 NPU加速器建模设计(完整版)
NPU加速器建模设计(完整版)
对NPU进行建模的主要目的是快速评估不同算法、硬件、数据流下的延时、功耗开销,因此在架构的设计初期,可以评估性能瓶颈,方便优化架构。在架构和数据流确定后,建模可以快速评估网络在加速器上的执行效率。对其建模可以从从算法维度和硬件维度进行。
算法维度:以一定的方式表示需要加速的网络,如一些中间件描述,主要包括算子的类型、网络的层数以及操作数精度等信息,这一部分可以由自定义的网络描述文件表示,也可以由编译器解析网络文件生成,目的在于定量的描述工作负载。
硬件维度,包括计算资源和存储资源两部分,不同的NPU具有不同数量的计算资源,加速不同算子的并行度也会有所区别。不同NPU的存储层次结构也有很大区别,权重、特征是否共用同一片缓存或者有各自独立的缓存,每一级存储的容量、带宽以及相互之间的连接关系,都是设计空间的一部分。
建模分析的主要问题是功耗、延时以及访存。
对功耗而言,通常具有统一的分析方法,通过每个操作的功耗,比如一次乘法,加载一个数据等需要的功耗,以及总的操作次数相乘后累加,就可以估算出整体的功耗。延时可以通过RTL/FPGA等精确的仿真得到,适用于架构与数据流确定的情况。另外有一些基于数学方法分析的建模方法,并不会实际执行网络,而是根据网络参数、硬件参数进行数学推导,估算延时。对访存的估计与需求有关,有些建模方法只关注于对DRAM的访问,有些则会同时考虑到片上不同存储单元间的数据移动。
建模越精确其越贴近特定的架构,更有利于评估算法在特定硬件上的计算效率。
建模越模糊越具有普适性,有利于在加速器设计初期进行设计空间探索。
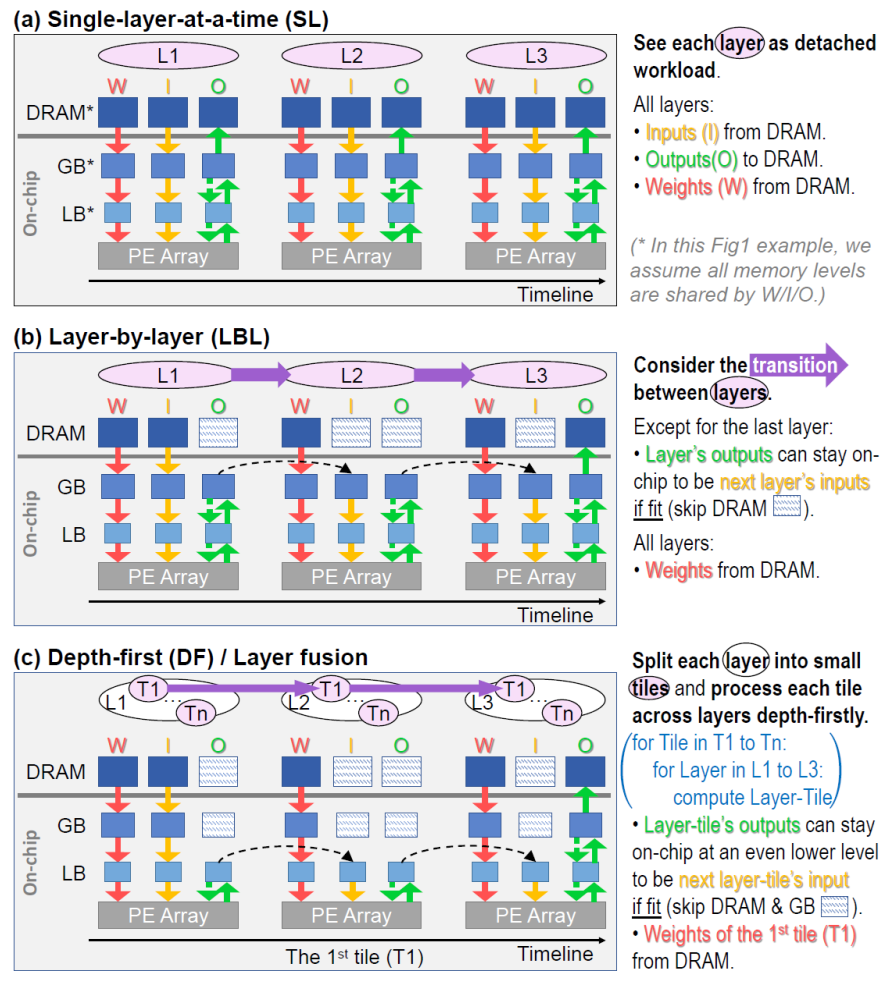
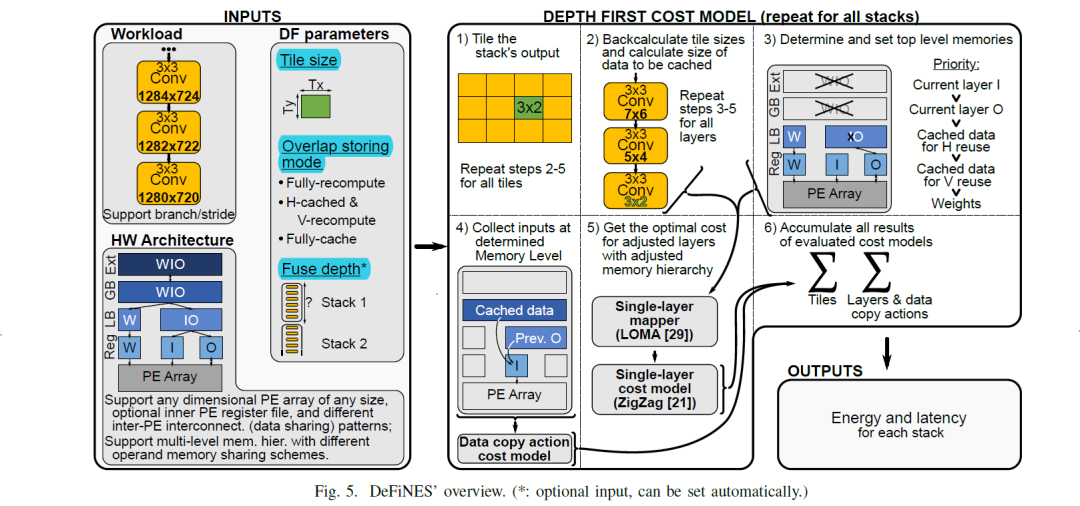
以下以最近的一篇论文为例,来分析加速器架构的设计空间探索,DeFiNES: EnablingFast Exploration of the Depth-first Scheduling Space for DNN Acceleratorsthrough Analytical Modeling,考虑了PE利用和内存层级结构,对于PE的利用,其主要是PE间的数据交互,排列和连接方式,并没有太大的探索空间,即计算和数据搬移的共同代价,在一些架构分析的时候,对内存层级关注较低,多集中on-off chip,这里深度优先的搜索加速器架构空间,配合cost