 清华朱军团队提出ProlificDreamer:直接文本生成高质量3D内容
清华朱军团队提出ProlificDreamer:直接文本生成高质量3D内容
清华大学 TSAIL 团队最新提出的文生 3D 新算法 ProlificDreamer,在无需任何 3D 数据的前提下能够生成超高质量的 3D 内容。
ProlificDreamer 算法为文生 3D 领域带来重大进展。利用 ProlificDreamer,输入文本 “一个菠萝”,就能生成非常逼真且高清的 3D 菠萝:

给出稍微难一些的文本,比如 “一只米开朗琪罗风格狗的雕塑,正在用手机读新闻”,ProlificDreamer 的生成也不在话下:

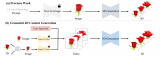
将 Imagen 生成的照片(下图静态图)和 ProlificDreamer(基于 Stable-Diffusion)生成的 3D(下图动态图)进行对比。有网友感慨:短短一年时间,高质量的生成已经能够从 2D 图像领域扩展到 3D 领域了!

A blue jay standing on alarge basket of rainbow macarons 这一切都来源于清华大学计算机系朱军教授带领的 TSAIL 团队近期公开的一篇论文《ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation》:

论文链接:https://arxiv.org/abs/2305.16213
项目主页:https://ml.cs.tsinghua.edu.cn/prolificdreamer/
在数字创作和虚拟现实等领域,从文本到三维模型(Text-to-3D)的威廉希尔官方网站 具有重要的价值和广泛的应用潜力。这种威廉希尔官方网站 可以从简单的文本描述中生成具体的 3D 模型,为设计师、游戏开发者和数字艺术家提供强大的工具。 然而,为了根据文本生成准确的 3D 模型,传统方法需要大量的标记 3D 模型数据集。这些数据集需要包含多种不同类型和风格的 3D 模型,并且每个模型都需要与相应的文本描述相关联。创建这样的数据集需要大量的时间和人力资源,目前还没有现成的大规模数据集可供使用。 由谷歌提出的 DreamFusion [1] 利用预训练的 2D 文本到图像扩散模型,首次在无需 3D 数据的情况下完成开放域的文本到 3D 的合成。但是 DreamFusion 提出的 Score Distillation Sampling (SDS) [1] 算法生成结果面临严重的过饱和、过平滑、缺少细节等问题。高质量 3D 内容生成目前仍然是非常困难的前沿问题之一。 ProlificDreamer 论文提出了 Variational Score Distillation(VSD)算法,从贝叶斯建模和变分推断(variational inference)的角度重新形式化了 text-to-3D 问题。具体而言,VSD 把 3D 参数建模为一个概率分布,并优化其渲染的二维图片的分布和预训练 2D 扩散模型的分布间的距离。可以证明,VSD 算法中的 3D 参数近似了从 3D 分布中采样的过程,解决了 DreamFusion 所提 SDS 算法的过饱和、过平滑、缺少多样性等问题。此外,SDS 往往需要很大的监督权重(CFG=100),而 VSD 是首个可以用正常 CFG(=7.5)的算法。效果展示ProlificDreamer 可以根据文本生成非常高质量的带纹理的三维网格:

ProlificDreamer 可以根据文本生成非常高质量的三维神经辐射场(NeRF),包括复杂的效果。甚至 360° 的场景也能生成:

ProlificDreamer 还可以在给出同样文本的情况下生成具有多样性的 3D 内容:

传统文生 3D 的优化算法给定一个 2D 图片上预训练好的扩散模型(例如 stable-diffusion),Dreamfusion [1] 提出可以在不借助任何 3D 数据的情况下实现开放域的文到 3D 内容(text-to-3D)生成。具体而言,对于一个 3D 物体,文生 3D 任务的关键是设计一种优化算法,使得 3D 物体在各个视角下投影出来的 2D 图片与预训练的 2D 扩散模型匹配,并不断优化 3D 物体。其中,SDS [1] (也称为 Score Jacobian Chaining (SJC) [3]) 是目前几乎所有的零样本开放域文生 3D 工作所使用的算法。该算法将 3D 物体视为一个单点(single point),并通过随机梯度下降优化该 3D 物体,优化目标是最大化该渲染的 2D 图像在预训练扩散模型下的似然值。值得注意的是,该优化问题的最优解并不等价于从扩散模型中采样。
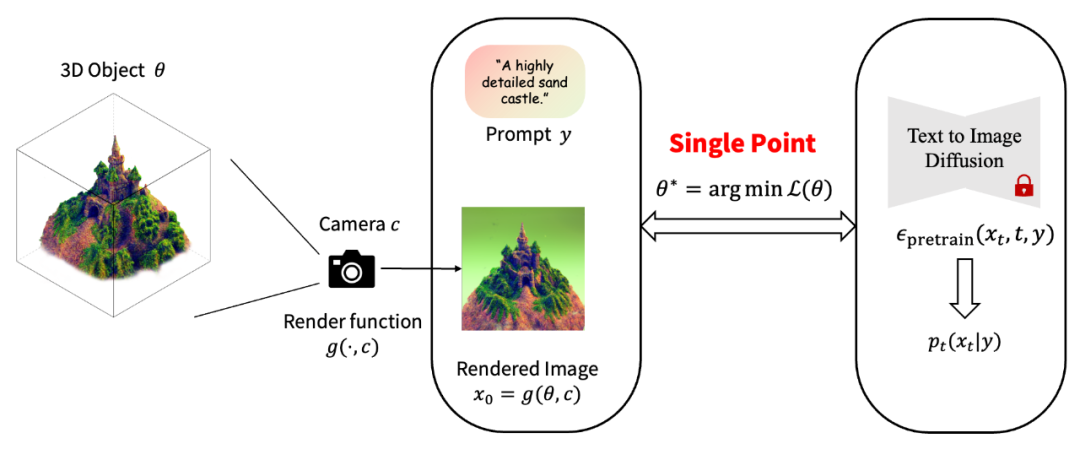
传统文生 3D 的优化算法示意图 实验中,所有基于 SDS/SJC 的方法目前都有一个严重的问题:生成的物体过于平滑、过饱和现象严重,并且多样性不高。例如,开源库 threestudio [4] 将目前主流的 text-to-3D 工作复现至与原论文可比水平,如下图所示:

由 threestuidio [4] 复现的文生 3D 工作 在此之前,基于 2D 扩散模型的文生 3D 仍然与实践落地有较大差距。然而,清华大学朱军团队提出的 ProlificDreamer 在算法层面解决了 SDS 的上述问题,能够生成非常逼真的 3D 内容,极大地缩小了这一差距。ProlificDreamer 的原理与以往方法不同,ProlificDreamer 并不单纯优化单个 3D 物体,而是优化 3D 物体对应的概率分布。通常而言,给定一个有效的文本输入,存在一个概率分布包含了该文本描述下所有可能的 3D 物体。
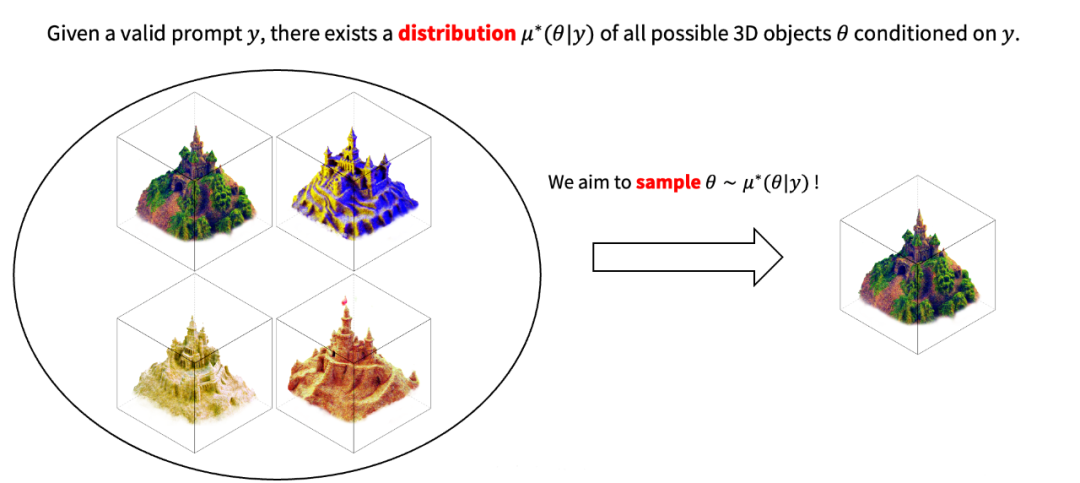
给定文本下的 3D 物体存在一个潜在的概率分布 基于该 3D 概率分布,我们可以进一步诱导出一个 2D 概率分布。具体而言,只需要对每一个 3D 物体经过相机渲染到 2D,即可得到一个 2D 图像的概率分布。
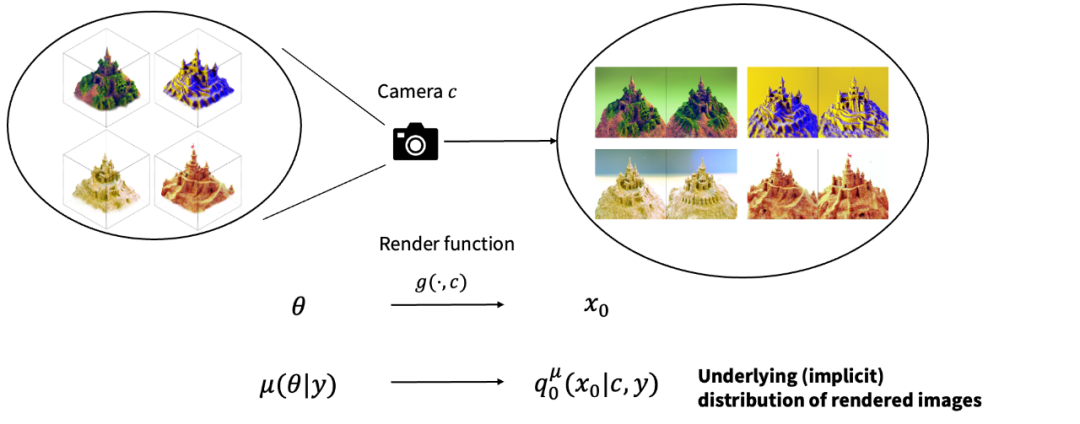
由潜在 3D 分布可以诱导出一个 2D 图像分布 因此,优化 3D 分布可以被等效地转换为优化 2D 渲染图片的概率分布与 2D 扩散模型定义的概率分布之间的距离(由 KL 散度定义)。这是一个经典的变分推断(variational inference)任务,因此 ProlificDreamer 文中将该任务及对应的算法称为变分得分蒸馏(Variational Score Distillation,VSD)。
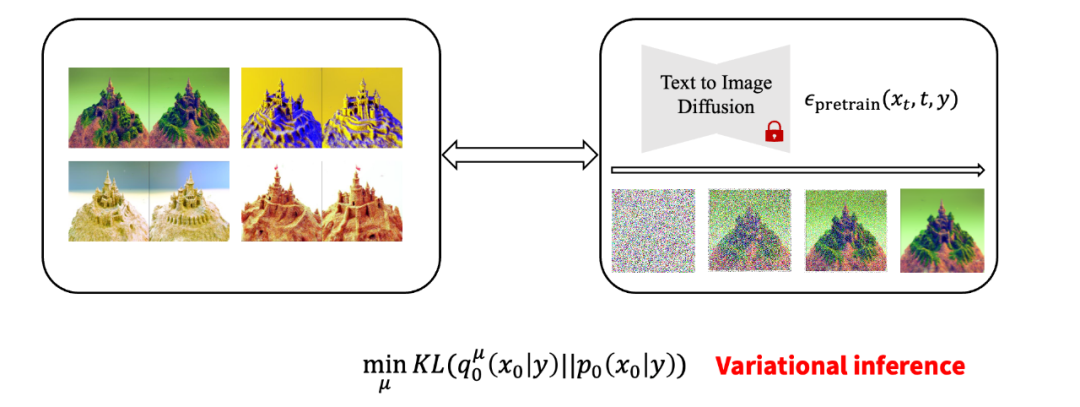
