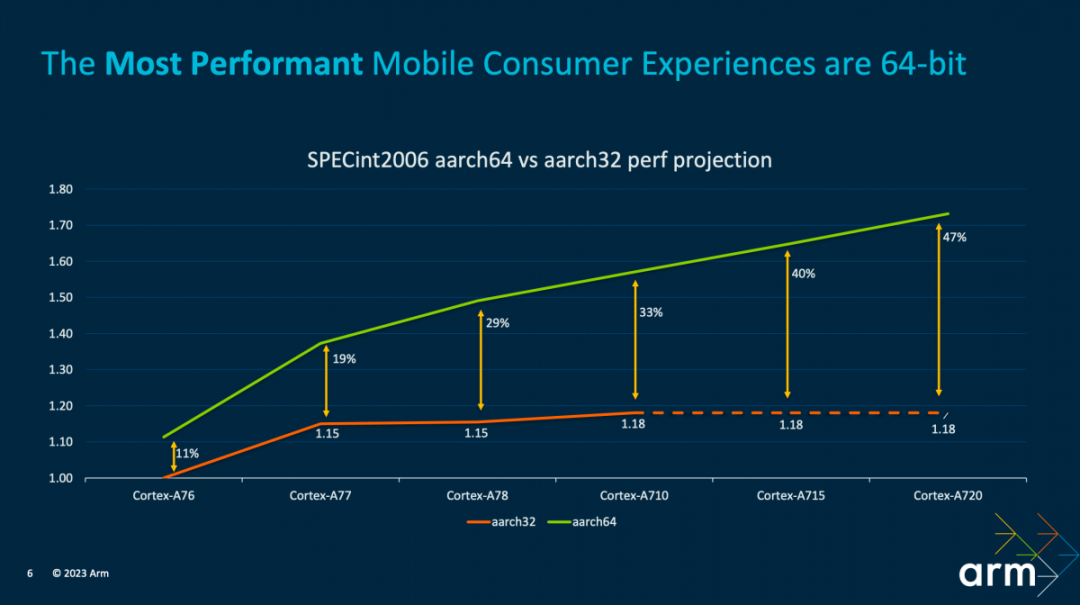 从安全和性能两个角度来看,64位都显然是个更好的选择。安全方面,64bit提供更大的内存地址空间,在地址空间布局随机化(ASLR)等特性实现上会更为有效;也为Arm多番提及的MTE和PAC(Pointer Authentication)提供了实现基础。
而在性能方面,Arm给出了上面这张图。Cortex-A7x系列核心,从A76到A720的SPECint2006性能变化情况:32位与64位应用的性能差别是在逐步扩大的。至Cortex-A710这一代性能差距扩大至33%,且后续的IP上32位应用不再能获得性能红利。Geraint说:“这种差距的拉大,一部分是由于 IP 实施的决策,我们会把更加宝贵的时间以及硅面积集中在 64 位路径的优化之上。”
“软件方面也是如此,我们的编译器和库优化团队,都把工作重点聚焦在 64 位上。如果现在你还是在做 32 位的开发,那么我们做的这些工作可能就不能为你提供赋能。”即便目前历史遗留问题多少都还在,TCS23应当也意味着移动平台的64位攻坚战进入了尾声。
从安全和性能两个角度来看,64位都显然是个更好的选择。安全方面,64bit提供更大的内存地址空间,在地址空间布局随机化(ASLR)等特性实现上会更为有效;也为Arm多番提及的MTE和PAC(Pointer Authentication)提供了实现基础。
而在性能方面,Arm给出了上面这张图。Cortex-A7x系列核心,从A76到A720的SPECint2006性能变化情况:32位与64位应用的性能差别是在逐步扩大的。至Cortex-A710这一代性能差距扩大至33%,且后续的IP上32位应用不再能获得性能红利。Geraint说:“这种差距的拉大,一部分是由于 IP 实施的决策,我们会把更加宝贵的时间以及硅面积集中在 64 位路径的优化之上。”
“软件方面也是如此,我们的编译器和库优化团队,都把工作重点聚焦在 64 位上。如果现在你还是在做 32 位的开发,那么我们做的这些工作可能就不能为你提供赋能。”即便目前历史遗留问题多少都还在,TCS23应当也意味着移动平台的64位攻坚战进入了尾声。
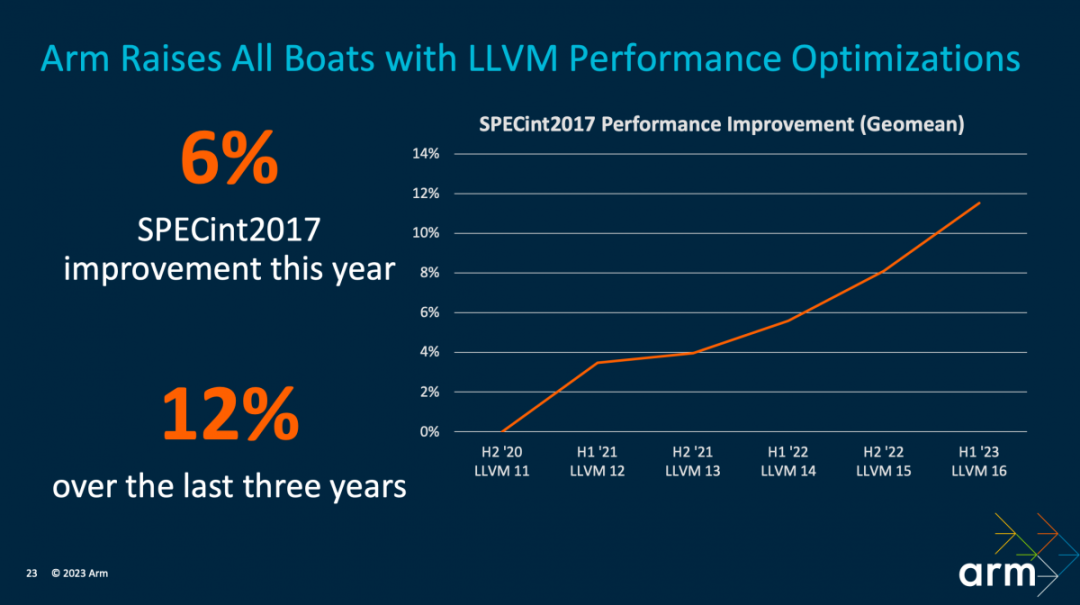 编译器方面,Geraint说过去3年时间里,LLVM实现了12%的性能提升。所以“这种工作是非常有价值的,因为它不仅提高了最新一代的 CPU 性能,不管这个设备是基于 Armv8 还是 Armv9,当它搭载最新的工具链重新编译的时候,会普遍获得性能的提升”。
Geraint强调,Arm在LLVM上的投入有很大一部分是集中在了SVE2指令的性能提升的——也就是Armv9架构引入的矢量扩展。
编译器方面,Geraint说过去3年时间里,LLVM实现了12%的性能提升。所以“这种工作是非常有价值的,因为它不仅提高了最新一代的 CPU 性能,不管这个设备是基于 Armv8 还是 Armv9,当它搭载最新的工具链重新编译的时候,会普遍获得性能的提升”。
Geraint强调,Arm在LLVM上的投入有很大一部分是集中在了SVE2指令的性能提升的——也就是Armv9架构引入的矢量扩展。
 Arm对于SVE2真正产生价值的目标是,“第一我们要确保 SVE2 的代码生成尽可能做好,这就意味着我们要保证 LLVM 能做矢量化的工作,同时又能确保 LLVM 能够矢量化目前它不能做到的事情。”也就是在LLVM可实现矢量化工作的基础上,做得比NEON更好,比如scatter/gather指令和predicted指令。
另一方面LLVM 16版本引入了Function Multi-Versioning,“所以开发者能够更加容易确保其函数的利用和 SVE2版本都能够生成,并且在运行的时候自动选择正确的版本”。“作为一个开发者你不必同时做两个二进位文件,或者每一次都进行 CPU 的检测。”这是为兼容性所做的考量。
不过我们知道,现阶段SVE2面临的一个实际问题还是在于利用率,和移动平台是否真正需要SVE2。所以Geraint特别提到SVE2对于图像处理非常适用。
Arm对于SVE2真正产生价值的目标是,“第一我们要确保 SVE2 的代码生成尽可能做好,这就意味着我们要保证 LLVM 能做矢量化的工作,同时又能确保 LLVM 能够矢量化目前它不能做到的事情。”也就是在LLVM可实现矢量化工作的基础上,做得比NEON更好,比如scatter/gather指令和predicted指令。
另一方面LLVM 16版本引入了Function Multi-Versioning,“所以开发者能够更加容易确保其函数的利用和 SVE2版本都能够生成,并且在运行的时候自动选择正确的版本”。“作为一个开发者你不必同时做两个二进位文件,或者每一次都进行 CPU 的检测。”这是为兼容性所做的考量。
不过我们知道,现阶段SVE2面临的一个实际问题还是在于利用率,和移动平台是否真正需要SVE2。所以Geraint特别提到SVE2对于图像处理非常适用。