model找到最优架构模型,从几个层面,逐次计算tile大小(会影响到between layer input/output位于那个内存层级上,以及weight复用的问题,即weight访问的频次),数据复用模式(即cache已计算的的数据,还是完全重新数据)以及层间融合(将层间存储在告诉存储区内完成上一层的output送入到下一层的input)减少高层存储访问三个方面来探讨搜索空间,需要一定的trade off,对于cost model,文章并没有作详细的介绍,cost model一般考虑lateny 和power两部分,尚未解决的问题:文章主要针对convolution进行的分析,以transform为代表的大模型,计算模式则完成不同,convolution计算中,weight复用,featuremap的滑动,以及感受野计算区域变化等和transform差距较大。优点:详细的内存层级分布的探讨和不同容量层级的内存分布,值得借鉴。缺点:cost model并未真正提及,对于convolution并没有关注到depthwise和point两种常见版本,对于transform新的计算模式并未涉及 文章中提及了fuselayer和cascade excute,前者很好理解,对于后者,给一个简单的介绍,所谓的cascade excute
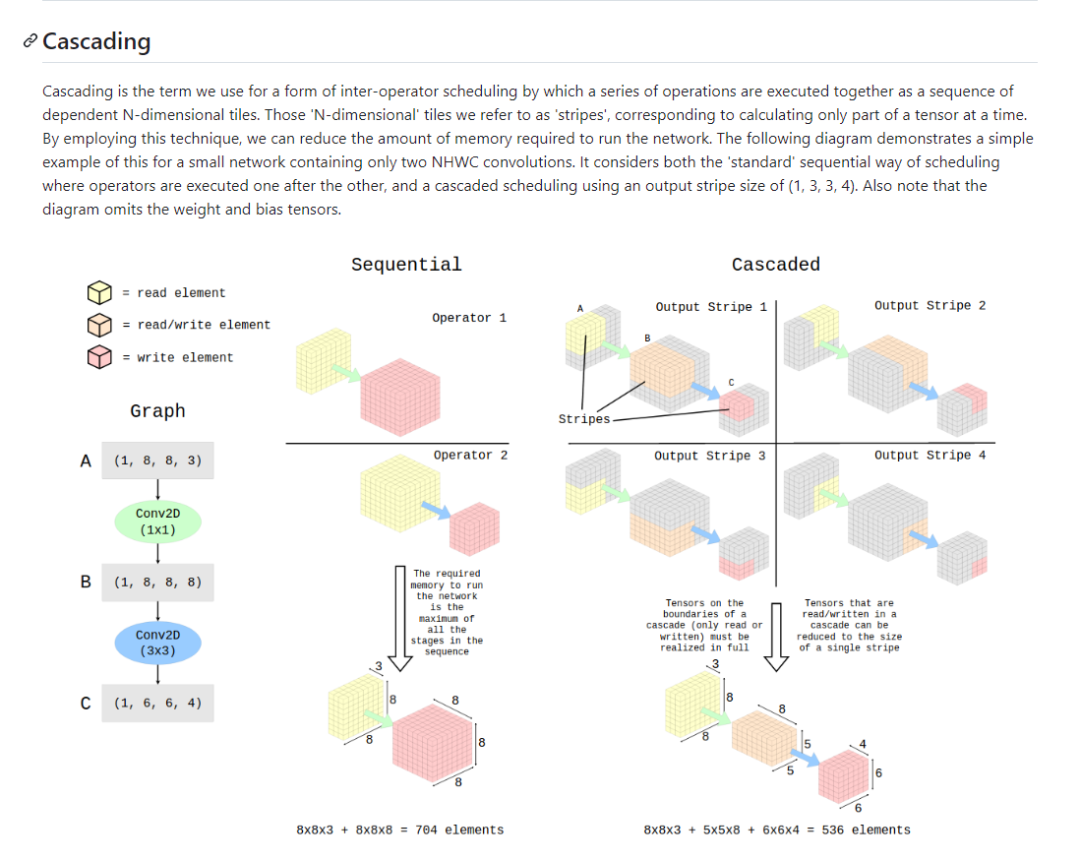
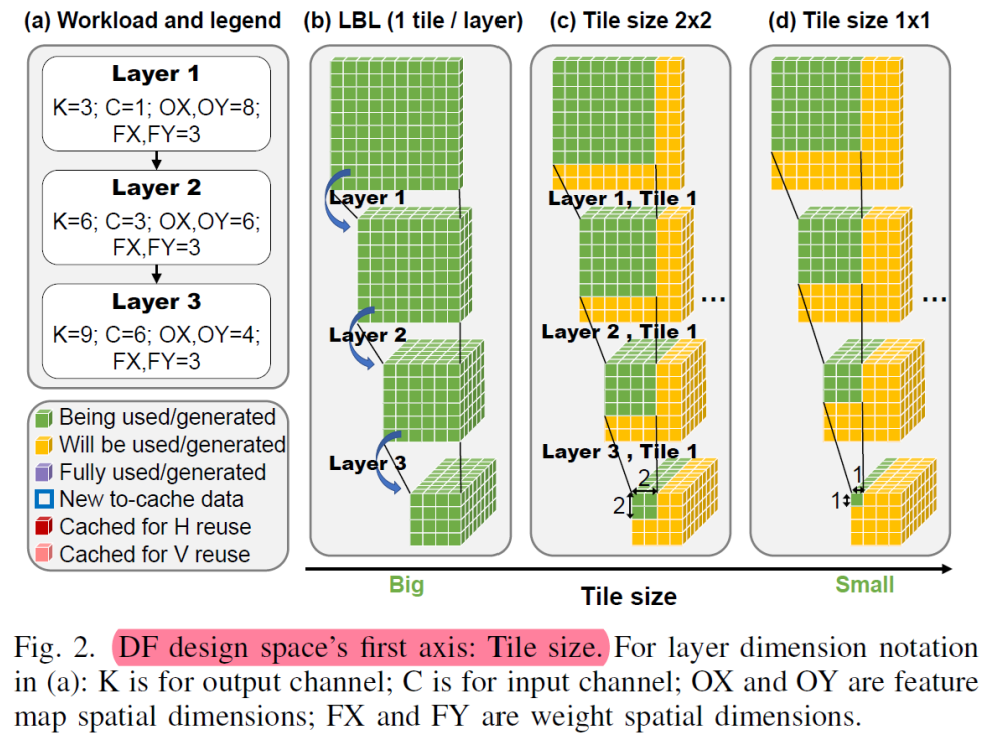
从图2这里可以看到,convolution的计算特点,weight在输入空间滑动带来的三个结果:1.支持逐个模块的计算,即这里延申的cross layer的tile计算块 2,数据的生产者消费者模式,即stride和kernel size差异引起的数据复用,和层间连接的数据交付 3.计算模式导致的存储结构,weight在层内的复用,而tile大小影响了计算时,weight的访问频次。基于此我们看到收感受野的影响(即convolution的计算结构)看到在fuse-layer的时候,较大的tile-size带来了较好的计算效率,对比图中可以看到tile_size=4*4,最上层的输入为10*10,tile_size为1*1,输入为7*7
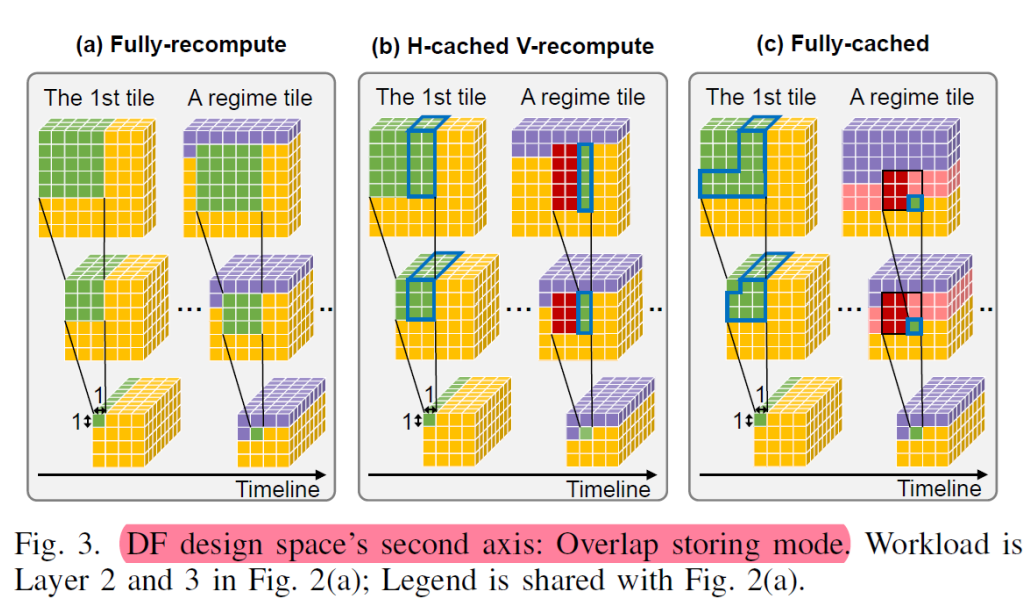
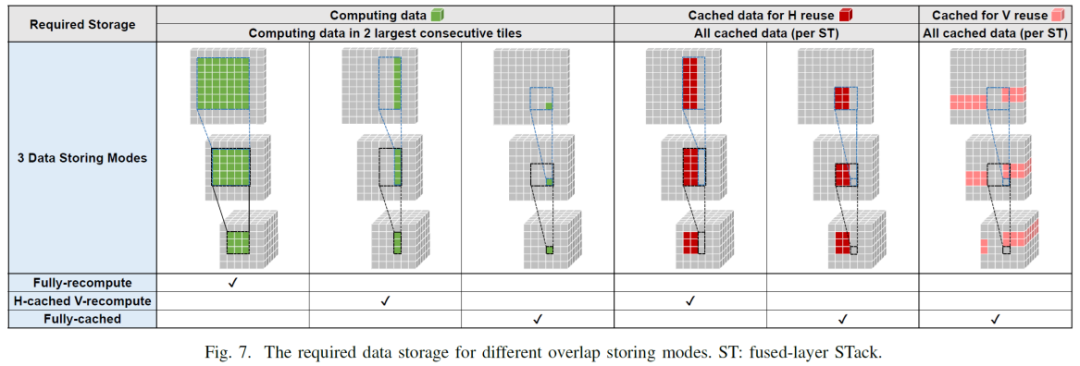