优化 3D 分布可以被等效地转换为优化 2D 图片之间的概率分布 具体而言,VSD 的算法流程图如下所示。其中,3D 物体的迭代更新需要使用两个模型:一个是预训练的 2D 扩散模型(例如 Stable-Diffusion),另一个是基于该预训练模型的 LoRA(low-rank adaptation)。该 LoRA 估计了当前 3D 物体诱导的 2D 图片分布的得分函数(score function),并进一步用于更新 3D 物体。该算法实际上在interwetten与威廉的赔率体系 Wasserstein 梯度流,并可以保证收敛得到的分布满足与预训练的 2D 扩散模型的 KL 散度最小。
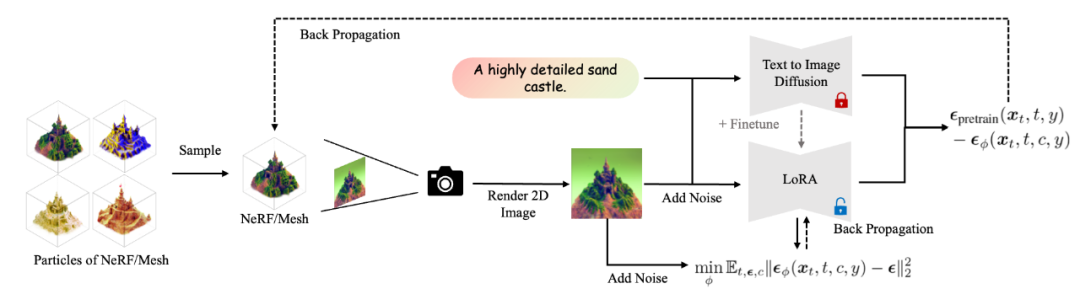
VSD 的训练流程图 与传统的 SDS/SJC 算法相比,可以发现 VSD 仅仅需要把原来的高斯噪声项换成 LoRA 项即可。由于LoRA 提供了比高斯噪声更精细的更新方向(例如,LoRA 可以利用文本 y、相机视角 c、扩散时间 t 等的先验信息),VSD 在实践中可以得到远超 SDS 的精细结果。并且,论文作者提出,SDS/SJC 实际上是 VSD 使用一个单点 Dirac 分布作为变分分布的特例,而 VSD 扩展到了由 LoRA 定义的更复杂的概率分布,因此可以得到更好的结果。此外,VSD 还对监督权重(CFG)更友好,可以使用与 2D 扩散模型一样的监督权重(例如 stable-diffusion 常用的 CFG=7.5),因此可以达到和 2D 扩散模型类似的采样质量。这一结果首次解决了 SDS/SJC 中的超大 CFG(一般为 100)的问题,也同时说明 VSD 这种基于分布优化的思想与预训练的 2D 扩散模型更适配。
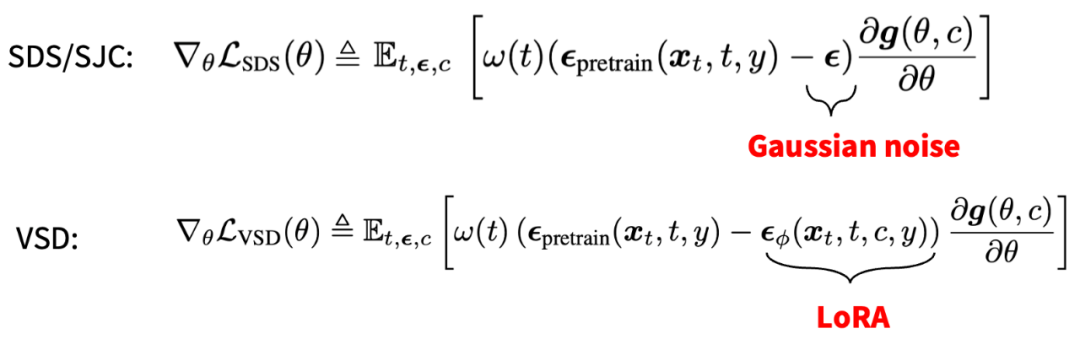
