 CVPR 2023 | 清华大学提出LiVT,用视觉Transformer学习长尾数据
CVPR 2023 | 清华大学提出LiVT,用视觉Transformer学习长尾数据
 背景
背景
在机器学习领域中,学习不平衡的标注数据一直是一个常见而具有挑战性的任务。近年来,视觉 Transformer 作为一种强大的模型,在多个视觉任务上展现出令人满意的效果。然而,视觉 Transformer 处理长尾分布数据的能力和特性,还有待进一步挖掘。
目前,已有的长尾识别模型很少直接利用长尾数据对视觉 Transformer(ViT)进行训练。基于现成的预训练权重进行研究可能会导致不公平的比较结果,因此有必要对视觉 Transformer 在长尾数据下的表现进行系统性的分析和总结。

论文链接:
https://arxiv.org/abs/2212.02015代码链接:
https://github.com/XuZhengzhuo/LiVT 本文旨在填补这一研究空白,详细探讨了视觉 Transformer 在处理长尾数据时的优势和不足之处。本文将重点关注如何有效利用长尾数据来提升视觉 Transformer 的性能,并探索解决数据不平衡问题的新方法。通过本文的研究和总结,研究团队有望为进一步改进视觉 Transformer 模型在长尾数据任务中的表现提供有益的指导和启示。这将为解决现实世界中存在的数据不平衡问题提供新的思路和解决方案。 文章通过一系列实验发现,在有监督范式下,视觉 Transformer 在处理不平衡数据时会出现严重的性能衰退,而使用平衡分布的标注数据训练出的视觉 Transformer 呈现出明显的性能优势。相比于卷积网络,这一特点在视觉 Transformer 上体现的更为明显。另一方面,无监督的预训练方法无需标签分布,因此在相同的训练数据量下,视觉 Transformer 可以展现出类似的特征提取和重建能力。 基于以上观察和发现,研究提出了一种新的学习不平衡数据的范式,旨在让视觉 Transformer 模型更好地适应长尾数据。通过这种范式的引入,研究团队希望能够充分利用长尾数据的信息,提高视觉 Transformer 模型在处理不平衡标注数据时的性能和泛化能力。 文章贡献
本文是第一个系统性的研究用长尾数据训练视觉 Transformer 的工作,在此过程中,做出了以下主要贡献:
首先,本文深入分析了传统有监督训练方式对视觉 Transformer 学习不均衡数据的限制因素,并基于此提出了双阶段训练流程,将视觉 Transformer 模型内在的归纳偏置和标签分布的统计偏置分阶段学习,以降低学习长尾数据的难度。其中第一阶段采用了流行的掩码重建预训练,第二阶段采用了平衡的损失进行微调监督。
文章贡献
本文是第一个系统性的研究用长尾数据训练视觉 Transformer 的工作,在此过程中,做出了以下主要贡献:
首先,本文深入分析了传统有监督训练方式对视觉 Transformer 学习不均衡数据的限制因素,并基于此提出了双阶段训练流程,将视觉 Transformer 模型内在的归纳偏置和标签分布的统计偏置分阶段学习,以降低学习长尾数据的难度。其中第一阶段采用了流行的掩码重建预训练,第二阶段采用了平衡的损失进行微调监督。
 其次,本文提出了平衡的二进制交叉熵损失函数,并给出了严格的理论推导。平衡的二进制交叉熵损失的形式如下:
其次,本文提出了平衡的二进制交叉熵损失函数,并给出了严格的理论推导。平衡的二进制交叉熵损失的形式如下:
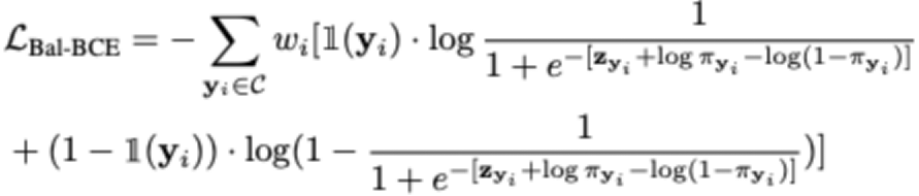 与之前的平衡交叉熵损失相比,本文的损失函数在视觉 Transformer 模型上展现出更好的性能,并且具有更快的收敛速度。研究中的理论推导为损失函数的合理性提供了严密的解释,进一步加强了我们方法的可靠性和有效性。
与之前的平衡交叉熵损失相比,本文的损失函数在视觉 Transformer 模型上展现出更好的性能,并且具有更快的收敛速度。研究中的理论推导为损失函数的合理性提供了严密的解释,进一步加强了我们方法的可靠性和有效性。
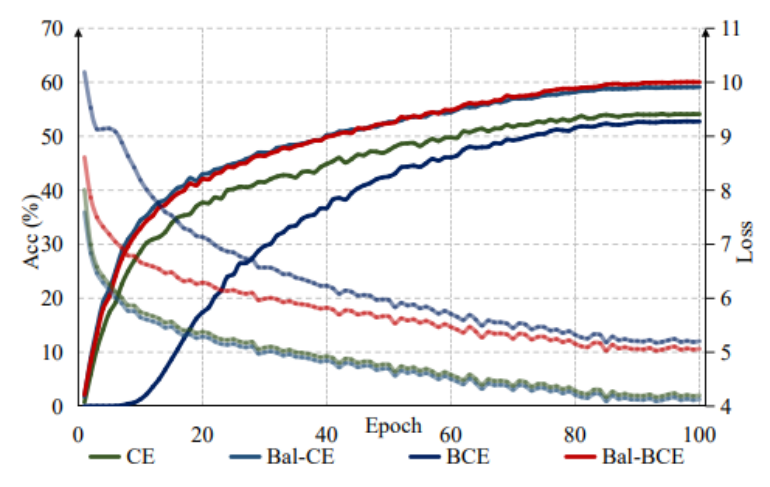 ▲不同损失函数的收敛速度的比较
基于以上贡献,文章提出了一个全新的学习范式 LiVT,充分发挥视觉 Transformer 模型在长尾数据上的学习能力,显著提升模型在多个数据集上的性能。该方案在多个数据集上取得了远好于视觉 Transformer 基线的性能表现。
▲不同损失函数的收敛速度的比较
基于以上贡献,文章提出了一个全新的学习范式 LiVT,充分发挥视觉 Transformer 模型在长尾数据上的学习能力,显著提升模型在多个数据集上的性能。该方案在多个数据集上取得了远好于视觉 Transformer 基线的性能表现。
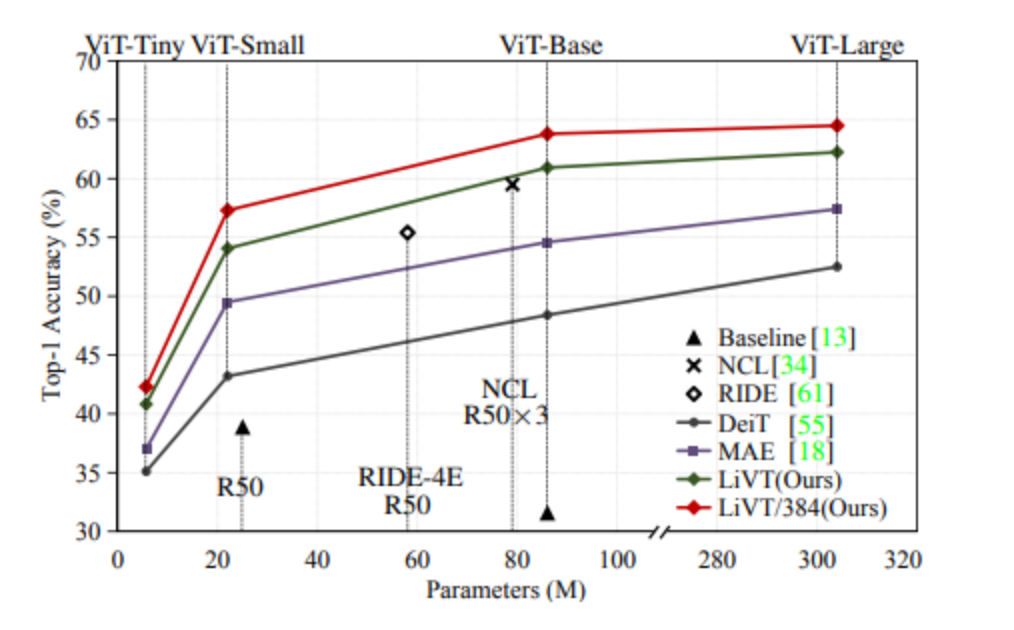 ▲不同参数量下在ImageNet-LT上的准确性
▲不同参数量下在ImageNet-LT上的准确性
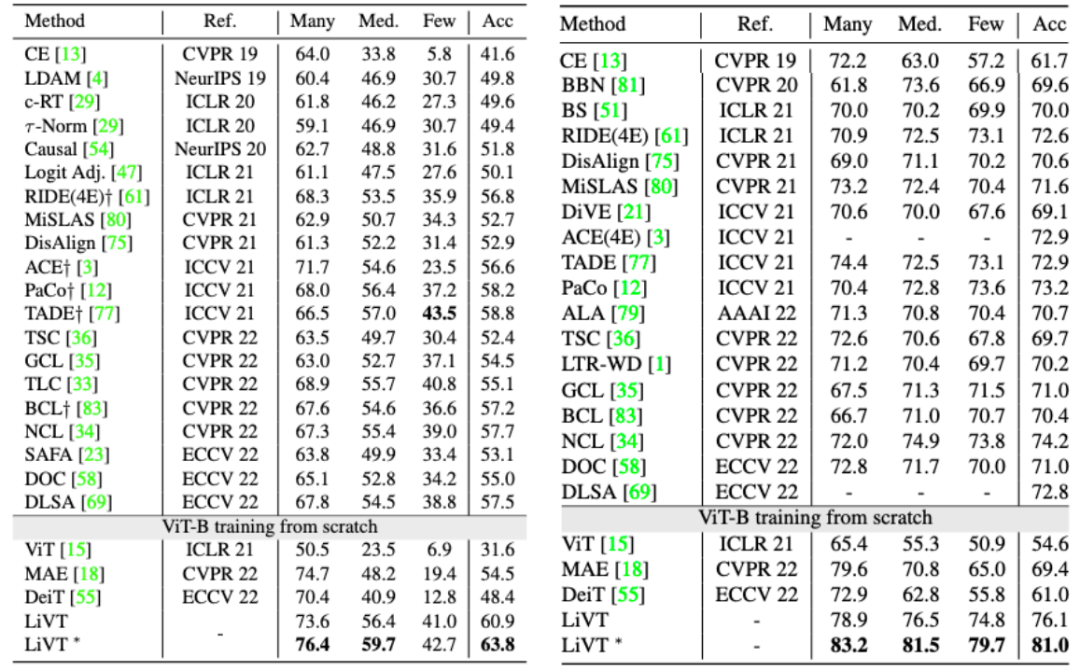 ▲在ImagNet-LT(左)和iNaturalist18(右)数据集上的性能表现
▲在ImagNet-LT(左)和iNaturalist18(右)数据集上的性能表现同时,本文还验证了在相同的训练数据规模的情况下,使用ImageNet的长尾分布子集(LT)和平衡分布子集(BAL)训练的 ViT-B 模型展现出相近的重建能力。如 LT-Large-1600 列所示,在 ImageNet-LT 数据集中,可以通过更大的模型和 MGP epoch 获得更好的重建结果。