紫色的表示计算已经生成的数据,对于图a为完全每次都从第一层开始重新计算的模式,表示最后一层生成一个1*1*c绿色的数据,倒数第二层需要提供3*3*c绿色数据,第一层需要提供绿色5*5*c绿色数据,因为其属于fullyrecompute,即没有数据复用,可以看到底层的c个数据需求,前两层分别需要用到9c个和25c个。对于图b, 属于H-cached,V-recompute,即水平方向缓存,垂直方向计算,最后一行中,生成一个1*1*c绿色数据,对应上面一层需要3*3*c的数据块产于运算,这其中需要复用cached的红色2*3*c的数据,和新加入了绿的1*3*c的数据,这其中新加入的1*3的绿色数据会设置成new to-cache 1*3*c的数据为下一次的领域计算作为cache,如图种蓝色框对应,中图种新读入的1*3*c的数据,则对应最上层需要new to-cache 1*5*c的数据,图c同理
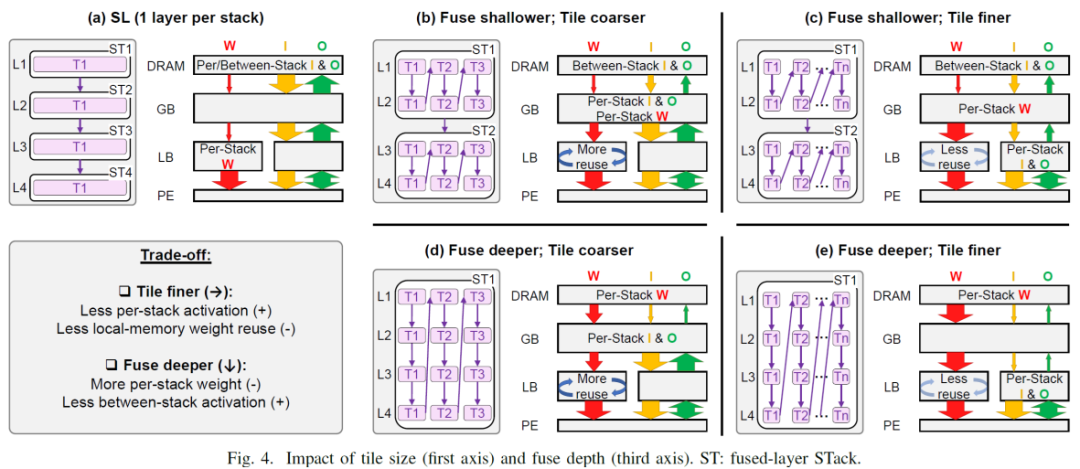
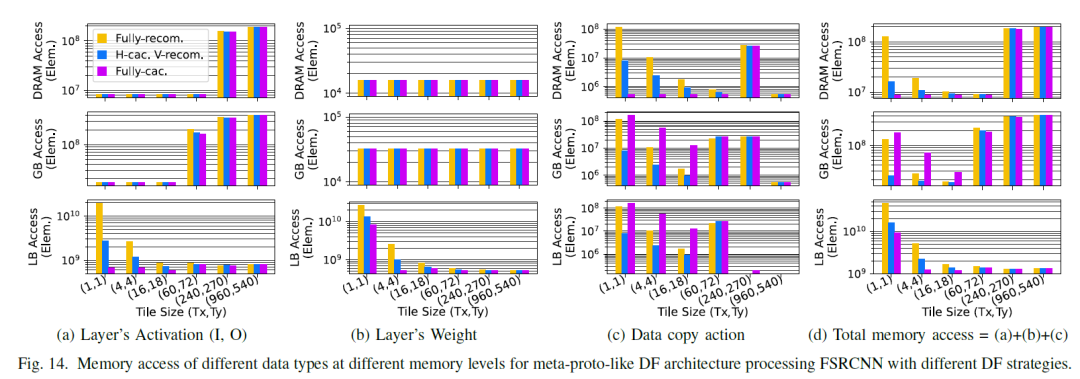
对于a,当一层一个stack的时候,每一层的weight比较小,则将其放置在LB中,因为其stack很浅,每层的between stack的I/O都会写到最慢的DRAM中,而其per stack的I/O(上一层的输出传递到下一层的输入)也只能在低级别存储中传递。
B vs C 相同之处,都进行了fuse, 对比a来说,因为fuse layer了,stack变深,多层间累计的weight变大,weight从原来图a中位于LB, 被迫放在了GB中,对于b vs c,看到tile粒度变细后,其相应的执行次数变多,则weight访问频次变高,c的 weight reuse变少。对于和a比较,因为fuse了,per stack的I/O(上一层的输出传递到下一层的输入)从a中的DRAM(因为a为single layer执行,即每次结果需要放回到DRAM,则between-stack的I/O放在DRAM,因为只有一层,其输出perI/O和between stack是一样的)移动到了GB中(b)或者LB中(c),因为tile粒度变小,所以c的per-stack位于LB中,而b 的per-stack位于GB中,对于between stack是位于stack之间的,无论b还是c都还是写入到最外层DRAM中,对于b和c而言fuse 