 如何学习基于Tansformer的目标检测算法
如何学习基于Tansformer的目标检测算法
视觉感知算法的核心在于精准实时地感知周围环境,以便下游更好地进行决策规划,而目标检测任务就是视觉感知的基础。不仅在自动驾驶领域,在机器人导航、工业检测、视频监控等领域,目标检测都有着广泛应用,也是近年来理论研究的热点。作为计算机视觉中的基础算法,目标检测对后续的人脸识别、目标跟踪、实例分割等任务都起着至关重要的作用。
基于深度学习的卷积学习网络(CNN)在目标检测任务上取得了优越的性能,例如FasterRCNN、YOLO系列、CenterNet等等,也在实际应用中实现了成功部署和使用。自Transformer在2017年被提出之后,无论是自然语言处理领域,还是计算机视觉 (CV)、强化学习 (RL)、生成对抗网络 (GAN)、语音处理甚至是生物学领域,Transformer都大放异彩。而在目标检测领域中,视觉Transformer不仅可以实现2D检测、3D检测,还可以实现多模态检测,BEV视角下的检测,性能也非常出色。 因此,掌握Transformer相关知识和工程基础成为了企业招聘算法工程师的一个技能要求点,也是简历上的一个加分项。
然而,想要掌握基于Transformer的目标检测算法,有以下3个难点:
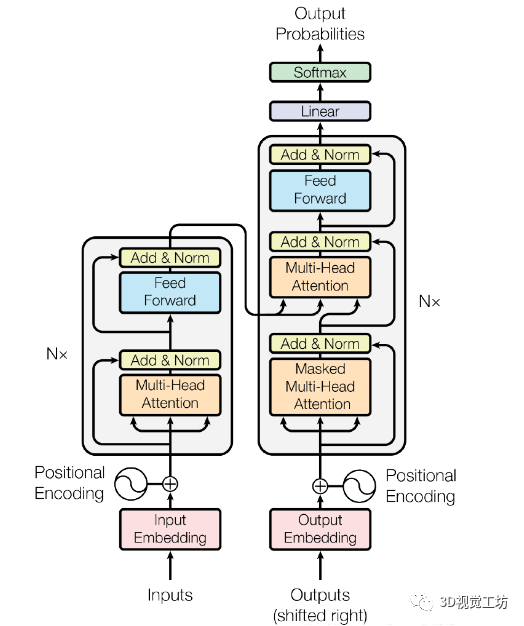
理解Transformer背后的理论基础,比如自注意力机制(self-attention), 位置编码(positional embedding),目标查询(object query)等等,网上的资料比较杂乱,不够系统,难以通过自学做到深入理解并融会贯通。
掌握基于Transformer的目标检测算法的思路和创新点,一些Transformer论文涉及的新概念比较多,话术没有那么通俗易懂,读完论文仍然不理解算法的细节部分。
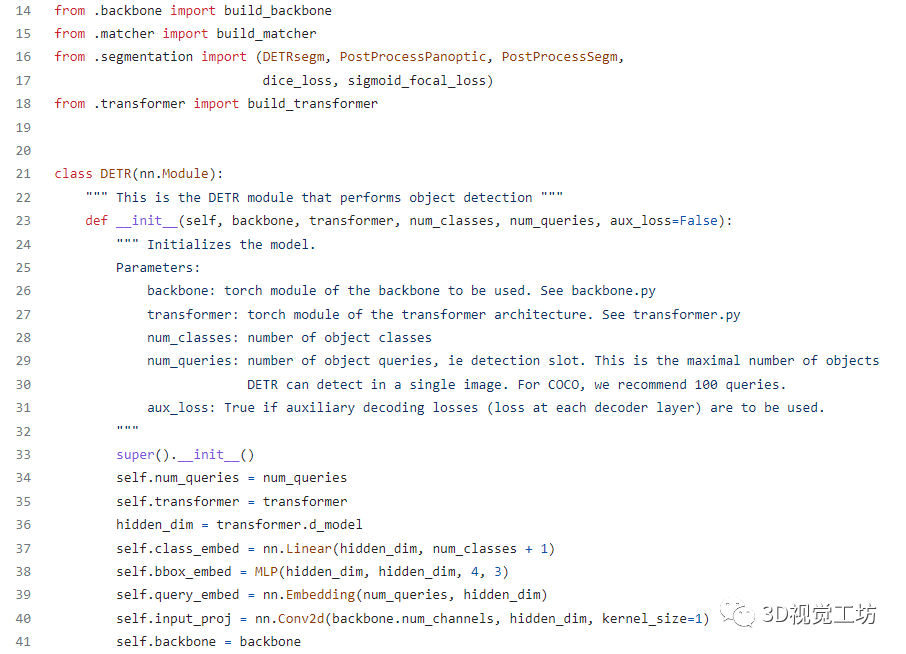
Transformer代码不易看懂,因为作用机制与CNN有不少差别,所以完全理解代码并实践应用需要花费很大功夫。
那么如何学习基于Tansformer的目标检测算法呢?
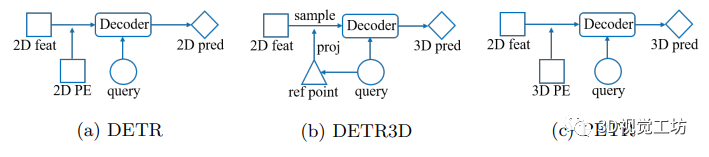
课程「目标检测中的视觉Transformer」正是帮助各位同学解决以上这些难点,不仅为大家详细讲解视觉Transformer的基础知识,还有各种经典的基于Transformer的目标检测算法,还配有代码解读和实践课程,让大家真正活学活用,理解和掌握这些知识理论。

实践部分
责任编辑:彭菁
-
目标检测
+关注
关注
0文章
209浏览量
15605 -
深度学习
+关注
关注
73文章
5500浏览量
121117
原文标题:目标检测中的视觉Transformer
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于深度学习的目标检测算法解析
PowerPC小目标检测算法怎么实现?
基于YOLOX目标检测算法的改进
基于像素分类的运动目标检测算法

基于多尺度融合SSD的小目标检测算法综述
浅谈红外弱小目标检测算法

无Anchor的目标检测算法边框回归策略

如何学习基于Tansformer的目标检测算法呢?

基于Transformer的目标检测算法






 工商网监
工商网监
评论