总结
本文提供了一种新的基于视觉 Transformer 处理不平衡数据的方法 LiVT。LiVT 利用掩码建模和平衡微调两个阶段的训练策略,使得视觉 Transformer 能够更好地适应长尾数据分布并学习到更通用的特征表示。该方法不仅在实验中取得了显著的性能提升,而且无需额外的数据,具有实际应用的可行性。 论文的更多细节请参考论文原文和补充材料。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2909文章
44635浏览量
373379
原文标题:CVPR 2023 | 清华大学提出LiVT,用视觉Transformer学习长尾数据
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网威廉希尔官方网站 研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
清华大学师生到访智行者科技交流学习
近日,清华大学 “威廉希尔官方网站
创新原理与实践” 研究生课程师生一行到访智行者进行交流学习。作为课程实践环节的重要一站,此次来访开启了一场深度的参观学习之旅。智行者董事长&CEO张德兆先生作为清华
清华大学创新领军工程博士团队调研芯和半导体
近日,清华大学2024级创新领军工程博士团队到今年国家科技进步一等奖获得企业——芯和半导体上海总部参观调研。
博世与清华大学续签人工智能研究合作协议
近日,博世与清华大学宣布,双方续签人工智能领域的研究合作协议,为期五年。在此期间,博世将投入5000万元人民币。基于2020年成立的清华大学—博世机器学习联合研究中心(以下简称“联合研究中心”),博世和
京微齐力受邀参加2024年清华大学工程博士论坛
此前,2024年清华大学国家卓越工程师学院工程博士论坛在北京亦庄(北京经济威廉希尔官方网站
开发区)举办。本届论坛以“清亦融创、新质引领”为主题,来自集成电路、生物医药、人工智能等战略性新兴领域500余位清华大学创新领军工程博士生参加。
英诺达与清华大学携手,共促国产EDA进步
10月30日,英诺达官方微信发布消息称,英诺达与清华大学近期展开合作,共同深化产学研融合。此次合作聚焦于集成电路低功耗设计领域,英诺达团队走进清华大学集成电路学院,为师生们带来了专题授课及深入交流。
清华新力量,沪上芯征程!清华大学上海校友会半导体专委会2024思瑞浦迎新日
聚焦高性能模拟芯片2024年10月,清华大学上海校友会半导体专业委员会联合思瑞浦共同举办2024年来沪清华校友迎新活动。金秋时节,新一批清华人离开清华园来到上海,希望借此活动助力他们更