层比较浅,对比可以看出tile 越细,即tile finer,则每一层的featuremap变小,per-stack的I/O越容易放到高速缓存中,看到在图C中 Per-Stack 的Input Feature Map & OutputFeatureMap集中在最底层的LB上,而图B中,则在放在GB中,即所谓tile finer--》less per-stackactivation. 但是同时也带来的缺点,多个tile则意味着更多次的访问weight,即所谓的tile finer-》lesslocal-memory weight reuse,再C中可以看到关于W为less reuse B vs D,对比可以看到,融合层数越多,即 fuse deeper,即每个stack包含的层数多,一个stack包含了多层的weight也就多,因此Moreper-stack weight, 对应图b中,weight可以在GB中,在图d,图e中,weight数据量较多,则都集中在了DRAM上,fusedeeper好处是这些stack中逐层之间的activation在高速存储中完成了交换(即上一层的输出是下一层的输入),图d中DRAM中没有 between-stack I/O ,I/O集中在下面的高速层,即lessbetween -stack activation
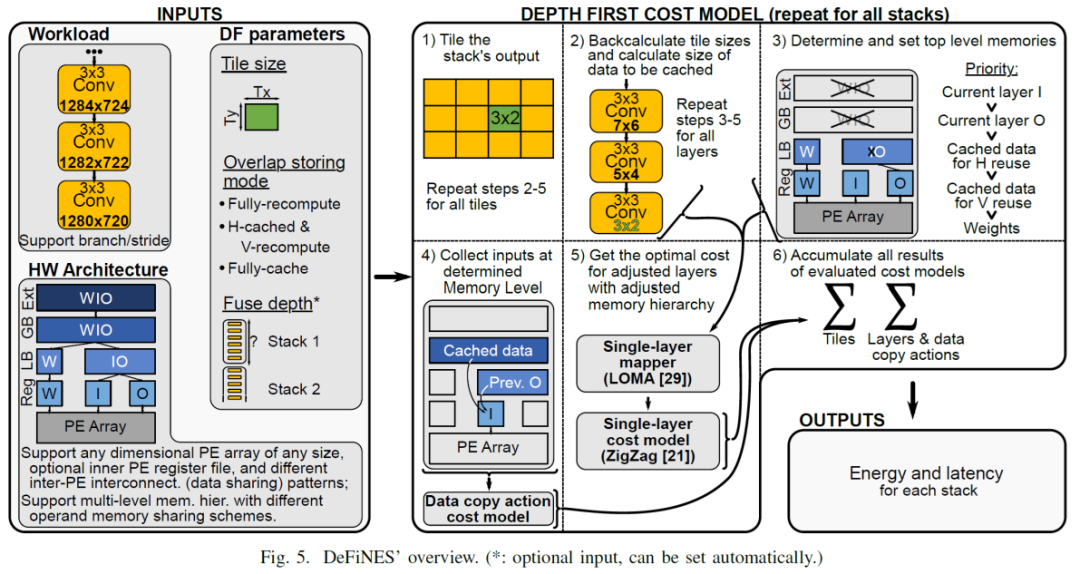
因为第一行/列中的块还没有可用的缓存数据——同样,最后一列/行中的块也不必为它们的邻居存储重叠,因此不是所有的tile都是相同的。
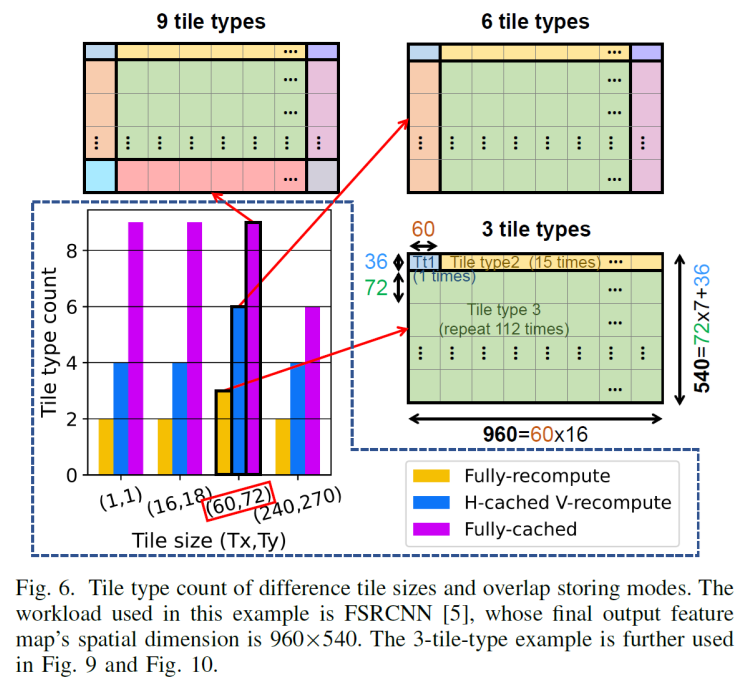
以下图来看那些数据可以利用cached data,那些用来cache for neighbors
5_step3 内存排列分布来看
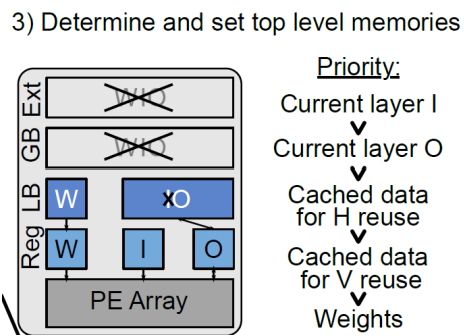

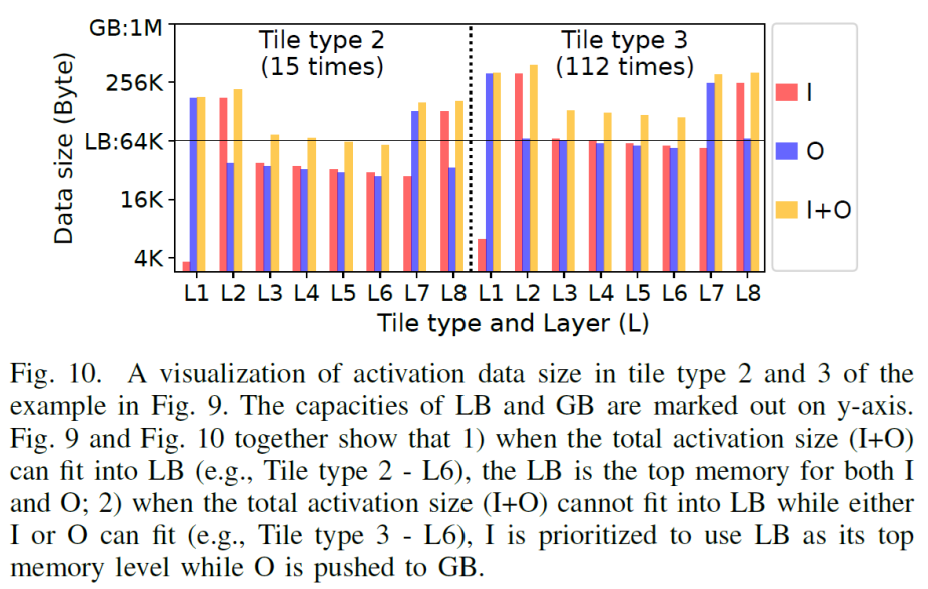
图9中为例看到,图像被分割成了3种tile,对于tile1,数目为1个,其weight首次需要从DRAM逐层搬移到进来,看到在tile