 他举了iToF(indirect Time-of-Flight)的例子,即用基于相位差的ToF方法来构建深度图。基于的Halide图像处理算法,都用Cortex-A720分别在FP32和FP16精度下跑,则SVE2相比NEON,分别有10%和23%的性能领先。这和SVE2的scatter/gather指令有很大的关系,也就是“从内存不连续部分检索数据”的效率。
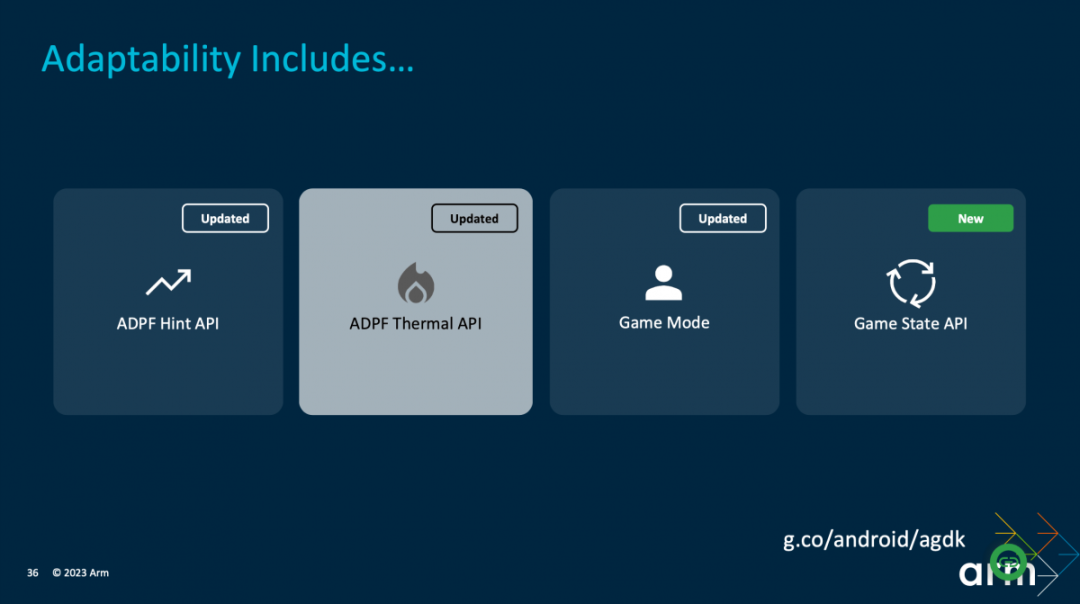
软件相关的提升,还有个有趣的部分是Android Adaptability Framework动态性能自适应框架(ADPF)。ADPF为开发者提供了一些API,包括ADPF Hint API,Thermal API,Game State API等。比如其中的Hint API,可让操作系统以更快的速度来进行CPU频率、资源的调节,达成性能需求或者节能;而Thermal API显然是温控相关的。
他举了iToF(indirect Time-of-Flight)的例子,即用基于相位差的ToF方法来构建深度图。基于的Halide图像处理算法,都用Cortex-A720分别在FP32和FP16精度下跑,则SVE2相比NEON,分别有10%和23%的性能领先。这和SVE2的scatter/gather指令有很大的关系,也就是“从内存不连续部分检索数据”的效率。
软件相关的提升,还有个有趣的部分是Android Adaptability Framework动态性能自适应框架(ADPF)。ADPF为开发者提供了一些API,包括ADPF Hint API,Thermal API,Game State API等。比如其中的Hint API,可让操作系统以更快的速度来进行CPU频率、资源的调节,达成性能需求或者节能;而Thermal API显然是温控相关的。
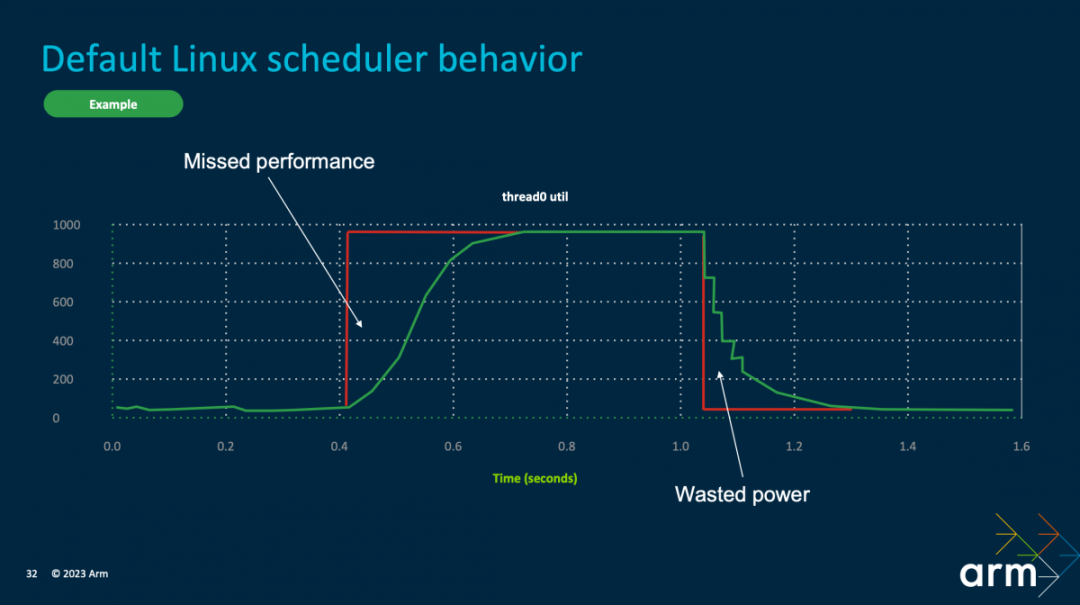 比如具体到PerformanceHint API,这个API存在的价值在于,它能为操作系统提供应用或游戏目标负载的更多信息,那么CPU可以更精准地调控资源——它比Linux内核的scheduler行为更高效。比如governor需要200ms从空闲状态拉升到最高频率,而在该工作完成后,频率还有个缓慢回落的过程。这些行为不够高效。
从应用或游戏直接把负载预期持续时间、目标发给操作系统,调度策略就会高效许多,可以减少掉帧、提升能效。Geraint说,PerformanceHint API的应用可确保正确的工作放在正确的核心上,“而不是用以前的工具如setAffinity进行猜测”。
Pixel手机将ADPF应用到了SurfaceFlinger(Android负责绘制应用UI的服务),减少了50%的掉帧、节电6%。PerformanceHint API在 Android 14成为必选项;Unity游戏引擎中,它也作为Adaptability Plugin插件存在。
比如具体到PerformanceHint API,这个API存在的价值在于,它能为操作系统提供应用或游戏目标负载的更多信息,那么CPU可以更精准地调控资源——它比Linux内核的scheduler行为更高效。比如governor需要200ms从空闲状态拉升到最高频率,而在该工作完成后,频率还有个缓慢回落的过程。这些行为不够高效。
从应用或游戏直接把负载预期持续时间、目标发给操作系统,调度策略就会高效许多,可以减少掉帧、提升能效。Geraint说,PerformanceHint API的应用可确保正确的工作放在正确的核心上,“而不是用以前的工具如setAffinity进行猜测”。
Pixel手机将ADPF应用到了SurfaceFlinger(Android负责绘制应用UI的服务),减少了50%的掉帧、节电6%。PerformanceHint API在 Android 14成为必选项;Unity游戏引擎中,它也作为Adaptability Plugin插件存在。
 还有个ADPF Thermal API,Geraint也做了分享,包括在游戏《Candy Clash》里的测试结果。其本质都在为达成更好的游戏体验,基于设备的热状态(thermal state),动态适配游戏画面渲染质量(包括帧率、分辨率、LOD、贴图),则即便是老手机也不会发生过热,而且可稳帧、降低功耗,测试结果是平均帧提高25%,CPU功耗降低最多18%。
ADPF以及Unity的自适应性能特性显然是需要和Arm IP配合的。当然了另一方面这也需要开发者去使用对应的API。这类API理所应当的,不仅成为软件层面性能提升的组成部分,也是Arm加强生态粘性的关键。
还有个ADPF Thermal API,Geraint也做了分享,包括在游戏《Candy Clash》里的测试结果。其本质都在为达成更好的游戏体验,基于设备的热状态(thermal state),动态适配游戏画面渲染质量(包括帧率、分辨率、LOD、贴图),则即便是老手机也不会发生过热,而且可稳帧、降低功耗,测试结果是平均帧提高25%,CPU功耗降低最多18%。
ADPF以及Unity的自适应性能特性显然是需要和Arm IP配合的。当然了另一方面这也需要开发者去使用对应的API。这类API理所应当的,不仅成为软件层面性能提升的组成部分,也是Arm加强生态粘性的关键。
 就软件和工具,Kinjal聊到了当前市场需求热点之一的AI,机器学习。Arm在这方面的中间件和库主要是Arm NN与Arm Compute Library。