热烈欢迎清华大学电子工程系学子来武汉六博光电交流实践!
近日,武汉六博光电威廉希尔官方网站
有限责任公司接到清华大学函件,正式成为清华大学电子工程系武汉实践基地之一。2024年8月1日上午,清华大学电子工程系实践团队一行共计13名学子前往武汉六博光电有限责任公司交流

易华录无锡数据湖与清华大学苏州汽车研究院(吴江)合作挖掘智能驾驶数据新价值
6月15日,易华录无锡数据湖与清华大学苏州汽车研究院(吴江)数字工业中心就“聚焦汽车智能驾驶领域,共同挖掘智驾数据新价值”举行了签约仪式。清华大学苏州汽车研究院顾问、数字工业中心主任王
清华大学研发新型仿生三维电子皮肤系统
在科技日新月异的今天,清华大学再次引领了科研的潮流。6月5日,从清华大学传来喜讯,该校航天航空学院与柔性电子威廉希尔官方网站
实验室的张一慧教授团队,成功研制出了一款具有仿生三维架构的新型电子皮肤系统。这一突破性的科研成果不仅代表了电子皮肤领域的新高度,更在人机交互、物理量测量等多个领
世界首款!又是清华:类脑互补视觉芯片“天眸芯”
近日,清华大学在类脑视觉感知芯片领域取得重要突破:清华大学依托精密仪器系的类脑计算研究中心施路平教授团队,提出一种基于视觉原语的互补双通路类

清华大学创新领军工程博士团访问摩尔线程
5月19日,“清华大学创新领军工程博士代表团走进摩尔线程”活动顺利举办。近五十位来自集成电路、能源、航天、通信等重要领域的清华大学工程博士参加了本次活动。
清华大学创新领军工程博士代表团到访摩尔线程,深化产学合作
5月19日,“清华大学创新领军工程博士代表团走进摩尔线程”活动成功举行。此次活动聚集了五十多位来自集成电路、能源、航天、通信等重要行业的清华大学创新领军工程博士。

清华大学联合中交兴路发布《中国公路货运大数据碳排放报告》
为践行并推动实现“双碳”目标,清华大学联合中交兴路发布《中国公路货运大数据碳排放报告》(以下简称:《报告》)。

直线电机生产厂家谈清华大学获芯片领域重要突破
设备制造商、医学设备制造商、科研机构以及各大高校。 像大家熟知的清华大学、北京航空航天大学、西安交通大学、哈尔滨工业大学、浙江大学、南京

清华大学研发成功大规模干涉-衍射异构集成芯片——太极
4月12日公布,清华大学研发出太极芯片,实现了每瓦160TOPS的高性能通用智能计算,这是该校电子工程系与自动化系共同攻克的难题。





 工商网监
工商网监
评论