type1中,其weight位于DRAM中,再其后的type2(15个)和type3(112个),weight是完全复用的,所以一直在LB结构中,对应于5_step3图中W位于LB中,而I因为有存储计算时的cache存在,前一层生成的输出可能部分被缓存起来,或者使用更低的内存级别用来作为下一层的输入,只会在每种type切换的时候,会从DRAM中读取一次数据,因此,从DRAM中读入后,以后的每次使用中,需要的一部分是新数据,一部分是来源于cache的数据,在type2和type3中,则基本都为LB中,而对于O只有在type类型切换,和最终结果则写出到DRAM中。从图5中step4可以看到,prev的outputfeautre map在内存层级中更优先于Cached data。
端到端的功耗匹配更具挑战性,因为它对几个细粒度设计和布局方面非常敏感,例如:
1)稀疏性,DepFiN使用稀疏性来关闭逻辑活动以节省功率;
2)位置和路由效应,导致数据传输比内存读/写成本更昂贵,还包括稀疏依赖效应;
3)工艺、电压和温度(PVT)变化
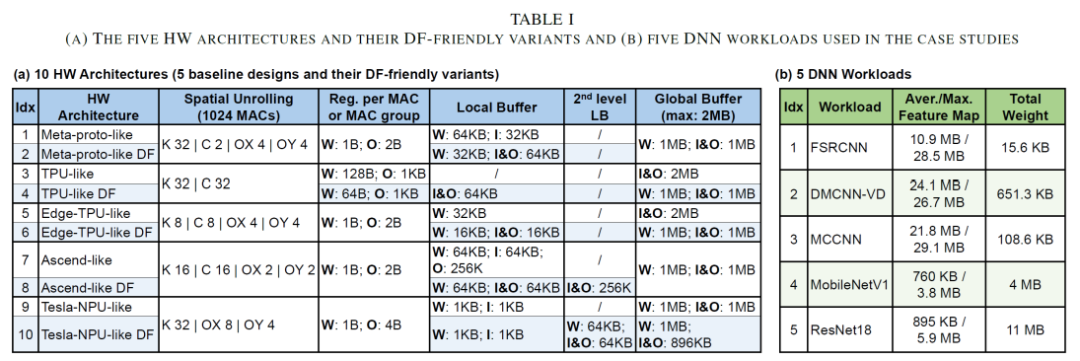
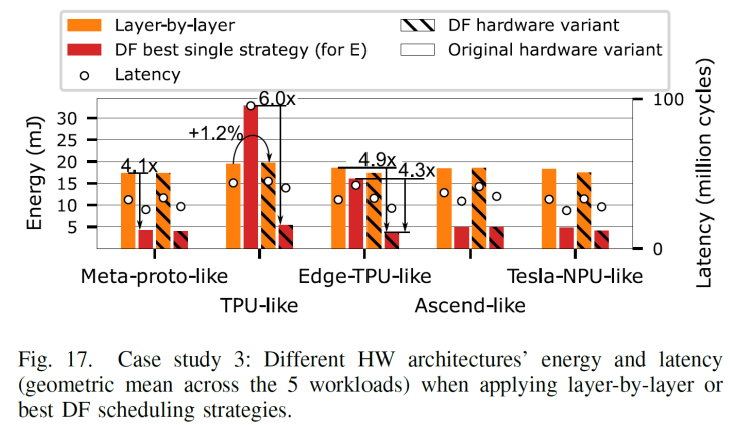
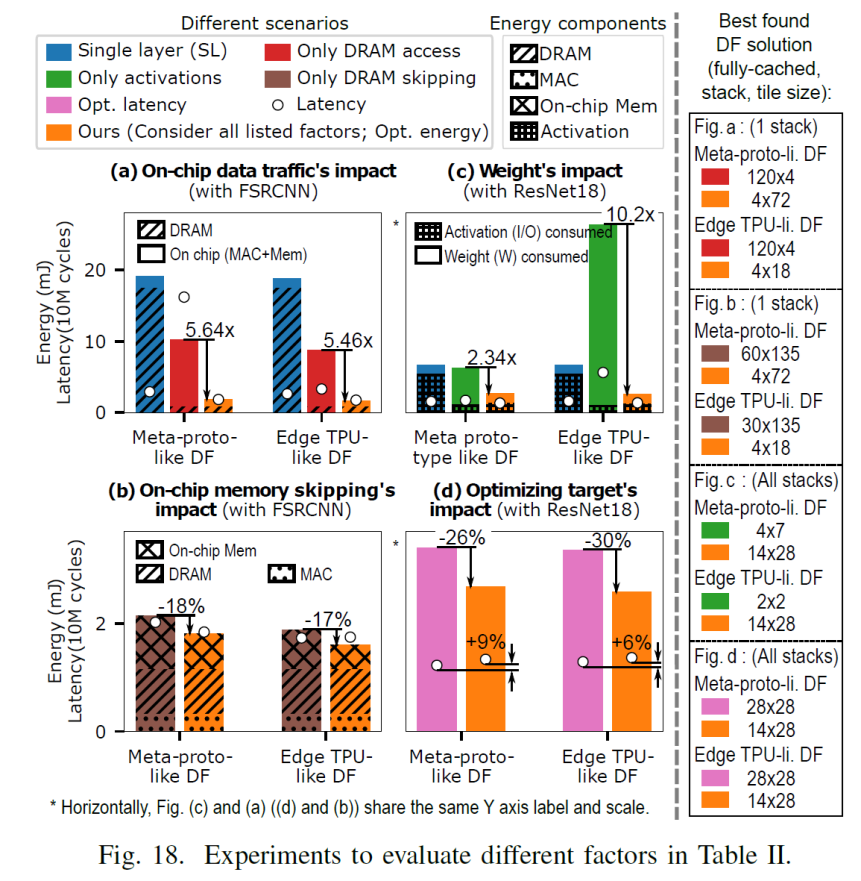
看table1看到对于架构进行like DF 手动改造的时候,对于meta-proto-like DF处理器,local buffer 减少了weight的分配,增大了I&O的数量, 并对 I&O 进行复用,增加I&O有助于融合的层次更深,支持更大一点的tile size,对于tpu-likeDF, 减少了reg for Mac group的数目,增加了Local buffer种I&O. 对于edgetpu-like DFT中,处理方式和meta-proto-like DF类似,都是减少了weight的LB的分配,增大了I&O,即更加关注可以用来在层间I/O传递, 给定一个workload和架构,深度优先策略的影响,以上图中Meta-proto-like DF架构和FSRCNN作为workload
case1:使用FSRCNN and Meta-proto-like DF 分别作为targeted workload 和 HWarchitecture. 对于三个DF影响因子,tile size, overlap storing mode 和fusedepth, 对应该case,其第三个轴fusedepth固定在整个DNN上,因为FSRCNN的总weight很小(15.6KB),因此所有权值都适合Meta-proto-likeDF架构的weight可以全部放进on-chiplocal buffer(看到该架构的weight使用的local buffer是32K),因此不把整个DNN融合成一个堆栈是没有好处