Kinjal说:“开发者每个季度都可以从Arm发布的最新软件库优化上实现更高的机器学习应用开发。”今年1月份,Android NN和ACL已经可以在谷歌应用商店下载;到2024年,两者都可以直接在GMS(Google Mobile Services)上直接访问——在更广的范围内,成为Android的NN标准。
就软件和工具,Kinjal聊到了当前市场需求热点之一的AI,机器学习。Arm在这方面的中间件和库主要是Arm NN与Arm Compute Library。
Kinjal说:“开发者每个季度都可以从Arm发布的最新软件库优化上实现更高的机器学习应用开发。”今年1月份,Android NN和ACL已经可以在谷歌应用商店下载;到2024年,两者都可以直接在GMS(Google Mobile Services)上直接访问——在更广的范围内,成为Android的NN标准。
 开发工具相关的,有个促成软件优化的改进,Profile Guided Optimization的性能提升。开发者借助PGO能够“收集应用执行需要的各类数据、信息,基于它进行优化,信息的收集能帮助大家了解到执行这个应用的瓶颈,从而有指导的进行调整,获得最大收益”。
Armv9架构通过名为ETE(Embedded Trace Extention)和TRBE(TRace Buffer Extention)的扩展,来捕捉这些数据,做“基于硬件的追踪”。最终在程序的binary size、追踪捕获数据对性能方面都达成了影响最低。
明年手机性能提升的一些数字参考
最后来谈谈可能更多人关心的性能提升数字,其中的绝大部分应该都是上述参考设计的表现提升,也要考虑进软件层面的提升。既然是系统层面的,那就是高层级的系统测试了,对于反映未来手机性能变化应该相比IP层面的性能和能效提升数字更有价值。
开发工具相关的,有个促成软件优化的改进,Profile Guided Optimization的性能提升。开发者借助PGO能够“收集应用执行需要的各类数据、信息,基于它进行优化,信息的收集能帮助大家了解到执行这个应用的瓶颈,从而有指导的进行调整,获得最大收益”。
Armv9架构通过名为ETE(Embedded Trace Extention)和TRBE(TRace Buffer Extention)的扩展,来捕捉这些数据,做“基于硬件的追踪”。最终在程序的binary size、追踪捕获数据对性能方面都达成了影响最低。
明年手机性能提升的一些数字参考
最后来谈谈可能更多人关心的性能提升数字,其中的绝大部分应该都是上述参考设计的表现提升,也要考虑进软件层面的提升。既然是系统层面的,那就是高层级的系统测试了,对于反映未来手机性能变化应该相比IP层面的性能和能效提升数字更有价值。
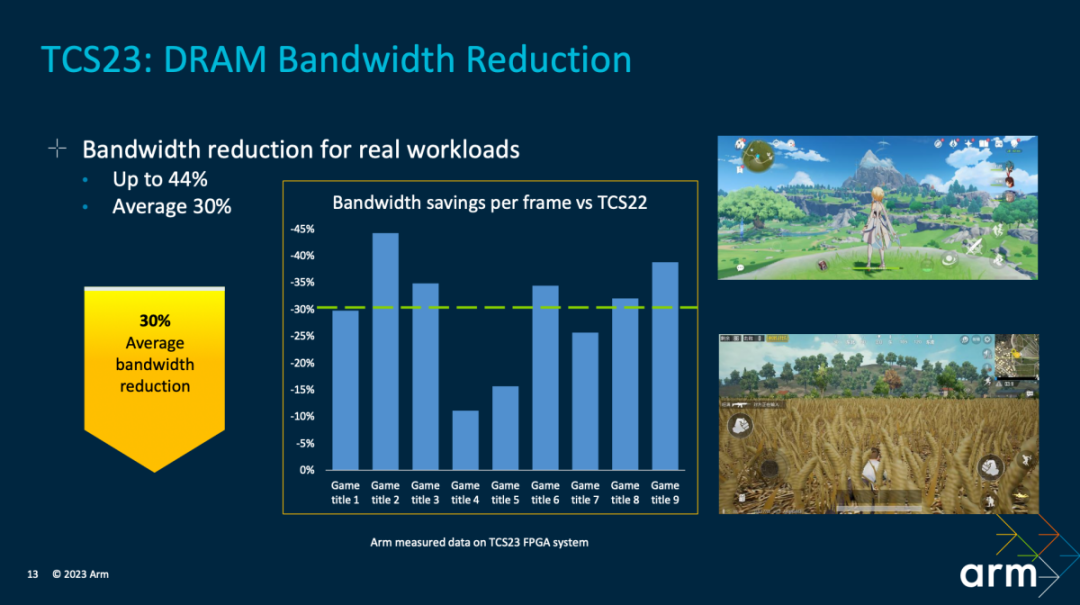 首先上述对比是不同游戏,每一帧的DRAM带宽需求缩减。Arm测试了不少游戏。相比TCS22,最高可达成44%的带宽缩减,平均缩减幅度30%。换句话说就是片外主内存的依赖更低了,这对提升游戏能效表现是很有价值的。
这也对应地带来了20%的功耗节省(测试这些游戏在60fps下持续性能发挥)。“决定,这些节约下来的能耗,它们或被用于 SoC 功率的计算中,来实现性能进一步提升,或者又可以把它们存起来,从而实现更长电池续航的时间,让用户能够玩更长时间的游戏。”Kinjal说。
前文也部分提到了图形计算目标之一的带宽缩减,主要是DVS延迟顶点着色威廉希尔官方网站
的加入,以及system cache分配策略优化。
首先上述对比是不同游戏,每一帧的DRAM带宽需求缩减。Arm测试了不少游戏。相比TCS22,最高可达成44%的带宽缩减,平均缩减幅度30%。换句话说就是片外主内存的依赖更低了,这对提升游戏能效表现是很有价值的。
这也对应地带来了20%的功耗节省(测试这些游戏在60fps下持续性能发挥)。“决定,这些节约下来的能耗,它们或被用于 SoC 功率的计算中,来实现性能进一步提升,或者又可以把它们存起来,从而实现更长电池续航的时间,让用户能够玩更长时间的游戏。”Kinjal说。
前文也部分提到了图形计算目标之一的带宽缩减,主要是DVS延迟顶点着色威廉希尔官方网站
的加入,以及system cache分配策略优化。
 在GFXBench系统性能测试里,两个比较知名的测试项Manhattan 3.0和Aztec Ruins High中,TCS23分别有21%和20%的性能提升。这是更高的频率、更多的shader核心,外加系统级优化带来的。未来的游戏手机又可以期待以下了。
CPU方面,Arm主要给的是Geekbench 6多线程测试,和Speedometer 2.1网页浏览测试。需要注意的是,GB6的这个测试,TCS23这边的CPU搭配方法是1+5+2,多线程性能提升27%。
Kinjal解释说之所以这样搭配,是因为“越来越多的人们开始比较多线程指标,并且它也成为我们合作伙伴进行优化的一个目标。我们看到许多 AAA 级的游戏会产生高性能线程,而且数量正在不断增加,因此就对CPU集群持续的多线程性能提出了要求。我们通过这个基准测试来展示全新 IP 效率的提升以及制程威廉希尔官方网站
