 语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
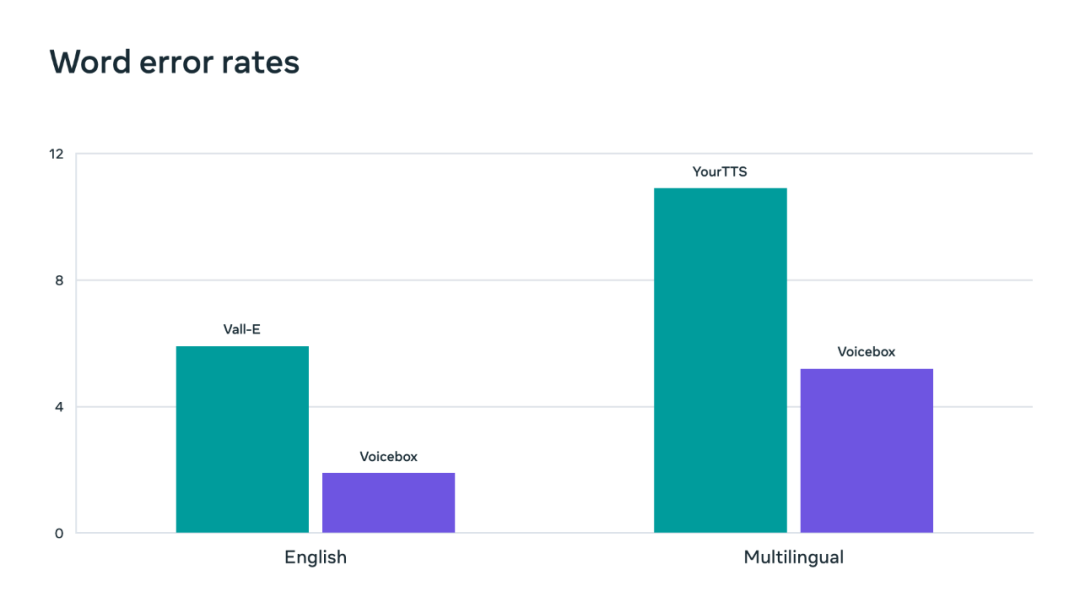
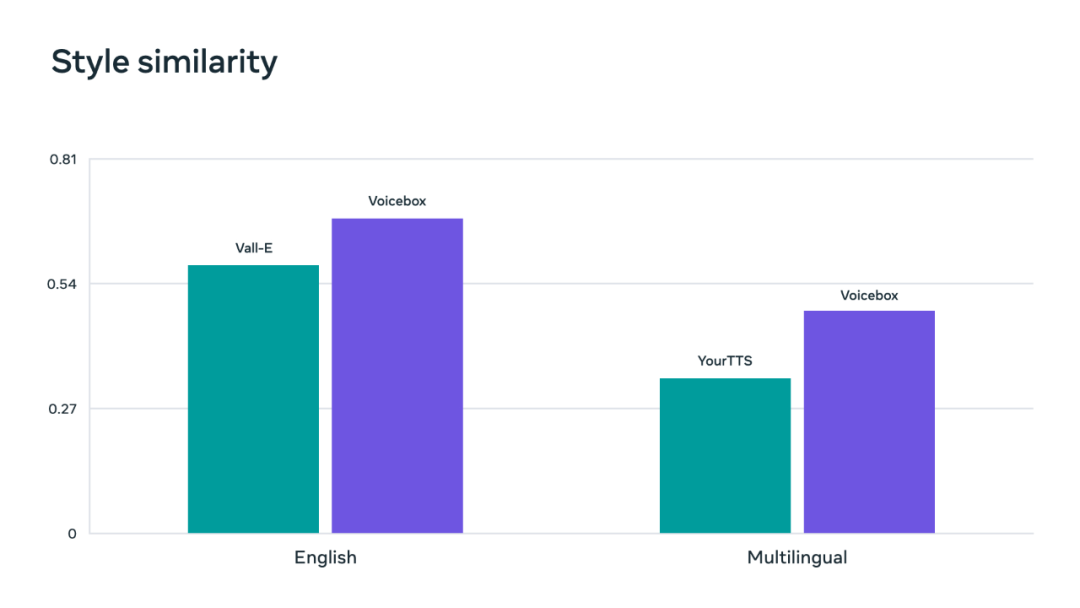
我们知道,GPT、DALL-E 等大规模生成模型彻底改变了自然语言处理和计算机视觉研究。这些模型可以生成高保真文本或图像,而且它们有个重要特点就是「通才」,可以解决没训过的任务。相比之下,语音生成模型在规模和任务泛化方面一直没有「突破性」成果。 今日,Meta 介绍了一种「突破性」的生成式语音系统,它可以合成六种语言的语音,执行噪声消除、内容编辑、转换音频风格等。Meta 称之为最通用的语音生成 AI。继开源 LLaMA 之后,Meta 在生成式 AI 方向又公布一项重大研究。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2909文章
44635浏览量
373383
原文标题:语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网威廉希尔官方网站 研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Meta重磅发布Llama 3.3 70B:开源AI模型的新里程碑
在人工智能领域,Meta的最新动作再次引起了全球的关注。今天,我们见证了Meta发布的 Llama 3.3 70B 模型,这是
阶跃星辰发布国内首个千亿参数端到端语音大模型
近日,阶跃星辰在官方公众号上宣布了一项重大突破——推出Step-1o千亿参数端到端语音大模型。该模型被誉为“国内首个千亿参数端到端
Meta发布新AI模型Meta Motivo,旨在提升元宇宙体验
Meta在人工智能领域迈出了重要一步。通过这款模型,Meta希望能够为用户提供更加自然、流畅的元宇宙交互体验。数字代理在元宇宙中的动作将更加
【实操文档】在智能硬件的大模型语音交互流程中接入RAG知识库
