 基于Go的缓存实现方法
基于Go的缓存实现方法
概念
缓存是计算机科学中的一个重要概念。设想某个组件需要访问外部资源,它向外部源请求资源,接收并使用资源,这些步骤都需要花费时间。当组件再次需要资源时,可以再次请求资源,但这种方式从时间上考虑是比较低效的。相反,组件可以将请求结果保存在本地某处,然后再次使用,使用本地数据总是比请求外部数据要快,这一策略就是缓存的基本概念。我们可以在内存、CPU缓存和服务器缓存(如Redis)中找到这些例子。
不同用例
Web服务中的缓存用于减少数据请求的延迟。Web服务保存第一次查询的执行结果,然后在需要的时候再次使用,而不用再次访问数据库。取决于数据的特性,缓存有不同情况,可以有相对静态的数据,如统计数据、计算结果,也有可能是经常变化的数据,如评论区或SNS。
最好的情况是缓存那些很少变化的数据。以月度统计数据为例,上个月的数据将不会变化,如果对它进行缓存,可能就不需要查询数据库获取上个月的数据了。
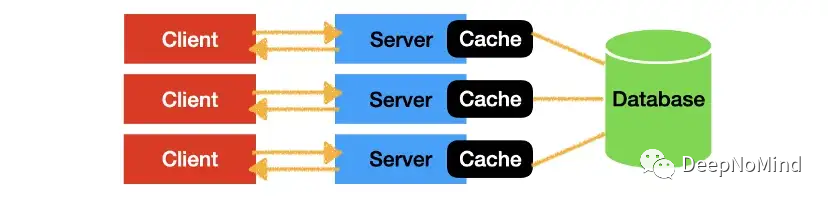
愚蠢的设计
对于快速变化的数据,在存在多个服务器时最好谨慎些。看看上面的设计,以评论区服务为例,考虑如下场景,用户A发表了一些评论,然后A决定删除评论,用户B尝试回复评论。在某些情况下,A和B向不同的服务器发送请求。A的删除操作可能不会传播到B的服务器缓存。结果会是这样: 缓存A和缓存B有不同的数据,数据库不知道哪个才是真实的,数据的完整性被破坏了。
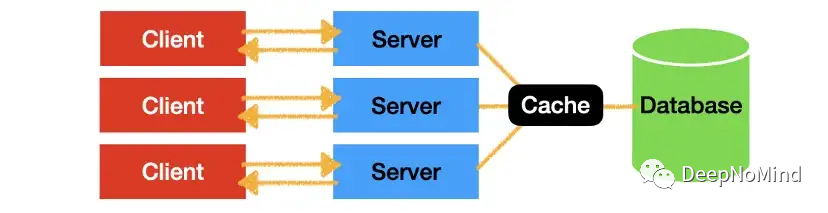
更好的方式
在这种情况下,可以使用单一外部缓存(如上图所示),多个服务器只访问统一的缓存。
限制条件
缓存比数据库要快,但在大小上要小得多。这是因为数据库将数据存储在驱动器中,缓存将数据存储在内存中。它们遵循各自相同的特征,同样也有不同的特点,如果主机停止工作,缓存的所有数据都会丢失,但数据库的数据不会丢失。
由于缓存位于内存中,空间是有限的,需要选择缓存哪些数据。在CS课上,我们会听到LRU(Least Recently Used,最近最少使用),LFU(Least Frequently Used,最不常用)和FIFO(First In First Out,先入先出)这样的词,这些是"选择哪一个"的标准,被称为驱逐策略(eviction policy)。
设计&实现
需求
键值存储(Key-Value Storage): 缓存既要有输入键、输出值的读功能,也要有输入键、值的写功能。这些函数应该在平均O(logN)时间内完成,其中N是键的数量。
LRU驱逐策略: 由于缓存空间有限,如果缓存满了,一些数据应该被清除,选择用LRU算法实现。
TTL (Time To Live): 每个键值都有生存时间,如果TTL到期,该键值应该被驱逐。
API设计
键值存储的意思是,如果请求键,缓存会返回那些存在的键的值,类似于hash-map抽象数据类型,以提供以下API概念的应用程序为例:
funcGet(keystring)(hitbool,value[]byte) funcPut(keystring,value[]byte)(hitbool)
Get: 通过键读取值的API。如果所提供的键在缓存中存在,则返回等效值。如果不存在,则返回hit=false。对于LRU策略,键将被标记为最近被使用,从而使该键不会被驱逐。
Put: 通过键写入值的API。如果所提供的键存在,则value将被替换为新值。如果不存在,将创建新的键值存储。因为该函数可以添加数据,其执行可能会导致溢出。在这种情况下,根据LRU策略,最近最少使用的键值将被清除。新添加/修改的键将被标记为最近使用的键。
数据结构
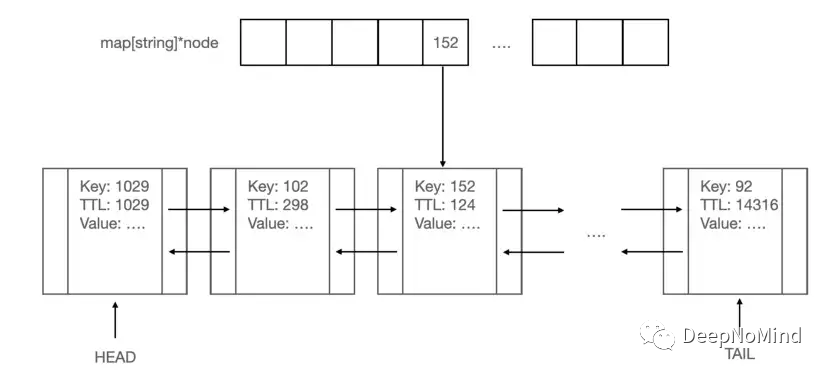
设计概念
我们使用两种不同的数据结构: hash-map和双向链表,实现键值读写和LRU策略的特性。
Hash-map: Hash-map是使用最广泛的键值数据结构,在Go中是现成的数据类型,可以通过map[
双向链表: LRU缓存可以通过双向链表实现。
基于这两种数据结构可以同时提供键值特性和LRU策略。参考以上设计概念图,hash-map的键将是字符串键,值是指向链表节点的指针,节点将保存键的值。
如果用户调用Get(),缓存应用程序将在hash-map中搜索键,跟随指针到达链表中的一个节点,获取值,完成LRU策略,并将值返回给用户。
类似的,如果调用Put(),会在hash-map中搜索键,跟踪指针并替换值,完成LRU策略,或者向hash-map中插入新键,并向链表中插入新节点。
并发控制
由于缓存被设计为支持频繁访问,因此在同一时间会有多个访问,并且总是存在并发问题的可能性。
在该设计中,存在两种不同的数据结构,并且并不总是同步的。在执行过程中,hash-map的修改和链表的修改之间有一个微小的时间间隔,请看下面的例子。
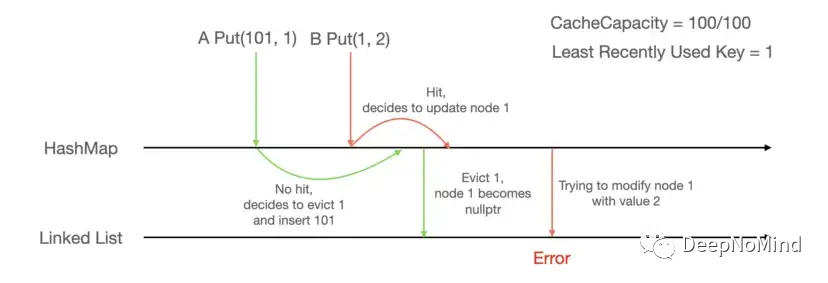
并发问题案例
该问题的触发条件为: 当前缓存已满,最近最少使用的键为1。这意味着,如果添加了新的键,键1和等效的值将被清除。
用户A使用新键101调用Put()。hash-map检查键,发现101不存在,决定清除1并将101添加到缓存中。
同时,用户B使用键1调用Put()。hash-map确认键1存在,并决定修改该值。
A的调用继续执行,从链表中删除节点1,从hash-map中删除键1。
紧接着,B的调用试图访问节点1的地址,并发现该地址已不存在,从而发生panic并造成应用失效。
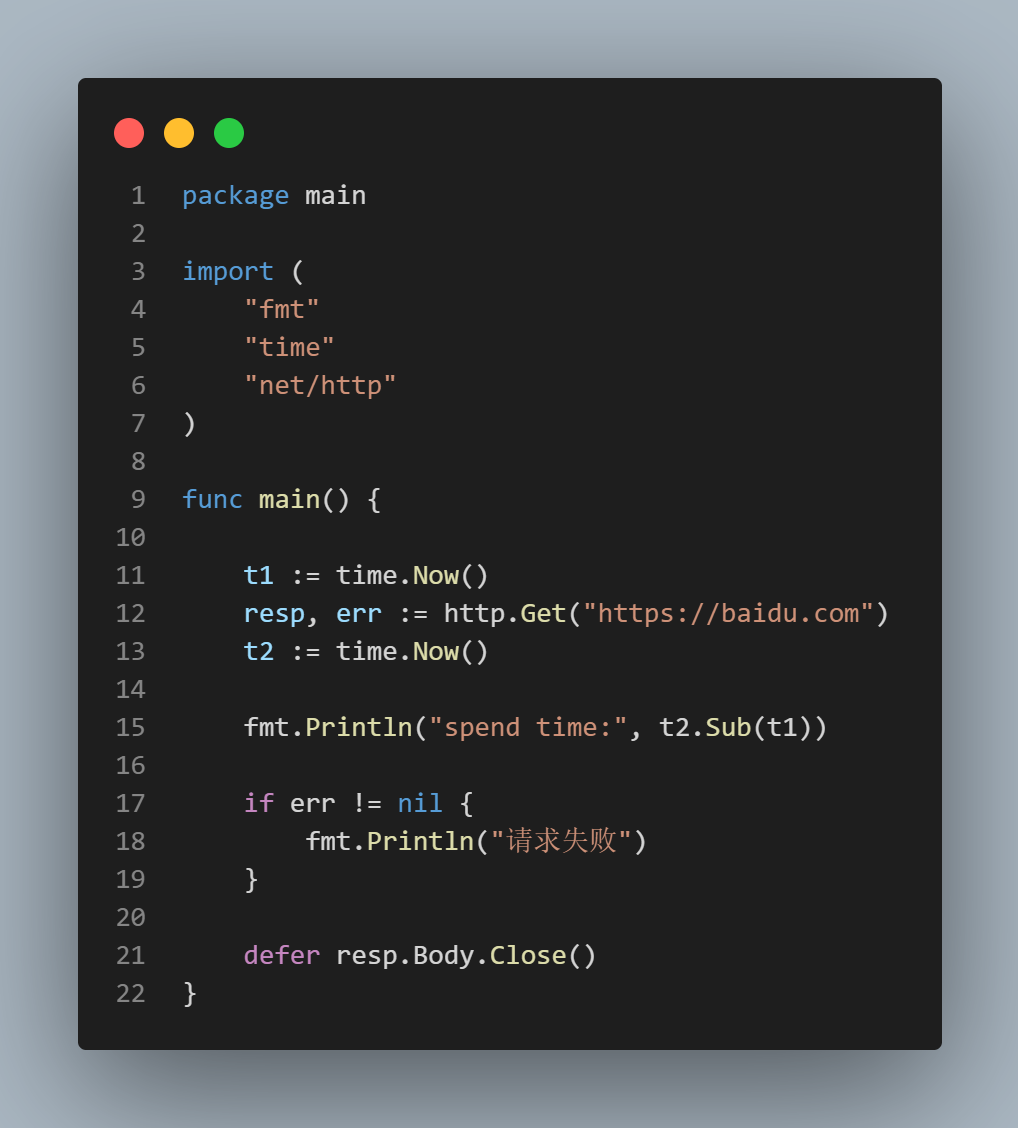
防止这种情况发生的最简单方法是使用互斥(Mutex),参考以下代码。
func(s*CStorage)Get(keystring)(data[]byte,hitbool){
s.mutex.Lock()
defers.mutex.Unlock()
n,ok:=s.table[key]
if!ok{
returnnil,false
}
ifn.ttl.Before(time.Now()){