的改进,可以满足持续多线程性能方面的要求。”
Speedometer这边是1+3+4,其中还加入了软件优化——即Arm与谷歌就Chromium的合作,开启PAC/BTI安全特性。软件优化达成的更高性能提升。
在GFXBench系统性能测试里,两个比较知名的测试项Manhattan 3.0和Aztec Ruins High中,TCS23分别有21%和20%的性能提升。这是更高的频率、更多的shader核心,外加系统级优化带来的。未来的游戏手机又可以期待以下了。
CPU方面,Arm主要给的是Geekbench 6多线程测试,和Speedometer 2.1网页浏览测试。需要注意的是,GB6的这个测试,TCS23这边的CPU搭配方法是1+5+2,多线程性能提升27%。
Kinjal解释说之所以这样搭配,是因为“越来越多的人们开始比较多线程指标,并且它也成为我们合作伙伴进行优化的一个目标。我们看到许多 AAA 级的游戏会产生高性能线程,而且数量正在不断增加,因此就对CPU集群持续的多线程性能提出了要求。我们通过这个基准测试来展示全新 IP 效率的提升以及制程威廉希尔官方网站
的改进,可以满足持续多线程性能方面的要求。”
Speedometer这边是1+3+4,其中还加入了软件优化——即Arm与谷歌就Chromium的合作,开启PAC/BTI安全特性。软件优化达成的更高性能提升。
 还有个CPU的对比,是比较CPU的机器学习性能,具体到对象识别、分类、人体姿势追踪等;比的主要就是Int8推理。不同核心的性能提升幅度,相比TCS22如上图所示。
图中右边是GPU的AI超分性能提升达成了4倍。这里面除了CPU、GPU算力加强,也在于Arm NN和Arm Compute Library的进化。
还有个CPU的对比,是比较CPU的机器学习性能,具体到对象识别、分类、人体姿势追踪等;比的主要就是Int8推理。不同核心的性能提升幅度,相比TCS22如上图所示。
图中右边是GPU的AI超分性能提升达成了4倍。这里面除了CPU、GPU算力加强,也在于Arm NN和Arm Compute Library的进化。
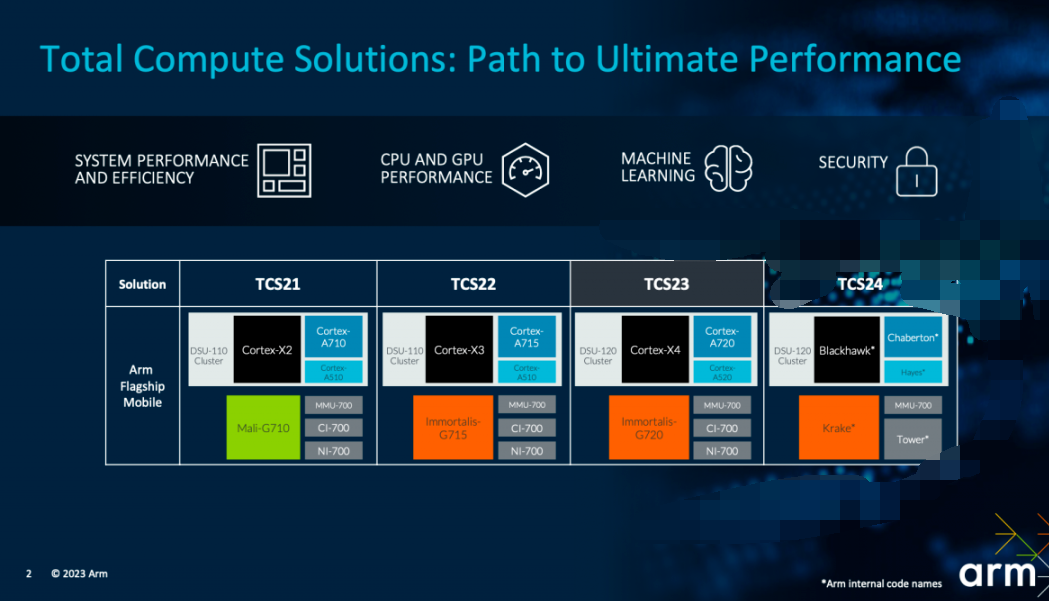 以上就是从解决方案层面Arm阐释的TCS23了。不过Kinjal提到,TCS23是个可伸缩的平台,面向广阔的客户端设备,不只是高端手机设备。比如说Immortalis-G720弹性缩放有下设Mali-G720/G620可选配;而在CPU集群方面,Cortex-A720核心有着对应的可伸缩选项。
“我们最新发布的产品也将推动下一代的旗舰智能手机。”Arm产品营销副总裁Ian Smythe说。实际上他在开篇还展望了未来的TCS设计,如上图,包括Blackhawk CPU以及Krake GPU等关键IP,“我们还着眼于未来。我们对 CPU 和 GPU 产品路线图的承诺更胜以往,在接下来的几年里,我们将在包括 Krake GPU 和 Blackhawk CPU 等关键 IP 上加大投入,以满足合作伙伴对于计算和图形性能的要求。”
以上就是从解决方案层面Arm阐释的TCS23了。不过Kinjal提到,TCS23是个可伸缩的平台,面向广阔的客户端设备,不只是高端手机设备。比如说Immortalis-G720弹性缩放有下设Mali-G720/G620可选配;而在CPU集群方面,Cortex-A720核心有着对应的可伸缩选项。
“我们最新发布的产品也将推动下一代的旗舰智能手机。”Arm产品营销副总裁Ian Smythe说。实际上他在开篇还展望了未来的TCS设计,如上图,包括Blackhawk CPU以及Krake GPU等关键IP,“我们还着眼于未来。我们对 CPU 和 GPU 产品路线图的承诺更胜以往,在接下来的几年里,我们将在包括 Krake GPU 和 Blackhawk CPU 等关键 IP 上加大投入,以满足合作伙伴对于计算和图形性能的要求。”
具体如上图所示,大部分人关心的是处在中间的环节,即Armv9架构及其上的存储与互联一致性、各种核心IP。实际TCS还包括图中的软件、开发工具,以及以先进工艺做Arm IP实施的物理IP。
Arm终端事业部产品管理高级总监Kinjal Dave说:“谈到解决方案,为什么 Arm 要采取这样一种全局的方法论来开发解决方案,不断推高性能、提高效率,本身变得越来越难且成本高昂。其实这对 Arm 来说,意味着我们每年推出的 TCS 在性能跟效率方面,都必须实现进步。所以,我们要采取一种平衡。”
Kinjal说Arm这些年来始终努力在benchmark和真实使用场景之间做平衡:“一方面,单独的 IP 要不断把它做强,另外一方面把这些单独的 IP 集合在一起时,总体的系统级别也要实现性能效率的双提升。” “为我们的合作伙伴提供融合了这些单独IP的系统级解决方案所带来的完整性能提升。”
随着摩尔定律的放缓,以及设计层面各种经典威廉希尔官方网站
的全面上线,这两年单独IP微架构层面带来的性能和效率提升也远不及此前那么大了,从更系统的角度来做考量也是半导体链条上各个玩家的共识。
所以这篇文章我们就从TCS23整体的角度来看看这一代平台的改进,其中会涉及到上述IP,但不会过多深入。另外很难得的是,Arm特别用一个主题演讲的章节去谈了软件改进,包括编译器、SVE2指令、Android动态性能框架等,本文也会略有涉及。