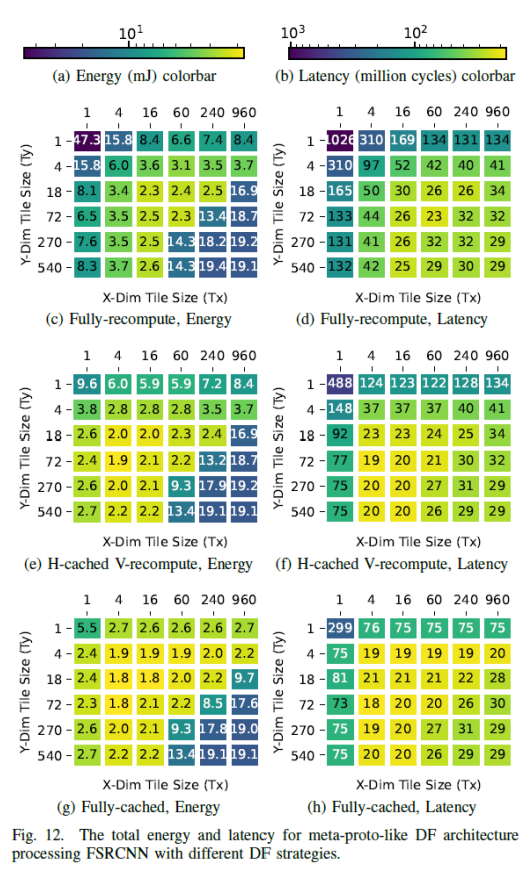
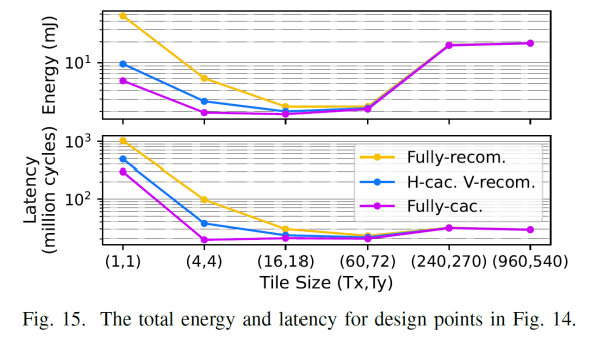
从图中,看右下角,不同计算模式下,它们的能量和延迟数(分别为19.1和29)是相同的,因为此时的tile大小为960*540即为全图,因此不存在tile, 即转换为了LBL, 因为不同的重叠存储模式对LBL没有影响
1.考虑相同重叠存储模式下,即同一个图内比较,发现不同的tile尺寸,tile尺寸太小和太大都是次优的。tile尺寸过大,会导致访问一些非常慢的存储层级,tile尺寸很小,则导致会大量访问weight, 太大太小都不是最好的选择,最好的点总是在中间的某个地方。
2.考虑不同重叠存储模式下相同的tile大小的情况下,即同一相对坐标下的跨图进行比较,大多数情况下能耗顺序为:full -cached 《 H-cached V-recompute《 full -recompute,这个也易于解释,适当的存储结构减少了大量的重复计算 3.不同的tile大小和模式会严重影响能量和延迟
4.fully recompute比fully-cached更喜欢更大的tile大小。Fully-cached倾向于小一些的tile.
对上图中,分析器对角线对应的tile组合,其对应的计算量如下
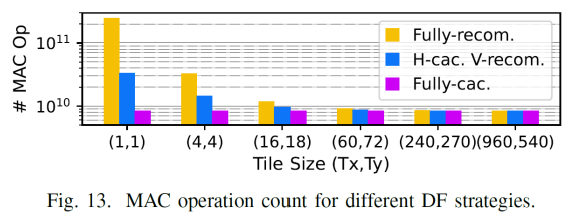
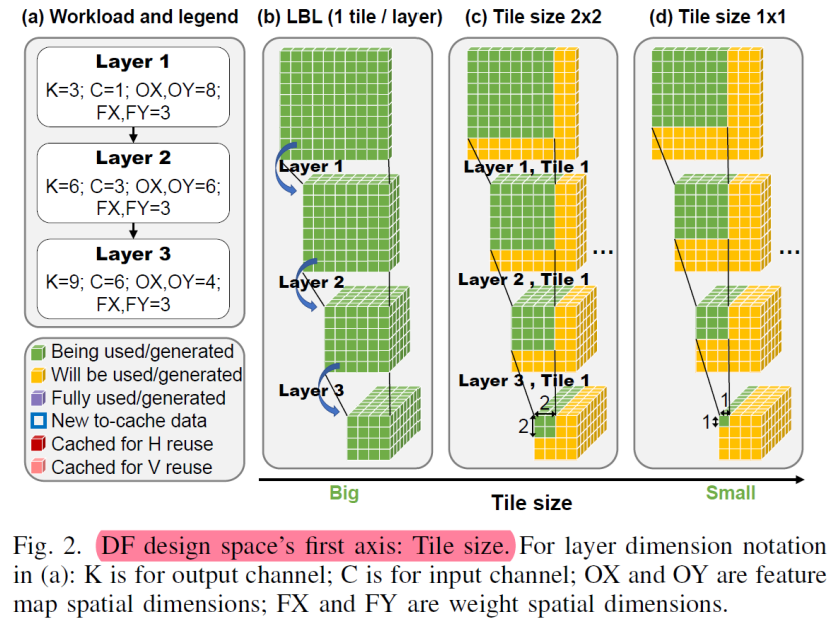
图13可以看到tile越小,则计算量反而越大,因为数据复用比例较低,在图13种可以看到在fully recom对应的1*1下,计算量最多, 以图2为例子,可以看到,对于tile1*1,则顶层需要的计算为7*7,而对于tile2*2 则需要的仅仅为8*8,因此可以看到tile size的大小并不是和计算量成线性关系,tile长宽增大一倍,计算量并没有相应的增大,而是小于其增速,则说明,tile越小,计算量较大,对于三种存储模式都是满足这个规律,只是full-cache 影响很小,统观全图,总的情况下满足fully-recom》H-cac,V-recom》Fully-cac. 