SDS/SJC 与 VSD 的更新公式对比 最后,ProlificDreamer 还对 3D 表示的设计空间做了详细的研究,提出了如下实现。在实践中,VSD 可以在 512 渲染分辨率的 NeRF 下训练,并极大地丰富了所得到的 3D 结果的纹理细节。
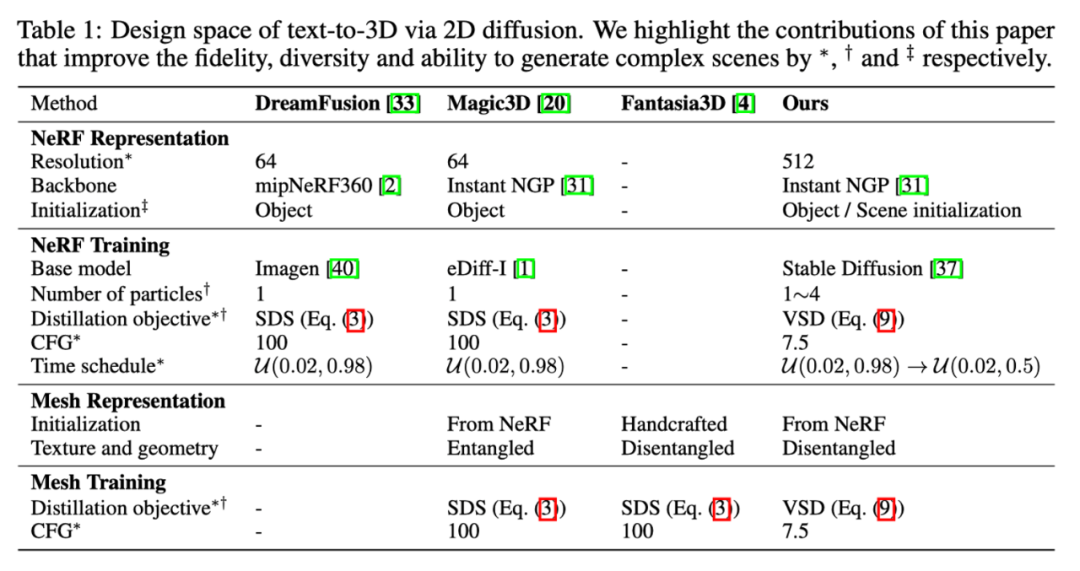
ProlificDreamer 与其它工作的实现细节比较
审核编辑 :李倩
-
3D
+关注
关注
9文章
2875浏览量
107495 -
算法
+关注
关注
23文章
4608浏览量
92845 -
数据集
+关注
关注
4文章
1208浏览量
24691
原文标题:无需任何3D数据!清华朱军团队提出ProlificDreamer:直接文本生成高质量3D内容
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何设计高质量低成本的3D眼镜_Designing Cost-Effective 3D Technol...
阿里3D AI威廉希尔官方网站 已成功应用诸多场景中,可迅速批量生产高质量3D模型
面向社交媒体的高质量文章内容识别模型
基于视觉注意力的全卷积网络3D内容生成方法
文本生成任务中引入编辑方法的文本生成

NVIDIA提出Magic3D:高分辨率文本到3D内容创建
Meta提出Make-A-Video3D:一行文本,生成3D动态场景!
面向结构化数据的文本生成威廉希尔官方网站 研究

生成高质量 3D 网格,从重建到生成式 AI

3D人体生成模型HumanGaussian实现原理
Adobe提出DMV3D:3D生成只需30秒!让文本、图像都动起来的新方法!






 工商网监
工商网监
评论