TCS23参考设计
本文就不过多提单独IP的性能与效率变化了,包括Cortex-X4相比X3性能提升15%,Cortex-A720相比A715能效提升20%,Cortex-A520相比A510能效提升22%,DSU提升动态功耗表现、针对闲置与低负载场景的新功耗模式,Immortalis-G720性能提升15%、带宽用量降低40%等等。
不过Arm针对TCS23就FPGA级别做了参考设计,“代表真实的芯片设备”。Arm做参考设计的原因,一是IP越来越复杂,其次是系统中的许多特性是需要跨系统的,比如说这次Arm一直在谈的MTE(Memory Tagging Extention)安全特性;
另外还包括“越来越多样化终端使用场景的出现”,以及“对这些芯片设计工作来说,在设计选择以及平衡方面的取舍难度也提高了。”
上面这张图就是Arm TCS23参考设计。大框架上CPU、GPU都用了这一代最新IP。不同核心组成的CPU集群,“与DSU-120共同连接到共享系统的背板(backplane)”;借助system cache(SLC)所在的CoreLink CI-700,一边连接到Immortalis-G720 GPU。
这里CoreLink CI-700作为存储系统的核心,为所有的IO流量提供一个汇聚点(也用于实现MTE)。同时,NI-700为所有其他流量提供一条通往DRAM独立的路径;“能进行QoS执行,允许不同的流量类型一起流动,而不会出现交叉流,或者互相阻塞的情况”。
系统级解决方案的奥义
参考设计的CPU部分,是1x Cortex-X4, 3x Cortex-A720, 4x Cortex-A520的配置;DSU-120配了8MB L3 cache。Arm认为1+3+4是性能和效率可达成均衡的配置方案。不过在多线程性能对比时,Arm也有基于1+5+2的搭配呈现。
Kinjal没有细谈这部分的配置。不过这里主要看的还是系统级别的工作。他强调CPU集群的关键首先是如何利用CPU和行为架构实现跨越三个层级的性能动态范围;其次影响CPU性能很重要的因素是DRAM延迟。
对于后者,一方面,“我们进行了DRAM结构性的静态延迟优化”,“首先是DynamIQ共享单元内和通往内存的路径中的时钟配置的选择,也就是在这个领域资源的竞争”——在这个过程里,需要进行DynamIQ时钟配置优化,“同时要最小化数量的选择”;
另一方面,还需要考虑“加载系统内存层面下的动态优先级别”,包括“GPU、摄像头以及其他多媒体管道等”,“它们可能要同时访问内存”。这些都要求在进行CPU集群配置时,做相应的考量。
在CPU集群的优化上,首先是基于“CPU核心微架构”提供“最为广泛的动态范围”,“跨越三层(Cortex X4,Cortex A720和Cortex A520)”。其中包括DVFS动态调整,线程核心迁移等;适配各种负载场景、应对不同的性能目标。此间涵盖以最优化的效率,针对不同的运行场景,包括了分配多少CPU资源,如频率、响应、哪些核心参与等等。
“计算IP级的系统级解决方案,包括不同电源选择的模式,不同时钟选项的配置”,“在TCS23中我们添加了一个逻辑增强型降功耗的模式”。
“在解决方案层级,我们的电源控制固件的堆栈以及调度器一起工作,能实现基于不同的使用场景的选择,这点很关键。”Kinjal说,“TCS23解决方案中还有一个系统控制处理器,它能够协调传感器控制框架,在各个CPU内核以及DSU-120工作点之间移动的时候充分考虑到散热以及输电的一些限制因素。”“跨整个CPU集群,我们还实施了积极的时钟门控以及时空调节的机制,来节约动态功耗。”
另一个关键是细粒度的电源模式——这也是当代低功耗设计的精髓所在。上面这张图每种颜色代表“单独的电源连接供电”。Arm在此的工作之一就是管理供电的复杂性,“我们有专门用于电压供应的管理、电源传输、网络控制电源控制部件。
“这里电源控制部件是与调度器,以及操作系统的电源管理软件共同协调工作的。”
图形计算相关的部分,Arm强调了3个解决方案层面的关注点,分别是带宽、功耗,与安全性。“我们将Arm Immotalis-G720集成到TCS23解决方案中,配置了MMU-700,与GPU实现共同的优化”。其中的某些部分,也会在我们后续的IP文章GPU相关部分做更详尽的介绍——比如节约带宽的Deferred Vertex Shading延迟顶点着色。
从大方向来看,节约带宽方面的工作包括AFRC与AFBC无损压缩——管线不同阶段的数据压缩始终是GPU不变的话题之一,它对于DRAM访问需求的降低,提供更大的发热空间都有价值;IO一致性,将缓存维护开销降到最低,并由CoreLink CI-700与Immortalis-G720合作,来达成性能的提升;以及利用大型系统高速缓存(system cache),而且还有个“内存分配提示,优先考虑哪部分要存在高速缓存中”。
能效优化部分,一方面是利用针对每个shader核心的power gating,另外就是核心群组的节电模式等。“TCS23解决方案提供了一套完整的参考:Immortalis-G720驱动如何与我们的参考固件堆栈协同,实现电源控制、动态电压与频率的调节。”另外,“我们在GPU中也实施了积极的clock gating方案,用以管理动态功耗。”