再看到随着tilesize的增大,因为cache的数据(用于减少重复计算量)的数据通常为kernel width-1列(H-cac,V-recom),或者(kernel width*kernel width-1)个(对应于Fully-cac),但是相对于大的kernel size而言,cache起来的数据占的比例在减小,因此cached data的作用在降低,这也是在前面,对于上一层输出的output featuremap比cached data更优先占用较快存储,随着tile size增大,比如增加到960*540这个时候cache的意义也就没意义了(即转换成了LBL),因此计算量也就一样了。
----------------------------------------------------------------- 将深度优先应用于多个workload来分析其各自的性能,这里使用了如下的5种策略,和五个网络,其中FSRCNN/DMCNN-VD/MCCNN属于activation占主要的类的workload,而MobileNetV1/Resnet18则属于weight占主导的workload。
Single layer: layers are completely evaluated one at a time, feature maps are always stored to and fetched fromDRAM in between layers;
Layer-by-layer: layers are completely evaluated one at a time,thatmeans no tile, intermediate feature maps are passed on to the next layer in thelowest memory level they fit in;
Fully-cached DF with 4*72 tiles, which is the bestfound in case study 1;
The best strategy found when a single strategy is used for all fused layer stacks;
The best combination, where different stacks can use different DFstrategies.