s.evict(n)
s.size--
returnnil,false
}
returnn.data,true
}
这段代码是Get()的函数定义,可以看到在第一行中有互斥锁代码,在第二行中有defer的互斥锁解锁代码(defer是Go关键字,将行执行推迟到函数的末尾)。这些代码应用于所有其他数据存储访问功能,如Put、Delete、Clear等。
通过使用互斥锁,每次执行都不会受到其他操作的影响,保证了数据访问的安全性。
生存时间(Time To Live)
目前TTL是采用被动方式实现的,这意味着如果执行了数据访问函数(Get, Put),它将检查TTL是否过期并决定是否删除。这也意味着即使节点已经过期,将仍然存在于数据结构中。
这种方法不需要消耗大量CPU时间来定期遍历所有节点,但是缓存很可能会保存过期的值。
大多数情况下,这么做没有问题,因为过期节点很可能是"最近最少使用"状态。但是,如果有函数通过数据结构清除过期节点就更好了,所以我们使用RemoveExpired()函数。
func(s*CStorage)RemoveExpired()int64{
varcountint64=0
forkey,value:=ranges.table{
ifvalue.ttl.Before(time.Now()){
s.Delete(key)
count++
}
}
returncount
}
此函数将被定期调用以清除所有过期节点。
结果
实现的Go包可以导入其他Go项目。另外,我还做了独立的缓存应用程序,提供gRPC API,细节可以查看这个存储库[2]。
结论
这是个很好的重新审视缓存概念的机会,并且我们用Go实现了缓存。缓存是降低组件延迟的好工具,虽然空间受限,但速度更快。
实现实际的缓存模块可以用hash-map和双向链表完成。并发问题有点棘手,所以不得不使用互斥锁。此外,我们混合了被动和主动方式来删除过期数据。
审核编辑:刘清
-
TTL
+关注
关注
7文章
503浏览量
70232 -
FIFO存储
+关注
关注
0文章
103浏览量
5969 -
SNS
+关注
关注
0文章
7浏览量
6675 -
Hash算法
+关注
关注
0文章
43浏览量
7382
原文标题:基于Go的缓存实现
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ASP缓存威廉希尔官方网站
【GoRK3288】1.Rockchip RK3288, GO!GO!!GO!!!
会go语言能做什么工作?
linux的DNS缓存清空方法
高速缓存/海量缓存的设计实现
sdwebimage清除缓存方法

PIC32MZ器件系列中使用L1CPU高速缓存实现的风险和解决方法
dubbo-go 中的 TPS Limit 设计与实现
缓存如何工作,如何设计CPU缓存
缓存的原理/作用/使用的场景/方法
基于Memcached的缓存资源集中管理方法_郭栋

Go在单线程计算性能上的优势





 工商网监
工商网监
评论