安全性方面,MMU-700的集成对于支持DRAM保护内容的安全处理,以及支持Android虚拟化框架是至关重要的。
结合包括cache、连接至内存的延迟、floorplan以及内存支持方面的变化,参考设计达成综合的带宽吞吐,相比于前代提升了33%。
所以在总结性发言里,Kinjal再度强调的一点就是基于TCS全面计算解决方案,“Arm已经超越单个IP产品,为客户实现端到端系统级的优化,从而释放整个SoC系统全面性能”。这是TCS存在的核心价值。
软件带来的性能提升
除了这些比较多人关注的IP之外,如文首所述,TCS作为解决方案还涵盖了工具、软件、物理/POP IP等。这里我们再谈一谈工具和软件,TCS23不仅升级了IP,也升级了软件与工具。Arm终端事业部生态系统及工程高级总监Geraint North说Arm的工程师中,超过45%都是软件工程师,底层部分涵盖了驱动、Linux内核,往上则有软件框架、性能分析工具、开发者教学、最佳实践等。
软件自然是位于硬件之上的层级,这部分Geraint主要谈了64bit完全迁移、compiler编译器性能提升,以及ADPF(Android自适应性能框架)带来的软件层面的性能提升。
实际上就软件相关的主题演讲,Arm还特别花篇幅去谈了安全,包括MTE、PAC/BTI威廉希尔官方网站
及对应生态——谈到与谷歌、Unity在安全特性上的合作,甚至在MTE(Memory Tagging Extension)威廉希尔官方网站
上,还特别找来快手、联发科、vivo这些合作伙伴站台。不过这次我们不会把笔墨放在安全问题上,即便这个问题就当代移动威廉希尔官方网站
而言正变得格外重要。
有关64位生态迁移的话题,桎梏并不在芯片和操作系统厂商身上,而在最上层的App开发者身上。自11年以前,CPU层面提供64位支持(Cortex-A57/A53),以及2年后Android操作系统跟进,一直到今年Pixel 7作为纯64位Android配置的手机问世,这仍然是个相当漫长的过程。而TCS23是彻底构建起纯64bit支持集群的一代。
从安全和性能两个角度来看,64位都显然是个更好的选择。安全方面,64bit提供更大的内存地址空间,在地址空间布局随机化(ASLR)等特性实现上会更为有效;也为Arm多番提及的MTE和PAC(Pointer Authentication)提供了实现基础。
而在性能方面,Arm给出了上面这张图。Cortex-A7x系列核心,从A76到A720的SPECint2006性能变化情况:32位与64位应用的性能差别是在逐步扩大的。至Cortex-A710这一代性能差距扩大至33%,且后续的IP上32位应用不再能获得性能红利。Geraint说:“这种差距的拉大,一部分是由于 IP 实施的决策,我们会把更加宝贵的时间以及硅面积集中在 64 位路径的优化之上。”
“软件方面也是如此,我们的编译器和库优化团队,都把工作重点聚焦在 64 位上。如果现在你还是在做 32 位的开发,那么我们做的这些工作可能就不能为你提供赋能。”即便目前历史遗留问题多少都还在,TCS23应当也意味着移动平台的64位攻坚战进入了尾声。
编译器方面,Geraint说过去3年时间里,LLVM实现了12%的性能提升。所以“这种工作是非常有价值的,因为它不仅提高了最新一代的 CPU 性能,不管这个设备是基于 Armv8 还是 Armv9,当它搭载最新的工具链重新编译的时候,会普遍获得性能的提升”。
Geraint强调,Arm在LLVM上的投入有很大一部分是集中在了SVE2指令的性能提升的——也就是Armv9架构引入的矢量扩展。
Arm对于SVE2真正产生价值的目标是,“第一我们要确保 SVE2 的代码生成尽可能做好,这就意味着我们要保证 LLVM 能做矢量化的工作,同时又能确保 LLVM 能够矢量化目前它不能做到的事情。”也就是在LLVM可实现矢量化工作的基础上,做得比NEON更好,比如scatter/gather指令和predicted指令。
另一方面LLVM 16版本引入了Function Multi-Versioning,“所以开发者能够更加容易确保其函数的利用和 SVE2版本都能够生成,并且在运行的时候自动选择正确的版本”。“作为一个开发者你不必同时做两个二进位文件,或者每一次都进行 CPU 的检测。”这是为兼容性所做的考量。
不过我们知道,现阶段SVE2面临的一个实际问题还是在于利用率,和移动平台是否真正需要SVE2。所以Geraint特别提到SVE2对于图像处理非常适用。
他举了iToF(indirect Time-of-Flight)的例子,即用基于相位差的ToF方法来构建深度图。基于的Halide图像处理算法,都用Cortex-A720分别在FP32和FP16精度下跑,则SVE2相比NEON,分别有10%和23%的性能领先。这和SVE2的scatter/gather指令有很大的关系,也就是“从内存不连续部分检索数据”的效率。