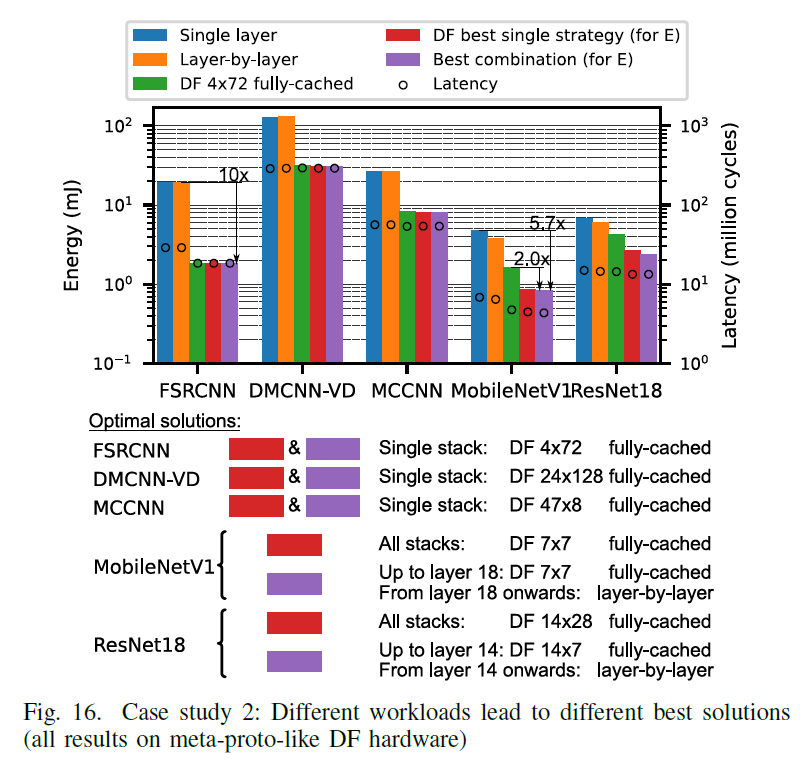
FSRCNN/DMCNN-VD/MCCNN属于activation占主要的类的workload, 这一类的特点weight比较少,适合多层进行fuse, 且weight通常多位于local sram中,且适合再进行 layer fuse的时候,stack的层次比较深,看到这三个网络的weight都在几十到几百K字节,适合fuse deep and single stack, 因此对于singlelayer是一种比较差的选择,这一类的另一个特点是activation占主要,则适合对activation 作 tile处理,因此,对于layer by layer也是一种比较差的选择,对应于图16 .FSRCNN/DMCNN-VD,MCCNN,使用singlelayer/layer-by-layer的时候效果都比较差。相应的这几种网络更适合选择fully-cache的tile,其多层融合的single stack, 对应于这三种网络,绿色DF 4x72 fully-cache,红色DF best single strategy 和紫色的best combination的效果都比较好。
再来看单一策略对不同网络的影响,对于Single layer,即每层作为一个stack, 对应于图中蓝色条,对于Layer-by-layer的黄色条,无论那种网络,这两张选择,其energy和latency都比较高。 因为其前者需要访问最慢的DRAM,后者无法tile,也需要访问较慢的存储结构,再来看DF best single stategy和best combination的两种情况下,即红色和紫色,对前三个网络都选择用了比较合适的single stack, 即所有的layer总体fuse一个single stack, ,其tile选取了较为合适的4*72/24*128/47*8, 对于数据存储,都选择了据存储性能为Fully-cache》H-cac,V-recom》Fully-cac,可以看到这三个网络都取得了不错的latency和energy,
绿色框DF tile采取相互适配的大小4*72,4*72模式也是在case1中对activation类型占优的网络找到的最优解,数据存储 选取为Fully-cached。在图中对于FSRCNN/DMCNN-VD/MCCNN,其DF4x72 fully -cached, DF best single strategy,Best combination占优,而Singlelayer/Layer-by-layer不占优
而对于MobileNetV1/Resnet18则属于weight占主导的workload,这一类的特点activation相对比较少,因此红色的DF best singlestategy和紫色的best combination中stack采取了不同的方式,以MobileNetV1为例子, DF best single stategy(a single strategy is used for all fusedlayer stacks)中每一个stack, 选取了7*7的tile大小,数据存储为fully-cached,而对于组合模式(where different stacks can use different DF strategies),则不同层使用不同的模式,前面18层使用一个固定的tile size,使用fully-cache, 而对于后面的层,以mobilenetV1为例子,whereas MobileNetV1 and ResNet18 are weight-dominant (feature mapsare smaller and gradually decrease across layers),在18层后,featureMap已经变得比较小,即不再对featuremap作tile处理。所以使用了layer-by-layer,总的来说更细粒度调度策略的紫色的best combination的效果最好。
-
FPGA
+关注
关注
1629文章
21729浏览量
603030 -
加速器
+关注
关注
2文章
798浏览量
37842 -
NPU
+关注
关注
2文章
280浏览量
18585
原文标题:NPU加速器建模设计(完整版)
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论