本帖最后由 jf_40317719 于 2024-9-29 17:13 编辑
智能硬件的语音交互接入大模型后可以直接理解自然语言内容,但大模型作为一
发表于 09-29 17:12
Jim Fan展望:机器人领域即将迎来GPT-3式突破
英伟达科学家9月19日,科技媒体The Decoder发布了一则引人关注的报道,英伟达高级科学家Jim Fan在近期预测,机器人威廉希尔官方网站
将在未来两到三年内迎来类似GPT-3在语言处理领域的
Meta发布Imagine Yourself AI模型,重塑个性化图像生成未来
Meta公司近日在人工智能领域迈出了重要一步,隆重推出了其创新之作——“Imagine Yourself”AI模型,这一
Meta发布全新开源大模型Llama 3.1
科技巨头Meta近期震撼发布了其最新的开源人工智能(AI)模型——Llama 3.1,这一举措标志着Meta在AI
Transformer模型在语音识别和语音生成中的应用优势
自然语言处理、语音识别、语音生成等多个领域展现出强大的潜力和广泛的应用前景。本文将从Transformer模型的基本原理出发,深入探讨其在
聆思CSK6视觉语音大模型AI开发板入门资源合集(硬件资料、大模型语音/多模态交互/英语评测SDK合集)
大模型语音问答、拍照识图、大模型绘图等丰富供能示例,支持语音唤醒、多轮语音交互。
2智能对话除了大模型
发表于 06-18 17:33
中国电信发布首个支持30种方言混说语音大模型
中国电信人工智能研究院(TeleAI)近日发布了一项引领业界的语音识别威廉希尔官方网站
——星辰超多方言语音识别大模型。这
OpenAI发布首个视频生成模型Sora
OpenAI近日宣布推出其全新的文本到视频生成模型——Sora。这一突破性的威廉希尔官方网站
将视频创作带入了一个
Meta推出最新版AI代码生成模型Code Llama70B
Meta近日宣布了其最新版本的AI代码生成模型Code Llama70B,并称其为“目前最大、最优秀的模型”。这一更新标志着





 工商网监
工商网监
评论