软件相关的提升,还有个有趣的部分是Android Adaptability Framework动态性能自适应框架(ADPF)。ADPF为开发者提供了一些API,包括ADPF Hint API,Thermal API,Game State API等。比如其中的Hint API,可让操作系统以更快的速度来进行CPU频率、资源的调节,达成性能需求或者节能;而Thermal API显然是温控相关的。
比如具体到PerformanceHint API,这个API存在的价值在于,它能为操作系统提供应用或游戏目标负载的更多信息,那么CPU可以更精准地调控资源——它比Linux内核的scheduler行为更高效。比如governor需要200ms从空闲状态拉升到最高频率,而在该工作完成后,频率还有个缓慢回落的过程。这些行为不够高效。
从应用或游戏直接把负载预期持续时间、目标发给操作系统,调度策略就会高效许多,可以减少掉帧、提升能效。Geraint说,PerformanceHint API的应用可确保正确的工作放在正确的核心上,“而不是用以前的工具如setAffinity进行猜测”。
Pixel手机将ADPF应用到了SurfaceFlinger(Android负责绘制应用UI的服务),减少了50%的掉帧、节电6%。PerformanceHint API在 Android 14成为必选项;Unity游戏引擎中,它也作为Adaptability Plugin插件存在。
还有个ADPF Thermal API,Geraint也做了分享,包括在游戏《Candy Clash》里的测试结果。其本质都在为达成更好的游戏体验,基于设备的热状态(thermal state),动态适配游戏画面渲染质量(包括帧率、分辨率、LOD、贴图),则即便是老手机也不会发生过热,而且可稳帧、降低功耗,测试结果是平均帧提高25%,CPU功耗降低最多18%。
ADPF以及Unity的自适应性能特性显然是需要和Arm IP配合的。当然了另一方面这也需要开发者去使用对应的API。这类API理所应当的,不仅成为软件层面性能提升的组成部分,也是Arm加强生态粘性的关键。
就软件和工具,Kinjal聊到了当前市场需求热点之一的AI,机器学习。Arm在这方面的中间件和库主要是Arm NN与Arm Compute Library。
Kinjal说:“开发者每个季度都可以从Arm发布的最新软件库优化上实现更高的机器学习应用开发。”今年1月份,Android NN和ACL已经可以在谷歌应用商店下载;到2024年,两者都可以直接在GMS(Google Mobile Services)上直接访问——在更广的范围内,成为Android的NN标准。
开发工具相关的,有个促成软件优化的改进,Profile Guided Optimization的性能提升。开发者借助PGO能够“收集应用执行需要的各类数据、信息,基于它进行优化,信息的收集能帮助大家了解到执行这个应用的瓶颈,从而有指导的进行调整,获得最大收益”。
Armv9架构通过名为ETE(Embedded Trace Extention)和TRBE(TRace Buffer Extention)的扩展,来捕捉这些数据,做“基于硬件的追踪”。最终在程序的binary size、追踪捕获数据对性能方面都达成了影响最低。
明年手机性能提升的一些数字参考
最后来谈谈可能更多人关心的性能提升数字,其中的绝大部分应该都是上述参考设计的表现提升,也要考虑进软件层面的提升。既然是系统层面的,那就是高层级的系统测试了,对于反映未来手机性能变化应该相比IP层面的性能和能效提升数字更有价值。
首先上述对比是不同游戏,每一帧的DRAM带宽需求缩减。Arm测试了不少游戏。相比TCS22,最高可达成44%的带宽缩减,平均缩减幅度30%。换句话说就是片外主内存的依赖更低了,这对提升游戏能效表现是很有价值的。
这也对应地带来了20%的功耗节省(测试这些游戏在60fps下持续性能发挥)。“决定,这些节约下来的能耗,它们或被用于 SoC 功率的计算中,来实现性能进一步提升,或者又可以把它们存起来,从而实现更长电池续航的时间,让用户能够玩更长时间的游戏。”Kinjal说。
前文也部分提到了图形计算目标之一的带宽缩减,主要是DVS延迟顶点着色威廉希尔官方网站
的加入,以及system cache分配策略优化。
在GFXBench系统性能测试里,两个比较知名的测试项Manhattan 3.0和Aztec Ruins High中,TCS23分别有21%和20%的性能提升。这是更高的频率、更多的shader核心,外加系统级优化带来的。未来的游戏手机又可以期待以下了。
CPU方面,Arm主要给的是Geekbench 6多线程测试,和Speedometer 2.1网页浏览测试。需要注意的是,GB6的这个测试,TCS23这边的CPU搭配方法是1+5+2,多线程性能提升27%。
Kinjal解释说之所以这样搭配,是因为“越来越多的人们开始比较多线程指标,并且它也成为我们合作伙伴进行优化的一个目标。我们看到许多 AAA 级的游戏会产生高性能线程,而且数量正在不断增加,因此就对CPU集群持续的多线程性能提出了要求。我们通过这个基准测试来展示全新 IP 效率的提升以及制程威廉希尔官方网站
的改进,可以满足持续多线程性能方面的要求。”
Speedometer这边是1+3+4,其中还加入了软件优化——即Arm与谷歌就Chromium的合作,开启PAC/BTI安全特性。软件优化达成的更高性能提升。
还有个CPU的对比,是比较CPU的机器学习性能,具体到对象识别、分类、人体姿势追踪等;比的主要就是Int8推理。不同核心的性能提升幅度,相比TCS22如上图所示。
图中右边是GPU的AI超分性能提升达成了4倍。这里面除了CPU、GPU算力加强,也在于Arm NN和Arm Compute Library的进化。
以上就是从解决方案层面Arm阐释的TCS23了。不过Kinjal提到,TCS23是个可伸缩的平台,面向广阔的客户端设备,不只是高端手机设备。比如说Immortalis-G720弹性缩放有下设Mali-G720/G620可选配;而在CPU集群方面,Cortex-A720核心有着对应的可伸缩选项。
“我们最新发布的产品也将推动下一代的旗舰智能手机。”Arm产品营销副总裁Ian Smythe说。实际上他在开篇还展望了未来的TCS设计,如上图,包括Blackhawk CPU以及Krake GPU等关键IP,“我们还着眼于未来。我们对 CPU 和 GPU 产品路线图的承诺更胜以往,在接下来的几年里,我们将在包括 Krake GPU 和 Blackhawk CPU 等关键 IP 上加大投入,以满足合作伙伴对于计算和图形性能的要求。”
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
ARM
+关注
关注
134文章
9097浏览量
367556 -
手机
+关注
关注
35文章
6880浏览量
157605 -
cpu
+关注
关注
68文章
10863浏览量
211763 -
gpu
+关注
关注
28文章
4740浏览量
128948
发布评论请先 登录
相关推荐
明年用5G手机? 最新数据显示:没那么简单
进程仍在最后的攻坚阶段,5G建设暂时不会占用国家过多的资源。此外,按照以往通讯升级的经验,从4G到5G还会受到地域、资费等限制。但目前,5G通讯的大部分标准还未拟定,明年全国覆盖5G网络的可能性不大,更别说使用5G手机了。综上所
发表于 10-24 15:58
搭载RISC-V芯片的手机,或将于明年正式推出
。最终,RISC-V作为硬件,打铁还要自身硬,RISC-V芯片必须先得证明自己的能力,比如芯片厂商推出性能更强的产品。在硬件基础打好了后,或许就如同苹果从x86转向ARM一样,包括Android、甚至未来
发表于 12-17 08:00
如何使用ESP8266和TAOS TCS23的颜色识别板?
我设法使用 ESP8266 和 TAOS TCS230 颜色识别模块实现了颜色识别板。我必须采取一些技巧才能让 GPIO 能够处理方波输入和频率,但最终让它工作并实现了原型板。这是项目的描述
发表于 05-24 08:46
TCS2315 GPRS手机解决方案
TCS2315 GPRS手机解决方案
TI 公司的TCS2315 GPRS手机解决方案是第三代基于GSM的超低成本手机,采用先进的65-n
发表于 12-26 14:53
•1175次阅读
全新的Arm全面计算解决方案实现基于Arm威廉希尔官方网站 的移动未来
Arm 高级副总裁兼终端事业部总经理 Chris Bergey 表示:“TCS23包含了基于全新第五代 GPU 架构、可实现终极视觉体验的全新Arm Immortalis GPU,助力 Ar

全新的Arm全面计算解决方案实现基于Arm威廉希尔官方网站 的移动未来
Arm® 今日宣布推出 2023 全面计算解决方案(TCS23),该解决方案将成为最重要的移动计算平台,为智能手机带来绝佳的解决方案。TCS23 提供一整套针对特定工作负载而设计与优化

Arm TCS23现迄今最快处理器IP组合,前瞻定义旗舰手机SoC性能,为生成式AI而来
最近Arm推出2023 全面计算解决方案(TCS23),发布最新CPU和GPU IP等产品。没有意外,高通和联发科的下一代旗舰手机SoC将采用Arm最新的CPU架构Cortex-X4,
从Arm TCS23看Arm对移动设备未来的洞察
5月29日Arm正式推出 Arm 2023 全面计算解决方案(TCS23), 包含基于全新第五代 GPU 架构、可实现终极视觉体验的全新Arm Immortalis GPU,助力
移动设备部署机器学习,Arm谈如何赋能移动AI
计算解决方案 (TCS23) 持续引领这样的应用趋势。在最近,Arm高级副总裁兼终端事业部总经理Chris Bergey接受媒体采访,分享了Arm对移动AI发展的看法以及Arm如何赋能
Arm携手MediaTek和vivo将TCS23运用于新一代旗舰智能手机
2023 年五月,Arm 宣布推出移动计算平台——2023 全面计算解决方案 (Arm TCS23)。
TCS23的软件栈和FVP加速移动生态的产品开发方案一览
今年五月,Arm 发布了 2023 全面计算解决方案 (TCS23)。TCS23 是面向移动计算的完整 IP 组合,也是我们有史以来最佳的面向智能手机的高端解决方案。
ARM发布旗舰手机芯片:性能提升、AI性能增强、节能减耗
ARM为Cortex-X系列CPU重新命名,以强调其性能的显著提升。据称,X925的单核性能较X4提升了36%(依据Geekbench测试结





 工商网监
工商网监
评论